

こんにちは。TATです。
今日のテーマは「Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた」です。
今回からしばらくは、楽天トラベル関連の記事で発信していきます。
スクレイピングでデータを収集したり、収集データの前処理をしたり、分析したり、いろいろとやってみようと思っています。
本記事が楽天トラベル関連の記事の第一弾で、Pythonを使って東京23区内にあるホテル情報を収集してみます。
必要なPythonコードを解説しつつ、スクレイピングする際のポイントとかをお伝えできればと思います。
収集データの中身の確認
まずは収集データの中身の確認です。
対象は東京23区
本記事では、東京23区のあるホテルを対象にします。
検索結果に出てきたホテル全ての情報を収集します。
こちらから東京23区内のホテル一覧が確認できます。
プログラムを走らせた2022年9月22日夜の時点では、全部で2,242個のホテルがありました
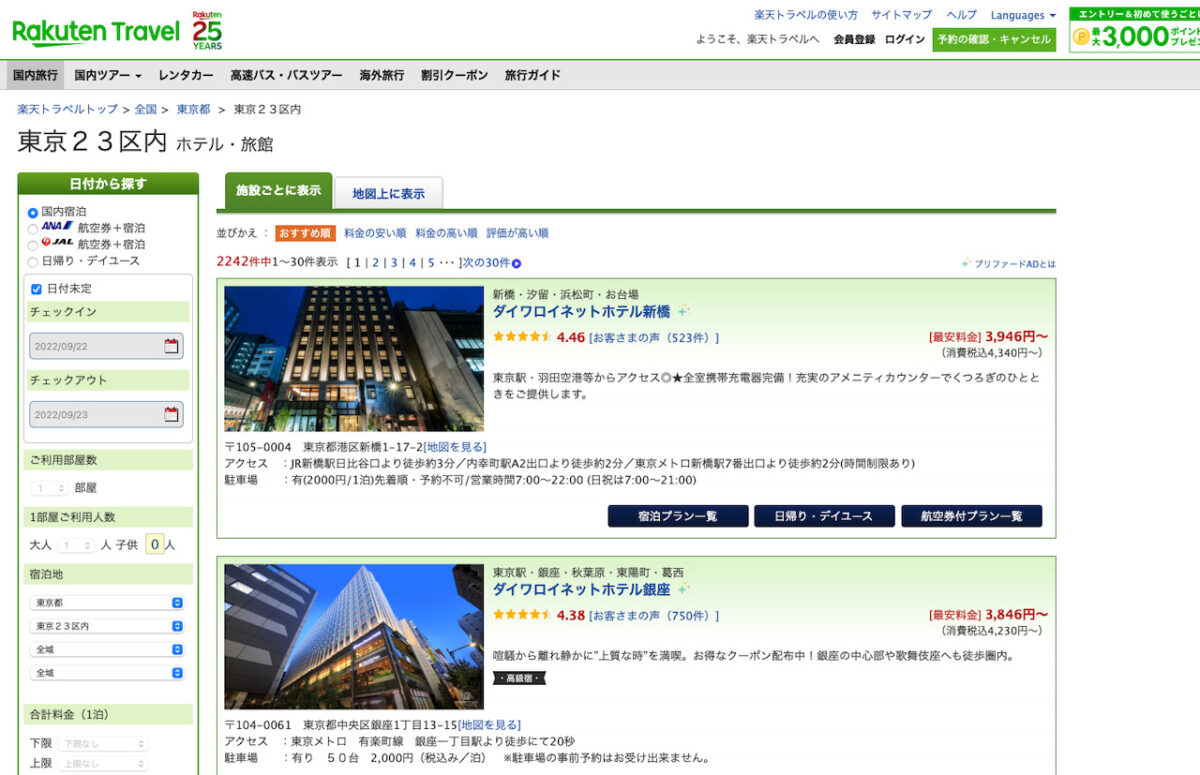
これらホテルの情報を収集します。
各ホテルの取得データ
次に各ホテルの取得データです。
今回は、各ホテルに対して次のデータを収集します。
ポイント
- ホテル名
- ホテルページのURL
- アクセス情報(住所とか最寄駅とか)
- レビュー情報(総合評価、評価内訳、項目別の評価)
- プラン名
- 部屋情報(広さとか食事とか)
- 基本価格(予約可能期間内の料金範囲のみ)
価格情報については、さらに細かく収集するなら日付ごとの料金を収集する必要がありますが、それは別の記事で紹介します。
本記事では上記の基本情報のみを収集していきます。
サイト構造の確認
次にサイト構造を確認します。
スクレイピングを行うなら必ず必要な作業です。
サイトの構造を理解して、どのようにプログラムを作っていくかを決めていきます。
ホテル一覧ページの確認
まずはホテル一覧ページを確認します。
こちらです
おすすめ順で収集します
表示順序はおすすめ順、料金の安い順、料金の高い順、評価の高い順から選択することができます。
今回はデフォルトで表示されるおすすめ順でいきます。
