

こんにちは。TATです。
今回は久しぶりのPythonのコード解説記事です。
過去記事で紹介したシエンタとフリードの中古車データの分析で使用したPythonコードについて解説していきます。
-

【Pythonでデータ分析】シエンタとフリードの中古車データを分析してみた
本記事では、その中でもデータ収集つまりはPythonによるスクレイピング、および収集したデータを整形する前処理にフォーカスして解説します。
その後の分析(可視化やデータの集計など)については、コード付きのスクショで確認できるようにしているので過去記事をご覧くださいませ。
データ収集や前処理の部分についてはテクニカルで細かい話になってくるので別記事で出すことにしました。
コードを全て公開するので、Python学習中を方のお役に立てると嬉しいです。
目次
【Pythonコード解説】価格.comをスクレイピングして中古車データを収集する

収集ターゲットのサイトを確認する
まずは今回のターゲットでる価格.comのサイトについて確認します。
スクレイピングを行う際には、まずはサイトの構造をみる必要があります。
今回対象としたページは2種類あります。
- 特定車種の中古車の一覧ページ
- 各中古車の詳細ページ
基本的には一覧ページへ行って、そこで各詳細ページのURLを取得して順番にアクセスしていくような流れになります。
全部終わったら次にページに進み、次のページがなくなるまでこれを繰り返していきます。
特定車種の中古車の一覧ページ
まずは中古車の一覧ページを確認します。
今回の分析対象となるシエンタとフリードのページはこちらになります。
→ https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Page=1/ (シエンタ)
→ https://kakaku.com/kuruma/used/spec/Maker=2/Model=30264/Generation=42017/Page=1/(フリード)
最後のPageの数字を変えるとページを切り替えることができることがわかります。
一覧ページはこんな感じです。
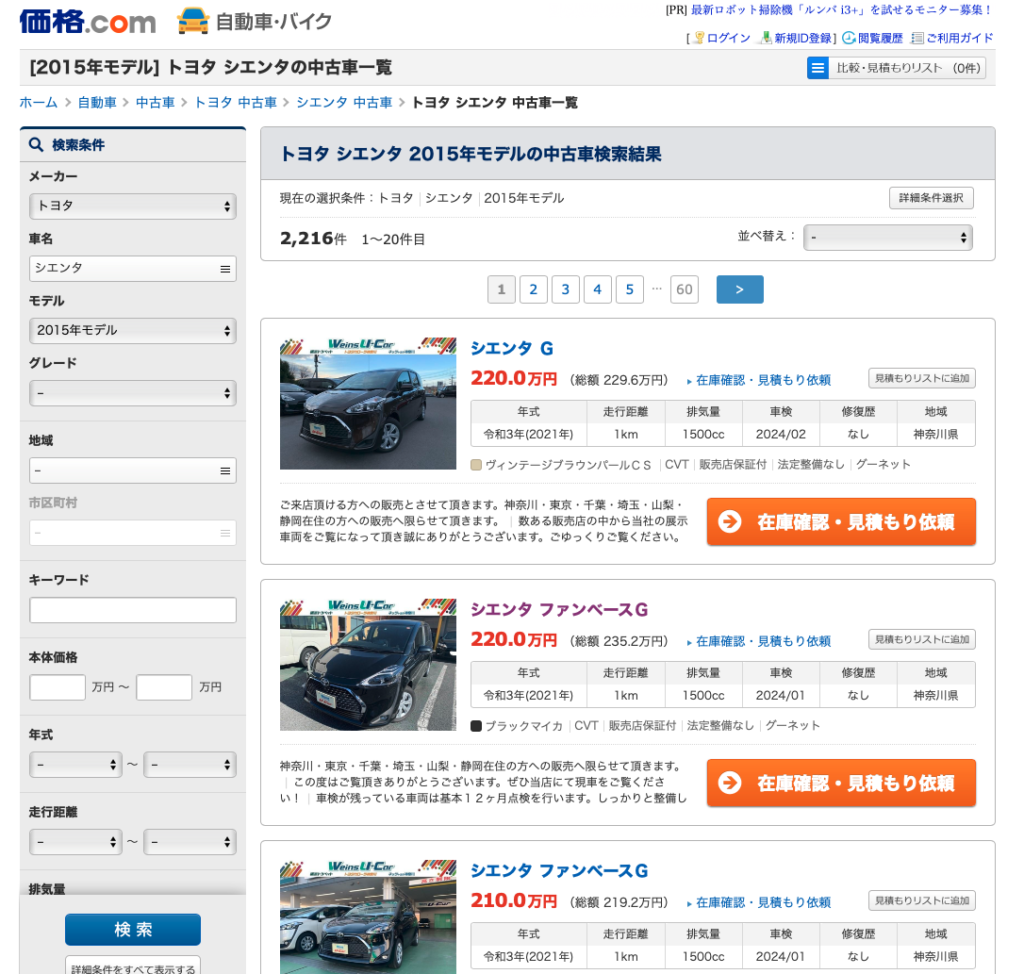
(参照元:価格.com)
次ページに行くには>ボタンを押すか、ページを直接選びます。
URLではPageの後に続く数字を変更すればOKです。
各中古車の詳細ページ
次に詳細ページを確認します。
詳細ページでは一覧ページよりも詳細な情報を入手することができます。
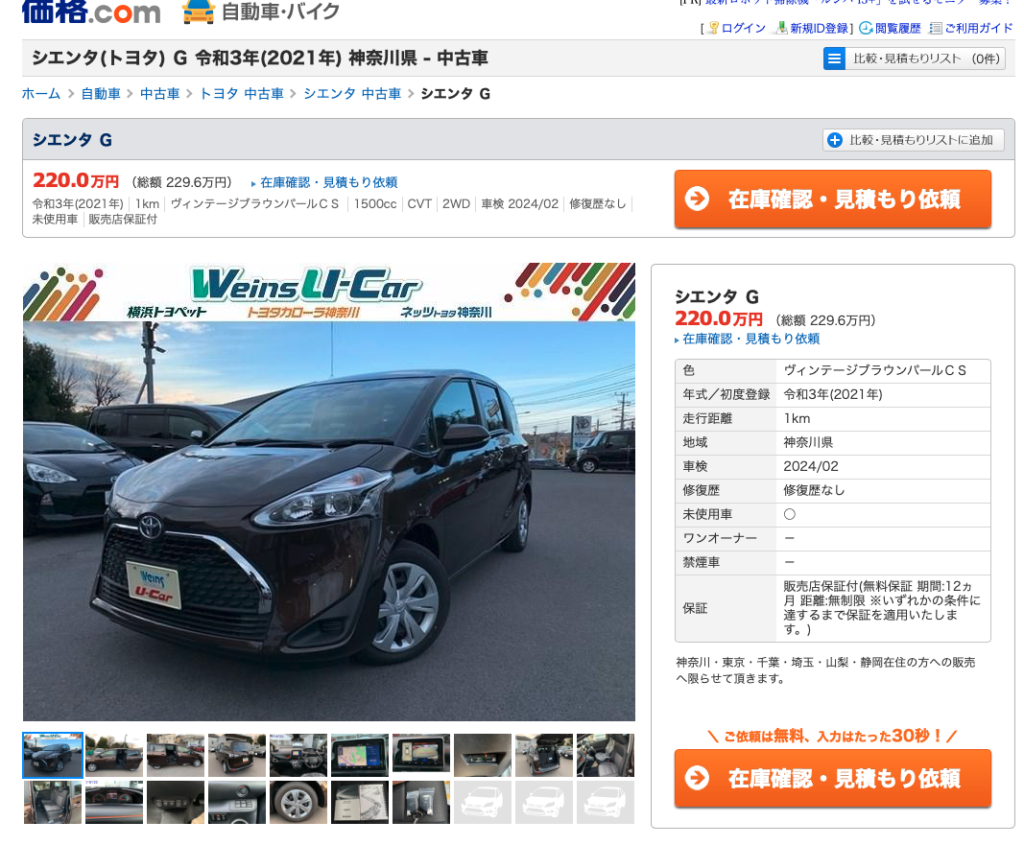
(参照元:価格.com)
右側には走行距離などのデータがあります。
これは一覧ページでも確認できる情報です。
必要な情報がこれで十分であれば、一覧ページから収集すれば十分ですね。
しかし詳細ページには下にスクロールするとさらに細かいデータがあります。
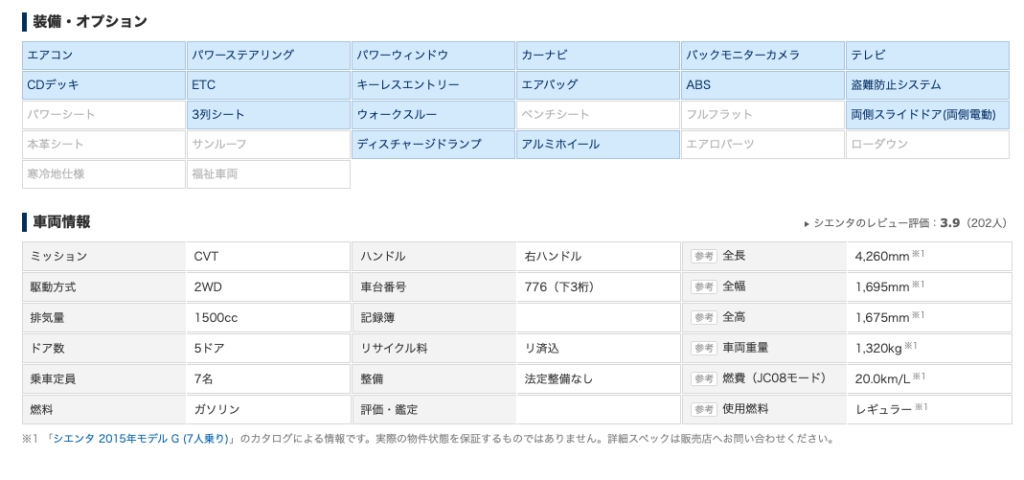
(参照元:価格.com)
装備・オプションや車両情報が揃っています。
これらの情報は詳細ページにこないと見ることができません。
ゆえに、ここのデータが必要になるのであれば、データはこのページから収集する必要があります。
