

こんにちは。TATです。
今日のテーマは「楽天トラベルから収集したデータから東京23区内のコスパ最強のホテルを探す」です。
前回の記事では、レビューデータに焦点をあてて分析を行いました。
今回は価格データに焦点をあてます。
楽天トラベルをスクレイピングして収集した東京23区のホテルデータを使って、コスパ最強のホテルを探してみようと思います。
まずは収集したデータをきれいに整形して、そこからいろいろな角度でデータを見ていきます。
そこから分析を行い、データから見つけ出した特徴などを使って、東京23区内のコスパ最強ホテルを探していきます。
今回の分析の通して良さそうなホテルがいくつか見つかったので今後チャンスがあれば泊まってみようと思います。
事前確認
まずは事前確認として使用するデータを確認しておきます。
収集データ
使用するデータはこちらの記事で収集したものです。
-

Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた
続きを見る
楽天トラベルをスクレイピング
楽天トラベルをスクレイピングして、東京23区内のホテルデータを収集しました。
こちらの記事では、スクレイピングで楽天トラベルからデータを収集して次の2つのデータセットを作りました。
データセット
- df_base: 各ホテルのアクセス情報とレビュー情報をまとめたもの
- df_plan_room: 各ホテルのプラン名と部屋情報(広さとか価格とか)をまとめたもの
データの前処理も完了
収集したデータは前処理を行い、分析に活用できるようにきれいに整形しました。
データ整形方法についてはこちらの記事で解説しています。
-

Pythonで楽天トラベルをスクレイピングして収集したデータを整形する【コード解説】