次のページがなくなるまで無限ループします
さらにサイトの構造を見ていきます。
ホテルの一覧ページを見ると、各ページには30件のホテルが掲載されています。
「次の30件」をクリックすると、次のページに進みます。
2ページ目のURLはこちらです。
https://search.travel.rakuten.co.jp/ds/yado/tokyo/tokyo-p2
URLを見ると、最後のp2の部分がページを示していることが想像できます。
1からスタートして、次ページがなくなるまで1ずつ足していけばいいことがわかります。
「次の30件」で検索すると最後のページでミスる
そして最後に注意点です。
次のページを確認する際に、「次の30件」で値を検索すると、最後のページでミスります。
30で割り切れる数なら問題ないですが、今回の2,242は30では割り切れないので、最後はこんな感じで「次の22件」となります。
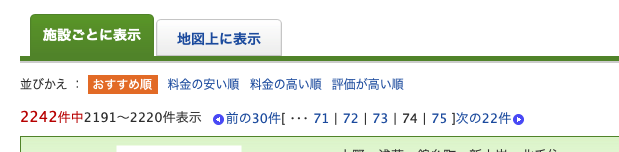
classで指定するとうまくいきます
最後のページまできちんとスクレイピングするためには、テキストで検索するのではなくて、classで指定してやるとうまくいきます。
次のページのリンクを見ると、1つ上の階層にliがあります。
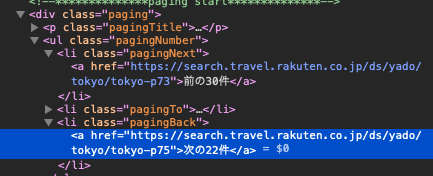
そしてこのliのclassを見てみるとclass="pagingBack"とあります。
なんか「NextとBackで使いどころが逆なんじゃね?」と思いましたが気にせずいきます(密かに楽天側のミスだと思ってます)w
このclass="pagingBack"のliを指定してあげると、テキストの中身に関わらず、次のページのリンクがあるのかどうかをチェックできます。
これが見つからなければ最終ページで、プログラムを終了すればOKです。
ホテルページの確認
次にホテルページの確認です。
例として「ホテル雅叙園東京」のページを見てみます。

個人的に思い入れのあるホテルなので、ここで例としてピックアップしましたw
過去記事: 【おすすめです!】ホテル雅叙園東京の「渡風亭」で『お食い初め』をしてきました!
