

こんにちは。TATです。
今日のテーマは「【Kaggleでデータ分析】Pythonでアニメデータを分析する③〜高評価の要因を探る〜」です。
これまでの分析記事の続きです。
-

【Kaggleでデータ分析】Pythonでアニメデータを分析する①〜データの概要把握とデータ整形〜
続きを見る
-

【Kaggleでデータ分析】Pythonでアニメデータを分析する②〜最高のアニメを探す〜
続きを見る
これまでの記事では、分析に利用するデータの概要確認やデータ整形を行ったり、データから最高のアニメを探したりしてきました。
今回は、データから高評価アニメの要因について探っていきたいと思います。
評価の高いアニメにはどのような共通点があるのか、評価との相関の強いデータはあるのか、こういったことを分析していこうと思います。
本記事がアニメデータの分析シリーズの最後の記事になります。
データのおさらい
まずはデータのおさらいです。
前回の記事に詳細はありますのでここではサクッといきます。
-
【Kaggleでデータ分析】Pythonでアニメデータを分析する①〜データの概要把握とデータ整形〜
続きを見る
データの入手元はKaggleです。
Anime listからデータをダウンロードしました。
データのダウンロードには登録(Register)が必要です。
ダウンロードしたデータをPythonで読み込んで、概要を確認しつつ、必要なデータ整形を行ったのが前回の記事でした。
データ整形作業としては、次の2つを実施しています。
データ整形
- rated_byを数値データに変換する
- statusをFinishedとAiringだけに絞る
こちらで完成したデータを本記事の分析に活用していきます。
評価が高いといえる基準点を探る
まずは評価が高いといえる基準点について探していきます。
10点満点のratingカラムがありますが、これが何点を超えたら高評価と判断することができるのでしょうか。
感覚的には8点とか9点とかいけば高得点な感じはしますが、ここではきちんとデータを確認して基準値を探っていきます。
