

こんにちは。TATです。
今日のテーマは「【Pythonコード解説】pandasのgroupbyとaggを組み合わせると便利さが格段に向上します」です。
Pythonのデータ分析ライブラリの1つであるPandasにはたくさんの機能が備わっています。
データの読み込みから、集計、前処理、可視化など、いろいろな用途に利用することができます。
本記事では、Pandasによるデータ集計に焦点を当てて、groupbyとaggの2つについて詳しく解説していきます。
結論、この2つを組み合わせるとデータ集計がかなり便利になります。
Pandasによるデータ集計に慣れてしまったらもうExcelには戻れなくなりますw
まずはそれぞれの関数についておさらいします
まずは、本記事で焦点を当てるgroupbyとaggそれぞれについて簡単にみていきます。
利用するデータについて
それぞれの関数の機能の使用例をご紹介するために、適当なデータを用意します。
Kaggleデータを使います
自分で用意するのはめんどくさいので、こちらの記事で利用したKaggleのデータを再利用します。
-

【Kaggleでデータ分析】Pythonでアニメデータを分析する①〜データの概要把握とデータ整形〜
続きを見る
ソースデータはこちらです。アニメのレビューをまとめたデータになります。
データをダウンロードするには登録(Register)が必要です。
-

【経験談】Kaggleは意味ないと言われるけど?→ データ分析を勉強するには最適な環境です
続きを見る
データの確認
用意したデータを確認します。
import pandas as pd
df = pd.read_csv("anime-list.csv")
各アニメのスタジオやレビューなどいろいろな情報がまとめられています。
本記事では、このデータを使ってgroupbyとaggを使ってみます。
groupby
まずはgroupbyです。
基本的な使い方についてみておきます。
任意のカラムごとに集計できる
groupbyでは任意のカラムごとにデータを集計することができます。
