

こんにちは。TATです。
今日のテーマは「Pythonで楽天トラベルをスクレイピングして収集したデータを整形する」です。
前回の記事では、Pythonで楽天トラベルをスクレイピングする方法をご紹介しました。
関連記事: Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた
今日はこの続きで、収集したデータを整形して綺麗にする作業を行っていきます。
特にスクレイピングで収集したデータは、そのままデータ分析を利用できるケースはあまりなくて、型変換をしたり不要なデータを置換したりカラムを追加したり削除したり、いろいろな前処理作業が必要です。
本記事ではこの前処理に焦点を当てて解説していきます。
利用したコードは全て公開するので参考になれば嬉しいです。
apply関数とかを駆使すれば短いコードでサクッとデータ整形できてしまうので便利です。
事前確認
まずは事前確認として収集データを確認しておきます。
収集データ
使用するデータがこちらの記事で収集したものです。
-

Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた
続きを見る
こちらの記事では、スクレイピングで楽天トラベルからデータを収集して次の2つのデータセットを作りました。
データセット
- df_base: 各ホテルのアクセス情報とレビュー情報をまとめたもの
- df_plan_room: 各ホテルのプラン名と部屋情報(広さとか価格とか)をまとめたもの
データの確認
データは2022年9月22日夜に収集したものです。
df_base
df_baseはこんな感じです。

ホテル名をはじめ、住所やアクセス、レビューデータがまとまっています。
df_room_plan
そしてdf_room_planがこちらです。

プラン名やルームタイプ、食事や人数、価格などの情報がまとまっています。
前処理に必要な作業を整理する
これらのデータは、このままの状態だと分析に利用することは難しいです。
数値データが文字列として扱われていたり、不要なデータが含まれていたり、文字列でデータがぐちゃっとまとまっていたりするので、これらの綺麗にしてあげる必要があります。
データ分析を行うには、このデータ整形(前処理と言われます)が重要になってきます。
そして場合によっては、この作業が最もめんどくさいです。。。
実施するデータ整形作業をまとめる
それでは今回行う作業をまとめます。
df_baseとdf_room_planでそれぞれ次の作業を行っていきます。
データ整形作業
df_base: アクセス情報やレビューデータをまとめたデータセット
- 住所を郵便番号を抽出
- 住所から区を抽出
- レビューデータの諸々のカラムを数値データに変換
df_plan_room: プラン名や部屋に関する情報をまとめたデータセット
- 食事を朝食と夕食で分ける
- 面積から平米数を抽出
- 人数を数値に変換
- 価格を最低価格と最高価格で分けて、さらに中間値も計算
上記の処理をPythonを使って行っていきます。
Pythonでデータ整形を実装する
それでは必要な作業が確認できたところで、ここからはPythonを使ってデータ整形を行っていきます。
必要なコードも公開していくので参考にしていただければと思います。
df_base: アクセス情報やレビューデータをまとめたデータセット
まずはdf_baseのデータ整形から行っていきます。
実装する作業は次の通りです。
データ整形作業
- 住所を郵便番号を抽出
- 住所から区を抽出
- レビューデータの諸々のカラムを数値データに変換
順番に見ていきましょう。
住所を郵便番号を抽出
まずは住所から郵便番号を抽出してみます。
reで正規表現を使うと便利です。
import re
def extract_postal_code(x):
x = x.replace("‐", "")
pattern = r"[0-9]{7}"
return re.findall(string=x.replace("-", "").replace("‐", ""), pattern=pattern)[0]
df_base["郵便番号"] = df_base["住所"].apply(extract_postal_code)
df_base["郵便番号"].head()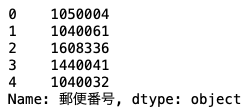
extract_postal_codeという関数を定義して、apply関数で実装しました。
extract_postal_code内では、不要な単語を削除して、reを使って郵便番号を抽出しています。
データを見ると、郵便番号には途中のハイフンがあるものとないものがありました。
ここではハイフンを削除して、7桁の数字を抽出することで郵便番号を取り出しています。
取り出したデータを"郵便番号"というカラムに格納すればOKです。
住所から区を抽出
次に住所から区を取り出します。
def extract_word(x):
for word in ["-", "〒", "東京都"]:
x = x.replace(word, "")
# remove postal code
x = re.sub(pattern=r"[0-9]{7}", string=x, repl="")
matched_words = re.findall(string=x.split("東京都")[-1], pattern=r".*?区")
if len(matched_words) > 0:
return matched_words[0]
else:
return np.nan
df_base["区"] = df_base["住所"].apply(extract_word)
df_base["区"] = df_base["区"].fillna("台東区")
df_base["区"].head()
extract_wordという関数を定義してapply関数を適用しました。
住所の構成を見ると、郵便番号が最初にきて、その後に東京都◯◯区〜という形式になっています。
したがって、冒頭の郵便番号と東京都を削除して、残った文字列から正規表現を使って◯◯区を抽出しています。
抽出した結果に値があれば返して、なければNaNを返します。
住所データを見ると、1つだけ区が含まれていないデータがありました。

