
こんにちは。TATです。
今日もPythonのコード解説記事です。
テーマは「OpenCVを使ってfinvizのヒートマップ画像を解析する」です。
こちらの記事で紹介しているfinvizのスクショを解析して、OpenCVを使った画像解析を行う方法について解説します。
-

【Pythonでデータ分析】株クラで目にする「おはぎゃー」のプロセスを自動化してみた!
finvizのスクショを見て、全体的に真っ赤(つまり全株下落)の場合は、株クラ界では「おはぎゃー」ツイートが散見されます。
「おはぎゃー」は「おはよう」と「(株価が下落して)ぎゃああああああ」を組み合わせた造語で、株クラ界ではおなじみのものになります。
Twitterなどで株式投資に関する情報収集をしている方なら一度は見たことがあるのではないでしょうか。
画像の判断は、人間なら画像を見て「こりゃ全体的に下がってるな〜」と判断できますが、プログラムだとそうはいきません。
ここをプログラムで自動化しようとなると少し工夫が必要になります。
目次
【Pythonコード解説】OpenCVを使ってfinvizのヒートマップ画像を解析する
(おさらい)finvizのスクショを取得する
本題に入る前に、今回必要になるfinvizのスクショについて確認しておきます。
finvizのサイトへ行くと銘柄ごとの騰落率がヒートマップで表現されています。
ここのページのスクショ画像を利用します。
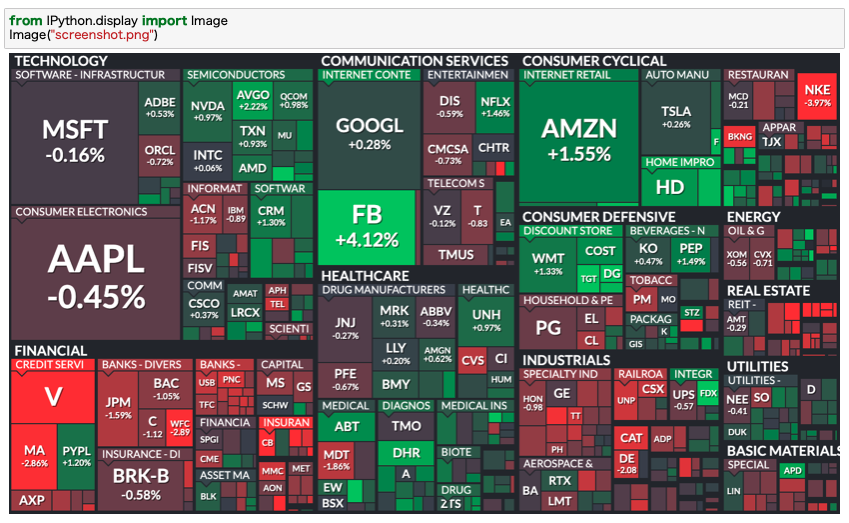
このヒートマップを見て、全体的に下落していたら株クラ界では「おはぎゃー」ツイートが見られます。
通常あれば手動でヒートマップを見て、全体的に下落していたらスクショを撮って、その画像を添えてツイートする感じになります。
全てマニュアルの作業です。
この一連の流れをプログラムで全自動化したのが過去記事です。
-
【Pythonでデータ分析】株クラで目にする「おはぎゃー」のプロセスを自動化してみた!
Seleniumを利用すれば、スクショを簡単に保存することができるので、画像を取得自体はサクッと実装することができます。
Seleniumによるスクショの取得方法の詳細についてはこちらの記事をご覧ください。
-
【Pythonコード解説】Seleniumでfinvizのヒートマップのスクショを保存する
-
PythonでSeleniumを利用する方法!セットアップの流れを徹底解説します!