続きを見る
データの確認
データは2022年9月22日夜に収集したものです。
df_base
df_baseはこんな感じです。
カラムが多いので一部排除しました。

ホテル名をはじめ、主にレビューデータがまとまっています。
df_room_plan
そしてdf_room_planがこちらです。

プラン名やルームタイプ、食事や人数、価格などの情報がまとまっています。
まずはデータをきれいにします
次にデータ整形をおこなっていきます。
すでにデータ整形はある程度終わっているのですが、不要なカラムとか似たようなデータが重複して存在していたりしているので、きれいにしていきます。
行った作業は次の通りです。
データ整形作業
- 面積(平米)と中間価格をベースに外れ値を排除
- 人数と中間価格から部屋価格を計算
- 必要なカラムベースで価格情報を集計
- 不要なカラムを削除
- レビューデータを結合
面積(平米)と中間価格をベースに外れ値を排除
まずは外れ値を排除します。
ここでは面積(平米)と中間価格を使って外れ値を定義しました。
まずは面積(平米)です。
ヒストグラムで見てみると、異常に大きい値があります。
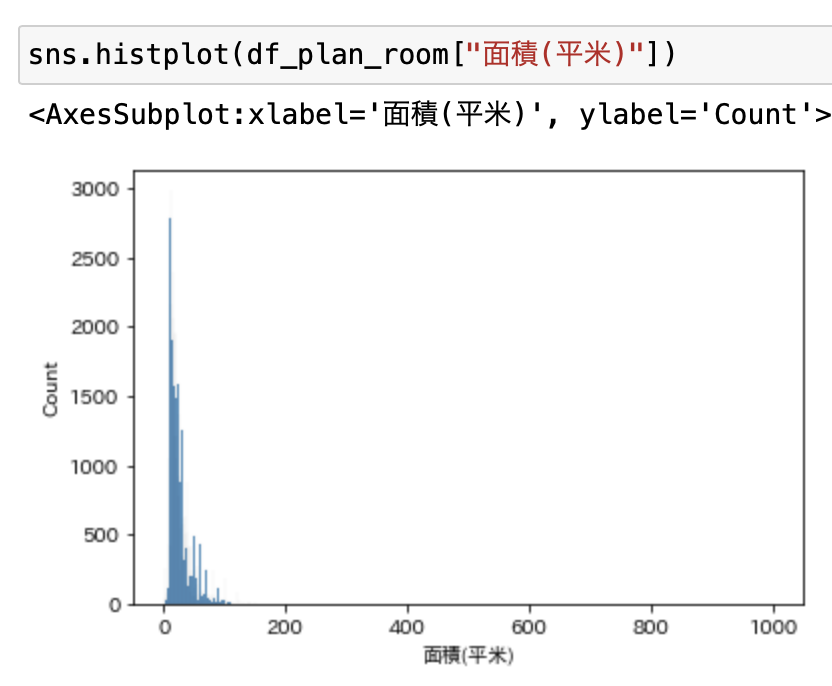
ここでは一律で下位および上位5%を排除しました。
それぞれ11平米と62平米でした。
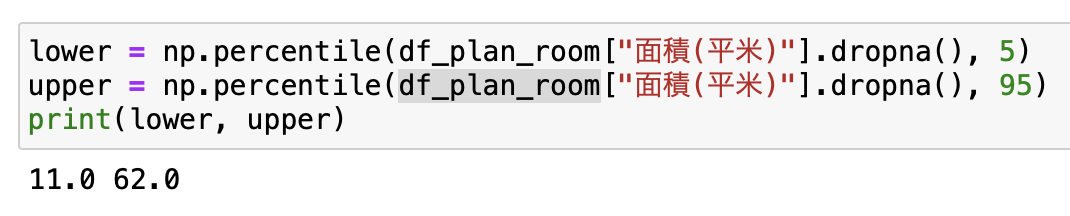
よって面積が11平米〜62平米の範囲に収まらないものは外れ値として排除します。