住所を調べたら台東区だったので、fillnaを使って、NaNになってるデータを台東区に置き換えました。
これで「区」カラムの完成です。
レビューデータの諸々のカラムを数値データに変換
次にレビューデータを諸々数値データに変換します。
不要な文字列(「件」とか「,」とか)を削除して、floatに変換します。
for col in ['アンケート件数', '5点', '4点', '3点', '2点', '1点']:
df_base[col] = df_base[col].apply(lambda x: float(str(x).replace("件", "")))
for col in ['総合', 'サービス', '立地', '部屋', '設備・アメニティ', '風呂', '食事']:
df_base[col] = df_base[col].replace("-----", np.nan)
df_base[col] = df_base[col].astype(float)
点数のカラムは一見すでに数値データになっているように見えましたが、よく見ると値がないものは"-----"となっており、文字列として扱われていました。
よって、"-----"をNaNに置き換えたうえで、floatに変換しています。
これで数値データへの変換が完了です。
型変換したカラムの冒頭5行だけ確認しておきます。
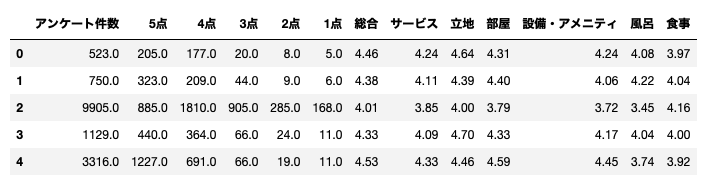
バッチリですね。
最後にデータを確認
以上で、df_baseのデータ整形は完了です。
最後にデータをあらためて確認しておきます。
余計なカラムは排除して冒頭5行だけを表示しました。
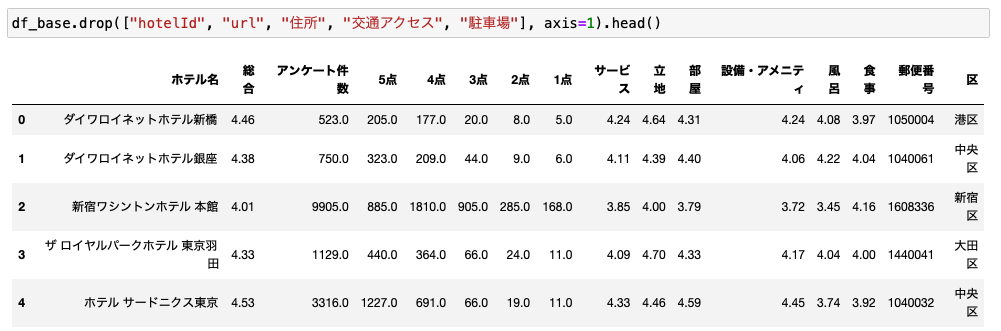
あとは住所から最寄駅とか徒歩の所要時間とかを抽出しても面白い分析ができると思います。
ただ、今回は以上で作業完了とします。
df_plan_room: プラン名や部屋に関する情報をまとめたデータセット
次にdf_plan_roomのデータ整形を行っていきます。
必要な作業を確認します。
データ整形作業
- 食事を朝食と夕食で分ける
- 面積から平米数を抽出
- 人数を数値に変換
- 価格を最低価格と最高価格で分けて、さらに中間値も計算
それでは順番に実装していきます。
食事を朝食と夕食で分ける
まずは「食事」カラムから朝食と夕食のカラムを作ってみます。
df_plan_room["朝食"] = df_plan_room["食事"].apply(lambda x: True if "朝食あり" in x else False) df_plan_room["夕食"] = df_plan_room["食事"].apply(lambda x: True if "夕食あり" in x else False)
これはとてもシンプルです。
「朝食あり」とあればTrue、なければFalseとすればOKです。
夕食も同じロジックを適用すればOKです。
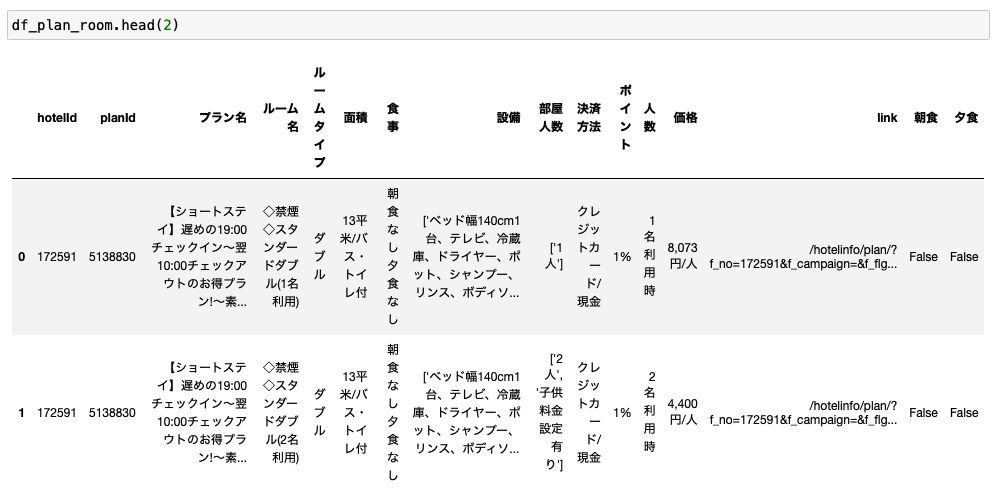
バッチリですね。
面積から平米数を抽出
次に「面積」カラムから平米数を抽出します。
データを確認すると、平米と畳の2種類の記載がありました。
1畳の広さは地域によって異なってきますが、ここでは1畳=1.62平米として計算しました。
df_plan_room["面積(平米)"] = df_plan_room["面積"].apply(lambda x: re.findall(string=x, pattern=r"[0-9.]+")[0] if len(re.findall(string=x, pattern=r"[0-9.]+"))>0 else np.nan) df_plan_room["面積(平米)"] = df_plan_room.apply(lambda x: float(x["面積(平米)"])*1.62 if "畳" in x["面積"] else float(x["面積(平米)"]), axis=1)
まず「面積」カラムから数値データを抽出します。
次に、「面積」に"畳"が含まれていたら抽出した数値に1.62を掛け、含まれていなければ抽出した値をそのまま返せばOKです。
きちんと変換できていることが確認できます。