各ホテルにIDらしきものが付与されている
まず、URLについて確認します。
https://travel.rakuten.co.jp/HOTEL/1661/1661.html
この1661というのはIDっぽいですね。
各ホテルに固有の番号がついています。
このIDさえわかれば、URLを特定することができます。
「地図・アクセス」ページ
ホテルのページにはいくつかのタグがありますが、「地図・アクセス」へいくと住所などの情報を収集できます。

URLはこちらになります。
https://travel.rakuten.co.jp/HOTEL/1661/rtmap.html
こちらもIDがわかればURLを特定できます。
「お客さまの声」ページ
次に「お客さまの声」のタブを確認します。
ここで、レビューデータを収集することができます。

総合評価やさらに細かいレビュー点数まで確認することができます。
ここから収集すればOKですね。
URLも次のとおりで、IDさえわかればURLが特定できる構造になっています。
https://travel.rakuten.co.jp/HOTEL/1661/review.html
Pythonでスクレピングする
サイトの構造が確認できたので、ここから実際にPythonでスクレイピングをしてデータを収集していきます。
ホテル一覧の取得
まずはホテル一覧を取得します。
東京23区内にあるホテルすべて2,242個を取得します。
まずは全Pythonコードをどうぞ
とりあえずPythonコードを公開して、後から解説していきます。
それではコードをどうぞ。
import requests
from bs4 import BeautifulSoup
import unicodedata
import re
import pandas as pd
import time
# 文字列を正規化する
def normalize_text(text):
return unicodedata.normalize("NFKC", text)
# htmlを取得
def get_html(url):
print(url)
r = requests.get(url)
soup = BeautifulSoup(r.content, "html.parser")
return soup
hotel_list_url = "https://search.travel.rakuten.co.jp/ds/yado/tokyo/tokyo-p{}"
all_data = []
is_next_page_available = True
page = 1
# 次ページがなくなるまでループ
while is_next_page_available:
# get html
soup = get_html(hotel_list_url.format(page))
# extract hotels
for hotel in soup.find("ul", {"id": "htlBox"}).findAll("h1"):
d = {}
d["ホテル名"] = normalize_text(hotel.find("a").getText().strip())
d["hotelId"] = re.findall(string=hotel.find("a").get("href"), pattern=r"HOTEL/([0-9]+)")[0]
d["エリア"] = normalize_text(hotel.findParent().find("p", {"class": "area"}).getText().strip())
d["link"] = hotel.find("a").get("href").split("?")[0]
all_data.append(d)
# check next page
if soup.find("li", {"class": "pagingBack"}):
page+=1
time.sleep(1) # サーバへの負荷を考慮して1秒待ってから次に進む
else:
is_next_page_available = False
df_hotel = pd.DataFrame(all_data)
df_hotel.head()
上記のコードで、ホテル一覧を取得できました。
各ホテルの名前、ID、エリア、URLを取得しています。
このIDがあれば、各ホテルのページにアクセスすることができるので、さらに細かい情報を収集することができます。
コードの中身を解説
ここからコードの中身について簡単に説明します。
まず、normalize_textとget_htmlという2つの関数を定義しています。
normalize_textで文字の揺らぎを回避
normalize_textは文字列を正規化するためのものです。
スクレイピングでデータを収集していると、文字の揺らぎが結構あります。
数字が一部全角になっていたり、変な文字コードが入っていたりします。
normalize_textでこれらを回避することができます。
get_htmlでHTMLを取得
get_htmlではHTMLを取得します。
requestsとBeautifulSoupを使いました。
次のページがなくなるまで無限ループ
全体的な流れとしては、hotel_list_urlのHTMLを取得して、各ホテルの情報を収集します。
soup.find("li", {"class": "pagingBack"})で次のページがあるかどうかを確認し、YesならPageに1を追加して継続、Noならプログラムを終了します。
# extract hotelsの部分では、各ホテルの情報を取得します。
各ホテルにはh1タグがついていたので、これらを全て取得して、1つずつ中身を取り出しています。
各ホテルの情報を取得
次に各ホテルの情報を収集していきます。
各ホテルのURLについては、IDさえあれば特定することができます。
先ほど収集した一覧データからIDを順番に取り出して各ホテルの情報を収集していけばOKです。
特定ホテルのアクセス情報を取得する
まずはアクセス情報を取得するためのプログラムについてみていきます。
前述の通り、アクセス情報にはホテルのIDさえわかればアクセスできます。
https://travel.rakuten.co.jp/HOTEL/1661/rtmap.html