lower = np.percentile(df_plan_room["面積(平米)"].dropna(), 5) upper = np.percentile(df_plan_room["面積(平米)"].dropna(), 95) df_plan_room = df_plan_room[(df_plan_room["面積(平米)"]>=lower) & (df_plan_room["面積(平米)"]<=upper)] sns.histplot(df_plan_room["面積(平米)"])
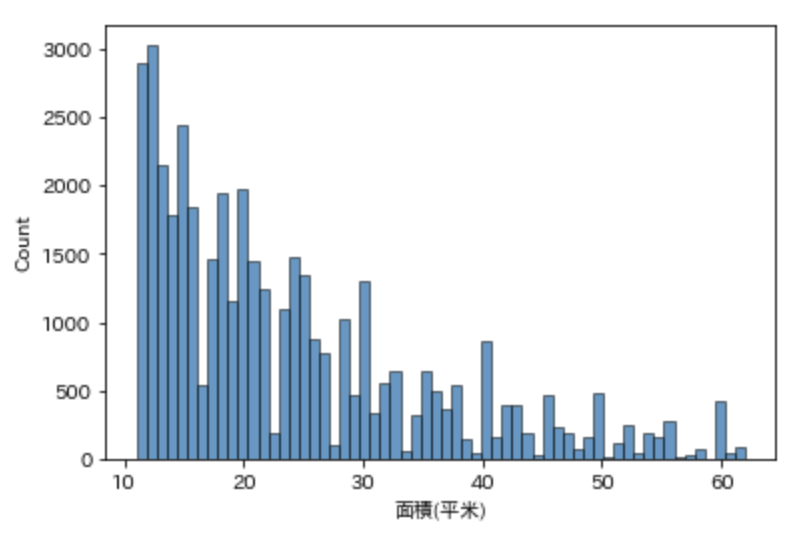
次に中間価格で見てみます。
describe関数でみてみると最低価格1円という明らかにバグった値があります。
上を見ればマックス500万円越えです。
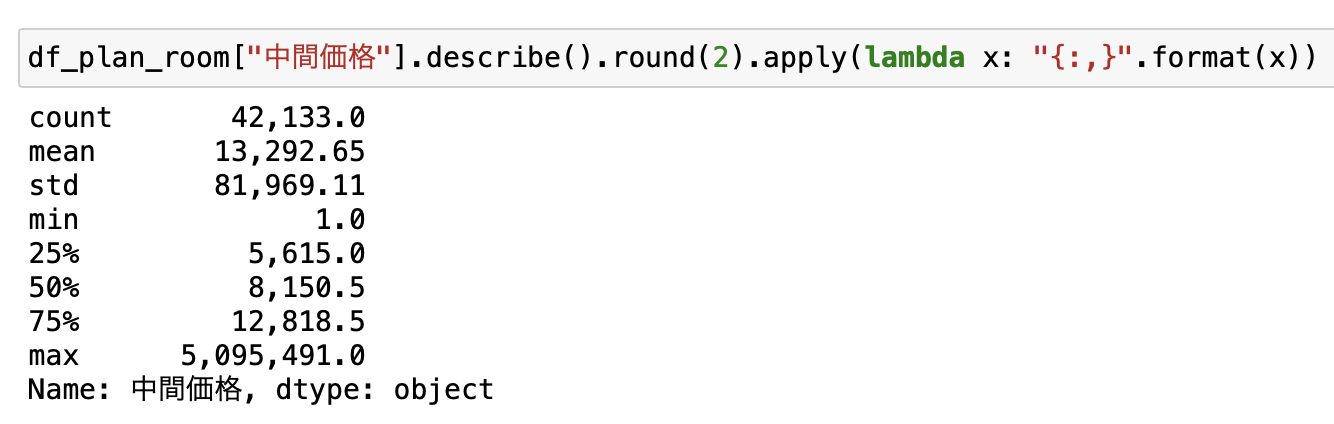
どう考えてもおかしいのでここでも外れ値除去を行います。
1%くらいがちょうど良さそうな感じがしたので、上位と下位1%を除去します。

計算すると下限は2,591円、上限は63,334.12円でした。
upper = np.percentile(df_plan_room["中間価格"], 99)
lower = np.percentile(df_plan_room["中間価格"], 1)
df_plan_room = df_plan_room[(df_plan_room["中間価格"]>=lower) & (df_plan_room["中間価格"]<=upper)]
df_plan_room["中間価格"].describe().round(2).apply(lambda x: "{:,}".format(x))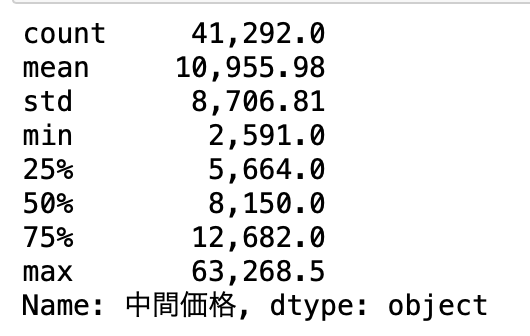
まともな数値になりました。
ヒストグラムもみておきます。
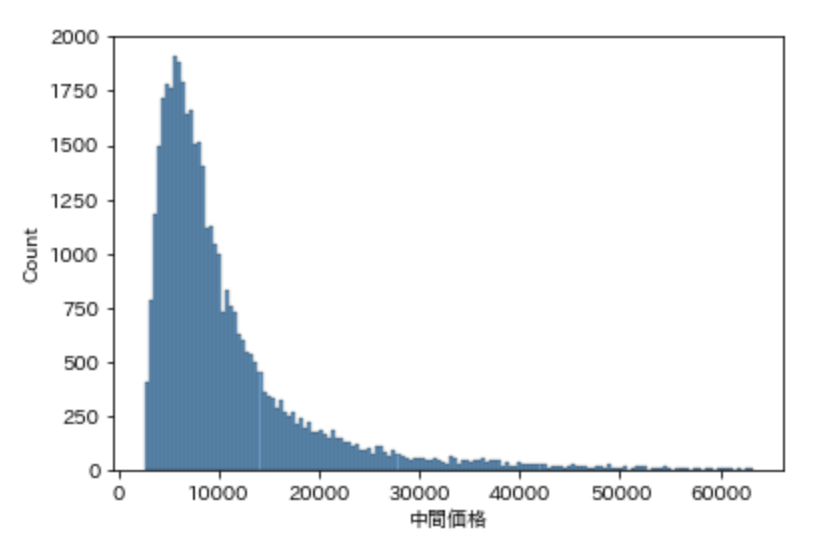
