
こんにちは。TATです。
今回のテーマは「Pandasを使ったデータ集計」です。
Pandasはデータ分析用のPythonライブラリーで、データ分析に便利な関数がてんこ盛りです。
ここでは例として過去の記事でも登場したKaggleのポケモンのデータセットを使って解説していきます。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
Pandasを利用すると、Excelでできるようなデータの集計を簡単に行うことができます。
値ごとにグルーピングして、それぞれの平均値を計算したり、最大値や最小値を見つけたり、Excelでできるような計算はほとんどPandasのライブラリーでできると思っていただいて問題ありません。
そして、Pandasであれば、こういった作業がほんの数行で完了します。
さらにExcelでは100万行(今は変わってるのかな?)までの行数制限がありますが、PythonであればPCのスペックが許す限りいくらでもいけます。
そこまででかいデータを扱うことはなかなかないかもしれませんが、Pythonを扱うことができればかなり便利になります。
目次
【Pythonコード解説】Pythonでポケモンのデータセットを集計する

データの準備
まずはデータの準備です。
データはKaggleから取得
今回利用するポケモンのデータセットはKaggleから取得できます。
ポケモンのデータはこちらになります。
データを取得するには無料の会員登録が必要になります。
Pandasでデータを読み込む
ダウンロードしたデータ(CSVファイル)をPandasで読み込めば、データ分析を開始することができます。
今回は、ポケモンの日本語名を取得して、メガ進化などうまく翻訳できなかったデータは排除したものを使います。
このやり方については過去記事で解説しています。
-

【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
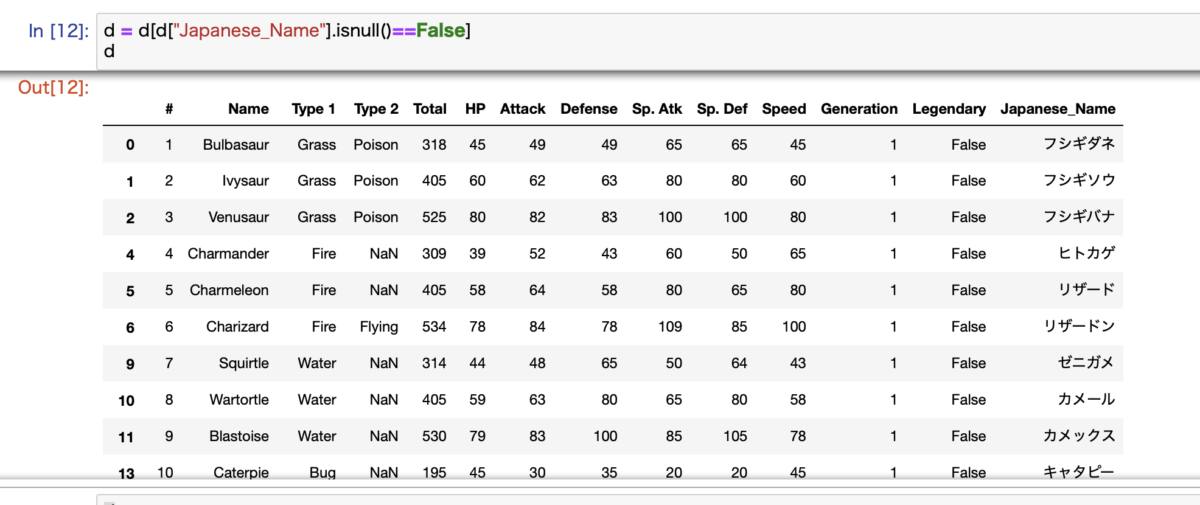
用意したデータがこちらです。
もともとは800行のデータがありましたが、メガ進化などのデータを排除したら95行が排除されて705行のデータになります。
データの概要を把握できるdescribe関数
ここからデータを集計するために役立つ関数を解説していきます。
まずはdescribe関数です。
過去の記事でもなんども登場しているお馴染みの関数です。
データ全体を把握できる
describe関数を使うと、データ全体を把握することができます。
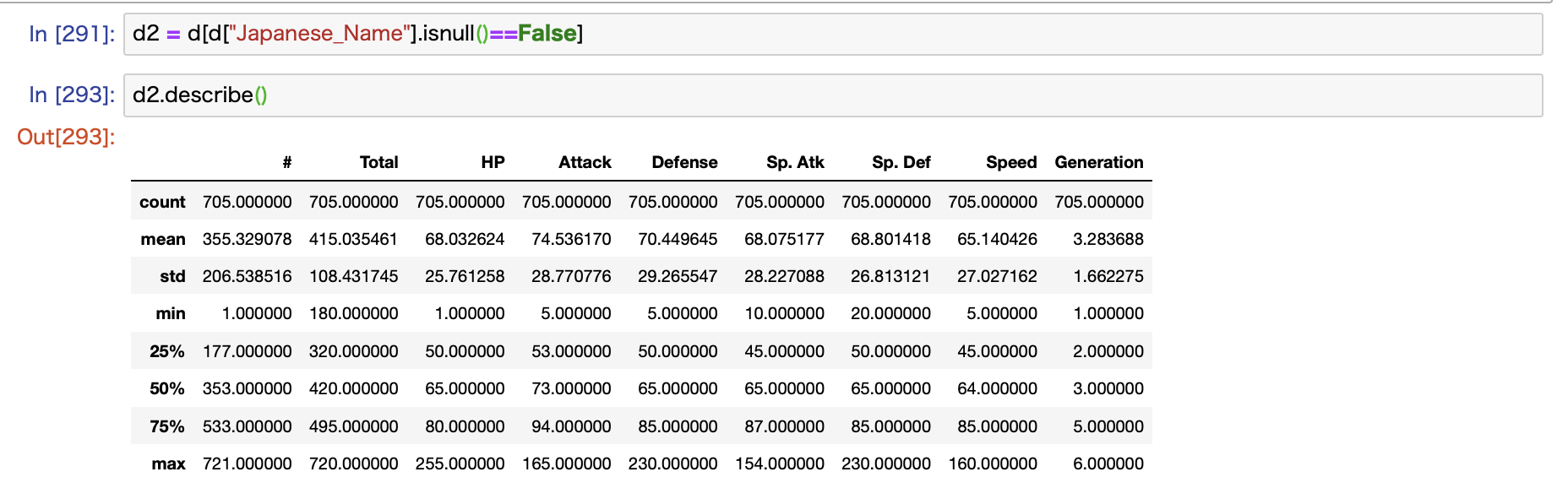