今回は、指定したIDのアクセス情報を取得する関数(get_access)を作りました。
access_url = "https://travel.rakuten.co.jp/HOTEL/{0}/rtmap.html"
def extract_hotel_name(soup):
return normalize_text(soup.find("h2").getText().strip())
# access info
def get_access(hotelId):
# get html
soup = get_html(access_url.format(hotelId))
# extract info
data = {}
data["ホテル名"] = normalize_text(extract_hotel_name(soup))
data["hotelId"] = hotelId
data["url"] = hotel_url.format(hotelId)
for li in soup.find("ul", {"class": "dtlTbl"}).findAll("li"):
key = normalize_text(li.find("dt").getText().strip())
value = normalize_text(li.find("dd").getText().strip())
data[key] = value
return data
こちらのコードを使うと、こんな感じでアクセス情報を取得することができます。

特定ホテルのレビューデータを取得する
同様に、特定ホテルのレビューデータを取得する関数(get_review)も作りました。
review_url = "https://travel.rakuten.co.jp/HOTEL/{0}/review.html"
# review
def get_review(hotelId):
soup = get_html(review_url.format(hotelId))
if soup.find("li", {"class": "rate"}):
# 総合評価
data = {
"総合": normalize_text(soup.find("li", {"class": "rate"}).getText().strip()),
"アンケート件数": normalize_text(soup.find("li", {"class": "number"}).getText().strip()).split(":")[1]
}
# 評価内訳
for li in soup.find("div", {"class": "rateDetail"}).findAll("li"):
key = normalize_text(li.find("span", {"class": "point"}).getText().strip())
value = normalize_text(li.find("span", {"class": "number"}).getText().strip())
data[key] = value
# 項目別の評価
for li in soup.find("div", {"class": "rateItem"}).findAll("li"):
key = normalize_text(li.find("span", {"class": "name"}).getText().strip())
value = normalize_text(li.find("span", {"class": "rate"}).getText().strip())
data[key] = value
else:
data = {}
return data
こちらも先ほど同様にIDを指定してあげると、レビューデータを取得してくれます。
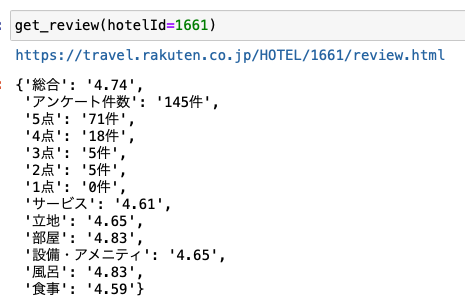
バッチリですね。
特定ホテルのプランと部屋の情報を取得する
次に特定ホテルのプランと部屋の情報を取得するためのプログラムを作ります。
これも関数(get_plan_and_room)を作りました。
price_url = "https://hotel.travel.rakuten.co.jp/hotelinfo/plan/{0}"
def get_plan_and_room(hotelId):
soup = get_html(price_url.format(hotelId))
all_data = []
# get plan list
for plan in soup.findAll("li", {"class": "planThumb"})[:5]: # プランが多すぎる場合を考慮して5つまでに制御
d = {}
d["hotelId"] = hotelId
# extract plan id
planId = plan.get("id")
d["planId"] = planId
#print(planId)
# plan name
d["プラン名"] = normalize_text(plan.find("h4").getText()).splitlines()[-1].strip()
# get room list
for room in plan.findAll("li", {"class": "rm-type-wrapper"}):
room_data = d.copy()
roomInfo = room.find("dd", {"class": "htlPlnTypTxt"})
# room name
if roomInfo.find("h4"):
room_data["ルーム名"] = normalize_text(roomInfo.find("h4").getText().strip())
elif roomInfo.find("h6"):
room_data["ルーム名"] = normalize_text(roomInfo.find("h6").getText().strip())
# room type
roomTypeInfo = roomInfo.find("span", {"data-locate": "roomType-Info"})
room_data["ルームタイプ"] = normalize_text(roomTypeInfo.find("strong").getText().strip())