続きを見る
画像の解析にはOpenCVを利用します
それではここからは、スクショ解析の解説をしていきたいと思います。
画像の解析にはOpenCVというライブラリーを使います。
OpenCVは、インテルが開発したオープンソースのライブラリーです。
OpenCVを使うと、画像処理が簡単にできるのでとても便利です。
特定の色を抽出したり、全体の色の平均を出したり、フィルターをかけたり、いろいろなことが短いコードで実装できます。
画像全体の平均色から判定します
今回の目的は、スクショを解析して、「おはぎゃー」ツイートをするかどうかを判断することです。
これにはいくつかの方法があります。
- 下落している銘柄を抽出して、画像全体に占める割合から判定する
- 画像全体の平均色を算出して判定する
1つ目の方法はシンプルかと思います。
画像から下落してる銘柄、つまりは赤色になっている銘柄を抽出して全体の何割を占めるかを算出します。
もし画像全体の90%以上が赤色と判断できたら、「おはぎゃー」ツイートするなどといった感じで基準を設けます。
2つ目の方法は、画像全体の平均の色を計算します。
この色がどれくらい赤いかによって判断するというものです。
今回は、実装の容易性を考慮して、2つ目の画像全体の平均色から判定する方法を採用します。
OpenCVによる画像解析を解説します
ここからはコードの解説です。
解説の手順は以下の通りです。
- スクショ画像を読み込む
- 画像の平均色を計算する
- 閾値より大きいかどうかを判定する
順番に見ていきます。
1. スクショ画像を読み込む
まずはOpenCVを使ってスクショ画像を読み込みます。
使用する画像については、過去記事でも紹介している通り、screenshot.pngという名前で保存しています。
-