今回は特に装備・オプションのデータも欲しかったので、詳細ページからデータを収集しました。
一覧ページは60ページまでしか表示できない・・・
次に問題点の確認です。
鋭い方ならもうお気づきかもしれませんが、一覧ページをよく見ると最高でも60ページまでしか表示できないことがわかります。
(参照元:価格.com)
1ページで20件ずつ表示されるので、最高でも1,200件までしか表示できないことがわかります。
スクショの通り、シエンタの中古車は2,216件もあるので全てを表示することができません。
よって少し工夫が必要になります。
今回は、地域ごとに分割してデータ収集することにしました。
左側にある条件で、地域を選択するとエリアを絞って検索することができます。
これで総数が1,200以下になるように調整します。
今回の場合は、次のように分けるといい感じになりました。
- 北海道, 東北, 関東
- 甲信越, 北陸, 東海, 近畿
- 中国, 四国, 九州, 沖縄
ここではマニュアルでやってますが、ちゃんと作り込むなら件数に応じてうまく条件を分割して検索するプログラムを入れ込んでもOKです。
今回はスピード重視でマニュアルで対応した次第です。
一回きりの情報収集なので、マニュアルでやったほうが早いという判断です。
ちなみにエリアごとに分けて検索するとURLは次のようになります。
- 北海道, 東北, 関東
→ "https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=1,2,9/Page=1/" - 甲信越, 北陸, 東海, 近畿
→ "https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=17,24,29/Page=1/" - 中国, 四国, 九州, 沖縄
→ "https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=36,42,47/Page=1/"
これらのURLから情報を収集して、全て合体すればデータが完成します。
ちなみにフリードは総数が1,200件以下だったので、分割して検索する必要はありませんでした。
データ収集用のソースコードを全て公開します
サイトの確認が終わったところで早速データを収集します。
Pythonでスクレイピングしてデータを収集します。
まずはコードをどうぞ
まずはとりあえず全コードを一気にお見せします。
その後にコードを機能ごとにかいつまんで解説していければと思います。
あんまりきれいなコードではないですがご容赦くださいw
import requests
from bs4 import BeautifulSoup
import re
from time import sleep
import pandas as pd
from retry import retry
@retry(tries=3, delay=5, backoff=2)
def get_html(url):
# 一覧ページのhtml取得
r = requests.get(url)
soup = BeautifulSoup(r.content, "html.parser")
return soup