いい感じに対数正規分布になっていますね。
人数と中間価格から部屋価格を計算
次に「人数」と「中間価格」のカラムから「部屋価格」を計算します。
楽天トラベルで表示されている価格は、すべて1人当たりの価格です。
複数人の場合は、人数分を掛け算してあげる必要があります。
df_plan_room["部屋価格"] = df_plan_room["人数"] * df_plan_room["中間価格"] sns.histplot(df_plan_room["部屋価格"])
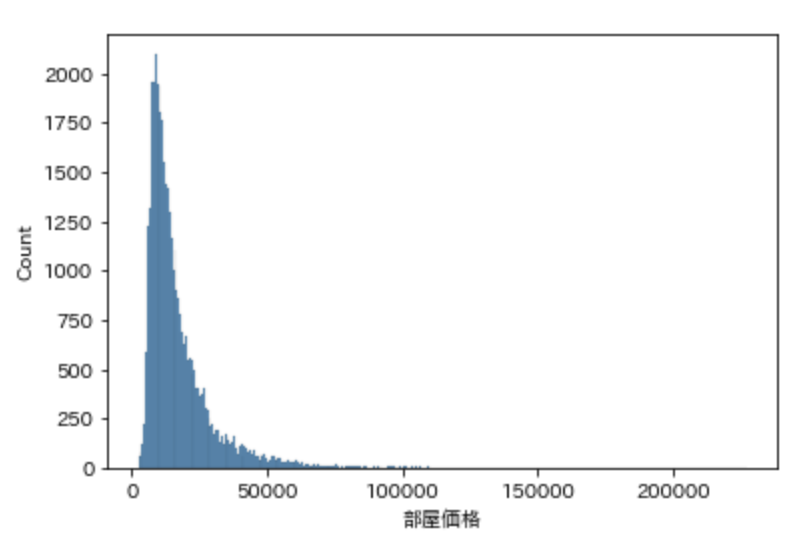
人数分がかけられたので最大価格も上がっていますね。

必要なカラムベースで価格情報を集計
次にデータを少しスッキリさせるために、groupbyを使って集計します。
ここでは「"hotelId", "ルームタイプ", "朝食", "夕食", "面積(平米)", "人数"」ごとに中間価格及び部屋価格の平均を計算しました。
df_plan_room_agg = df_plan_room.groupby(["hotelId", "ルームタイプ", "朝食", "夕食", "面積(平米)", "人数"]).agg({"中間価格": "mean", "部屋価格": "mean"}).reset_index()
df_plan_room_agg.head()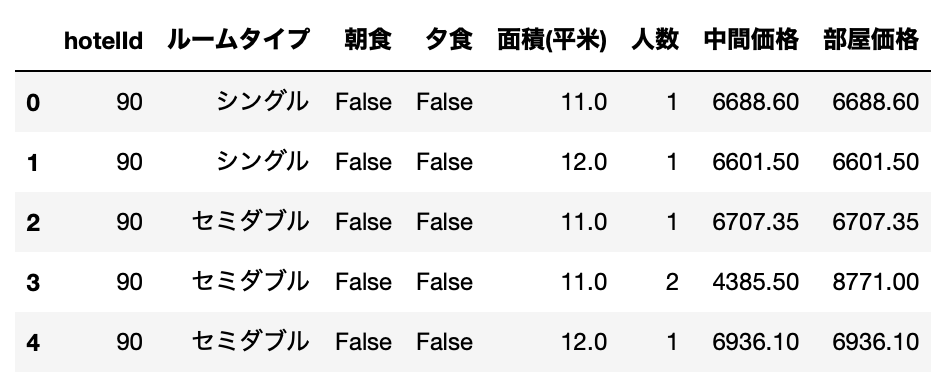
かなりデータがスッキリしました。
ホテルによっては似たようなプランが50個とかあります。
ページ読み込みを遅くなるし、見にくくなるし、もっとスッキリさせればいいのにと感じてしまいますw。
こういったデータをそのまま使うと統計値にも影響してしまうので、ある程度まとめてしまいました。