【Pythonコード解説】Seleniumでfinvizのヒートマップのスクショを保存する
画像を読み込むのはとても簡単で、1行で終了します。
import cv2
img = cv2.imread("screenshot.png")
これで画像の読み込みは完了です。OpenCVライブラリーを使う際にはcv2という名前で利用することができます。
cv2のimread関数で画像ファイルを指定すれば完成です。
imreadは多分image readとかの意味かと思います。
これで読み込まれた結果がこちらです。
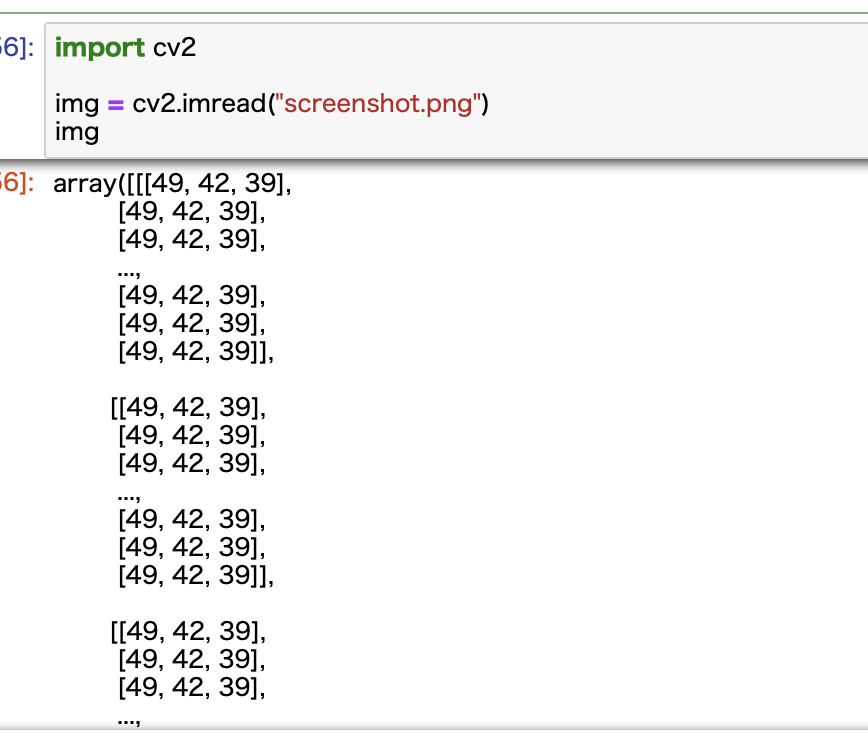
ご覧の通り、謎の数字が羅列されています。
これは、行(高さ) x 列(幅) x 色(3)の3次元配列データです。
それぞれのリストの中に数字が3つずつ格納されていますが、これらはそれぞれBGR(青、緑、赤)の数値を示しています。
中学校あたりで習った「色の3原色」を使えばすべての色を表現することができます。
よって、データとして扱う場合にはいかなる色でもこの3つの色に分解することが可能です。
OpenCVを使うと、画像を読み込むだけですぐにこの配列データに変換してくれるのでとても便利です。
2. 画像の平均色を計算する
画像の読み込みが完了したところで、次に画像全体の平均色を計算していきます。
鋭い方ならお気づきかもしれませんが、平均色を計算するのはとても簡単です。
先ほどの数列の弄って平均値を計算すれば終了です。
import cv2
img = cv2.imread("ohagya-.jpeg")
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
average = cv2.mean(rgb)