describe関数で基本的な統計値を確認する
最初にdescribe関数を使ってratingの基本的な統計値を確認します。
df["rating"].describe().round(2)
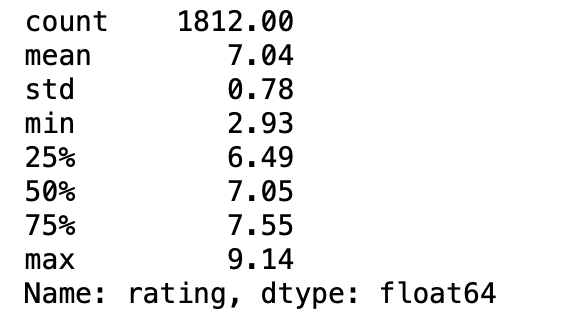
データ数は全部で1,812個あります。
平均値は7.04点ですので、これを超えたら平均点以上です。
中央値は7.05点で平均値とほぼ一致していますね。
第一四分位数は6.49点、第3四分位数は7.55点です。
つまり6.49点以下だったら下位25%になります。
一方で、7.55点以上だと上位25%の仲間入りができます。
ヒストグラムで見る
次にヒストグラムでratingをみてみます。
正規分布になりました
import seaborn as sns sns.displot(df["rating"])
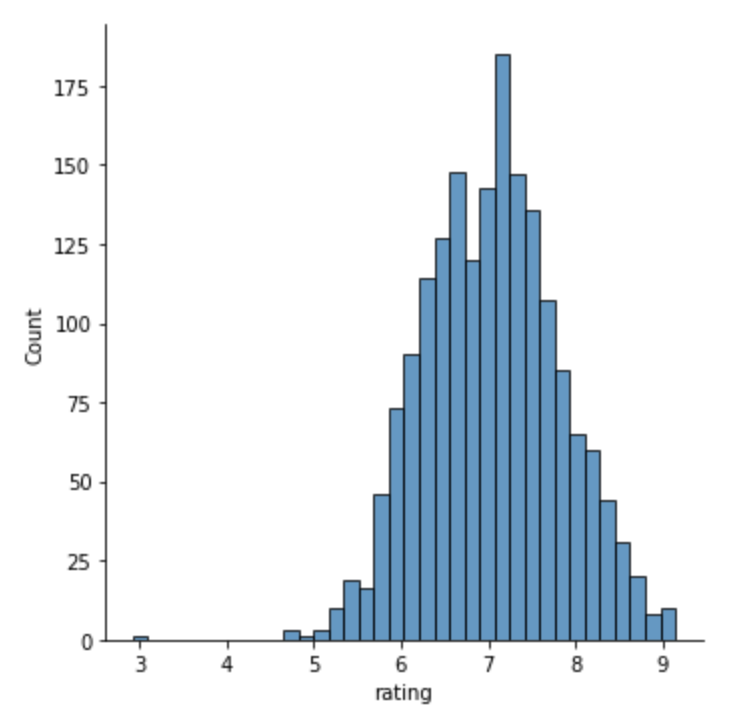
いい感じの正規分布ですね。
平均値と標準偏差を使って外れ値を出す
正規分布なので、平均値と標準偏差から外れ値を出すことができます。
具体的には、正規分布における次の特性を利用します。
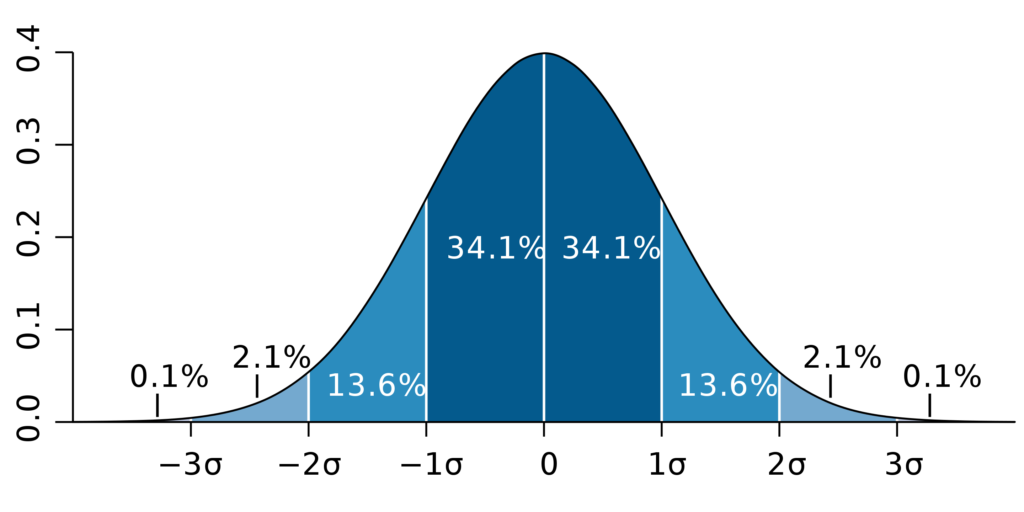
引用元:Wikipedia「正規分布」
平均値がゼロではない場合は、この図に全て平均値を足せばOKです。
σは標準偏差です。
つまり、mを平均値とすると、m+2σを超えるのは全体の約2.2%ほどしかありません。
つまりは上位2.2%のアニメに該当します。
これを利用して基準点を決めるのもありです。
今回の場合、平均値は7.04点、標準偏差は0.78点なので、m+2σは(7.04 + (2*0.78))=8.6点となります。
8.6点以上であれば全体の上位約2.2%にはいるので、評価が高いと言えるのではないでしょうか。
ちなみにratingが8.6点以上のアニメは40個ありました。
パーセンタイルを使ってみる
次にもう一つの方法としてパーセンタイルを使ってみます。
パーセンタイルは、全体の上位5%に入るには何点以上必要かみたいな基準線です。