これでプラン名とか設備とか、余計なカラムも消えました。
不要なカラムを削除してレビューデータを結合
最後に、不要なカラムを削除しつつ、レビューデータを結合します。
価格データは先ほどのgroupbyで不要なカラムはすでに削除しているので、レビューデータだけカラムを絞ります。
df = pd.merge(
df_base[["ホテル名", "hotelId", "総合", "アンケート件数", "区"]],
df_plan_room_agg,
on="hotelId"
)
df.rename(columns={"面積(平米)": "面積"}, inplace=True)
df.head()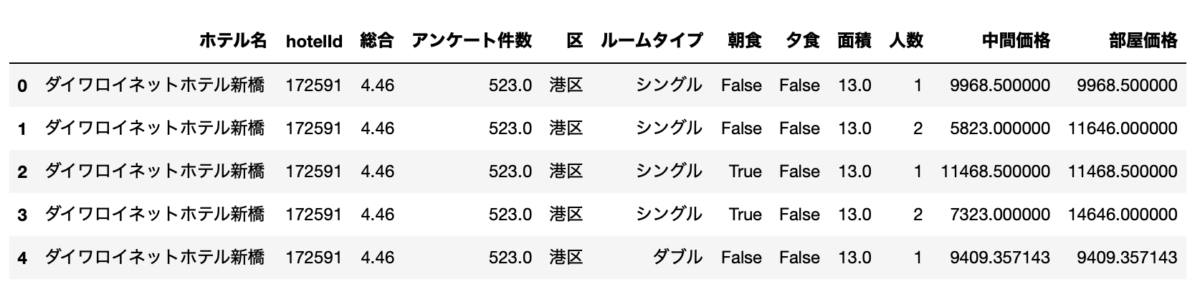
ついでに「面積(平米)」を「面積」に変更しました。
これでデータの準備完了です。
価格データを分析する
データの準備が整ったところで、ここからデータをいろいろみていきます。
面積と価格の関係
まずはシンプルに面積と価格の関係を見てみます。
当たり前ですが、部屋が広ければ値段も高くなるだろうって話です。
px.scatter(data_frame=df[df["人数"]==1], x="面積", y="中間価格")
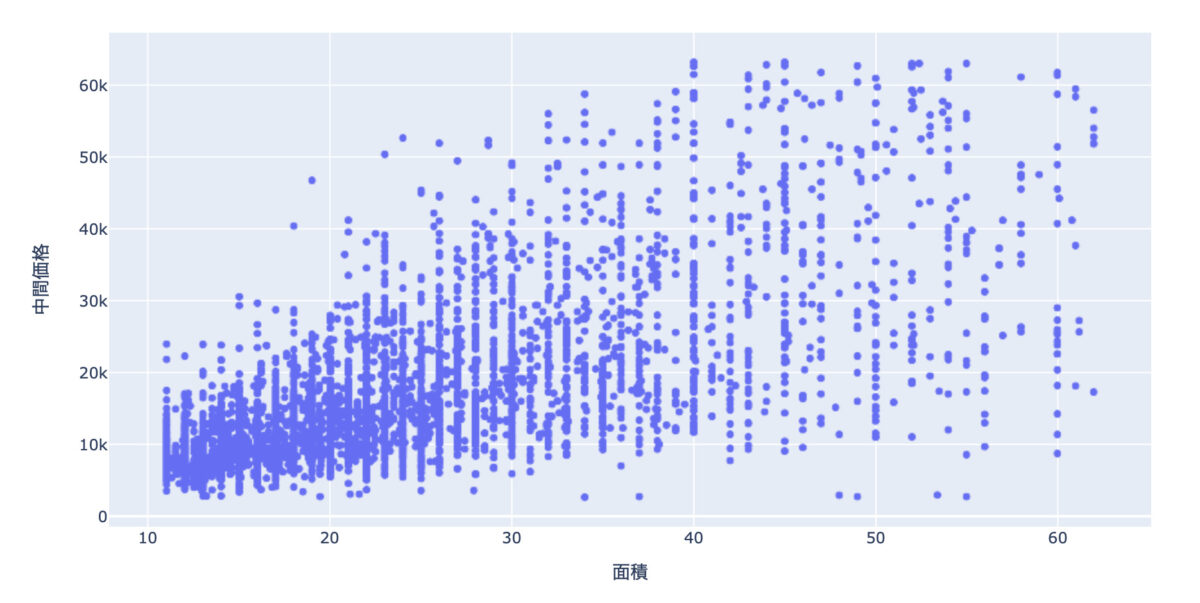
右上がりになっていることがわかります。
ただ、面積がある程度広がっていくと、価格のレンジもかなり広がっています。
部屋の広さが60平米を超えていて、なおかつ価格が2万円を切っているホテルも少なからず存在していることがわかります。
レビューと価格の関係
次にレビューと価格の関係を見てみます。
これには、「総合」カラムを使います。