この平均値を計算するための関数もOpenCVには用意されています。
これを使えば一瞬ですが、ここでは少し手間を加えています。
平均値を計算する前に、数値データをBGRからRGBに変換しています。
OpenCVでは、デフォルトでBGR(青、緑、赤)の順番で数値が表現されますが、一般的にはRGB(赤、緑、青)の順番で表記される場合が多いです。
2通りの表現が混ざると混乱するので、RGBで統一します。
OpenCVには変換用の関数もあるので、これも1行で完了します。
cvtColor関数で、cv2.COLOR_BGR2RGBを指定すればおしまいです。
変換したものをrgbという変数に格納して、この平均値をmean関数で計算します。
これで平均値の計算は終了です。
結果はこんな感じ。
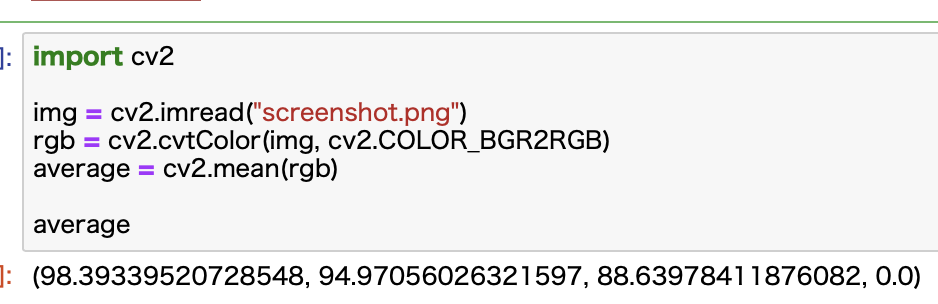
平均色を確認します。
import PIL
PIL.Image.new('RGB', (100, 100), tuple([int(i) for i in average[:-1]]))
ここではPILライブラリーを使っています。
サイズやRGBを指定して画像を作成できるので便利なんですね。
ちなみにRGBの指定条件としてはtupleで整数である必要があるため、リスト内表記を使って整数に変換したものをtupleに変換したものを引数に使っています。
リスト内表記を使うと、複数行のコードをまとめられるので使いこなせると結構便利だったりします。
ただ、Python独特の表記方法なので慣れるまでは違和感があるかもです。
これで表示される画像がこんな感じです。
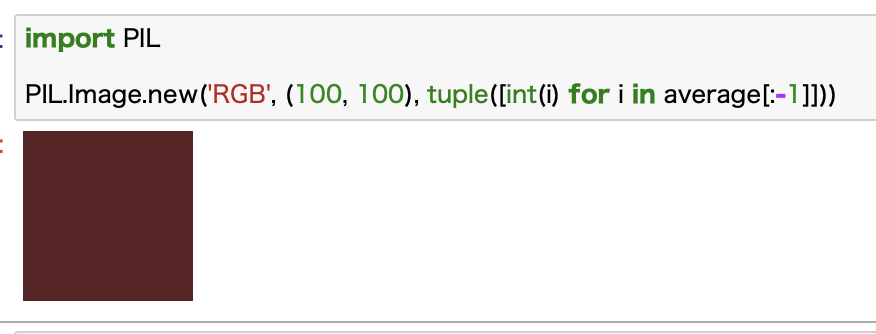
赤茶色っぽい感じですね。
以上の流れで、画像全体の平均色を計算することができました。
