

こんにちは。TATです。
今日のテーマは「列単位で一括処理できる超便利なPandasのapply関数の使い方について徹底解説」です。
データ分析に必ずと言ってもいいほど利用されるPythonのPandaですが、ここではデータの一括処理に便利なapply関数に焦点を当てます。
applyを使えば、列単位でデータの処理を簡単に行うことができます。
また、複数の列を対象に処理することも可能ですし、行単位の処理もできます。
処理にはlambda関数を使ってもいいですし、自作関数を適用することも可能です。
本記事では、便利なapply関数の使い方について解説していきます。
半分は僕自身の備忘録のためですw
目次
apply関数の基本的な使い方
まずはapply関数の基本的な使い方についてみていきます。
公式ドキュメントはこちらにあります。
apply関数は、DataFrameの列単位で使用します。
指定した列の各値に処理を一括で施すことが可能です。
適当なDataFrameを用意
ちょっと適当なDataFrameを用意します。
import pandas as pd
df = pd.DataFrame([
["A", 1, 100],
["B", 2, 210],
["C", 3, 1005],
["D", 4, 1028],
["E", 5, 50],
["F", 6, 19],
["G", 7, 106],
["H", 8, 105],
["I", 9, 295],
["J", 10, 20],
],columns=["X", "Y", "Z"])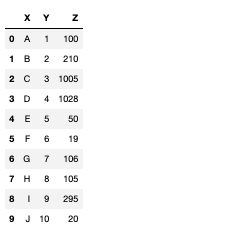
基本は関数を用意して列単位で適用する
apply関数を利用するには、列を指定して適用します。
例として、引数の2乗を計算する関数を定義してY列にapply関数を適用してみます。
def func(x):
return x * x
df["Y"].apply(func)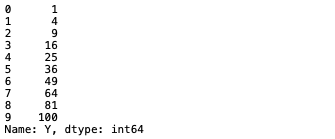
funcという関数を用意して、ここで引数(x)を2乗したものを返します。
これでapply関数を適用すると、各値を2乗した値が返されていることが確認できます。
これを別のカラムに格納してやれば、簡単にカラムを追加することができます。
df["Y2"] = df["Y"].apply(func)
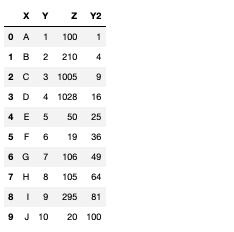
Y2というカラムが追加されました。
lambda関数を使うとコードがスッキリする
関数を定義する代わりにlambda関数を使うと、コードがスッキリします。
先ほどの関数をlambda関数に置き換えてみます。
df["Y"].apply(lambda x: x*x)
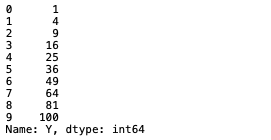
lambda関数を使うと、わずか1行で完了します。
apply関数を使いこなす
apply関数の基本的な使い方がわかったところで、ここからは少し実用的な使い方をご紹介します。
複数の列でapply関数を適用する
まずは複数の列に対してapply関数を適用させてみます。
これには、apply関数の中でaxis=1を追加すればOKです。
例としてX列とY列を結合してA-1みたいな値を返してみます。
def func(x):
return "{}-{}".format(x["X"], x["Y"])
df[["X", "Y"]].apply(func, axis=1)
この際、引数のxはSeriesになるので、列名を指定すればデータを取得できます。
同様の処理をlambda関数で実装することも可能です。
df[["X", "Y"]].apply(lambda x: "{}-{}".format(x["X"], x["Y"]), axis=1)
引数のある関数にapply関数を適用する
次に関数に引数がある場合の処理を紹介します。
関数に引数がある場合には、apply関数適用時にargsを指定すればOKです。
例として、Z列に対して任意の数字を足す関数を定義してapply関数て実装してみます。
結果をZ2というカラムに格納しました。
def func(x, number):
return x + number
df["Z2"] = df["Z"].apply(func, args=(10000, ))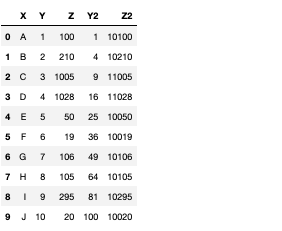
10000を引数をして指定しましたが、きちんと計算できていることが確認できます。
argsを指定する際、引数が1つの場合は最後に,をつけないとエラーになるのでお気をつけください。
引数が複数ある場合だとこれは不要です。
行単位でapply関数を適用する
最後に、行単位でapply関数を適用する方法についてご紹介します。
先ほどの複数の行でapply関数を適用したときと同様に、axis=1とすればOKです。
行単位で処理を行いたい場合は列の指定は不要で、DataFrameに直接apply関数を適用していきます。
例として、全ての列の値を文字列として-で繋いで返す関数を作ってapply関数を適用してみます。
def func(x):
return "-".join(x.astype(str).tolist())
df.apply(func, axis=1)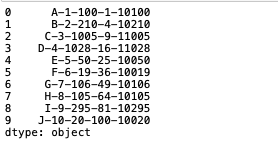
列によっては数値データが含まれているので、astype(str)で文字列に変換した上で、tolist()でリストに変換、最後にjoinで文字列として結合すればOKです。
各行の値が連結できていることが確認できます。
これで、apply関数の使い方の解説はおしまいです。
なぜapply関数なのか?forループじゃダメなのか?