中間価格との関係を散布図で見てみます。
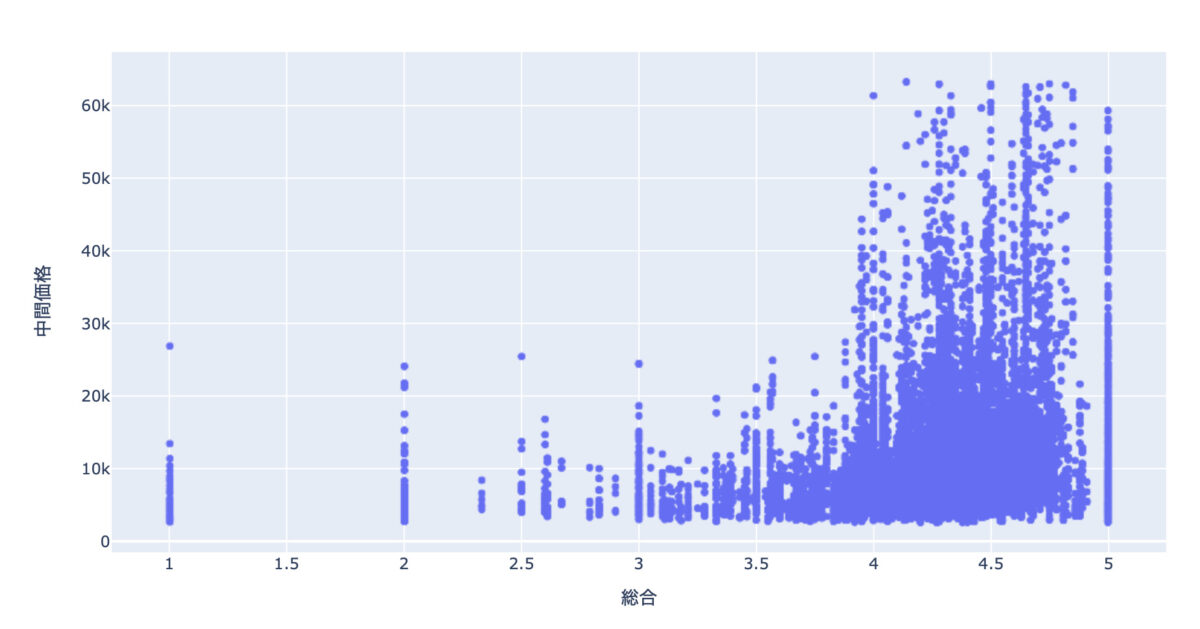
レビューが4をあたりから価格のレンジが大きくなっています。
評価が低いと価格もそれなりですね。
ルームタイプごとの価格の分布
次にルームタイプごとの価格を見てみます。
部屋価格
箱ヒゲ図を使って部屋価格の分布を可視化してみます。
px.box(data_frame=df, x="ルームタイプ", y="部屋価格", color="人数")
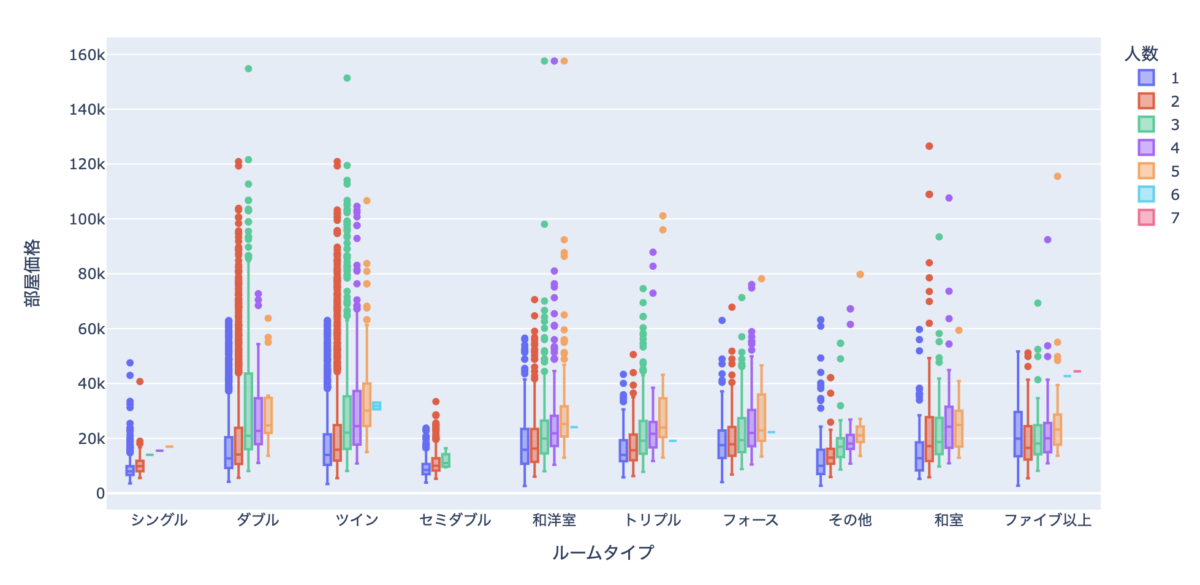
人数別で色を変えてみました。
人数が増えると部屋価格が上がっていることがわかります。
ただ、人数が1人から2人になっても部屋価格が2倍になるということはあまりありません。
中間価格
次に中間価格でもみてみます。
これは人数に関わらず、常に1人当たりの価格です。
px.box(data_frame=df, x="ルームタイプ", y="部屋価格", color="人数")
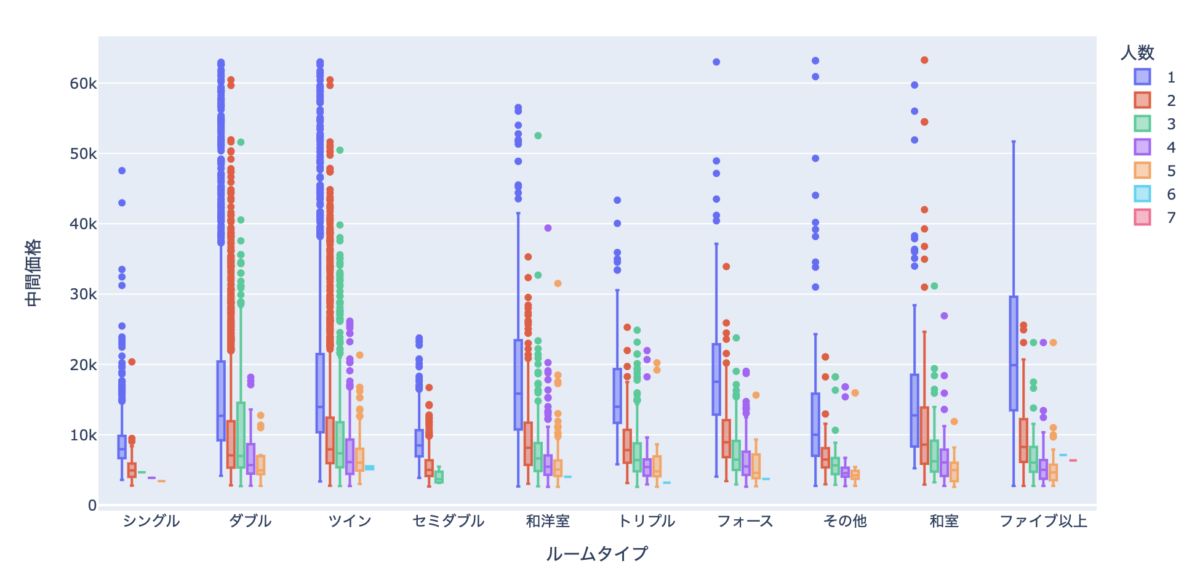
ご覧の通り、人数が多くなるにつれて1人当たりの価格は下がっていきます。
1人で宿泊するのが一番割高です。
複数人でホテルを利用した方がお得であることがわかります。
食事と価格の関係
次に食事が価格に与える影響についてみてみます。
朝食
まずは朝食から見てみます。
人数が1人の場合で絞って比較してみます。
px.box(data_frame=df[df["人数"]==1], x="朝食", y="部屋価格")
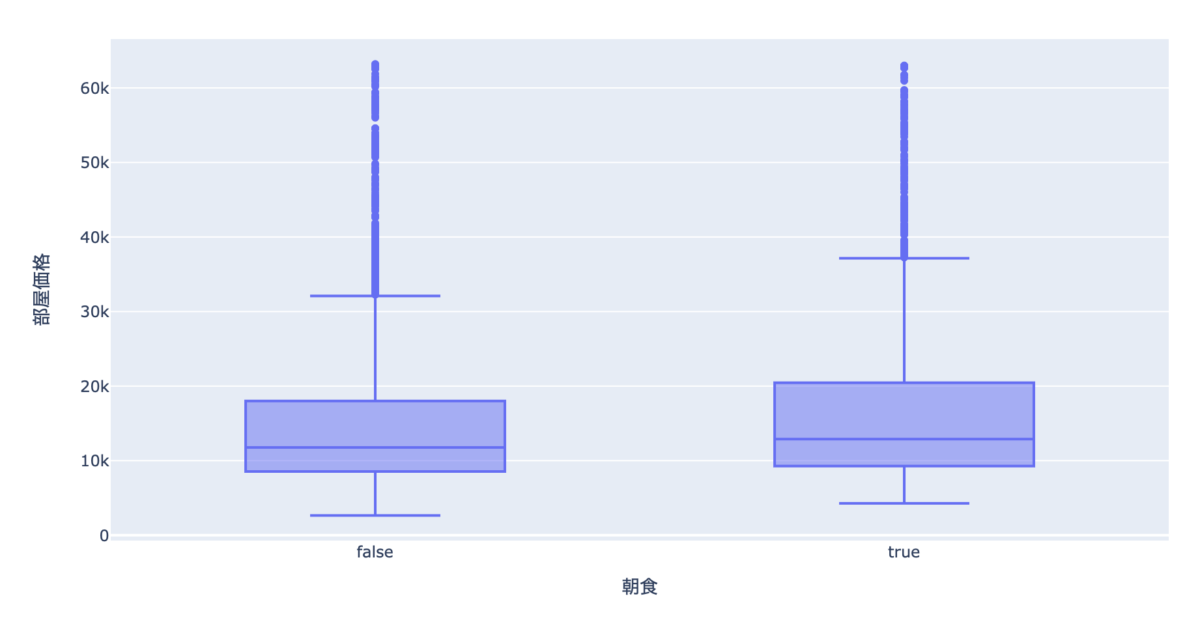
朝食があると少し上がっていますね。