これはPythonのnumpyを使うと簡単に計算できます。
試しに上位1%に入るための基準点を出してみます。
np.percentile(df["rating"].dropna(), 99)
これの結果は8.79点となります。
99は全体の99%をカバーするための基準点なので、これを超えると上位1%に入るということになります。
こんな感じで上位5%とか10%とか基準を設けて 、パーセンタイルを利用すれば基準となるratingが算出できます。
ちなみに、上位10%なら8.089、上位5%なら8.369、上位1%なら8.79になります。
それぞれ該当するアニメの数は182, 91, 20個でした。
全体が1,812個なので妥当な数であることがわかりますね。
どの基準線を使うか~上位5%を採用する~
ここまでで、評価が高いと言える基準点を探してきました。
どれを使うのか人によって変わってくるところですが、ここでは上位5%のデータを評価が高いアニメとして取り扱っていきます。
抽出された91個のアニメデータを使って、特徴を見ていきます。
df_top = df[df["rating"]>=8.369]
抽出されたデータはdf_topとしておきます。
rating上位5%のアニメの特徴を探す
それでは先ほど抽出した上位5%のアニメの特徴を探していきます。
studioではMadhouseが最も多い
まずはstudioを見てみます。
数が多いのでトップ5だけ表示します。
df_top["studio"].value_counts().head()

ご覧の通り、Madhouseがダントツで多いですね。
該当するアニメはデスノートやちはやふる、ハンターハンター、はじめの一歩などがありました。
sourceはダントツで漫画
次にsourceで見てみます。
df_top["source"].value_counts().head()

漫画がダントツで1位ですね。
yearでは最近のものが多い
次にyearを見てみます。
放送が開始された年です。