def parse_car_detail_info(car_url):
# 変数定義
data = {}
# html取得
soup2 = get_html(car_url)
data["名称"] = soup2.find("h3").getText().strip()
# 価格
data["価格"] = soup2.find("span", {"class": "priceTxt"}).find("span").getText().strip()
# 総額
if len(re.findall(r"[0-9.]+", soup2.find("span", {"class": "total"}).getText().strip())) != 0:
data["総額"] = re.findall(r"[0-9.]+", soup2.find("span", {"class": "total"}).getText().strip())[0]
else:
data["総額"] = None
# スペック
for tr in soup2.find("table", {"class": "specList"}).findAll("tr"):
data[tr.find("th").getText().strip()] = tr.find("td").getText().strip()
# 装備・オプション
for li in soup2.find("div", {"class": "optionArea"}).findAll("li", {"class": "yes"}):
data[li.getText().strip()] = 1
for li in soup2.find("div", {"class": "optionArea"}).findAll("del"):
data[li.getText().strip()] = 0
# 車両情報
dt = soup2.find("div", {"class": "carinfoArea"}).findAll("dt")
dd = soup2.find("div", {"class": "carinfoArea"}).findAll("dd")
for i, value in enumerate(dt):
data[value.getText().strip()] = dd[i].getText().strip()
return data
def check_next_page(soup):
if soup.find("li", {"class": "next"}):
return 1
else:
return 0
# 変数定義
all_data = []
# 60ページまでしかページ遷移できないので、地域ごとに分けて収集する
url_list = [
"https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=1,2,9/Page={}/", # シエンタ, 北海道, 東北, 関東
"https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=17,24,29/Page={}/", #シエンタ, 甲信越, 北陸, 東海, 近畿