平均で比較してみると、1,700円くらいの差がありました。
夕食
次に夕食です。
px.box(data_frame=df[df["人数"]==1], x="夕食", y="部屋価格")
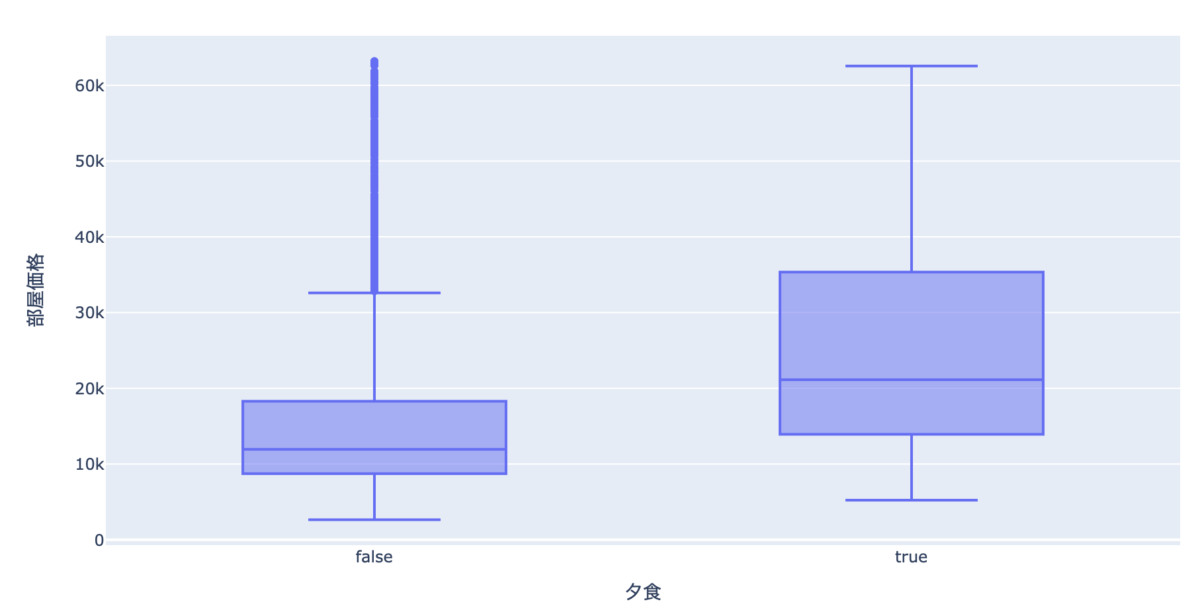
こちらの方が差が大きいですね。
平均で比較すると1万円ほどの差がありました。

コスパを考えたら朝食(個人的に朝から外食は無理w)だけつけて、夕食は1万円以下で外で済ませる感じですかねw
コスパ最強のホテルを探す
ここまでで、データの中身をいろいろ確認できました。
ここからは、これまでの発見を使って、コスパの良いホテルを探してみようと思います。
いいのがあれば今後僕が利用するためですw
条件を設定
まずはコスパの良いホテルの条件を考えます。
これは人によって変わってくると思います。
僕の場合、ホテル選びで大事にしたいことをピックアップしてみました。
TATのホテル選びのポイント
- 広い部屋がいい
- 人数は2人(子供ちっちゃいからカウントされない想定)
- 朝食は欲しい
- 駅近がいい
- 子供も泊まりやすいホテルがいい
- レイトチェックアウト欲しい
ただの願望の塊になってしまいましたが、ざっくりこんな感じです。
広さを求め出すと、どうしても毎回そこそこのホテルを選ぶことになります。
2022年になってからは子供が生まれたので、子連れでも過ごしやすいってのも大事なポイントですね。
ただこの辺は今あるデータから絞ることは難しいので、今回は次の3つのカラムで絞ってみます。
ホテル選びに使う条件
- 面積
- 総合
- 朝食
設定条件でホテルを抽出
それでは早速やってみます。
面積上位10% & 総合上位10% & 朝食あり & 人数2人
