

こんにちは。TATです。
今日は久々にPythonのコード解説です。
テーマは「WebスクレイピングでAjaxを突破してデータを取得する」です。
Webスクレイピングの中でも少し難易度が高い方法になります。
こちらの記事でJリーグの選手データを収集した方法について解説します。
-

【Sorare攻略大作戦】Jリーグの全選手データを収集して分析する【Pythonでデータ分析】
続きを見る
Webスクレイピングをかじっていると、「Chromeでソースを見たらデータが確認できるのに、requestsなどで取得したらデータがなくなった。おわたw」みたいな経験をしたことがある方が少なからずいるのではないでしょうか?
この要因はいろいろ考えられますが、その1つがAjaxです。
Ajaxは「Asynchronous JavaScript + XML」の略で、Webブラウザ内で非同期通信を行いながらインターフェイスの構築を行うプログラミング手法です。(Wikipedia参照w)
「は?」と思われるかもしれませんが、サイトを見ているとURLが変わらないのに、ボタンを押すと表示内容が変わるみたいなページを見たことがあると思います。
これはAjaxの利用例です。
ページを切り替えることなく、Webブラウザ内でデータのやり取りをすることができ、URLが同じまま表示内容を変更することができるようになります。
今回は、PythonのWebスクレイピングでここを突破する方法を解説しようと思います。
目次
【Pythonコード解説】WebスクレイピングでAjaxを突破してデータを取得する!

まずはAjaxが立ちはだかると何が起こるのかを確認する
まずは冒頭でお伝えした「Chromeでソースを見たらデータが確認できるのに、requestsなどで取得したらデータがなくなった。おわたw」という事象の例をご紹介します。