実際にお見せした方が早いので、まずは表示されるデータを見てください。
基本的な統計データが計算されます。
表示されるデータは次の通りです。
- データ数
- 平均
- 標準偏差
- 最小値
- 第一四分位数(25%)、第二四分位数(50%)、第三四分位(75%)
- 最大値
平均値を把握しつつ、標準偏差でデータのばらつき具合を確認することができます。
これだけでなんとなくデータ全体の雰囲気がつかめます。
第二四分位数は中央値と同じです。
最小値、最大値、第一四分位数(25%)、第二四分位数(50%)、第三四分位(75%)から、データのヒストグラムをイメージすることができます。
データ分析を行う際には、まずはこのdescribe関数を使ってデータ全体の概要をつかみます。
ポイント
describe関数を使ってデータ全体を把握する
数値データじゃないと計算されません
そしてデータ集計を行う際に1つだけ注意点があります。
それは、数値データじゃないと計算されないということです。
当たり前のことなのですが、データをきちんとみると数値データに見えるけど実際は文字列という場合もよくあります。
特にCSVから読み込んだデータやスクレイピングで収集したデータは数字でも文字列として扱われていることがあるので注意が必要です。
スクレイピングで取得したデータは基本的に文字列です。
期待していたデータが集計されていない場合は、データの型をチェックしてみてください。
ポイント
計算されない場合はデータの型をチェックする
info関数でデータの型をチェックする
各カラムのデータの型については、info関数で確認できます。
describe関数と一緒に使ってデータを確認するとミスが減ります。
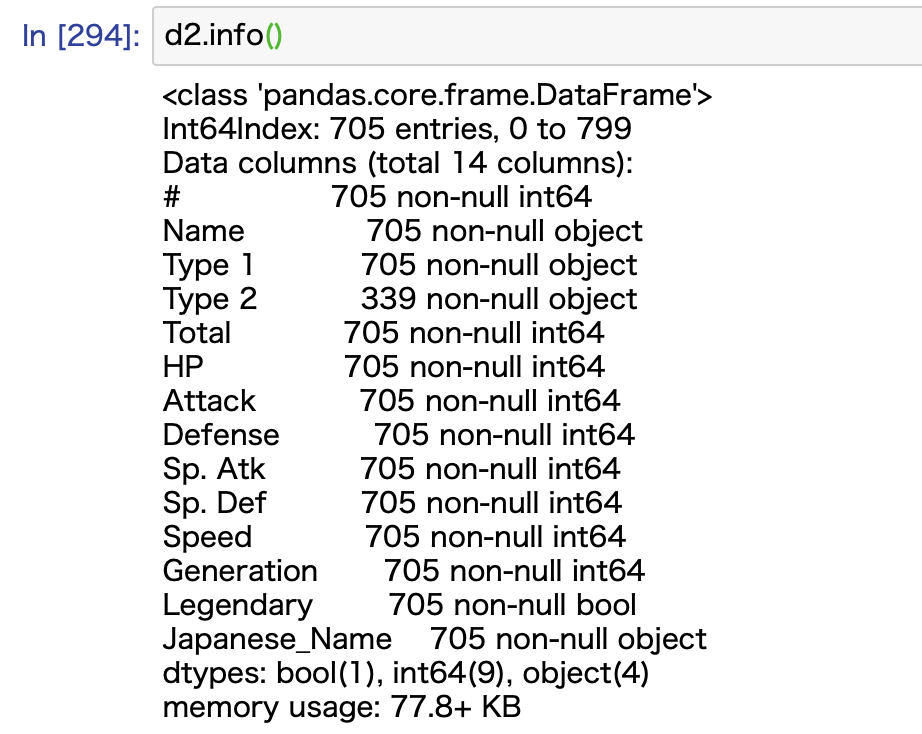
intとかfloatが計算できるデータ型になります。
文字列の集計
あまり使わないかもですが、次に文字列データの集計についてもみておきます。
データ数をチェックするならvalue_counts()
文字列の集計を行うなら value_counts関数が便利です。
これはカラムごとで使用して、各値の個数をカウントしてくれます。
結果は個数が多い順に表示されます。
例としてType 1をカウントしてみます。

この場合は水タイプが最も多く、ひこうタイプが一番少ないことが1発で確認できます。
重複を排除するならunique関数
次に重複したデータを排除した結果を表示してみます。
これにはunique関数を使います。
名前の通りですね。
これを使うと重複データは削除されて表示されます。
先ほどと同様にType 1に使ってみます。

重複しているデータが排除されていることがわかります。