# meal
roomMealInfo = roomInfo.find("span", {"data-locate": "roomType-option-meal"})
room_data["食事"] = normalize_text(roomMealInfo.getText().replace("食事", "").strip())
# area
room_data["面積"] = normalize_text(roomTypeInfo.getText().replace(room_data["ルームタイプ"], "").strip())
# facility
facility = [normalize_text(i.strip()) for i in roomInfo.find("p", {"data-locate": "roomType-Remark"}).getText().split("・")]
room_data["設備"] = facility
# people info
people = roomInfo.find("span", {"data-locate": "roomType-option-people"}).getText().replace("人数", "").strip()
room_data["部屋人数"] = [normalize_text(i.strip()) for i in people.splitlines()]
room_data["決済方法"] = normalize_text(roomInfo.find("span", {"data-locate": "roomType-option-payment"}).getText().replace("決済", "").strip())
room_data["ポイント"] = normalize_text(roomInfo.find("span", {"data-locate": "roomType-option-point"}).getText().replace("ポイント", "").strip())
for li in room.find("ul", {"class": "htlPlnRmTypPrc"}).findAll("li"):
row_data = room_data.copy()
row_data["人数"] = normalize_text(li.find("dt").getText()).splitlines()[0]
row_data["価格"] = normalize_text(li.find("dt").find("strong").getText())
row_data["link"] = normalize_text(li.find("a").get("href"))
all_data.append(row_data)
return pd.DataFrame(all_data)
こんな感じでIDを指定してあげるとプランと部屋のデータが取得できます。
こちらは、返り値がDataFrame形式となっています。

プラン名や面積、設備など、取れる情報はなるべく根こそぎ取得しています。
そしてこちらのプログラムでは、下記のコードで取得するプランを最初の5つだけに制限しています。
for plan in soup.findAll("li", {"class": "planThumb"})[:5]:
楽天トラベルでプランを探すと、場合によっては100個以上のプランがあったりします。
全部取得してると無駄にデータが多くなるので、各ホテルで5つまでに絞りました。
プラン数が多くなりすぎると、ページがわかりにくくなったり、データ量が増えてページの読み込みが遅くなったりと、結構弊害が出てくるので少し工夫した方がいいんじゃないかな〜と個人的に思います。。。
Booking.comとかはこの辺りの情報がきれいに整っている印象があります。 (その代わりに特別プランみたいなものはない。。。)
全ホテルのデータを取得する
ここまでで、ホテルリストの収集と、特定ホテルのデータの収集するコードができたので、ここからが最後の仕上げです。
全ホテルのデータを収集します。
これはシンプルに、ホテル一覧のデータからIDを1つずつ取得して、アクセスとかレビューデータをそれぞれ取得していけばOKです。
とりあえずコードをどうぞ
base_data = []
plan_room_data = []
for i in range(len(df_hotel)):
#for i in range(5):
print("{}/{}".format(i+1, len(df_hotel)))
hotel_row = df_hotel.iloc[i]
hotelId = hotel_row["hotelId"]
# base info
base = get_access(hotelId)
base.update(get_review(hotelId))
base_data.append(base)
time.sleep(1)
# price data
df_plan_room = get_plan_and_room(hotelId)
plan_room_data.append(df_plan_room)
time.sleep(1)
df_base = pd.DataFrame(base_data)
df_plan_room = pd.concat(plan_room_data, ignore_index=True)
これで各ホテルのデータを取得することができます。
サーバーへの負荷を考慮して、ところどころに1秒待機するロジックを加えました。
base_dataにアクセス情報とレビュー情報をまとめて、plan_room_dataに部屋とプランのデータを格納していきます。
最後に収集したデータをDataFrameに変換すれば完成です。
plan_room_dataには、DataFrameがリスト形式で格納されているので、1つにまとめるときにはpd.cocatを使います。
データの確認
収集したデータを確認します。
アクセスデータとレビューデータ
まずはアクセスデータとレビューデータがまとまっているdf_baseです。

きちんとデータが収集できていますね。
2,242個、全てありました!