例として使わせていただくサイトが、JLEAGUE.JPです。Jリーグの公式サイトらしいです。
過去記事で、分析のためにこちらのサイトから選手データを収集したことがありました。
-
【Sorare攻略大作戦】Jリーグの全選手データを収集して分析する【Pythonでデータ分析】
続きを見る
その際にぶち当たったのがAjaxです。
事象を確認してみます。
右上にある「クラブ」をクリックするとチーム一覧が見れます。
J3までのチームが揃っています。
例としてコンサドーレ札幌の選択してみます。
少しスクロールすると、選手名鑑というタブがあります。
これを選択すると選手一覧が表示されます。
こちらのリンクからご確認いただけます。
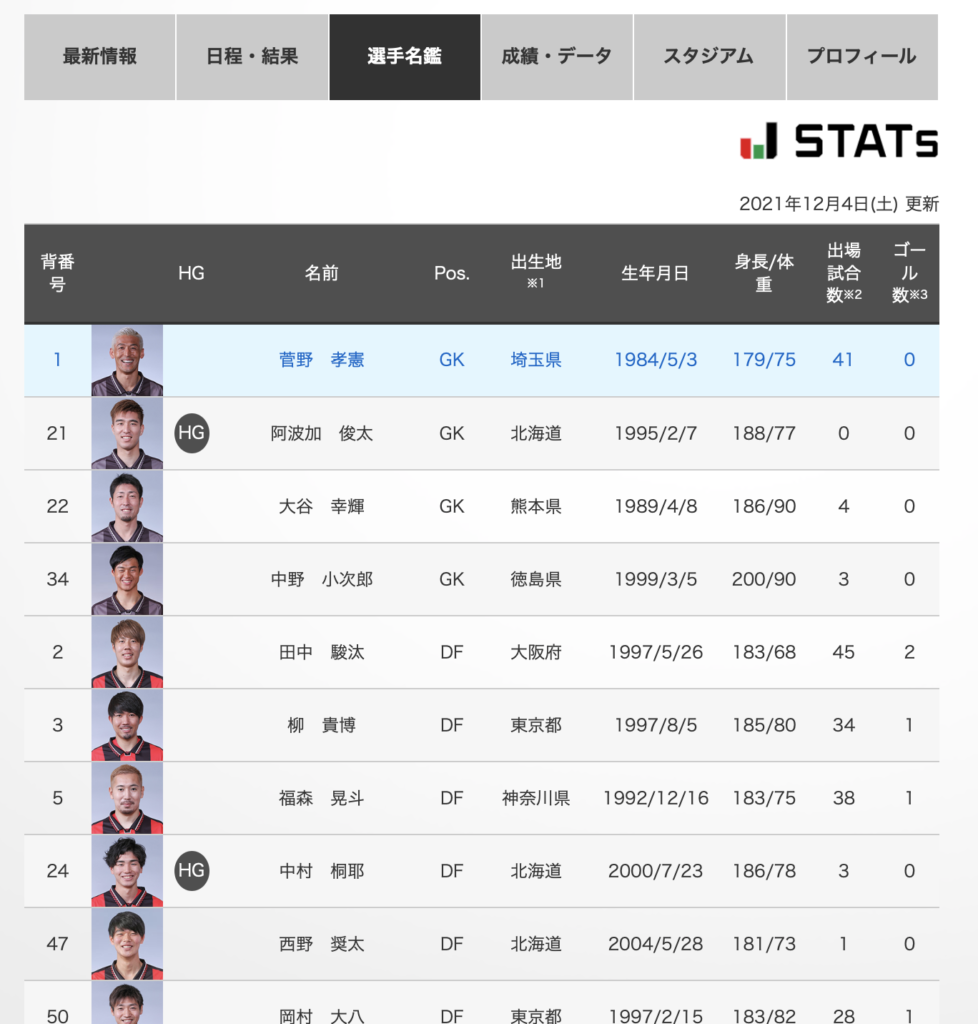
早速このデータを確認してみます。
1番上の菅野選手を検索してみます。
こちらのリンクをChromeで開いて、右クリックから検証を選択します。
ここで菅野選手を検索してみます。
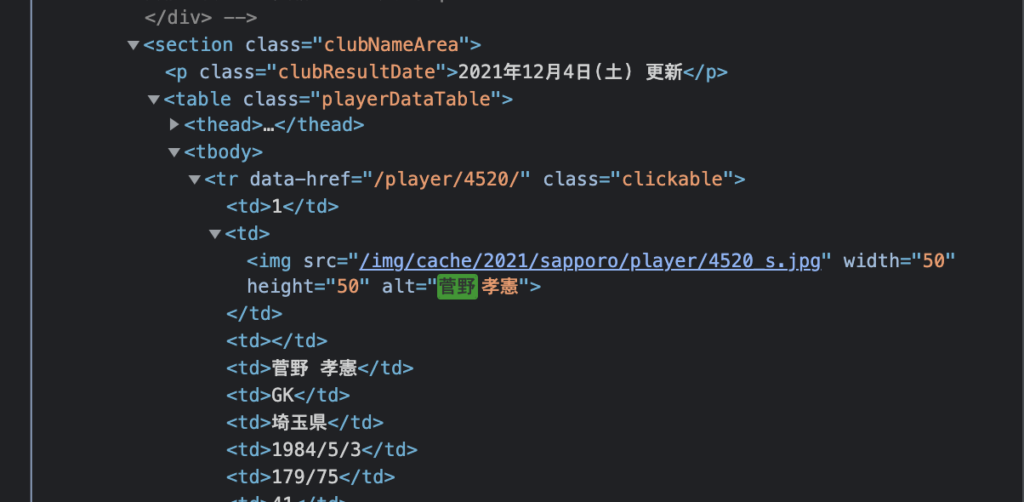
見つかりました。
同じ作業をスクレイピングでも行ってみます。
コードはシンプルです。
import requests from bs4 import BeautifulSoup url = "https://www.jleague.jp/club/sapporo/day/#player" r = requests.get(url) soup = BeautifulSoup(r.content, "html.parser")
このsoupの中身を確認してみると、菅野選手がどこにもないことが確認できます。
普通にURLにアクセスしてデータを取得しても、選手データは取得できません。
菅野選手に限らず、すべての選手データは空っぽになっています。
この要因がまさにAjaxです。
Chromeで消えた選手データを見つけ出す!