df_top["year"].value_counts().plot(kind="bar")
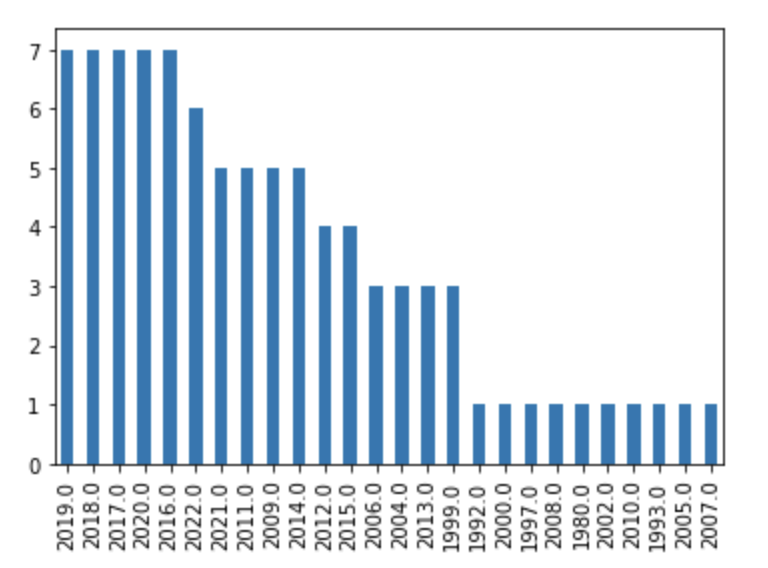
2015年以降の最近のアニメが多いですね。
demographicでは少年が多い
次にdemographicです。
df_top["demographic"].value_counts()

少年と青年で大半を占めています。
Kidsは1つもありませんでした。
themeでみる
次にthemeで見てみます。
これは,で区切られて複数あるものもあるので、それぞれ分割して集計して、多い順に並べてみます。
種類が多いのでトップ10だけを表示します。
themes = []
for theme in df_top["theme"].tolist():
themes.extend(theme.split(", "))
pd.Series(themes).value_counts().head(10)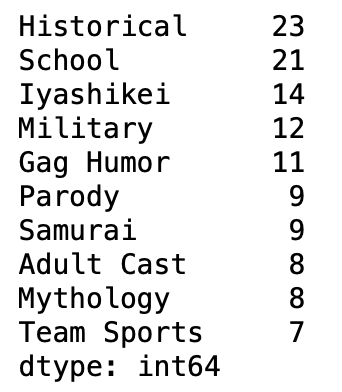
1位と2位は僅差ですね。
それぞれHistoricalとSchoolが入っています。
歴史と学園ですね。
歴史だと鬼滅の刃とか銀魂とかキングダムあたりが入っています。
学園だと呪術廻戦とかスラムダンクとかが入っていました。
最後にtagsで見てみます。
themesと同様に複数あったりするので集計してトップ10を出してみます。
themes = []
for theme in df_top["tags"].tolist():
themes.extend(theme.split(", "))
pd.Series(themes).value_counts().head(10)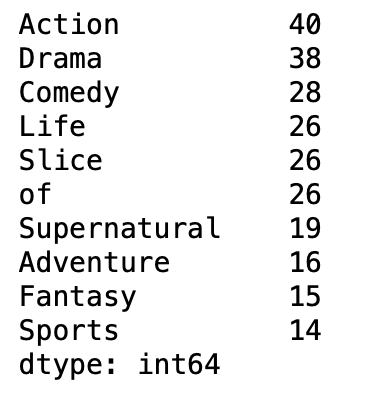
アクションとドラマが飛び抜けていますね。
アクションでは進撃の巨人や鋼の錬金術師、ハンターハンター、鬼滅の刃などが入っています。
Dramaでは進撃の巨人、ジョジョの奇妙な冒険、ちはやふるなどがありました。
ratingとの相関を分析する
次に少し角度を変えてみます。