例えば、demographicごとのレビューの平均点を出してみます。
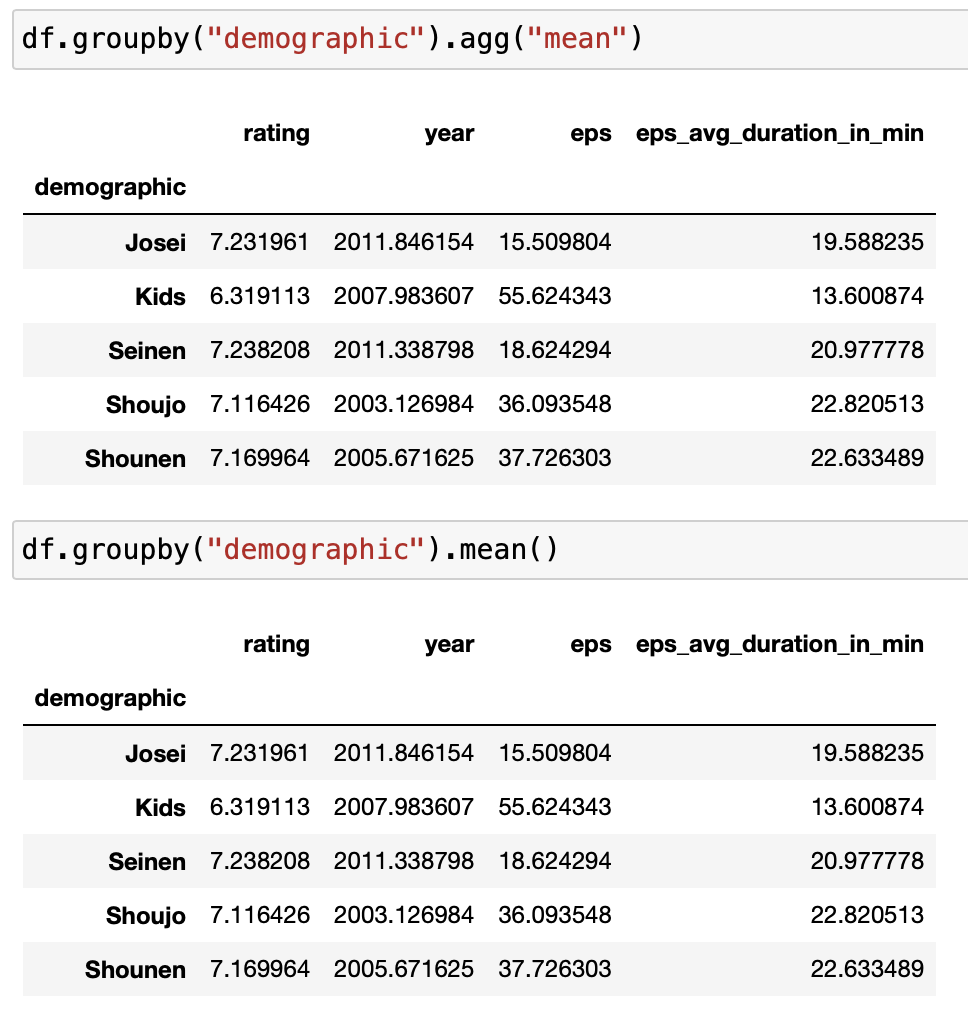
df.groupby("demographic").mean()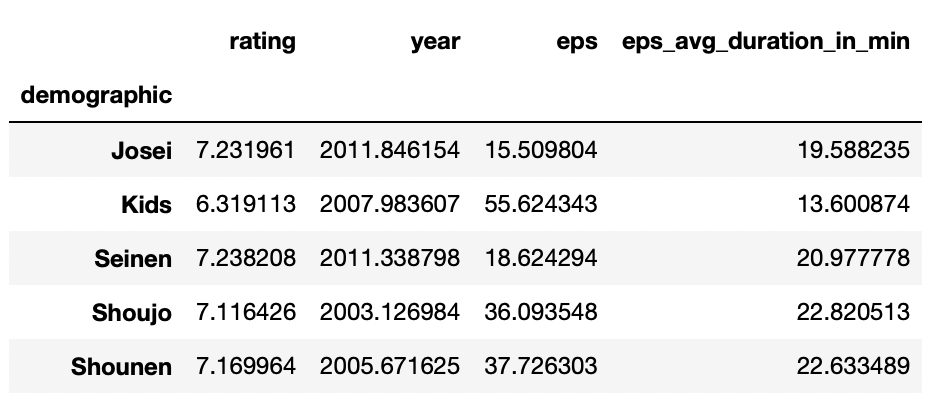
上記の通り、数値データが全て計算されます。
平均点は数値データしか計算できないので、計算できないカラムは自動的に排除されます。
ここでは平均点を計算するためにmean()を使いましたが、このほかにもいろいろな計算ができます。
groupbyの計算メソッド(一例)
- mean: 平均
- sum: 合計
- median: 中央値
- max: 最大値
- min: 最小値
- std: 標準偏差
- nunique: ユニーク値の個数
- size: データ数
- first: 最初のデータ
- last: 最後のデータ
- など
必要に応じていろいろな計算方法を適用できるのでとても便利です。
複数のカラムを選択することも可能
また、複数のカラムを指定して計算することも可能です。
この際には、list形式で指定します。
例えば、demogiraphicとstatusで平均点を計算するとこんな感じです。
df.groupby(["demographic", "status"]).mean()
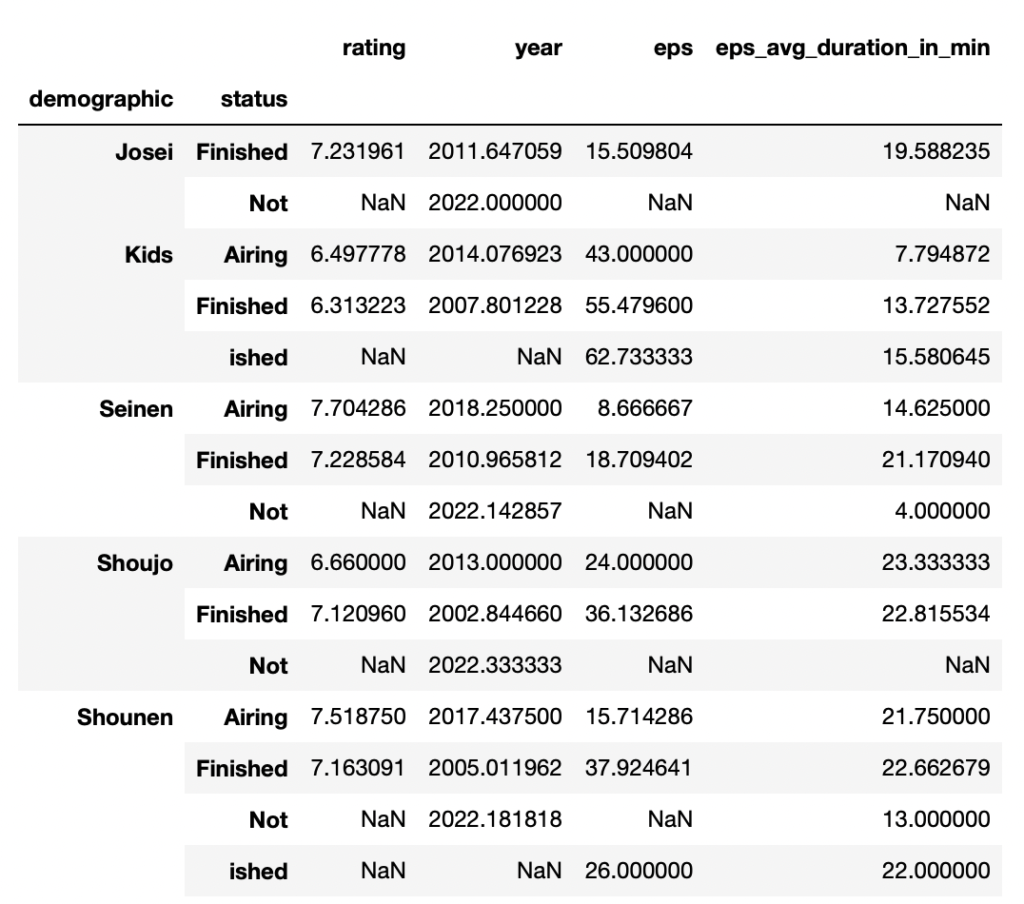
複数カラムを指定した際にはマルチインデックスとなります。
もちろん、この場合でも上記でご紹介したような計算方法を適用することが可能です。
agg
次にaggについて基本的な使い方をサクッと見ていきます。
aggはおそらくaggregateの略で、カラムや列ごとにデータを集計することができます。
aggの基本的な使い方
aggの基本的な使い方はシンプルで、引数に計算方法を指定すればOKです。
例として平均値を計算してみます。
df.agg("mean")
平均値なので、数値データのカラムだけが計算されます。
複数の計算方法を指定することも可能
