
こんにちは。TATです。
今日のテーマはPythonの辞書の作成です。
ある単語を投げたらそれに対応する単語が返ってくるイメージですね。
ここでは、例としてポケモンの名前の英和辞典を作ってみます。
以前、ポケモンのデータセットを分析する記事を書きました。
ここで利用したデータセットは英語だったので、日本語に変換する必要があったんですね。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
ここではその工程をコード付きで解説していきたいと思います。
ついでにデータをスクレピングするコードとか、ちょっとしたテクニックとかも解説していこうと思います。
目次
【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る

1. Kaggleのポケモンデータセット
まずは今回利用させていただくデータを紹介しておきます。
以前の記事でも書いたKaggleのポケモンのデータセットです。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
データはKaggleからゲット
今回用いたポケモンのデータの入手元はKaggleというサイトです。
データ分析のコンペとかを開催しているサイトで、データ分析のお勉強にはうってつけの場所です。
そして今回使ったポケモンのデータはこちらになります。
データを取得するには無料の会員登録が必要になります。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
データを確認する
次に取得したデータを確認します。
CSVデータを読み取るにはpandasのread_csvを使います。
最初の5行だけを確認するとこんな感じで、名前とかタイプとか攻撃力とかのデータが揃っていることがわかります。
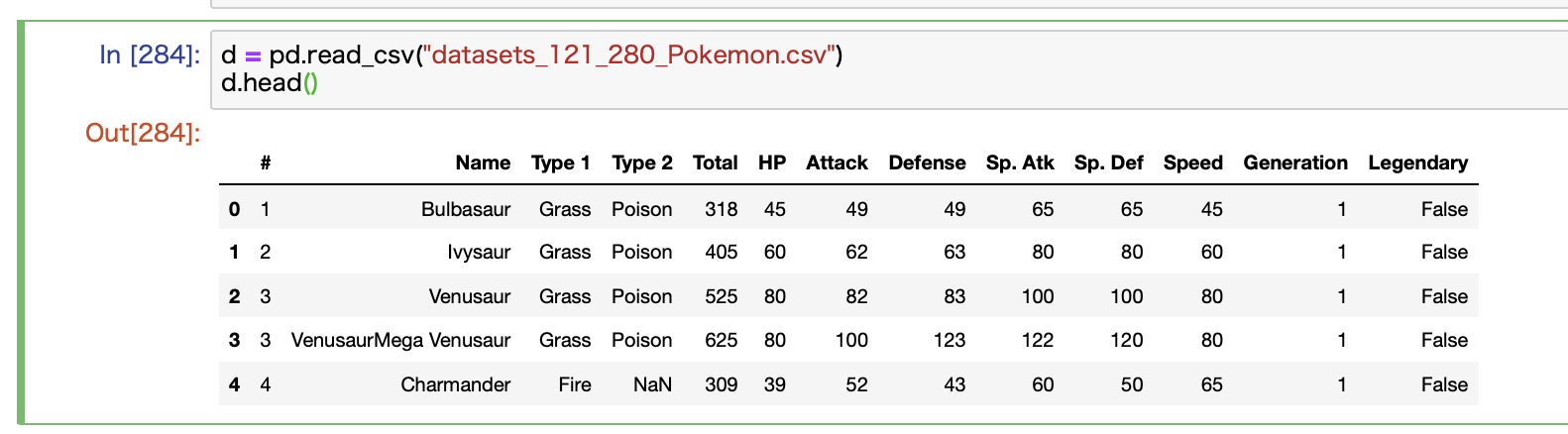
ご覧の通り、全て英語です。
このままだと何が何だかさっぱりわからないので、今回はこのNameを日本語に翻訳する英和辞書を作っていきます。
2. 英和辞書を作る
データの確認ができたところで早速英和辞書を作っていきます。
今回はスクレイピングを利用してデータを取得します。
データ元はWikipediaです
データ元はWikipediaです。
さすがはWikipedia様で、ポケモンの各言語の名称がまとめられているページがあるんですね。
参考にしたページがこちらです。
このページには、英語のみではなくドイツ語や中国語などもあります。
さすがですね。
スクレイピングでデータを取得する