ここまでは評価の高いアニメの特徴などを調べてきましたが、ここからはratingとの相関を見ていこうと思います。
用意したデータにはいろいろなカラムがあります。
これらのデータに相関があるのかを調べてみます。
pariplotで散布図を見る
まずはseabornのpairplotで各カラム間の散布図を見てみます。
import seaborn as sns sns.pairplot(df)
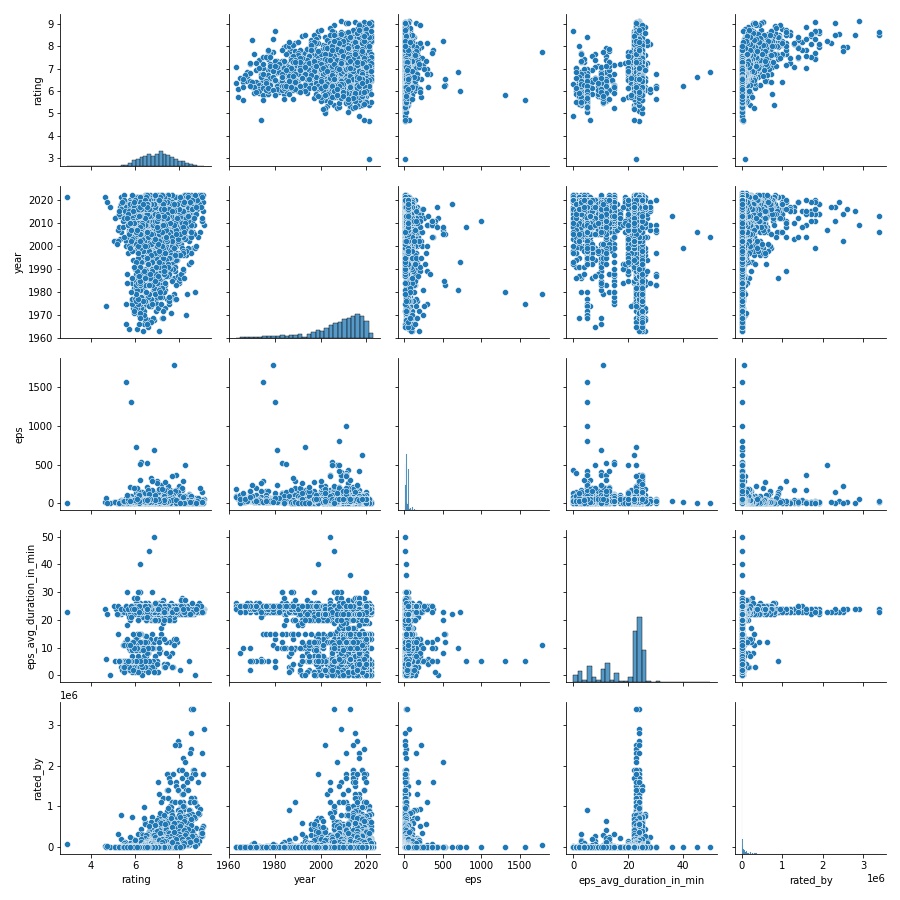
pariplotはデータサイズによっては読み込みに時間はかかりますが、全カラムの関係をパッとみれるのでとても便利です。
各カラムのヒストグラムもあわせて表示されます。
パッとみた感じがっつり相関しているようなものはなさそうな感じがします。
無理やり上げるならrated_byやyearでしょうか。
数が大きくなるとratingが高いアニメが結構入ってくるように見えます。
yearに関しては新しくなるにつれてアニメの数も増えてくるので、いい評価のものもありますが低評価のアニメも増えてボラティリティが増えてる感じですね。
相関係数をヒートマップで表示する
次に相関係数を見てみます。
corr関数を使えば一瞬です。
df.corr()
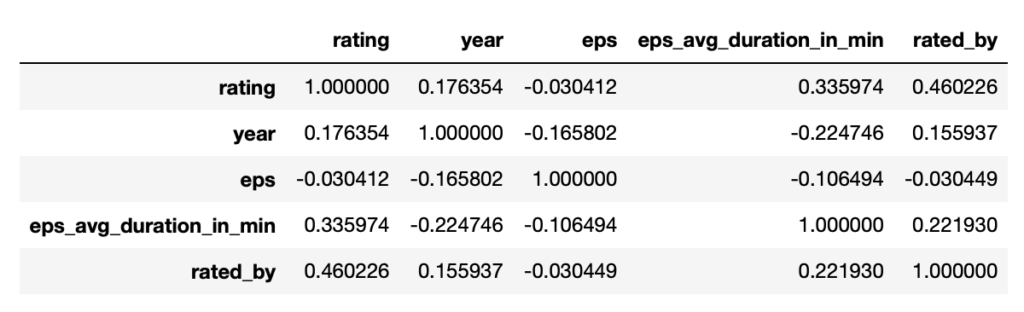
やっぱり相関が強いのはratingとrated_byですね。
ちなみに相関係数はヒートマップで表示するとみやすくなります。
sns.heatmap(df.corr(), annot=True)
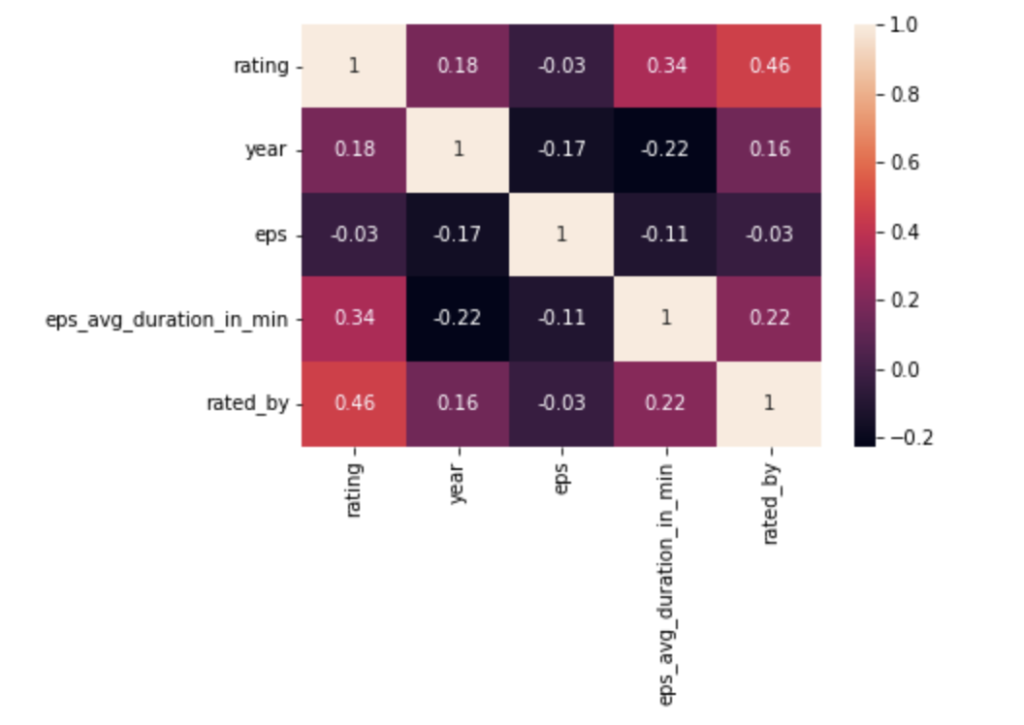
annot=Trueとすれば、相関係数が表示されます。
やはり相関がそこまで強いものはないですね。
ratingとrated_byを関係を深掘りする
ここで、相関が一番高かったratingとrated_byについてもう少しデータを見ていきます。
散布図を確認
これらの散布図をあらためて見ておきましょう。