問題が確認できたところで、消えた選手データを探し出します。
これをするにはChromeの「検証」を活用します。
右クリックから「検証」をクリックすると、このようなソースコードを確認することができます。
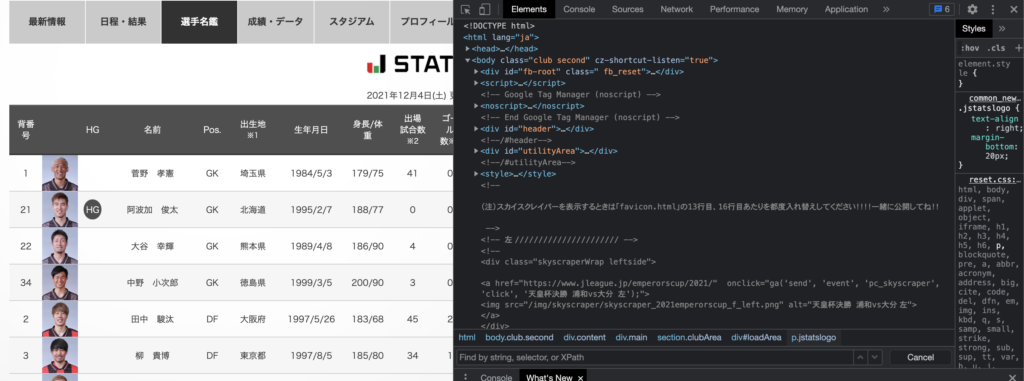
先ほどはここから選手データを確認することができましたが、Pythonでスクレイピングしたら確認できませんでした。
理由はAjaxを活用しているためです。
さらに細かくみていくためにNetworkを見てみます。
Networkを選択するとこんな画面に遷移します。
おそらく最初は何も表示されていません。
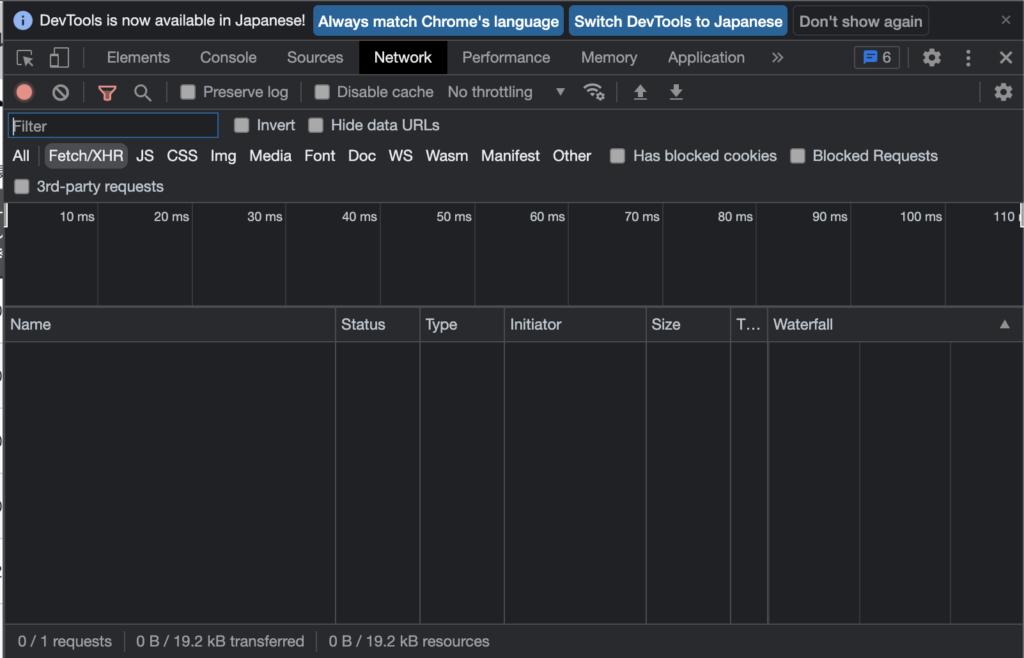
この状態でページを切り替えていくと、通信内容を細かくチェックすることができます。
例として、「選手名鑑」をもう一度クリックしてみます。
ここではFIlterをFetch/XHRとしていますが、Allにしたらもう少しここで表示されるデータ量が増えます。
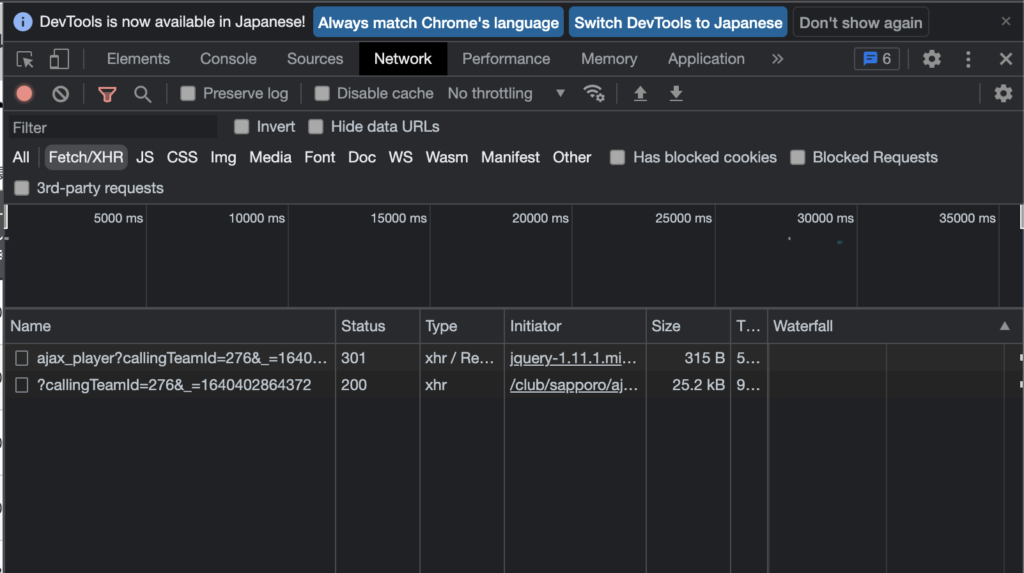
ここで表示されている最初のデータをクリックしてみると中身を確認できます。
Request URLとかStatus CodeとかHeader情報を確認できます。
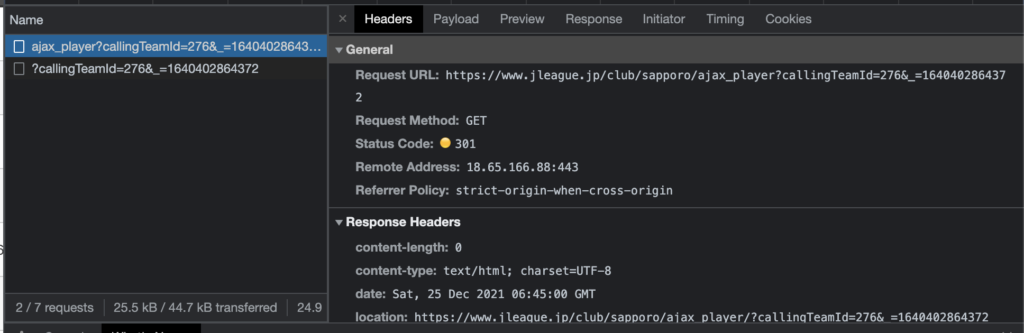
もう1つのデータも見てみます。
こちらはStatus Codeが200となっているので成功していますね。
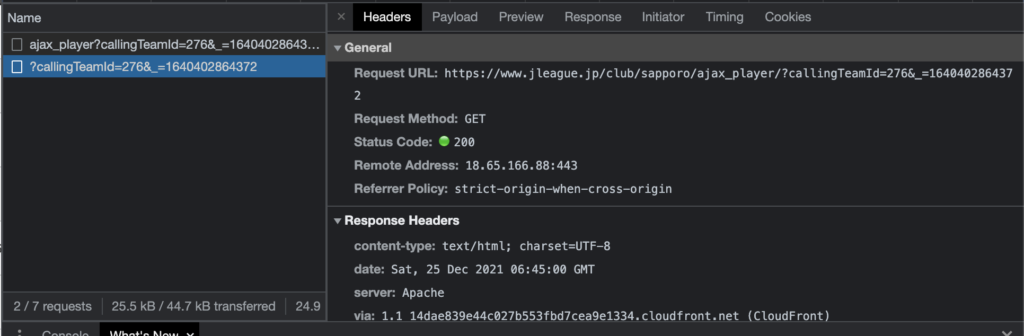