"https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Prefecture=36,42,47/Page={}/", #シエンタ, 中国, 四国, 九州, 沖縄
"https://kakaku.com/kuruma/used/spec/Maker=2/Model=30264/Generation=42017/Page={}/" # フリード
]
for url in url_list:
# 1~60ページまでスクレイピング
for page in range(1, 61):
print(url.format(page))
# 一覧ページのhtml取得
soup = get_html(url.format(page))
# 各ページの詳細情報を取得
for item in soup.findAll("div", {"class": "ucItemBox"}):
# url取得
car_url = "https://kakaku.com" + item.find("a").get("href")
print(car_url)
# 車情報取得
all_data.append(parse_car_detail_info(car_url))
# 1秒待つ
sleep(1)
# 次ページが存在するか確認
if check_next_page(soup) == 0:
print("All done")
break
# Dataframeに変換
df = pd.DataFrame(all_data)
ざっくり解説します
なるべく多くのコメントをつけるようにしたので、どこで何をやっているのかはなんとなくお分かりいただけるかと思います。
簡潔にプログラムの流れについて解説しておきます。
ここでは3つの関数を作成しました。
それぞれの役割は関数名の通りです。
- get_html:指定したURLのHTMLを取得する
- parse_car_detail_info:中古車の詳細ページからデータを抽出する
- check_next_page:次のページが存在するかチェックする
63行目以降がメインのコードになります。
67行目でURLのリストを定義しています。
これは地域ごとに分けたシエンタの一覧ページとフリードの一覧ページです。
それぞれのURLに対して次ページがなくなるまでスクレイピングしていく流れになります。
それぞれのURLでPageを指定したら一覧ページのHTMLを取得します。(80行目)
20件の中古車データを取得して、それぞれのURLにアクセスして詳細情報を取得します。
取得データはall_dataに追加していきます。
各ページを取得するたびに1秒待つ動作を入れて、サーバーへの負担を軽減しています。
最終的に集めたデータをDataFrameに変換して収集完了です。
収集データを確認する
上記のコードで収集したデータがこちらになります。
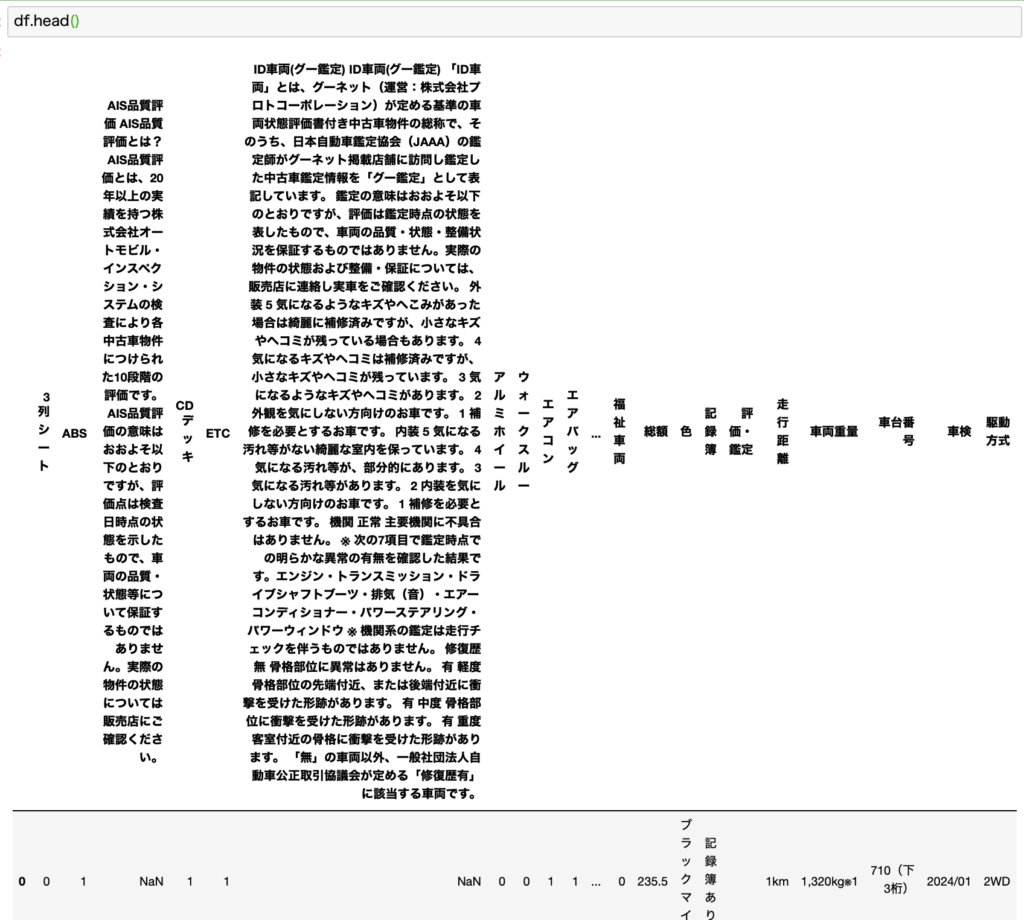
ご覧の通り、謎のカラムが入っていますねw
収集したデータをそのまま分析に使うことはほとんどありません。
データをきれいにする前処理が必要になってきます。
【前処理】収集したデータを整形する
次に収集したデータを整形する前処理の作業について解説していきます。