3. 閾値より大きいかどうかを判定する
最後に計算した平均色が、「おはぎゃー」ツイートをするに値するかを判定します。
これにはいくつかの画像を解析した上で適切な閾値を設定する必要があります。
この閾値を超えたら「おはぎゃー」、超えなかったらスルーです。
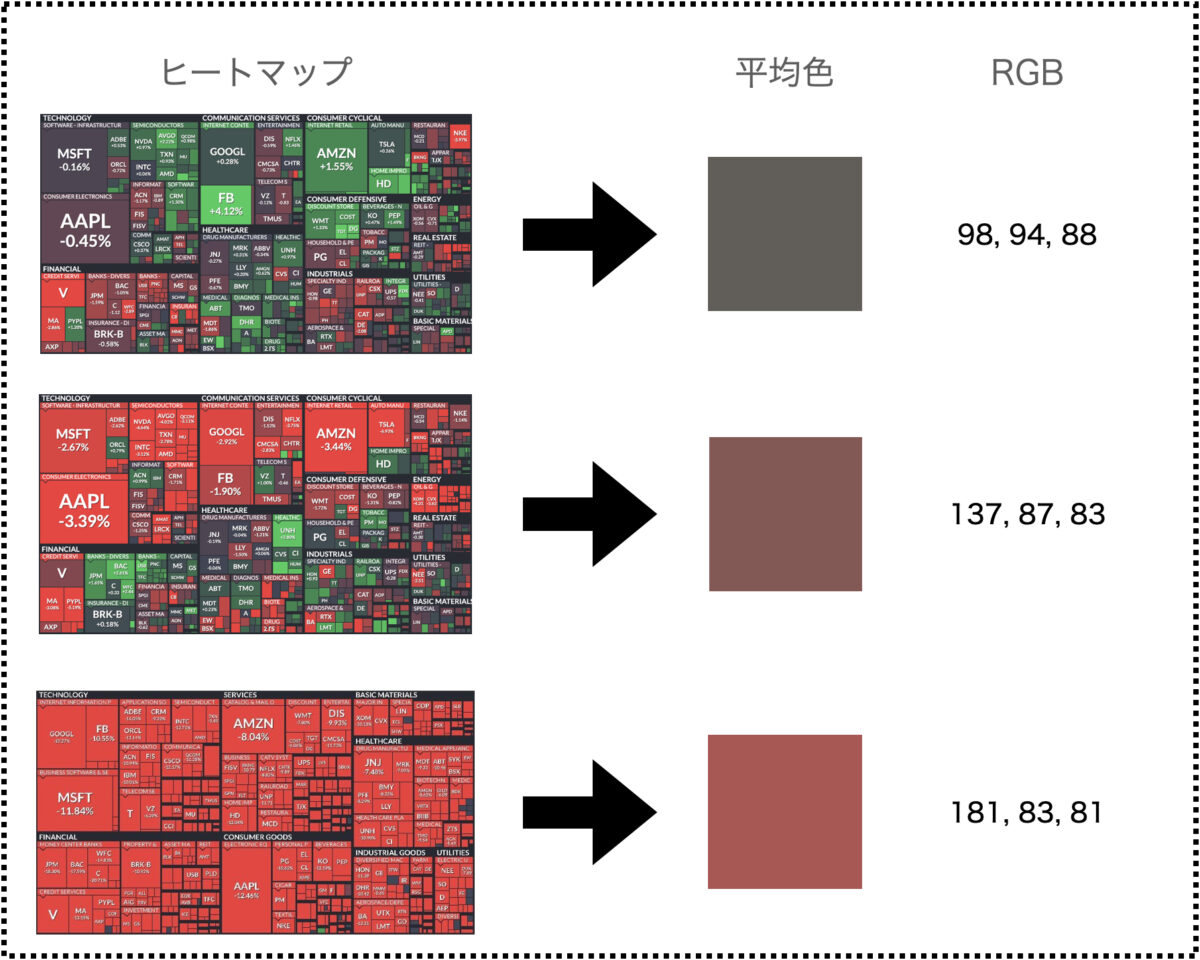
いくつかの画像と平均色を見てみましょう。
一個ずつ紹介するとめんどいので1枚にまとめました。
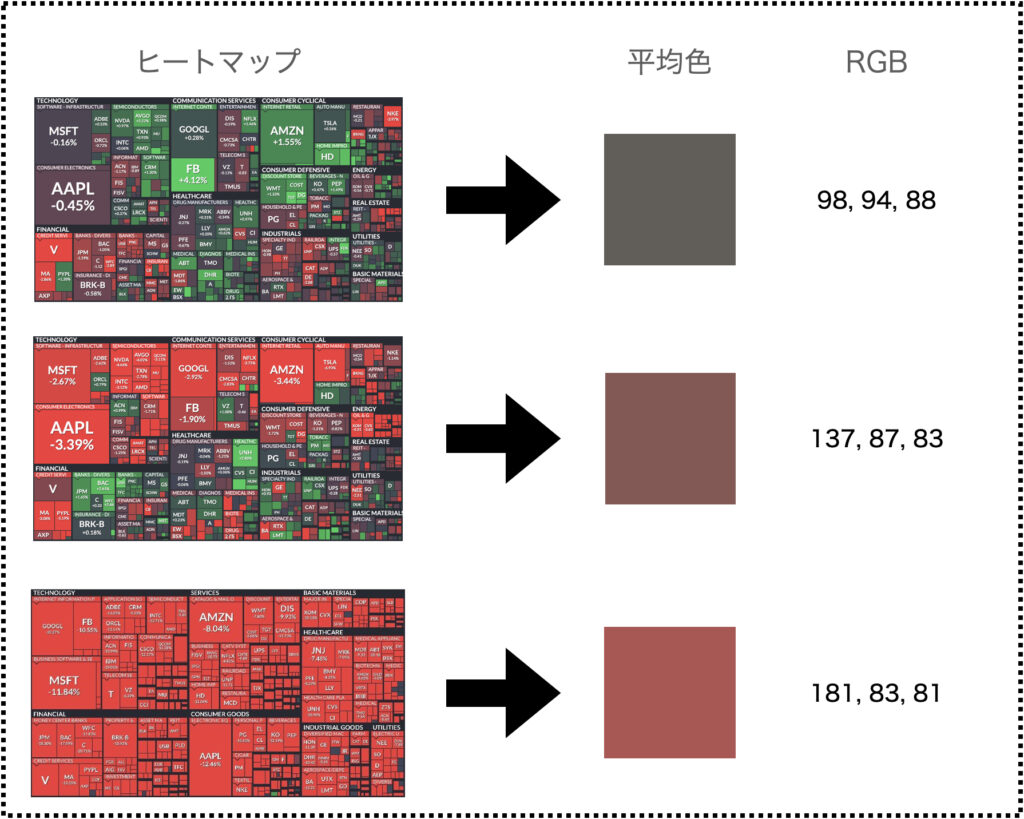
結果を見ると一目瞭然ですよね。
赤色が増えると平均色にも反映されていることがわかります。
RGBの数値を見ても、Rの数値(一番最初の数字)が増加していることがわかりますね。
一方でGとBの数値はそれほど変化していないことがわかります。
上記の結果より閾値を決めます。
厳しめに設定するのであれば、Rが180以上の場合は「おはぎゃー」と判定すればよさそうです。
少し緩めに設定するなら137と181の間をとって、160とか170あたりがよさそうです。
この判断は決め打ちで決めてしまっても良いですが、より精度を上げたいのであれば、さらに画像データを含めて「おはぎゃー」と判断するか否かを人間が判定して、そのデータを元に機械学習モデルで閾値を決めるというのもありです。
ただし、そこそこのデータ量が必要になるので、スクショの収集とラベリング(おはぎゃーか否か)の作業が必要になります。
データの準備が終わったらモデルの開発を行うので、工数はかかりますがその分精度の高い判定ができるようになります。
ここら辺の判断は、このプログラムの使い道とかを考慮しながらの判断になるかと思います。
今回の場合は、僕の遊びなので決め打ちで180でいきます。GとBは無視します。