こちらのPreviewやResponseをみると、取得データを確認することができます。
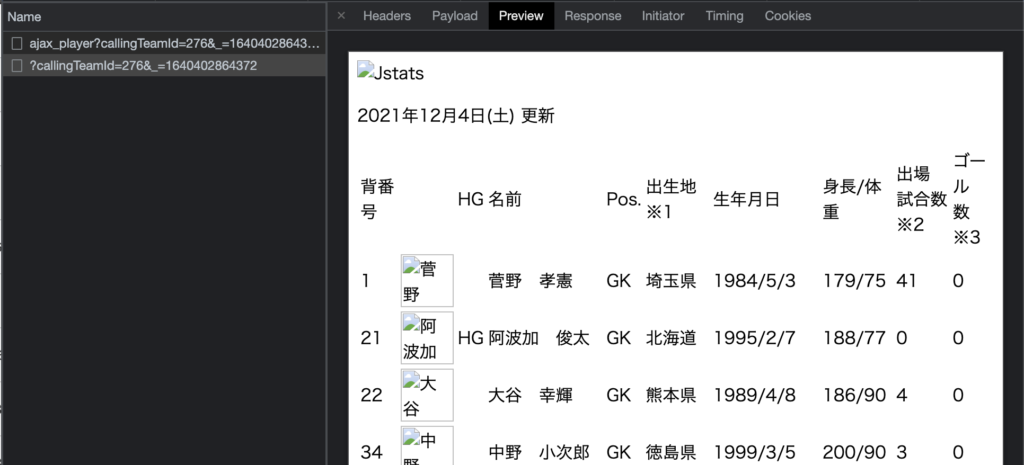
ここのデータを確認すると、先ほど取得することができなかった選手データがあることがわかります。
つまり、ここで取得されたデータが、サイト上で表示されているということになります。
選手一覧ページを開いた場合には、全体のページを開くために必要なデータを取得する通信と、この選手データを取得する通信は完全な別物として動いています。
Pythonのrequestsで取得したデータは、前者のデータしか取得することができないので、今回のような問題が発生します。
逆を言えば、後者のデータを別途取得することができれば、この問題は解決できます。
Pythonでデータを取得して確認する
最初のHeadersページからRequest URLをみてみると、次のURLであることが確認できます。
https://www.jleague.jp/club/sapporo/ajax_player/?callingTeamId=276&_=1640402864372
ここにアクセスすれば選手データが取得できるわけです。
実際にデータを取得して確認してみましょう。
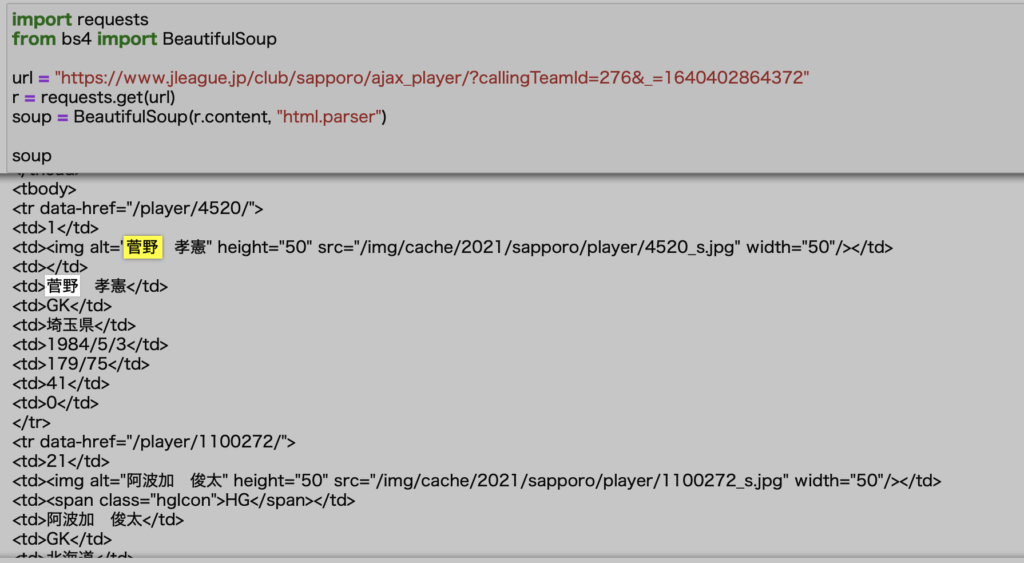
ご覧の通り、きちんと選手データが取得できていることが確認できます。
これで選手データの取得が可能であることがわかりました。
あとは各チームに対して同様の処理を繰り返せば全選手データを収集することができます。
ただ、ここで1つ問題があります。
それがURLに含まれる変数です。