複数の計算方法を指定することも可能です。
この場合はlist形式で指定します。
df.agg(["mean", "std"])
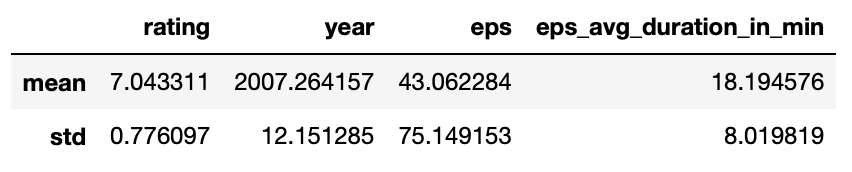
この場合はDataFrame形式になり、indexが指定した計算方法になります。
カラムごとに計算方法を指定できる
さらにカラムごとに計算方法を指定することもできます。
カラムAではsum、カラムBではmeanといったように、カラムごとに異なる計算を指示することができます。
この場合は引数をdict型にして、カラムごとにリスト形式で計算方法を指定します。
例として、適当にratingは平均、epsは平均と合計を出してみます。
df.agg({"rating": ["mean"], "eps": ["mean", "sum"]})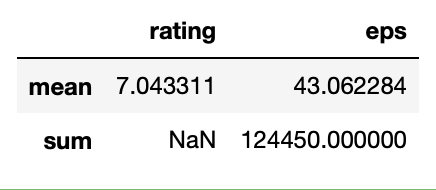
指定されたものだけが計算されていることが確認できます。
groupbyとaggを組み合わせると超便利になる
上記でご紹介したgroupbyとaggを組み合わせるとめちゃくちゃ便利になります。
普通に使えば変わりないw
基本的に普通に使う分には結果に変わりないので、お好きな方を使えばOKです。
この場合はaggを入力するのはめんどいのでシンプルにmean()を使えばいいですね。
特定のカラムだけを計算できる
groupbyとaggを組み合わせて使うメリットはここからです。
まず、特定のカラムだけを計算することができます。
不要な部分が出てこないのでスッキリします。
df.groupby("demographic").agg({"rating": "mean"})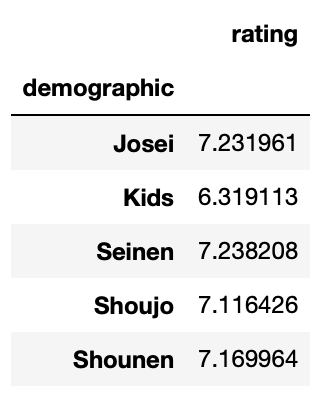
この場合、計算方法が1つの場合はlist形式ではなくても大丈夫です。
無駄な計算が省けるのもプログラム的にはメリットです。
カラムごとに計算方法を変えられる
カラムごとに計算方法を変えることができるのもメリットです。
