

こんにちは。TATです。
今日のテーマは「【Kaggleでデータ分析】Pythonでアニメデータを分析する①〜データの概要把握とデータ整形〜」です。
久しぶりにKaggleのデータを使ってデータ分析をしていきたいと思います。
これまでにもいろいろなデータを見てきましたが、今回取り扱うのはアニメのレビューデータです。
過去のアニメのレビューデータがまとめられたものを見つけたので、興味本位で分析してみることにしました。
何を隠そう、僕自身がアニメ大好きなので、このデータを見つけた瞬間に分析することを決めましたw
そして今回の分析の進め方としては、記事を分割して更新していこうと思います。
今までの記事ではどうしても1記事にまとめようと頑張って、最終的にめちゃくちゃ長くなってしまうというケースが多かったので、今後はテーマをきっちりを決めて記事があまり長くなりすぎないように努めます。
今回は第一弾ということで、今回取り扱うアニメデータの概要を把握しつつデータ整形を行っていきます。
データ分析を行う際に、一番最初にやらなければいけない作業です。
Kaggleからアニメデータをダウンロードする
今回用いたアニメのレビューデータの入手元はKaggleというサイトです。
Kaggle公式サイトより
Kaggleはデータ分析をコンペを運営しているサイト
Kaggleはデータ分析のコンペを運営しているサイトです。
いろいろなデータが与えられて、参加者が分析して結果を競い合います。
優勝者には、賞金が贈られたり、開催企業の就職面接を受ける権利などが与えられます。
GoogleやFacebook、日本企業ではメルカリなどもKaggleによるコンペを企画しています。
他人のコードが誰でも見れる
さらに他の参加者のコードも見ることができるので、コードの書き方を学ぶ場としても最適です。
ある程度の基礎知識があれば、あとは人のコードを見ながら学ぶことは効率的です。
僕自身もKaggleでいろいろな人のコードを見ながら学んできました。
ただ、Kaggle は基本的に英語サイトなので、英語が読めないとしんどいです・・・
今回利用したデータ
そして今回利用したアニメのデータがこちらになります。
データをダウンロードするには登録(Register)が必要です。
データの中身を見る
データの準備ができたところで、早速中身を確認していきます。
PythonでCSVファイルを読み込む
まずはデータの読み込みです。
PythonでCSVを読み込みます。
最初の5行を確認してみましょう。
import pandas as pd