もう一度URLを見てみます。
https://www.jleague.jp/club/sapporo/ajax_player/?callingTeamId=276&_=1640402864372
最後についてるcallingTeamId=276&_=1640402864372が変数です。
これを取得しないとURLをプログラムで自動生成することができません。
276はチームのIDっぽい感じがしますね。
コンサドーレ札幌のIDが276と思われます。
もう一つの1640402864372は謎です。。。
とりあえずこの手のURLを確認する際には、変数を少しずついじりながらどんな返答が返ってくるのかを確認するのがベストです。
まずは変数を全て消した状態できちんとデータを取得できるのかをみてみます。
これでうまくいけば一番楽ですね。ダメなら1つずつ変数をいじっていきます。
実際にデータを取得してみると、なんと変数なしでもきちんとデータが取得できてしまいましたw
「できるんかーい」と心の中で叫びましたw
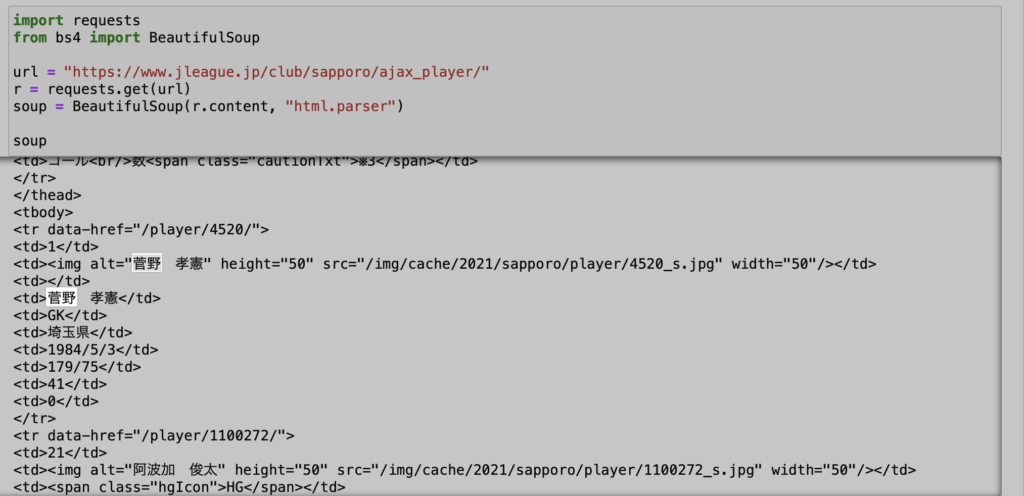
よって、今回の場合は変数なしのURLを指定すればOKということになります。
最後にajax_player/を追加すればOKですね。
選手データを収集する
これで選手データを取得する準備が整いました。
先ほどまでの流れで、選手一覧データまで取得できることが確認できました。
あとは選手1人ずつ取得していけばOKです。
取得結果を見ると、data-hrefというデータがあることがわかります。
これが選手データを見るためのURLです。
/から始まっているので、相対パスとなっています。