そして広さが畳で記載されている部分についてもきちんと計算できていることが確認できます。

これで部屋の広さを平米数で統一することができました。
人数を数値に変換
次に「人数」カラムを数値データに変換します。
これはシンプルに数値を抽出してintに変換すればOKです。
df_plan_room["人数"] = df_plan_room["人数"].apply(lambda x: re.findall(string=x, pattern=r"[0-9]")[0]) df_plan_room.head(2)

人数のカラムが数値に変換されました。
価格を最低価格と最高価格で分けて、さらに中間値も計算
最後に「価格」から最低価格と最高価格を抽出して、さらにそれらの中間値(平均)を計算します。
df_plan_room["価格"] = df_plan_room["価格"].apply(lambda x: x.replace(",", "").replace("円/人", "").replace("円/室", "").split("~"))
df_plan_room["最低価格"] = df_plan_room["価格"].apply(lambda x: float(x[0]))
df_plan_room["最高価格"] = df_plan_room["価格"].apply(lambda x: float(x[-1]))
df_plan_room["中間価格"] = df_plan_room[["最低価格", "最高価格"]].mean(axis=1)
まず、「,」や「円/人」などの不要な文字列を削除します。
そして「~」でスプリットしてリスト形式にします。
リストの最初が最低価格、最後は最高価格です。
これらを平均したものが中間価格になります。

「最低価格」、「最高価格」、「中間価格」の3つのカラムが追加されました。
以上で、df_plan_roomのデータ整形が完了しました。
最後にデータを確認
最後にデータ整形が完了したデータを確認しておきます。
不要なカラムは排除して冒頭の5行だけを表示します。

いい感じです!
これでやっとデータ分析の準備が整いました。
まとめ
本記事では、「Pythonで楽天トラベルをスクレイピングして収集したデータを整形する」というテーマで、前回の記事で収集した楽天トラベルのデータをPythonを使ってデータ整形する方法について解説しました。
特にスクレイピングで収集したデータは、そのままデータ分析に使えることはあまりありません。
不要な文字列が含まれていたり、まだまだ汚いデータが多いです。
データ分析を行うためには、前処理が必要です。
前処理はデータ分析の工程の中で最もめんどくさい作業になることもあります。
ただ、ここをしっかりとやっておかないときちんと分析の作業ができなくなるので、必須の作業です。
ややこしい作業が発生しますが、Pythonであれば数行のコードで処理することができます。
特に正規表現を扱えるreや、カラム単位で一括処理ができるapply関数などを扱えるとかなり便利です。
本記事ではreやapplyを乱用してきましたが、参考になれば嬉しいです。
やっぱりPythonは便利ですね。Pythonに慣れてしまうとExcelでデータ処理とかもう無理な体になってしまいますw
前回記事のスクレイピングに続いて、本記事でデータ整形が完了して、ようやくデータ分析ができるデータセットが出来上がりました。
長い道のりでしたw
次回からは、いよいよいろいろとデータ分析をしてみようと思います。
とりあえず今回はここまで。
最後まで読んでくださり、ありがとうございました。
関連記事: Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた




{kind=link}