こちらのページをスクレイピングすることでデータを取得します。
コードも全部ご紹介します。
こちらです。なるべく多くのコメントをつけるように努めました。
import requests
from bs4 import BeautifulSoup
# URL定義
pokemon_url = "https://wiki.ポケモン.com/wiki/ポケモンの外国語名一覧"
# HTML取得
r = requests.get(pokemon_url)
soup = BeautifulSoup(r.content, "html.parser")
# 辞書を定義
translator = {}
# Tableの各行を辞書へ加える
for tr in soup.find("div", {"id": "mw-content-text"}).findAll("tr"):
if len(tr.findAll("td")) > 2:
translator[tr.findAll("td")[2].getText().strip().lower()] = tr.findAll("td")[1].getText().strip()
requestsパッケージを利用してHTMLを取得し、BeautifulSoupを利用して解析していきます。
ポケモンの外国語名一覧(Wikipedia)のHTMLを見ると、テーブルがある部分はid="mw-content-text"内にあったので、ここにある全てのtrタグを取得して、1行ずつ辞書に挿入していった感じです。
完成した辞書がこちらです。いい感じですね。
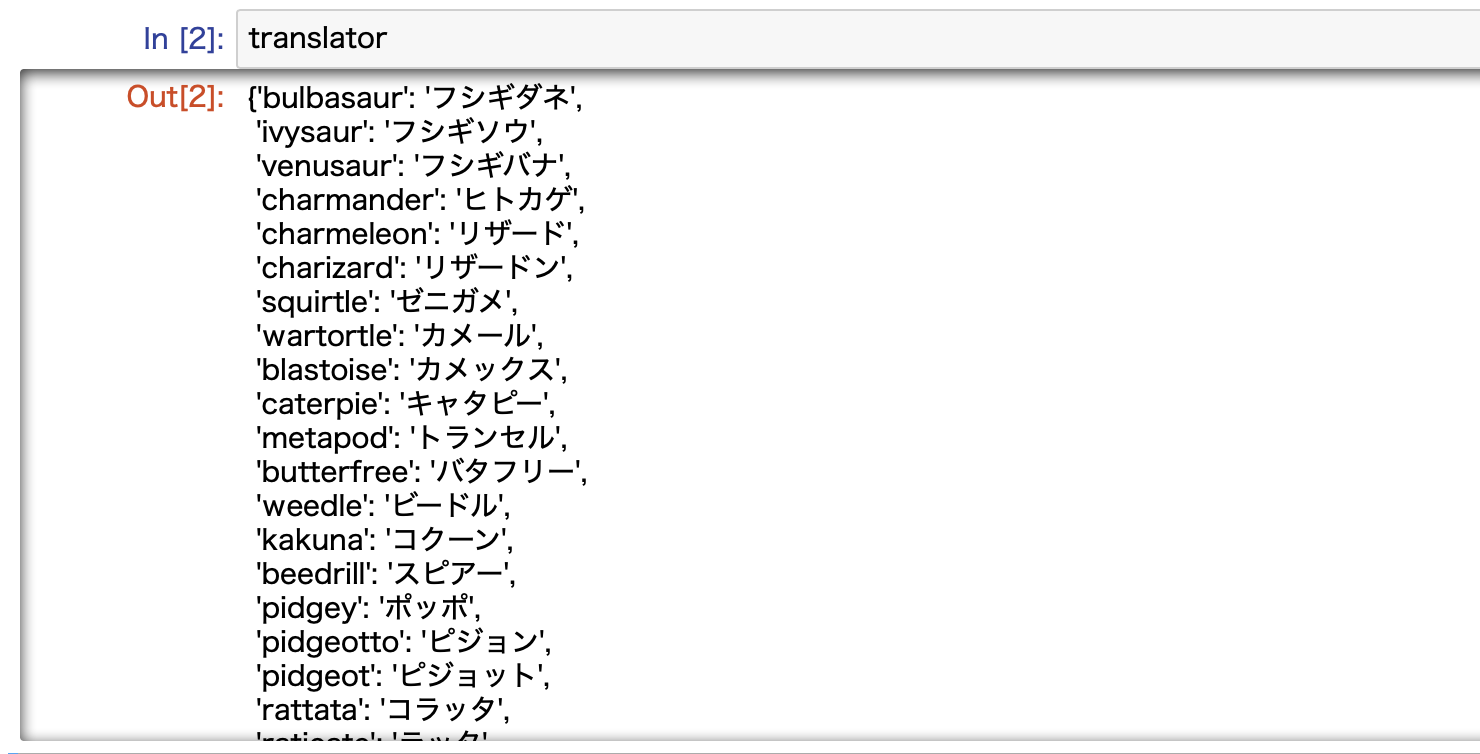
小文字に統一して文字のゆらぎを減らす
さらに、ここで辞書を作成するにあたって工夫した点を一つご紹介しておきます。
それは文字を全て小文字で統一したことです。
Wikipediaのページを見ると、最初の1文字は大文字ですが、辞書を作成する際には小文字に変換しました。
コードにあるlower()ってのが小文字に変換するコマンドです。
これをした理由は、文字のゆらぎを減らすためです。
Kaggleから取得したデータも最初の一文字は大文字になっているのですが、いくつかを違いがありました。
例えばホウオウです。伝説のポケモンですね。
これはWikipediaではHo-Ohですが、KaggleのデータではHo-ohです。
そのままの状態では文字列が一致せずに正しく変換することができません。
しかし、両方とも全て小文字に統一してしまえば、問題なく変換することができます。
このように、文字列を扱う場合には小文字に統一するなどしてゆらぎを減らすことで精度を上げることができます。
ポイント