プランと部屋のデータ
次にプランと部屋のデータがまとまっているdf_plan_roomです。

こちらもきちんとデータが収集できていることが確認できます。
ただし、こちらは一部のホテルのデータは含まれていませんでした。
理由は、こんな感じで情報がなかったためです。
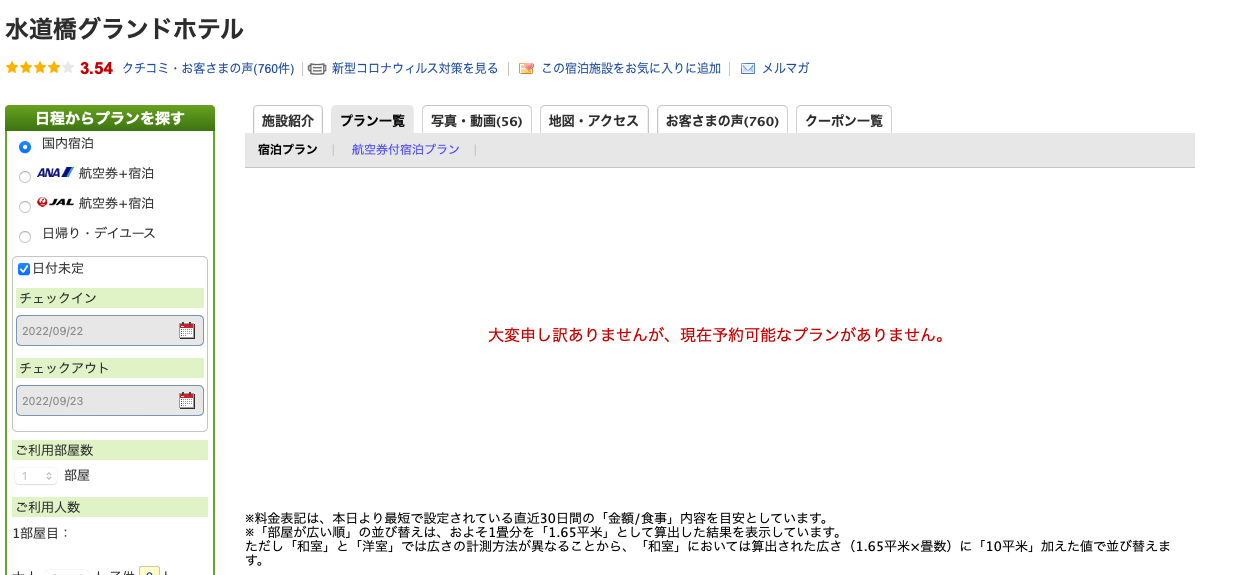
最終的に収集できたホテル数は、1,702個でした。
思っていたよりも予約を停止しているホテルが多いですね。
分析するにはデータが汚すぎるw
以上でデータの収集は完了しましたが、このままの状態では分析はできません。
今のままでは汚すぎて分析することは不可能です。
数値データも文字列になってますし、住所とかもベタがきなので区ごとに分けて比較するとかの分析も一切できません。
分析をするにはたくさんのデータ整形が必要になってきます。
そしてこれが一番大変だったりします。。。
これについては次の記事でまとめていこうと思います。
まとめ
本記事では、「Pythonで楽天トラベルから東京23区内のホテル情報を収集する」というテーマで、Pythonを使って、楽天トラベルとスクレイピングする方法について解説しました。
久々のコード解説記事で気合が入ってしまったのか、かなり長文になってしまいました。
本記事でご紹介したとおり、Pythonであれば比較的短いコードでスクレイピングも用意に実装することができます。
データの収集にPythonはとてもおすすめです。
ただ、今回収集したデータはまだまだ汚い状態でこのまま分析に使うことはできません。
分析を行うためには、まずはデータをきれいに整形してあげる必要があります。
データ整形のやり方については次の記事で解説していこうと思います。
とりあえず、本記事ではデータの収集に焦点を絞って、これで終わりにしたいと思います。
ここまでの長文を読んでくださり、ありがとうございました。




{kind=link}