データ集計にはgroupby関数が便利
最後に、Pandasによるデータ集計で最も利用される(と個人的に思ってる)groupby関数について解説します。
これは例えば、Type 1ごとに数値データを集計して平均値を出したり最大値、最小値を計算することができます。
エクセルでもできるような計算が、Pythonなら数行でできます。
1つのカラムを指定して集計する
まずは基本的な使い方として1つのカラムを指定してデータを集計してみましょう。
ここでは、Type 1で集計します。
Type 1の値ごとに集計してくれます。
ここではType 1の平均値を計算しています。
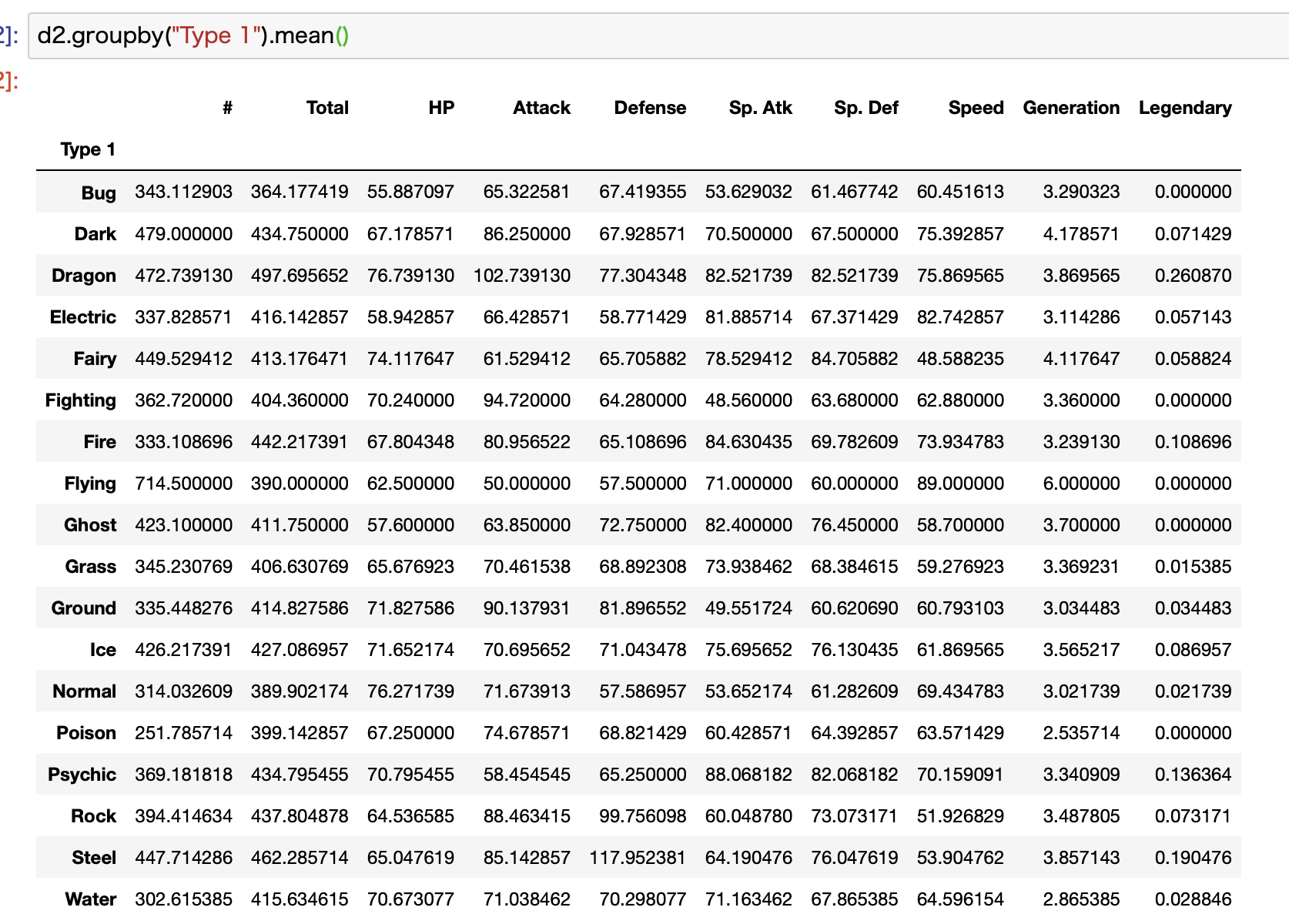
mean()が平均値を意味しています。
これをmax()に変更すると最大値、min()で最小値、std()で標準偏差、count()でデータ数、median()で中央値を計算することができます。
複数のカラムを指定して集計する
先ほどの例ではType 1で集計しましたが、複数のカラムを指定することも可能です。
この場合はリストで表記します。
例としてType 1とLegendaryで集計するとこんな感じになります。
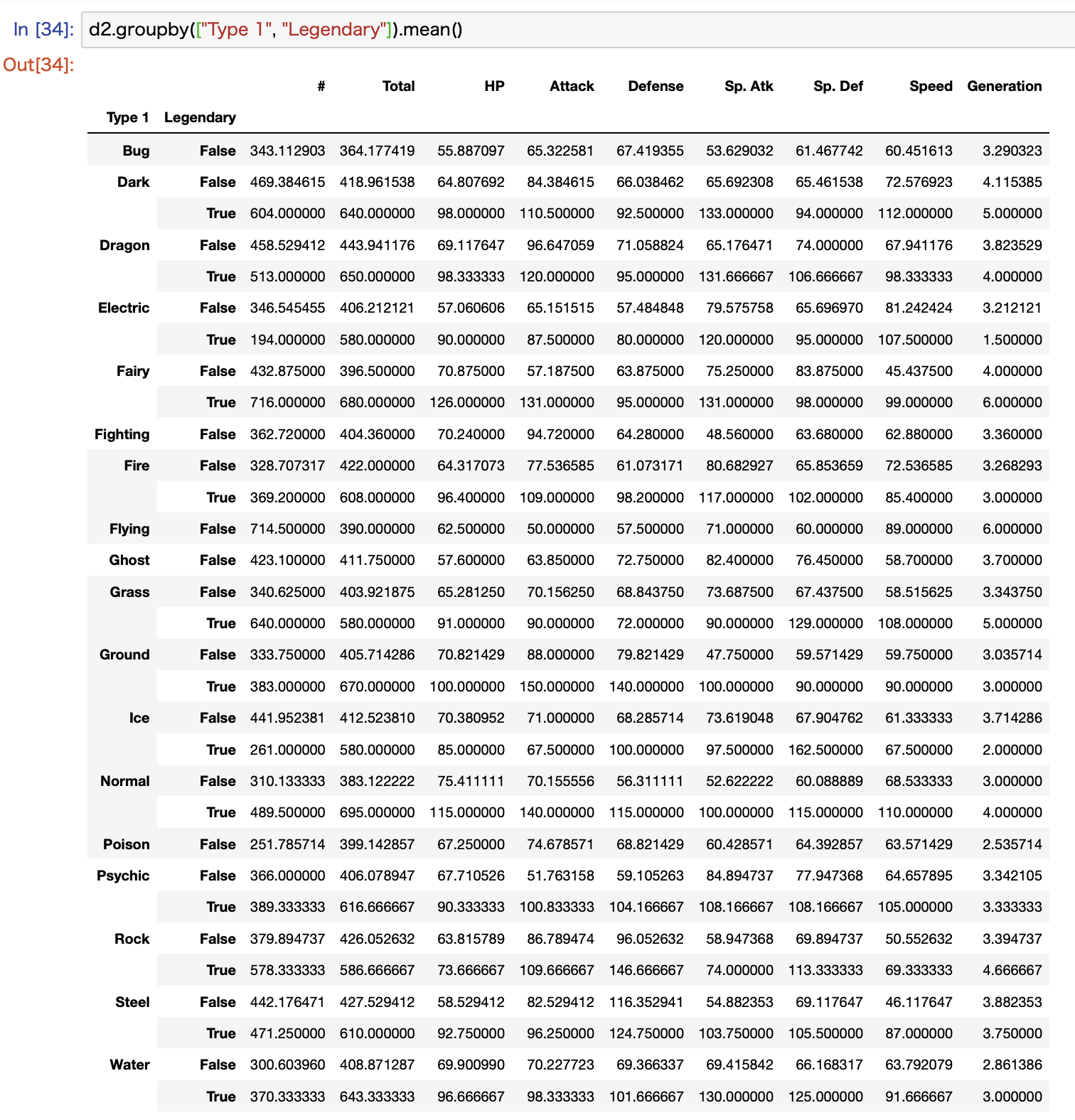