この場合はTOPドメインであるhttps://www.jleague.jpの後に続ければOKです。
実際にやってみます。
findAllですべてのtrを取得して、菅野選手に該当するデータを取得します。
trの1つ目はカラム名になるので、2つ目以降から選手データになります。
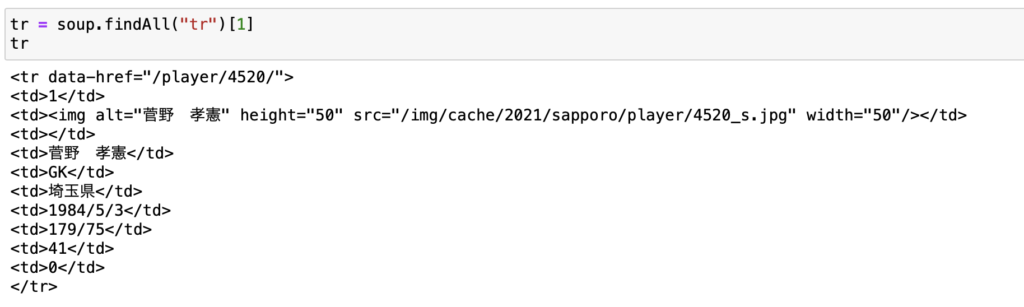
ここからdata-hrefを取り出します。
これをするにはgetで要素名を指定すればOKです。
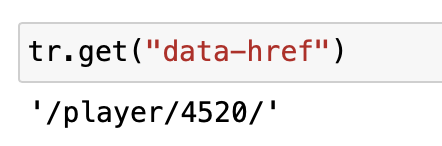
これをTOPドメインにくっ付ければURLが完成します。

このURLからデータを取得すれば選手の細かいデータが取得できるはずです。
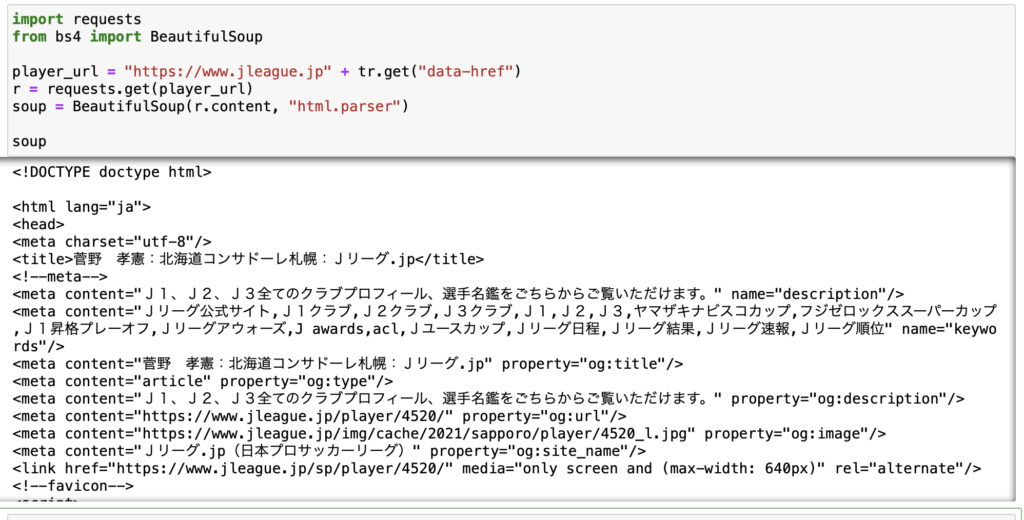
きちんとデータが取得できました。
Ajaxを突破するために必要なステップ
ここまでの内容をまとめます。
Pythonに関わらず、Webスクレイピングで、意図していたデータが取得できなかった場合は、Ajaxがその阻害要因になっている場合があります。
これをチェックするには、次のような手順を踏みます。
- Chromeの「検証」→「Network」を選び、取得したいデータが存在する通信を探し出す
- 見つかったらRequest URLを確認する
- URLに変数があった場合は、その変数が必要かどうかをチェックする
- 変数が必要な場合は変数が取れる場所を探す
今回のケースでは4は発生しなかったわけですが、もしあった場合にはさらにこの変数を取得する方法を考える必要があります。