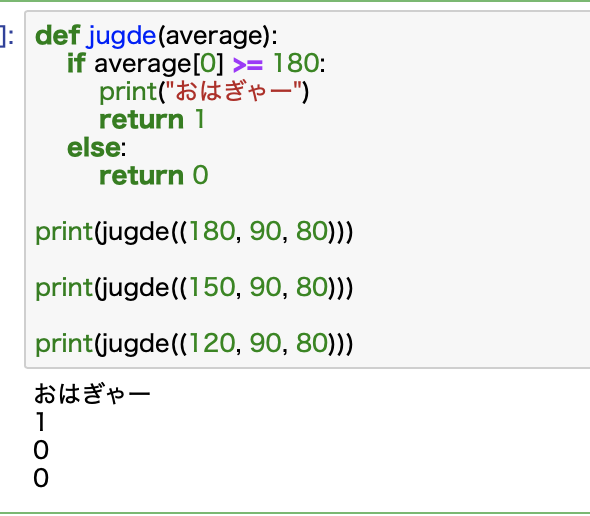
結果をもとに「おはぎゃー」を判定します。
def jugde(average):
if average[0] >= 180:
print("おはぎゃー")
return 1
else:
return 0
シンプルな関数です。
RGBの数値データを渡して、最初の数値(R)で判断します。
180以上なら「おはぎゃー」確定で1を返し、そうでない場合は0を返します。
返り値が1なら「おはぎゃー」です。
適当な数値でテストしてもちゃんと機能してることが確認できます。
(おまけ)OpenCVから特定の色を抽出する
最後におまけです。
今回は画像全体の平均色を計算して判定しましたが、OpenCVを使うと特定の色を抽出することができます。
これを利用すれば、抽出したデータが全体のどれくらいを占めるかを計算して、「おはぎゃー」の判定が可能です。
ちょこっとですが、特定の色を抽出する例をお見せします。
import cv2
img = cv2.imread("screenshot.png")
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 抽出する色の範囲を指定する
lower_color = np.array([75 ,50, 50])
upper_color = np.array([255,100,100])
# 指定した色に基づいたフィルタリング
mask = cv2.inRange(rgb, lower_color, upper_color)
output = cv2.bitwise_and(img, img, mask=mask)
# 結果のファイルを画像として保存
cv2.imwrite("filtered_screenshot.png", output)