Type 1でグルーピングされて、さらにLegendaryのTrueとFalseでそれぞれ集計されていることがわかります。
agg関数で特定のカラムごとに計算する
次に特定カラムのみを計算する方法をご紹介します。
全てを計算してから必要なカラムだけを取り出すのもありですが、もっとスマートに行うにはagg関数を使うと便利です。
これを使えば、計算するカラムを指定できるだけではなく、カラムごとに計算方法を指定することができます。
例として、Type 1でグルーピングして、Totalでは平均値、HPでは最大値を計算してみます。
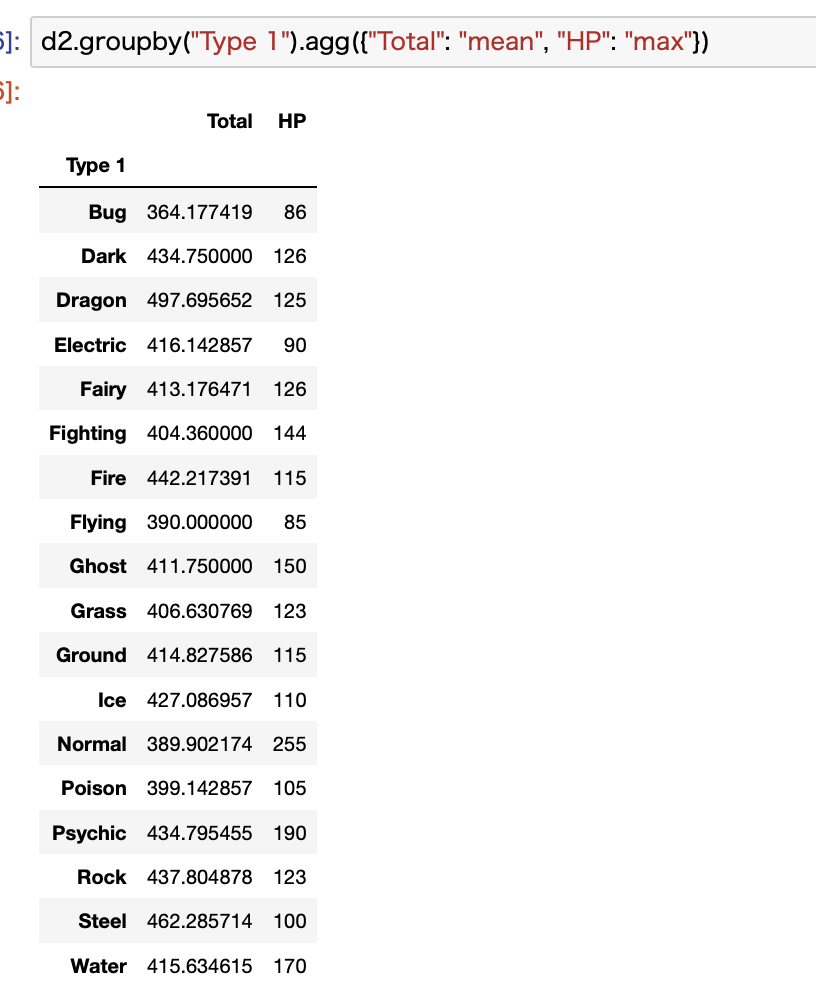
上記の通りで、agg関数を使う際には、カラムと計算方法を辞書型で指定します。
agg関数で1つのカラムに対して複数の計算をする
そしてagg関数を使えば、カラムごとに複数の計算を指定することも可能です。
この場合はリストで指定します。
例として、Type 1でグルーピングしてTotalでは平均値と標準偏差、HPでは最小値と最大値を計算してみます。
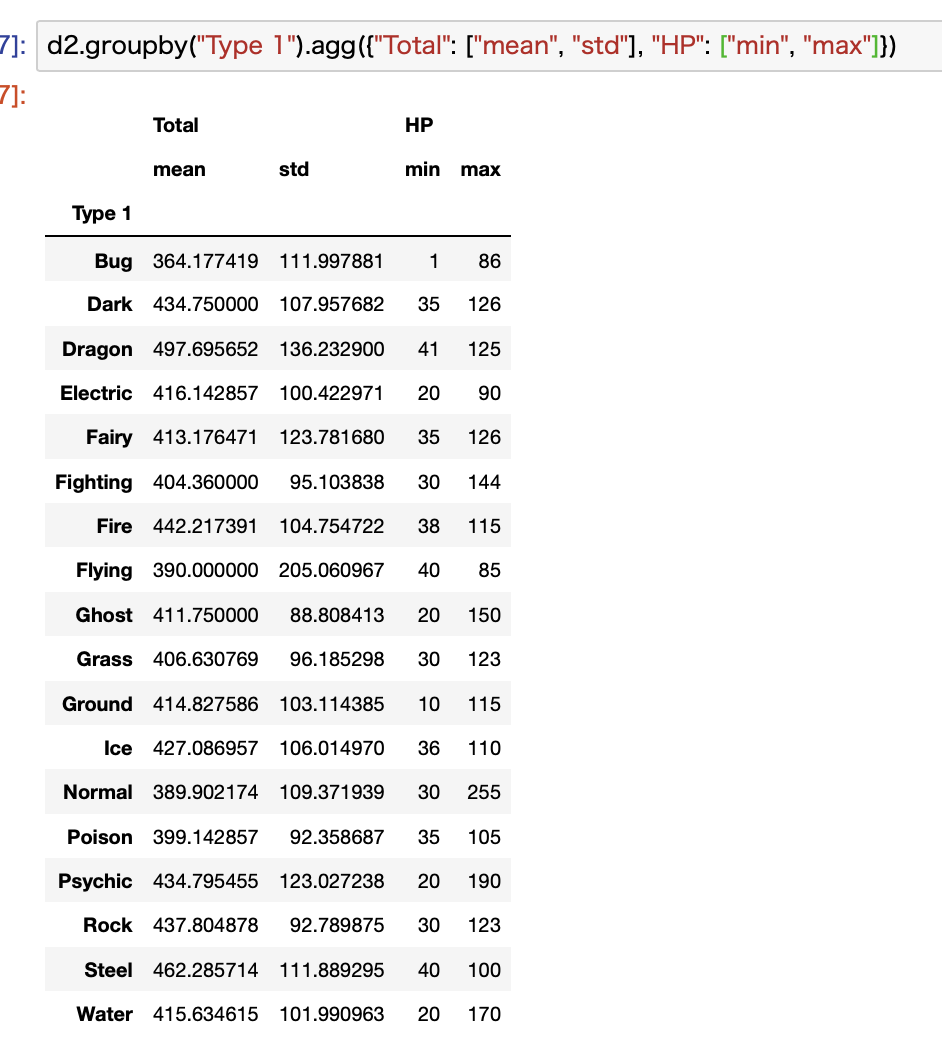
複数の計算方法を指定した場合には、上記の通りマルチインデックスになります。
agg関数はgroupby関数なしでも使えます