基本的にスクレイピングで集めたデータをそのまま分析に使うことができる場合はほとんどありません。
データの型を変換したり、不要なデータを削除したり、いろいろな整形作業が必要になってきます。
実施した前処理
今回行った作業は次の通りです。てんこ盛りですw
ポイント
- 「年式/初度登録」カラムから年式(西暦)を抽出
- 「価格」「燃費(JC08モード)」カラムを数値データに変換
- 「走行距離」カラムを数値データ(km単位)に変換
- 「未使用車」「禁煙車」「ワンオーナー」「修復歴」カラムの対象となるものを1、そうでないものを0に変換
- フリードになぜか1991年のデータが紛れていたので排除
- 「価格」あるいは「年式」情報がないデータは排除
これらの処理を施すことで、データ分析が可能な状態になります。
コードを公開
それでは上記の前処理を行うためのコードを公開します。
一気にまとめてどうぞ。
# カラムが100文字以上のものは排除
remove_columns = []
for i in df.columns:
if len(i) >= 100:
remove_columns.append(i)
df = df.drop(remove_columns, axis=1)
# 年式/初度登録:年式(西暦)を抽出
df["年式"] = df["年式/初度登録"].apply(lambda x: int(re.findall(r"[0-9]{4}", x)[0]) if len(re.findall(r"[0-9]{4}", x))!=0 else np.nan)
# 価格:無効データをNaNとして数値データに変換
df["価格"] = df["価格"].replace("応談", np.nan)
df["価格"] = df["価格"].astype(float)
#燃費(JC08モード):数値データを抽出して変換
df["燃費(JC08モード)"] = df["燃費(JC08モード)"].apply(lambda x: float(re.findall(r"[0-9.]+", x)[0]) if len(re.findall(r"[0-9.]+", x))!=0 else np.nan)
def convert_distance(value):
if len(re.findall(r"[0-9.]+", value)) == 0:
return 0
else:
num = float(re.findall(r"[0-9.]+", value)[0])
if "万" in value:
num = float(num) * 10000
return num
# 走行距離:数値データを抽出して変換 単位もkmで統一
df["走行距離"] = df["走行距離"].apply(convert_distance)
# 未使用車:対象する場合は1、しない場合は0に変換
df["未使用車"] = df["未使用車"].apply(lambda x: 1 if x=="○" else 0)
# 禁煙車:対象する場合は1、しない場合は0に変換
df["禁煙車"] = df["禁煙車"].apply(lambda x: 1 if x=="○" else 0)