df = pd.read_csv("anime-list.csv", index_col=0)
df.head()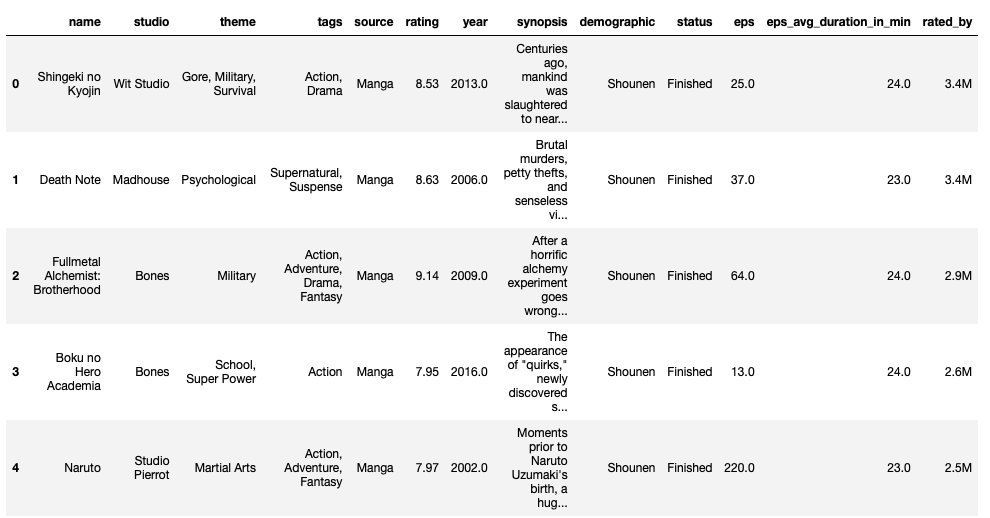
これでデータの読み込みが完了しました。
カラムを確認する
次にデータのカラムを確認していきます。
カラムの説明はファイルをダウンロードしたページにあります。
カラム
- name: アニメタイトル
- studio: スタジオ名
- theme: テーマ
- tags: 追加のテーマやジャンルなど
- source: ソース(マンガなど)
- rating: 評価点
- year: 放送が開始された年
- synopsis: アニメの概要
- demographic: 対象性年齢区分(少年やキッズなど)
- status: ステータス(放送終了、放送中など)
- eps: エピソード数
- eps_avg_duration_in_min: 1羽あたりの長さ(分)
- rated_by: レビュー数
さっとこんな感じです。
データの概要を確認する
ここからデータの概要を見ていきます。
概要を見るにはdescribe関数が便利です。
データ数や平均値など基本的な統計データをまとめて確認することができます。
df.describe()
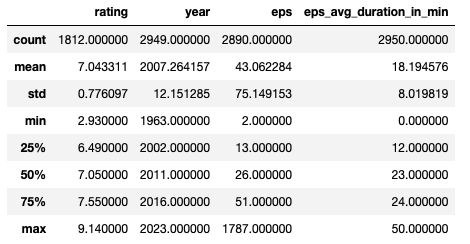
count数がバラバラ
countがデータの個数になりますが、これがカラムによってバラバラですね。
つまり、欠損データが含まれていることがわかります。
ratingは10点満点
ratingを見ると最小値が2.93点で最高値が9.14点です。
10点満点で評価されていることが想像できますね。
平均で7点ほどになります。
最も古いものは1963年!
yearで見ると最も古いものは1963年です。
めちゃ古い。。。
エピソードの最大値は1,787!!!
エピソード数の最大値が1,787というのも衝撃です。
カラムの型を確認する
次にカラムの型を確認します。
これにはinfo関数が便利です。
df.info()
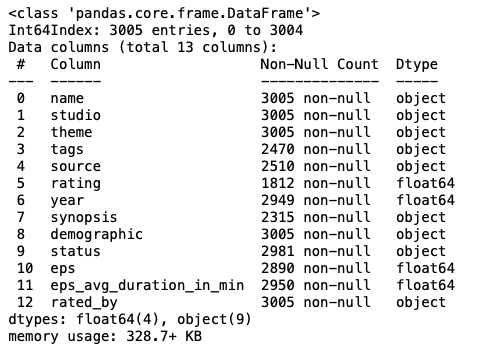
ratingやyear, eps, eps_avg_duration_in_minはfloatなので数値データでその他は文字列です。
カラムごとの値を確認する
次に各カラムの値を見ていきます。
全部見ても仕方ないので、ここでは僕が気になったものだけピックアップします。
studio
まずはstudioです。