ここまでgrouoby関数と組み合わせて紹介してきましたが、agg関数は単体でも利用可能です。
こんな感じで全カラムで計算することもできれば、カラムを指定して計算方法を指定することも可能です。
この場合は指定した計算方法がindexになります。
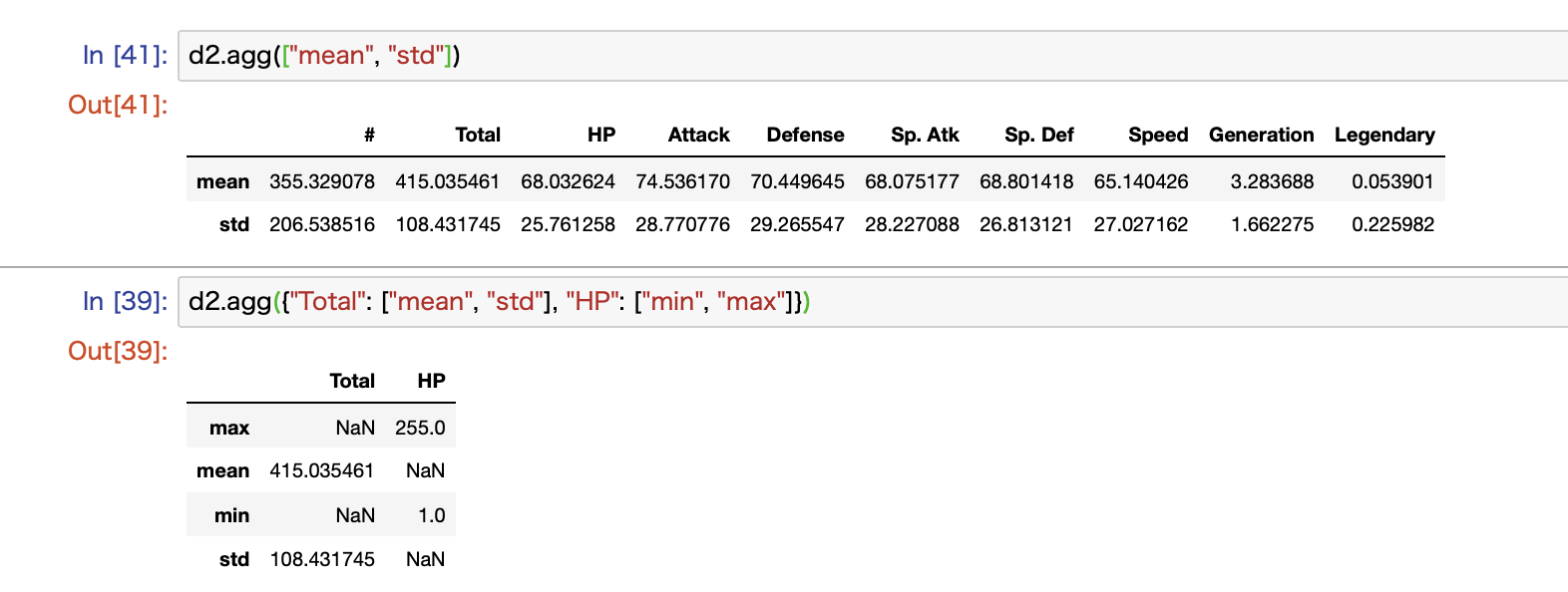
カラムごとに別々の計算方法を指定した場合には、指定されていない箇所はNaNになります。
以上で、Pandasを利用したデータ集計の解説はおしまいです。
データ分析にはPythonが最適です
ここまで紹介してきたように、Pythonを使うと複雑な計算処理もシンプルなコードで一瞬で計算することができます。
Pythonはデータ分析やAI関連に強くて、世界中で人気を集めている言語です。
すっきりとしたコード体系で、誰でもきれいなコードが書けるような設計になっています。
過去の記事では、データ分析としてPythonをご紹介している記事や、Pythonでできることをまとめたものがありますので、もしPythonにご興味があれば合わせてご覧ください。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
まとめ
いかがでしたでしょうか。
ここでは、ポケモンのデータセットを題材にPythonのPandasを使ったデータ集計の方法について解説しました。
普段はエクセルなどで計算している方も多いかと思いますが、Pythonであれば複雑な処理でも数行のコマンドで一瞬で計算することができます。
エクセルでは行数に制限があるので大きなデータセットを扱うことはできませんが、Pythonなら問題なしです。
効率よくデータ分析するならPythonが最適です。
今後もこういったPythonのコード解説に関する記事を増やしていければと思います。
次は、ポケモンのデータセットを使って、データの可視化にフォーカスしてコード解説記事を書こうと思っています。
ここで紹介した集計データを可視化することで、ただの数値の羅列よりもかなりデータの傾向や特徴がわかるようになります。
ここまで読んでくださり、ありがとうございました。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-
【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
-
【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-
【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】




{kind=link}