import plotly.express as px px.scatter(data_frame=df, x="rated_by", y="rating")
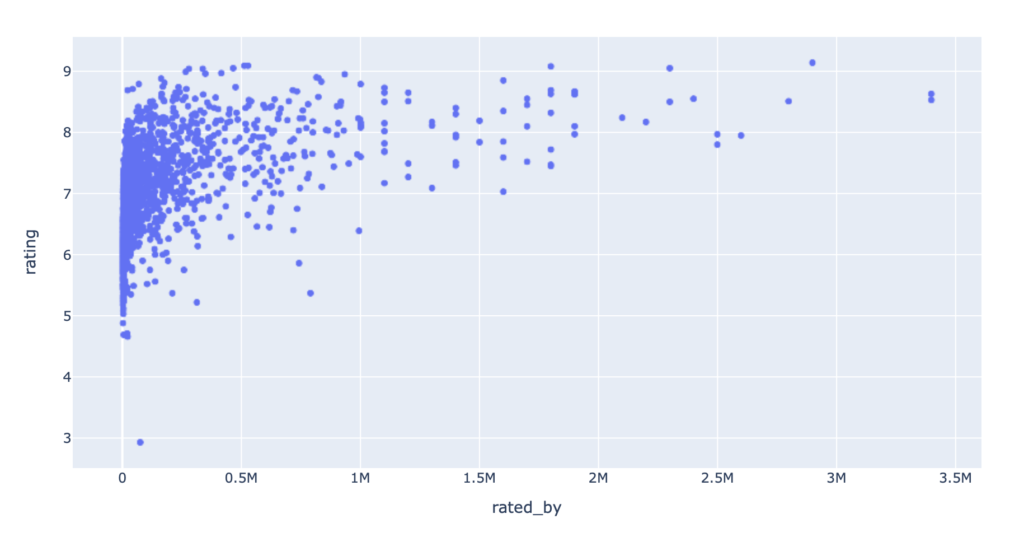
rated_byが大きくなるとratingも大きくなってる感じがします。
ただ回帰直線を引こうとするとどうもしっくりきません。
rated_byのlogを取ると相関が鮮明にわかる
これはぶっちゃけ経験則になってしまうんですが、このような散布図になるとlogを取るといい感じになる場合があります。
plotlyでグラフを描いたのは、logによる表記が簡単に実装できるためです。
x軸をlog形式にしてみます。
import plotly.express as px px.scatter(data_frame=df, x="rated_by", y="rating", log_x=True)
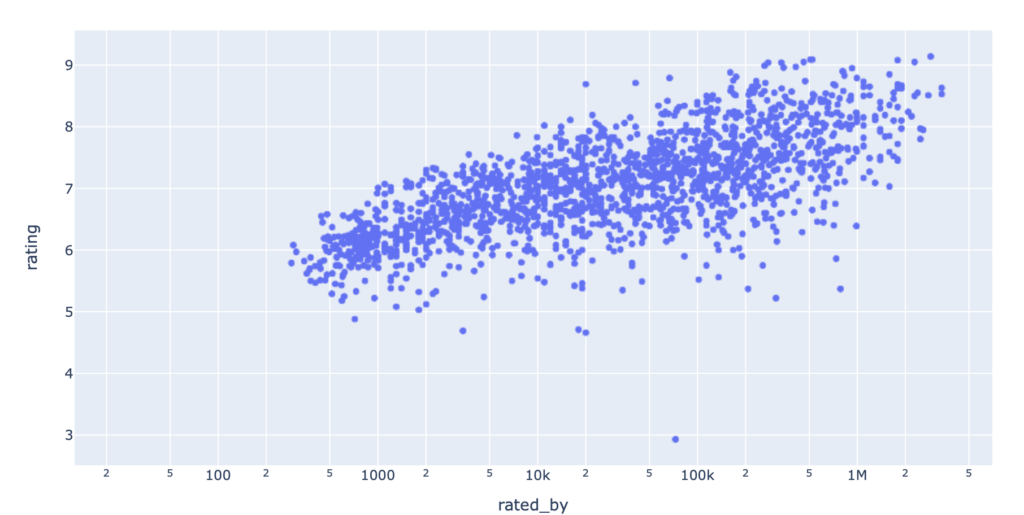
x軸のrated_byをlog形式にしました。
いかがでしょうか。
先ほどの結果と比べると見違えるくらいきれいな相関が見てとれます。
logにすると、メモリの単位が通常時とは違い、桁数が段々と増えていきます。
こうすることで相関がきれいになる場合があるんですね。
rated_byのlogを計算して相関を求める
それでは最後にrated_byのlogを計算して、ratingとの相関を見てみましょう。
import numpy as np df["rated_by_log"] = df["rated_by"].apply(lambda x: np.log(x)) df.corr()["rating"]

logはnumpyを使えば簡単に計算できます。
結果を見てみると、ratingとrated_by_logの相関係数は約0.69でした。
これは強い相関があると言えそうですね
評価の高い作品は口コミで広がってるのかな???
rated_byのlogとratingには強い正の相関があることがわかりました。
つまり、レビュー数が多くなるほど評価が高くなるということです。