例えば、今回のケースでいえばcallingTeamId=276とかです。
これが必須だった場合、どこから取得できるのか考えてみます。
いきなり答えから言ってしまうと、これは最初に選手データが存在しなかった「https://www.jleague.jp/club/sapporo/day/#player」で確認できました。
ここで検証をクリックして「276」を検索してみると、このように発見できます。
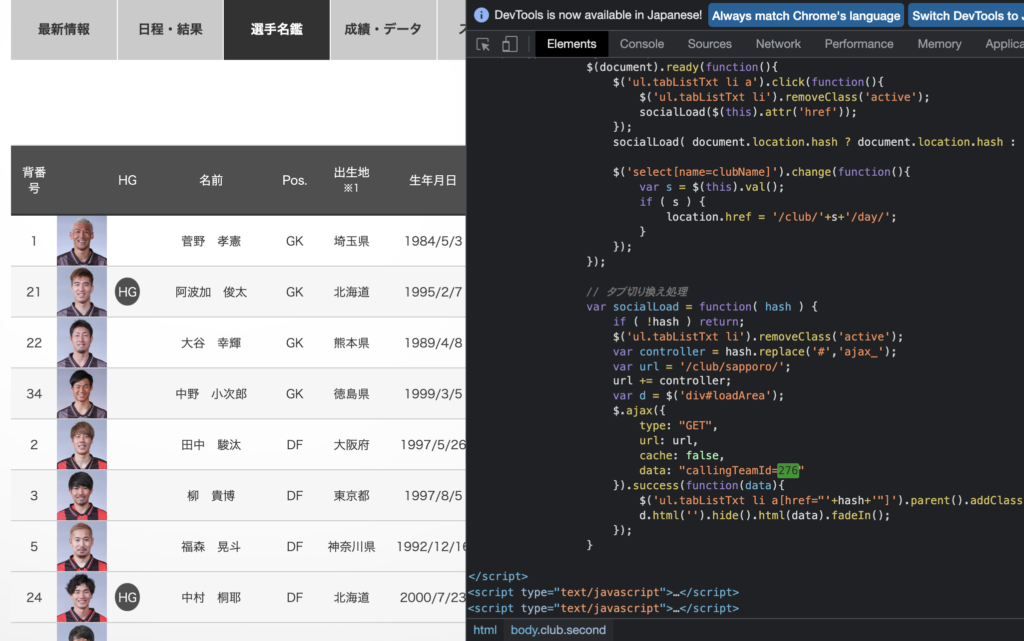
これを取得してURLを作ればよさそうです。
このように、変数が必要だった場合には少し厄介になりますが、不可能になるわけではありません。
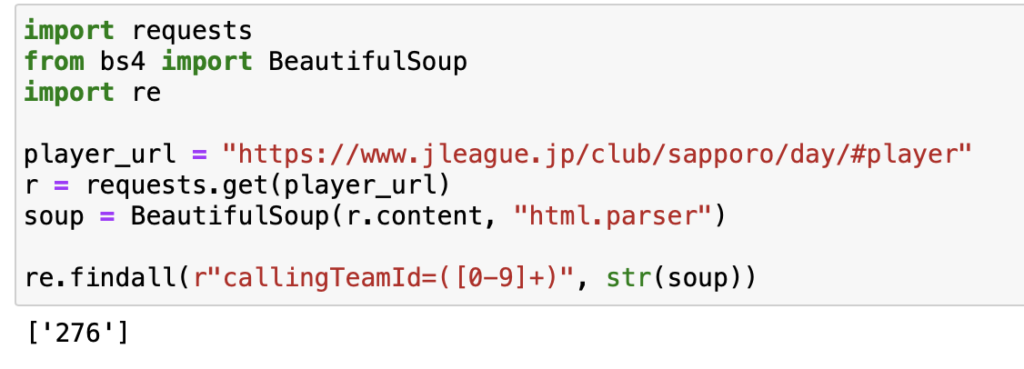
ちなみに、上記のようなJavascriptでデータが存在しているときは、これまでのように要素にアクセスしてデータを取得することができません。
この場合は正規表現などを活用して必要なデータを抽出することが必要になります。
正規表現は使いどころがたくさんあるので、是非とも知っておきたいスキルです。
他のPython解説記事を見ていると、こういった場合はSeleniumを使う必要がありますと言われたりしていることがありますが、本記事で解説した通り、Selniumなしでも突破可能です。
ちなみにSeleniumを使うと動作がめっちゃ遅くなるので、なるべくSeleniumなしでプログラムを実装できた方が良いです。
WebスクレイピングにはPythonが最適です。
ここまで解説してきたように、Pythonを使うと短いコードでわりと簡単にデータの収集や分析をすることができます。