例としてratingは平均点、nameはデータ数を出してみます。
df.groupby("demographic").agg({"rating": "mean", "name": "size"})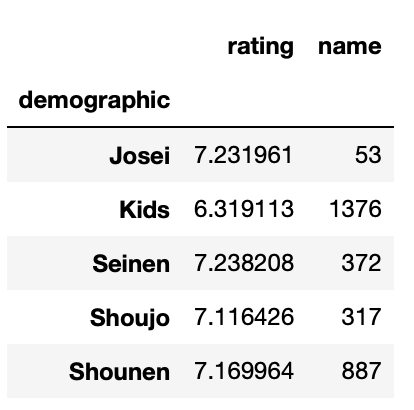
きちんと計算されていることが確認できます。
複数の計算方法も指定可能
さらに複数の計算方法を指定することも可能です。
この場合はlist形式になります。
例として、ratingの平均、標準偏差、データ数をまとめて出してみます。
df.groupby("demographic").agg({"rating": ["mean", "std", "size"]})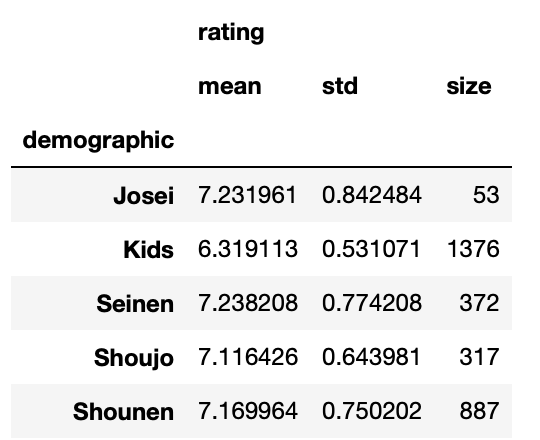
上記の通り、計算方法を複数指定した場合は、マルチカラムになります。
groupby x agg の組み合わせがマジ便利
このように、groupbyとaggを組み合わせると、データの集計方法が格段にレベルアップします。
複数の計算方法をまとめて適用することも可能ですし、カラムごとに異なる計算方法を適用することも可能です。
必要なデータだけが計算されるので、計算の無駄もなくなります。
Python、特にPandasのこういった機能の利便性を知ってしまうと、もうExcelとかには戻れなくなりますw
まとめ
本記事では、「【Pythonコード解説】pandasのgroupbyとaggを組み合わせると便利さが格段に向上します」というテーマでお話ししました。
Pandasにはデータ集計に便利な機能がたくさん備わっています。
その中でも、groupbyとaggを組み合わせるとかなり便利になります。
この機能を知らずに複数行かけて書いていたコードも、groupbyとaggを組み合わせるだけで数行に収まるようになったりもします。
Pythonにはこういった便利なライブラリや機能がたくさん用意されています。
本記事がみなさんのお役に立てれば幸いです。
ここまで読んでくださり、ありがとうございました。




{kind=link}