ここから先は僕の推測に過ぎませんが、評価の高いアニメは口コミとかメディアで取り上げられたりしてどんどん広がって、最終的にはたくさんの人に見られるようになり、評価の数も増えていくのではないでしょうか?
面白くないと人にも薦めないと思うので、評価数も少なくなります。
この推測を検証する術は今のデータではありませんが、データを見ながらこういった意見をあーでもないこーでもないと出し合うのがデータ分析の面白いところの1つで大事になってきたりします。
結局のところ、データはただの数字に過ぎないので、その背景にある人々の行動とかを知るには限界があります。
こういう時こそ人間様の出番で、いろいろな仮説を出してデータの裏にある人々の行動とか背景を考えることが大事になってきます。
まとめ
本記事では、KaggleのAnime listからデータを使って高評価のアニメの要因について調べてきました。
評価の高いアニメを調べてみると、歴史や学園系のものが多かったり、2015年以降の比較的新しいアニメが多かったり、いろいろな特徴が見えてきました。
さらにレビュー数とレビューの相関を調べると、評価の高いアニメは評価数も多いことがわかりました。
これは、良い作品は口コミでどんどん広がって、最終的に多くの人が見るようになりレビュー数も増えるのではないかというのが僕の考えです。
データを見ているといろいろな発見ができますが、その数字の背景とか裏に隠されているものは人間の想像力が大事になってきたりします。
リアルとデータをうまく結びつけることができるようになるというのもデータ分析では大事な要素の1つです。
また、本記事がアニメデータの分析の最後の記事になります。
もしご興味あれば、過去の記事も合わせてご覧いただければと思います。
-
【Kaggleでデータ分析】Pythonでアニメデータを分析する①〜データの概要把握とデータ整形〜
続きを見る
-
【Kaggleでデータ分析】Pythonでアニメデータを分析する②〜最高のアニメを探す〜
続きを見る
ここまで読んでくださり、ありがとうございました。




{kind=link}