これするとlower_colorとupper_colorで抽出する色の範囲を指定しています。
ここに含まれる画像のみが抽出できるようになります。
結果はこんな感じです。
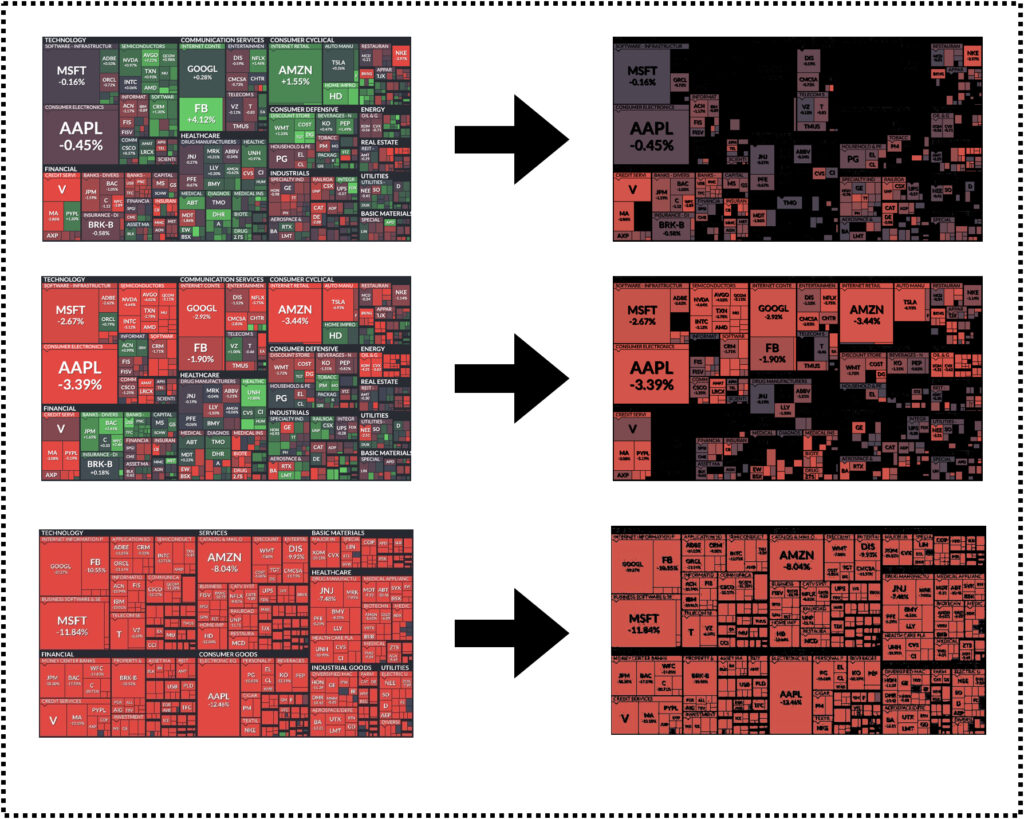
ここから抽出されたデータが画像全体のどれくらいの占めているのかを計算すればOKです。
抽出されない箇所は黒色になるので、全体から黒の割合を引いてもいいかもですね。
こんな感じで、「おはぎゃー」の判定方法はいくつもあるので、ご自身のやりやすい方法で実装していただければと思います。
プログラムが正しく動けば問題はないので、それを実現する方法が複数あるのであれば実装の容易性や精度などを考慮して決めると良いと思います。
まとめ
いかがでしたでしょうか。
今回は、「OpenCVを使ってfinvizのヒートマップ画像を解析する」というテーマで、OpenCVを使った画像解析について開設しました。
簡単なコードしか紹介できていませんが、どんな感じでプログラムで画像解析をするのか、少しでもイメージが理解いただけたら嬉しいです。
Pythonを使えば、通常は人間がマニュアルで行う作業もプログラムによる自動化が可能になります。
仕事でも副業でも転職でも、身につけておくとなかなかの武器になるのでオススメです。
また、くだらない内容ですが本記事の関連記事も合わせてご覧ください。
-

2023年Q3(7〜9月)の運用実績(+ 99,151円)- 本業忙しくてほぼ株見てなかった。。。
続きを見る
-
【Pythonコード解説】Seleniumでfinvizのヒートマップのスクショを保存する
続きを見る
ここまで読んでくださってありがとうございました。




{kind=link}