データを集計して最も多いものトップ10を表示します。
これにはvalue_countsを使うと便利です。
df["studio"].value_counts().head(10)

Unknownが最大ですw
これを除くと最も多いのが東映アニメーションですね。
それ以降は正直よくわからないスタジオばかり。。。
theme
次にthemeです。
同じ方法で見てみます。
df["theme"].value_counts().head(10)
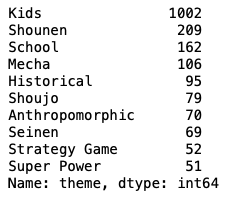
Kidsが圧倒的に多いですね。
以下、少年、スクールと続いています。
そしてその次のMechaはなんなんだと思いましたが、ガンダムとかのロボット系のテーマのようです。
source
次にsourceを見てみます。
df["source"].value_counts().head(10)

漫画がダントツで1位です。
オリジナルも多いですね。
ゲームが3位というのは少し驚きました。
rating
次にratingです。
これはヒストグラムにしてみます。
import seaborn as sns sns.displot(data=df, x="rating")
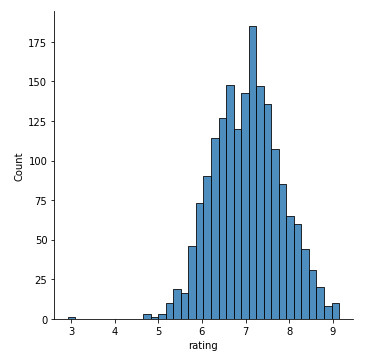
いい感じの正規分布ですね。
7点あたりを最頻値として左右に広がっています。
year
次にyearです。
こちらもヒストグラムで見てみます。
import seaborn as sns sns.histplot(data=df, x="year")
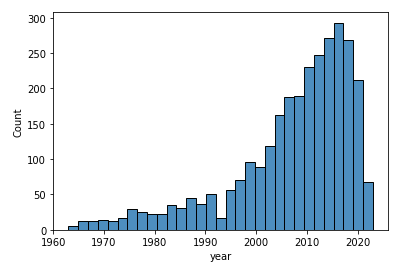
2000年あたりから急激に数が増えてきていることがわかります。
demographic
次にdemographicです。
df["demographic"].value_counts().head(10)

こちらは5つしかありませんでした。
最も多いのはKidsです。
次に少年、青年、少女、女性と続きます。
status
statusも見てみます。
df["status"].value_counts().head(10)

4つのデータがありました。
Finishedは既に放送が終了しているもの、Airingが現在放送中のものであることが想像できます。
しかし、Notとishedについては謎です。
該当するアニメを見てみます。
まずはNotです。
df[df["status"]=="Not"]
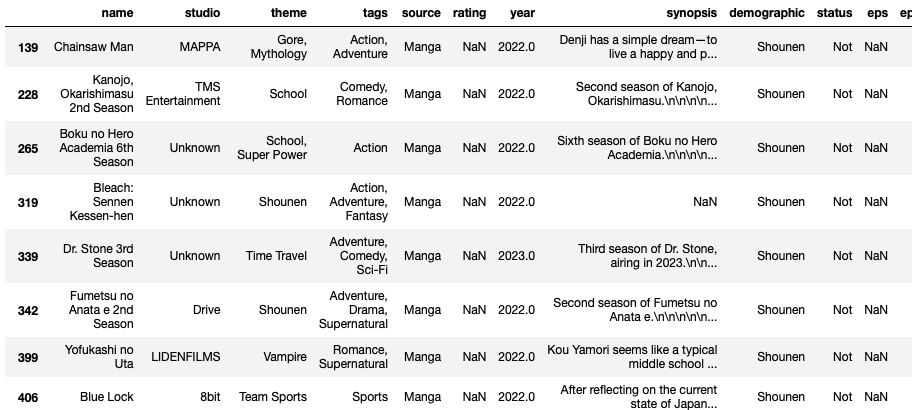