文字列を扱う際には、小文字に統一するなどしてゆらぎをなるべく抑える!
英和辞書を使ってみる
作成した辞書を使うには、ポケモンを英語で入力すればOKです。
こんな感じです。
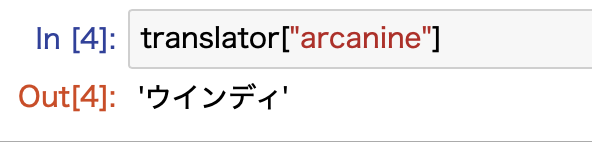
適当にポケモンを英語名で入れてあげると、日本語に変換してくれます。
ここでは全て小文字にすることをお忘れなく!
これで辞書が完成しました。
3. 辞書を適用して日本語名を取得する
さて、それでは作成した辞書を使って全てのポケモン名を英語から日本語に訳してみましょう!
apply関数とlambda関数で一発で翻訳する
DataFrameでデータを扱っていれば、この処理は1行で完了します。Python最強ですね。
ここではapply関数とlambda関数を使います。合わせ技です。
# 英語名を日本語名に訳す d["Japanese_Name"] = d["Name"].apply(lambda x: translator.get(x.lower()))
Name列に対して、辞書を介して日本語に翻訳しています。
各値をxとして、それぞれをlower関数で小文字に変換したのちにtranslatorに引き渡しています。
返ってきた値がJapanese_Nameに挿入されます。
for文を使って1つずつ処理してもいいのですが、処理スピードが遅くなりますし、コードも煩雑になります。
なるべくapply関数などを使ってスマートでスッキリとしたコードを書くように心がけていきたいものです。
ポイント
列の各値を処理するにはapply関数が便利です。
一部翻訳できないデータがありました・・・
それでは処理したデータを確認します。
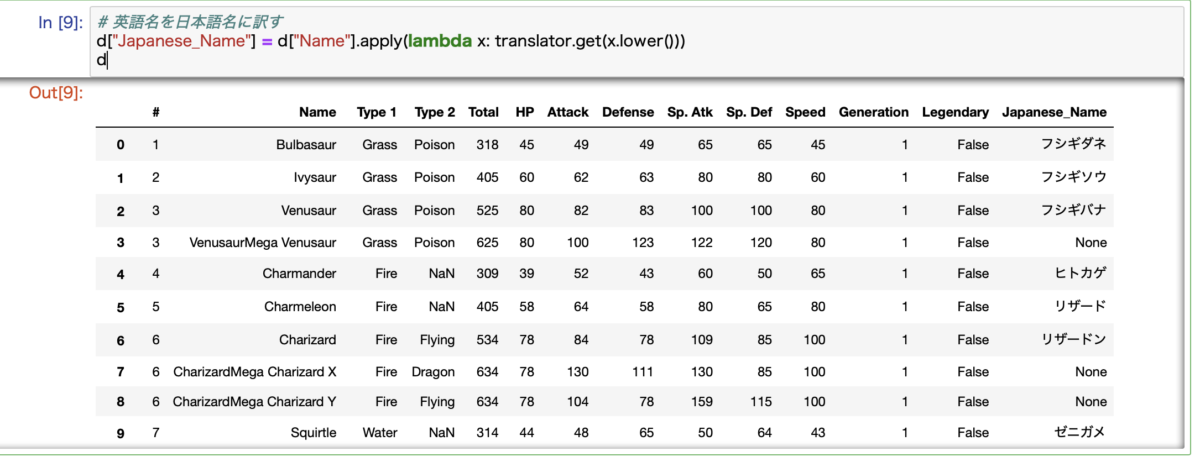
ここで残念なお知らせです。
よく見るときちんと日本語名に翻訳されていないポケモンがいますね。
これはメガ進化とか特殊な条件で進化できるポケモンたちです。
これらは辞書データに一致する項目がないため、Noneとなっています。
ここもきちんと翻訳する場合には、工夫が必要です。
Megaをメガを訳しつつ、文字列の中に該当するポケモンがあるかチェックして、それらをくっつけるような処理をすればOKです。
数行でできますが、めんどいのでここでは割愛しますw
興味のある方はぜひ挑戦してみてください。
Noneを排除して処理完了
ここではNoneとなっているメガ進化とかのポケモンは排除して処理します。
僕はルビー・サファイア(第3世代?)までしかポケモンでは遊んでいないので、メガ進化とかはよくわかっていませんw
ゆえに消します。
これを消すのは簡単です。