# ワンオーナー:対象する場合は1、しない場合は0に変換
df["ワンオーナー"] = df["ワンオーナー"].apply(lambda x: 1 if x=="○" else 0)
# 修復歴:ある場合は1、ない場合は0に変換
df["修復歴"] = df["修復歴"].apply(lambda x: 1 if x=="修復歴あり" else 0)
# 年式が1991年のデータを排除
df = df[df["年式"]!=1991]
# 価格あるいは年式がないものは排除
df.dropna(subset=["価格", "年式"], how="any", inplace=True)
上記のコードを使うと、データをきれいに前処理することができます。
基本的にはapply関数を使ってワンコマンドで処理しています。
apply関数を使うと列単位でまとめて処理できるので便利です。
lambda関数を使えば関数を定義せずに関数を扱うことができるので、一回きりの処理を行う場合は便利です。
処理が複雑だったり、何度も繰り返し同じ処理を行う場合には関数として外出しした方が便利になります。
完成データを確認
前処理を完了したデータがこちらになります。
変なカラムは排除されて、データもきれいに整形されていることが確認できます。
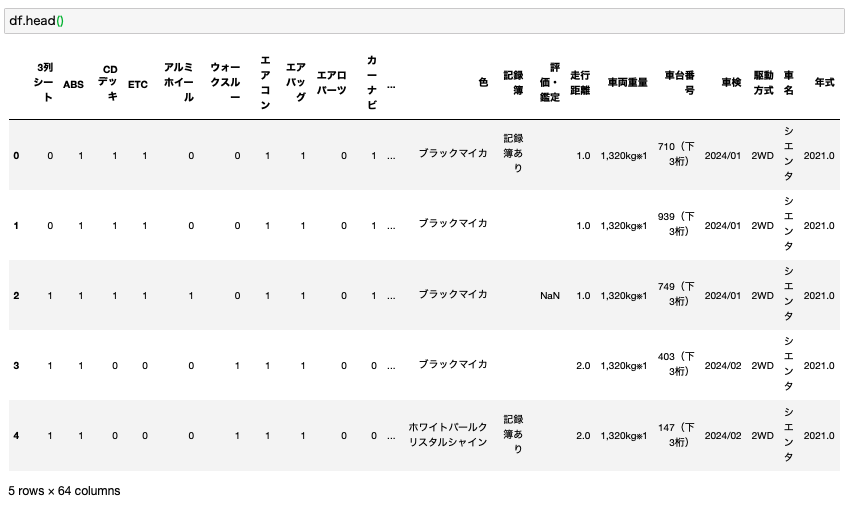
ここまでの処理が完了してようやくデータ分析を開始することができます。
データ収集もなかなか大変な作業ですが、それ以上にこの前処理の作業の方が大変です。
そして単純にめんどくさいです。
データを確認した上で、分析に使うにはどんな作業が必要なのかをいちいち調べる必要があるのでデータ内容によってはかなり厄介な作業になります。
しかしながら、この作業をおろそかにするとデータ分析が行えないので、この作業は必須になります。
ここまで紹介したコードで準備したデータを使って、こちらの記事で紹介している分析を行いました。
-
【Pythonでデータ分析】シエンタとフリードの中古車データを分析してみた
データ分析にはPythonが最適です。
ここまで解説してきたように、Pythonを使うと短いコードでわりと簡単にデータの収集や分析をすることができます。
Pythonはデータ分析やAI関連に強くて、世界中で人気を集めている言語です。
すっきりとしたコード体系で、誰でもきれいなコードが書けるような設計になっています。
過去の記事では、データ分析としてPythonをご紹介している記事や、Pythonでできることをまとめたものがありますので、もしPythonにご興味があれば合わせてご覧ください。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
まとめ
いかがでしたでしょうか。
今回は過去記事で紹介したシエンタとフリードの中古車データの分析で使用したPythonコードについて解説しました。
-
【Pythonでデータ分析】シエンタとフリードの中古車データを分析してみた
特にデータ収集と整形にフォーカスしてPythonコードを全て公開して解説しました。
現在Pythonを学習している方やこれからPythonを学ぼうとしている方に少しでもお役に立てば嬉しいです。
ここまで読んでくださってありがとうございました。




{kind=link}