yearを見ると2022年とか2023年なのでまだ放送が開始されていないアニメであることがわかります。
当たり前ですが、ratingもまだありません。
これは分析の際には無視してよさそうですね。
次にishedです。
df[df["status"]=="ished"]
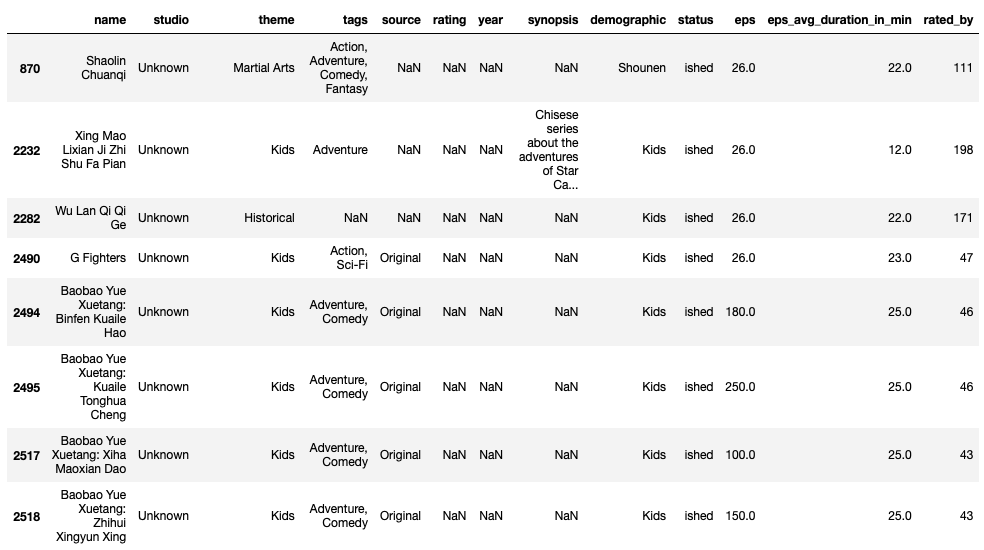
これは謎ですね。
タイトルを見ると中国のアニメのような感じがします。
ratingもないのでこれも無視しちゃいますかね。
よって、分析に使うのはFinishedとAiringだけにします。
rated_by
最後にrated_byです。
df["rated_by"].value_counts().head(10)
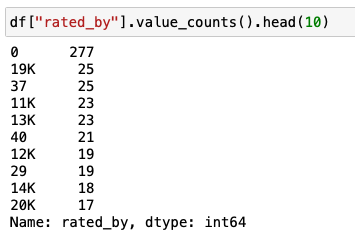
これは文字列になっていますね。
19KのKは千を意味するので、これは19,000という意味になります。
データを見るとKとMがあります。
これは数値に変換しないと使い勝手が悪いので少しデータ整形でいじることにします。
一旦は、これでデータの中身の確認ができました。
分析に備えてデータを整形する
データの中身の確認ができたところで、次にデータ整形を行っていきます。
データ分析を行う際には、この整形作業はとても大事です。
外れ値を除去したり、データの型を変換したり、不要なデータを排除したり、いろいろな作業が発生します。
今回利用するKaggleのデータは、ある程度綺麗になったデータがほとんどなので、あまり大変な作業は発生しませんが、それでもやるべきことはあります。
今回やるのは次の2つです。
データ整形
- rated_byを数値データに変換する
- statusをFinishedとAiringだけに絞る
上記の2つを行っていきます。
rated_byを数値データに変換する
まずはrated_byのデータを数値データに変換します。
ここが少し厄介なところです。
いろいろな方法があると思いますが、僕の場合は正規表現を使って数字を抽出して、文字列にKあるいはMがあればそれぞれ1,000と1,000,000をかけました。
import re
def convert_to_number(x):
number = float(re.findall(r"[0-9.]+", x)[0])
if "K" in x:
number = number * 1000
if "M" in x:
number = number * 1000000