#日本語名がNoneを行を排除する d = d[d["Japanese_Name"].isnull()==False]
この1行で、日本語名がNoneの行を排除することができます。
これでデータがきれいになりました。
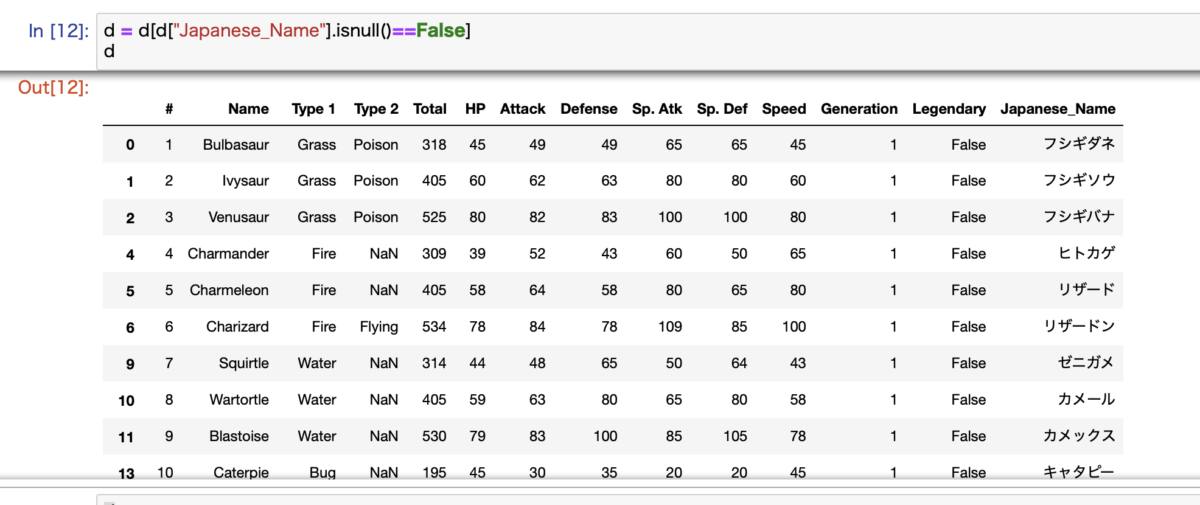
これで翻訳作業の処理は全て完了になります。
こちらのデータを利用して、過去記事で紹介した分析をしました。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
4. (おまけ)多言語辞書を作る
以上で紹介したかったコードはおしまいですが、最後におまけです。
ポケモンの外国語名一覧(Wikipedia)には、日本語と英語以外の言語もいくつかあるので、日本語からこれらの言語に訳せる多言語辞書を作ってみたいと思います。
そんな大したことありませんが、この記事を書いてるうちに僕がたまたま思いつきましたw
もしご興味があれば参考がてらみてあげてくださいw
今回は、辞書に日本語でポケモン名を入れると各言語の名前が返ってくるようにしたいと思います。
さらに言語を指定すれば該当する値が返ってくるようにします。
言語の指定がない場合には全てのデータが返ってくる仕様にします。
まずはコードをどうぞ
それではまずはコードを全部どうぞ!
import requests
from bs4 import BeautifulSoup
# URL定義
pokemon_url = "https://wiki.ポケモン.com/wiki/ポケモンの外国語名一覧"
# HTML取得
r = requests.get(pokemon_url)
soup = BeautifulSoup(r.content, "html.parser")
"""
tableからDataFrameを作成する
"""
# リストを定義 *ここに各行のデータを加えていく
rows = []
# 各行を処理する
for tr in soup.find("div", {"id": "mw-content-text"}).findAll("tr"):
# thタグがあればTableのコラムとしてデータを取得
if tr.find("th"):
columns = [x.getText().strip() for x in tr.findAll("th")]
# tdタグがあればリストに挿入
if tr.find("td"):
rows.append([x.getText().strip() for x in tr.findAll("td")])
# DataFrameに変換する
df = pd.DataFrame(rows, columns=columns)