PythonはWebスクレイピングやデータ分析、AI関連に強くて、世界中で人気を集めている言語です。
すっきりとしたコード体系で、誰でもきれいなコードが書けるような設計になっています。
過去の記事では、データ分析としてPythonをご紹介している記事や、Pythonでできることをまとめたものがありますので、もしPythonにご興味があれば合わせてご覧ください。
僕自身も社会人になってからPythonを独学しました。それくらい学びやすい言語でもあります。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
まとめ
いかがでしたでしょうか。
ここでは「WebスクレイピングでAjaxを突破してデータを取得する」というテーマで解説してきました。
Webスクレイピングの中では少し難易度が高い方法になりますが、使いこなせるようになるとデータ取得の幅が大きく広がります。
一般に、今回のようなケースの場合は、Seleniumを使ったスクレイピング方法を解説している記事も散見されますが、本記事で解説した通り、Seleniumなしでも突破できます。
Seleniumを使うと動作が遅くなりがちなので、なるべくSeleniumなしで実装できた方が良いです。
本記事で例として取り上げたJリーグデータについては、分析結果をこちらの記事で紹介しているのでもしご興味があれば合わせてご覧ください。
-
【Sorare攻略大作戦】Jリーグの全選手データを収集して分析する【Pythonでデータ分析】
続きを見る
ここまで読んでくださり、ありがとうございました。




{kind=link}