return number
df["rated_by"] = df["rated_by"].apply(convert_to_number)
df["rated_by"].head()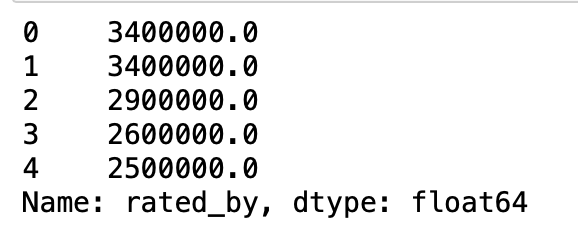
これでrated_byが数値データに変換されました。
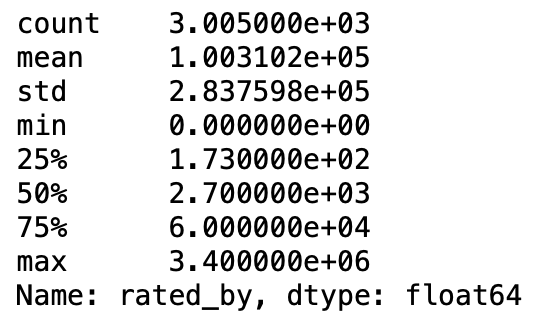
そして、数値データになったのでdescribe関数で基本的な統計情報を見ることができます。
df["rated_by"].describe()
statusをFinishedとAiringだけに絞る
次にstatusで不要なデータを排除します。
前述しました通り、FinishedとAiringのみに絞ります。
df = df[df["status"].isin(["Finished", "Airing"])]
これで完了です。
元々3,005個のデータがありましたが、これで2,916個になりました。
改めてデータを確認する
データ整形が完了したので、改めてデータを確認します。
df.head()
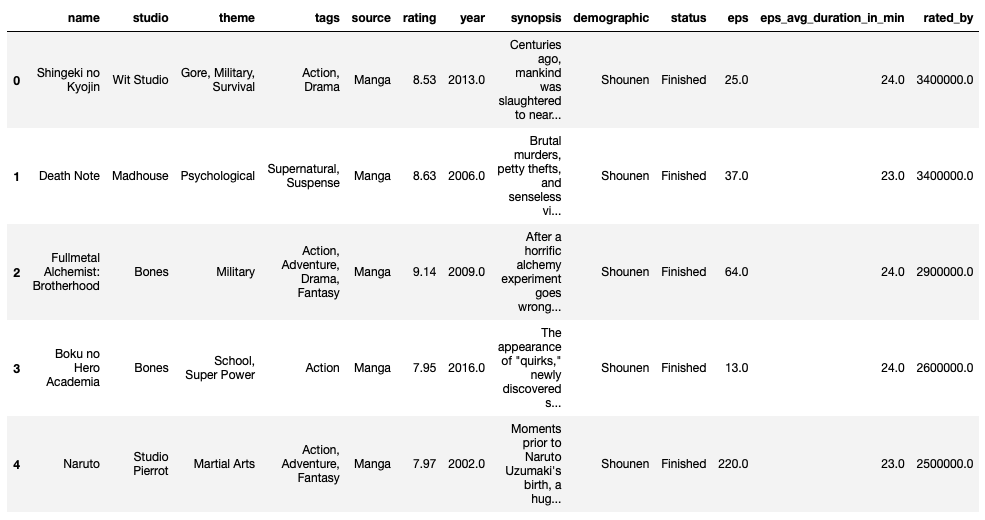
rated_byはいい感じに数値データに変換されています。
これだとわからないですが、statusもFinishedとAiringに絞られています。
これでデータ分析のための準備が完了しました。
次回からはこのデータを使って色々と分析していきます。
まとめ
本記事では、Kaggleに見つけたアニメのレビューデータを分析するために、データの概要の確認やデータ整形について解説してきました。
データ分析を行う際には、どのようなデータなのか、そのまま分析に利用できるのか、を最初に必ず確認する必要があります。
ここで紹介した方法は1つの例に過ぎませんので、人によっていろいろな方法があるかと思います。
大切なことは、データ分析の目的をしっかりと持って、その目的を果たせるようにデータを準備することです。
例えば、ここではrated_byを数値データに変換しましたが、このデータを使う予定が一切ないのであればこの作業は不要です。
僕の場合はこれらのカラムごとの相関関係とかもみたいと思ったので数値データに変換しました。
可視化する際にも、レビュー数のデータがあれば新しい角度からデータが見れますからね。
次回からは、本記事で用意したデータを使って色々とデータを分析していこうと思います。
ここまで読んでくださり、ありがとうございました。




{kind=link}