apply関数は書き方に少しクセがあるので、最初はとっつきにくいかもしれませんが、慣れてしまうととても便利です。
最後に、(今更ですが)なぜapply関数を使うべきかについて少し触れておこうと思います。
ぶっちゃけ、ここで紹介した処理はapply関数を使わずとも、forループを使っても実装できます。
「なんでわざわざapply関数を使うんだ?」という疑問に僕からお答えしておきます。
apply関数を使うべき理由
- コードがスッキリする
- 処理速度がforループに比べてはるかに早い
上記の2点が主な理由になります。
コードがスッキリする
1つ目は見た目です。
forループを使うより、apply関数を使った方がコードがスッキリします。
コードの行数も減ります。
lambda関数を利用すればさらにスッキリします。
処理速度がforループに比べてはるかに早い
2点目が処理速度です。
これが一番大事かもしれません。
apply関数を使うとforループに比べて処理速度が爆上がりします。
上記のサンプルコードではデータ量が大きいのでそこまで処理速度を実感することはできませんが、データのサイズが大きくなるにつれてこの影響は大きくなります。
基本的には、forループはなるべく利用せずにapply関数を利用した方が無難です。
データの分析・可視化にはPythonが最適!
本記事で紹介したコードは、全てPythonを使って書いています。
Pythonはデータの分析や可視化を得意とするプログラミング言語で、さらにAI関連のライブラリーも豊富で昨今のAIブームで需要が急拡大しています。
→ 【いますぐ始められます】データ分析をするならPythonが最適です。
また、Pythonは比較的学びやすい言語でもあります。
実際、僕は社会人になってからPythonを独学で習得して転職にも成功し、Python独学をきっかけに人生が大きく変わりました。
→ 【実体験】ゼロからのPython独学を決意してから転職を掴み取るまでのお話。
Pythonの学習方法についてはいろいろな方法があります。
僕はUdemyを選びましたが、書籍やプログラミングスクールも選択肢になります。
→ 【決定版】Python独学ロードマップ【完全初心者からでもOKです】
→ 【まとめ】Pythonが学べるおすすめプログラミングスクール
→ プログラミングの独学にUdemyをおすすめする理由!【僕はUdemyでPythonを独学しました!】
まとめ
本記事では、「列単位で一括処理できる超便利なPandasのapply関数の使い方について徹底解説」というテーマでapply関数の使い方について解説しました。
apply関数を使えば、PandasのDataFrameやSeriesのデータを列単位で一括処理することができます。
複数列の処理も可能ですし、行単位の処理にも対応しています。
apply関数を使えばmforループよりもコードがスッキリしたみやすいコードになるだけではなく、処理速度が格段に向上します。
特にデータサイズが大きくなるとこの差は顕著に出てくるので、基本的にはなるべくforループは使用せずにapply関数を利用することをお勧めします。
apply関数は少し書き方にクセがあるので最初にうちは慣れないかもしれませんが、慣れてしまえばこんなに便利な関数はありません。
是非とも本記事のコードを参考にしていただければと思います。
ここまで読んでくださり、ありがとうございました。




{kind=link}