"""
DataFrameから辞書を作成する
"""
# 不要な'番号'列を削除
df.drop("番号", axis=1, inplace=True)
# '日本語'列をindexに変更
df.set_index("日本語", inplace=True)
# 辞書を定義
translator = {}
# 各行を辞書に追加
for i in range(len(df)):
# 行データを抽出
row = df.iloc[i]
# データを辞書型に変換して辞書に追加
translator[row.name] = dict(row)
関数もなくベタ書きで申し訳ないのですが、これで多言語辞書を作成することができます。
今回は、WikipediaにあるTableデータをDataFrameに変換して、それをもとに辞書を作成しました。
ぶっちゃけ、このDataFrameを作成するプロセスはなくても、いきなり辞書を作ることも可能です。
ただ、今回はこのやり方のほうがついでに色々なコードの書き方を紹介できるかなと思ってこのような形にしました。
簡単に上から解説していきます!
リスト内表記を制する
最初に解説するべきは、やはりリスト内表記かなと思います。
Python特有の書き方なので困惑する方も多いかと思います。
先ほどのコードで言うところのこれです。
columns = [x.getText().strip() for x in tr.findAll("th")]
これはfor文とそれぞれの値の処理を1行にまとめています。
返り値はリストになって、columnsという変数に格納されています。
このままだとわかりにくいので、通常のfor文を使った場合と比べてみましょう。
これらは書き方は違えど、全く同じ処理をしています。
# リスト内表記を利用する場合
columns = [x.getText().strip() for x in tr.findAll("th")]
# リスト内表記を利用しない場合
columns = []
for x in tr.findAll("th")
columns.append(x.getText().strip())
見ての通り、リスト内表記を使った方が1行にまとまってスッキリします。
ついでにこっちの方が処理も早いです。
今回の場合は処理するデータが800行くらいしかないので大差はありませんが、数百万行とかの話になってくると大きな差が出てきます。
リスト内表記を使った方が圧倒的に早いです。
Python特有の書き方なので、慣れてきたら是非とも使いこなしていきたいテクニックです。
ポイント
リスト内表記でコードをシンプルになおかつ処理を高速化する!
リストをDataFrameに変換する
リスト内表記を駆使して完成したlistデータは、DataFrameに変換しています。
こちらのコードですね。
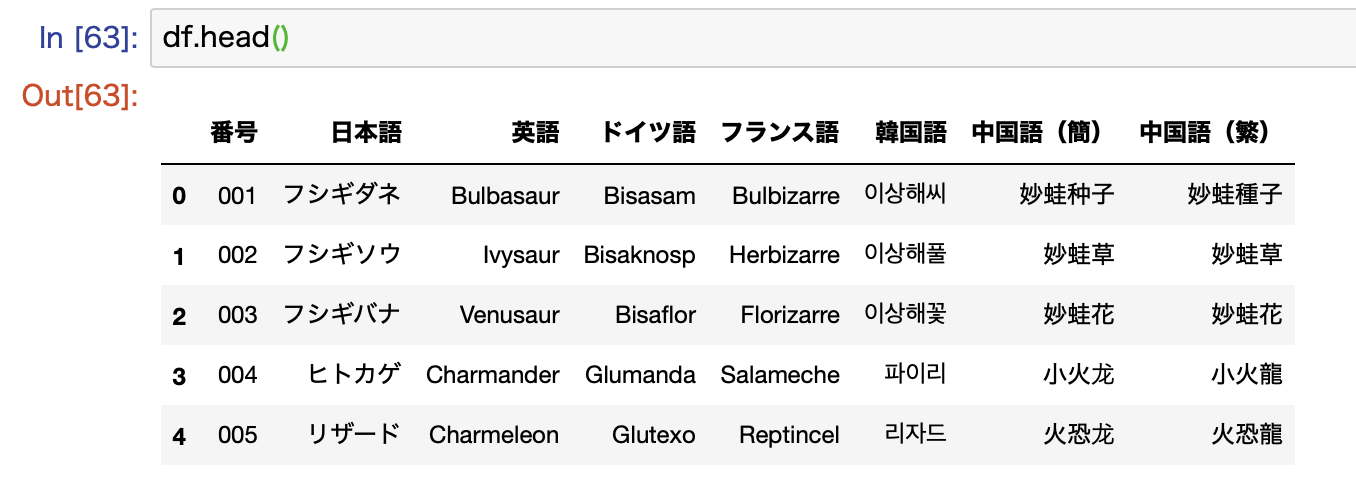
# DataFrameに変換する df = pd.DataFrame(rows, columns=columns)
これでrowsというlistをDataFrameに変換します。columns引数を指定するとカラム名を任意の値にすることができます。
ここでできるdfはこんな感じになります。
DataFrameを整形する
次に作成したDataFrameを整形します。
ここではdrop関数で'番号'列を削除して、set_index関数を使って'日本語'をindexにセットしています。

これで辞書を作成する下準備が完了しました。
DataFrameから辞書を作成する
最後にこのDataFrameから辞書を作成すれば完成です。
ここではiloc関数を使って、1行ずつ取り出して辞書に挿入しています。
これですね。
# 辞書を定義
translator = {}
# 各行を辞書に追加
for i in range(len(df)):
# 行データを抽出
row = df.iloc[i]
# データを辞書型に変換して辞書に追加
translator[row.name] = dict(row)
ilocは数字で行列を指定して抽出できる関数です。
ここでは行ごとに抽出して、そこからindex名を抽出し、データをdictで辞書型に変換して辞書に挿入しています。
これを各行に繰り返せば多言語辞書の完成です。
多言語辞書を使ってみる
ここで完成した辞書がこんな感じです。いい感じにできていますね。
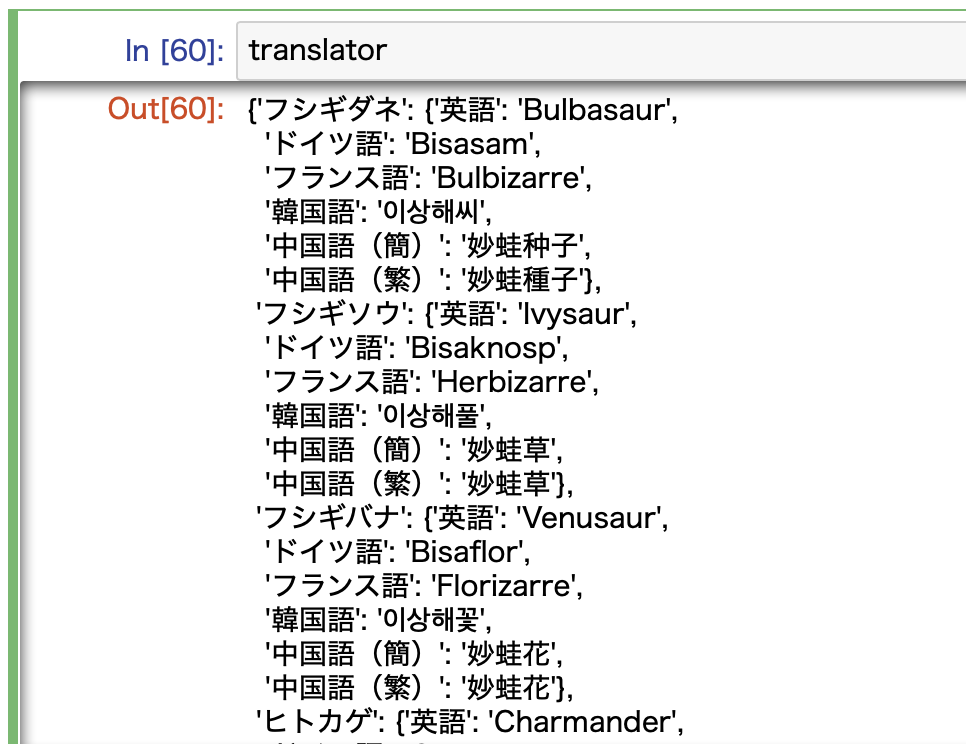
ここに日本語名で適当なポケモンを入れると多言語に翻訳することができます。
ポケモン名だけ入れるとこんな感じで各言語の値が返ってきます。

ちなみにさっきから例でウインディを使っているのは、僕が個人的にウインディが好きだからですw
言語を指定することもできます。
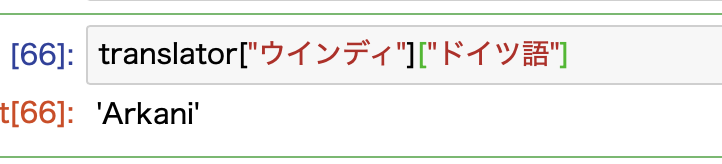
以上で、ポケモンを日本語から多言語に翻訳する辞書が正しく動作していることが確認できました!
まとめ
いかがでしたでしょうか。
ここでは、ポケモンの英和辞書を例に、Pythonの辞書を利用する一例をご紹介しました。
これに加えて、スクレイピングやデータ処理の手法についても解説できたので、少しでもお役に立てると嬉しいです。
ここで作成した辞書を使って、ポケモンのデータセットを英語名から日本語名に翻訳して、その後の分析に利用しました。
データを見たらお分かりいただけるかと思いますが、英語名だと何が何だかさっぱりわかりませんw
ゆえに、日本語に翻訳するための辞書が必要になったわけですが、Pythonであればデータの取得から処理まで非常にシンプルなコードでできるので、とっても便利です。
今後もコードの解説記事をどんどん増やしていきたいと思います。
ここまで読んでくださってありがとうございました。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-
【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】




{kind=link}