まずは手っ取り早く、面積と総合については上位10%に絞って探してみます。

面積は43平米以上、総合評価は4.67点以上です。
これで絞ってみます。
該当ホテルは全部19個ありました。
価格の安い上位10個だけ表示します。
df[(df["人数"]==2) & (df["面積"]>=43.0) & (df["総合"]>=4.67) & (df["朝食"]==True)].sort_values("部屋価格").drop_duplicates("ホテル名", keep="first").head(5)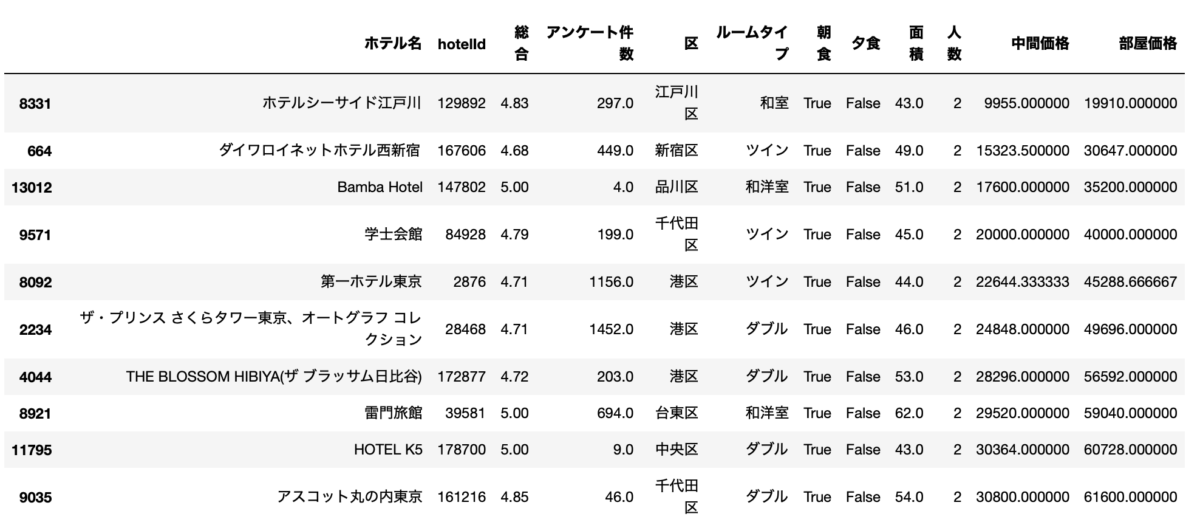
最も安いのはホテルシーサイド江戸川です。
唯一2万円を割っています。
サイトを見ると、葛西臨海公園の近くにあるようです。
施設もきれいでいい感じです。
家族向けなホテルな感じがします。
2位以降は料金が上がってしまいますね。。。
ちょっと総合評価の基準値が高すぎた感じがします。
面積上位10% & 総合平均以上 & 朝食あり & 人数2人
次に少し条件を緩めます。
先ほどの結果は、2位以降は結構高かったので、総合評価の基準を少し下げて、平均点以上にしてみます。
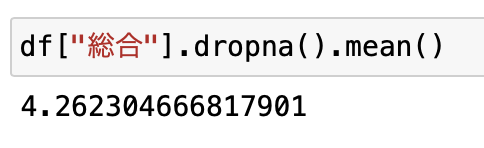
平均点は約4.26点でした。
該当ホテルは56個ありました。
だいぶ増えました。
最も部屋価格の安い上位10個を紹介します。
df[(df["人数"]==2) & (df["面積"]>=43.0) & (df["総合"]>=4.262304666817901) & (df["朝食"]==True)].sort_values("部屋価格").drop_duplicates("ホテル名", keep="first").head(5)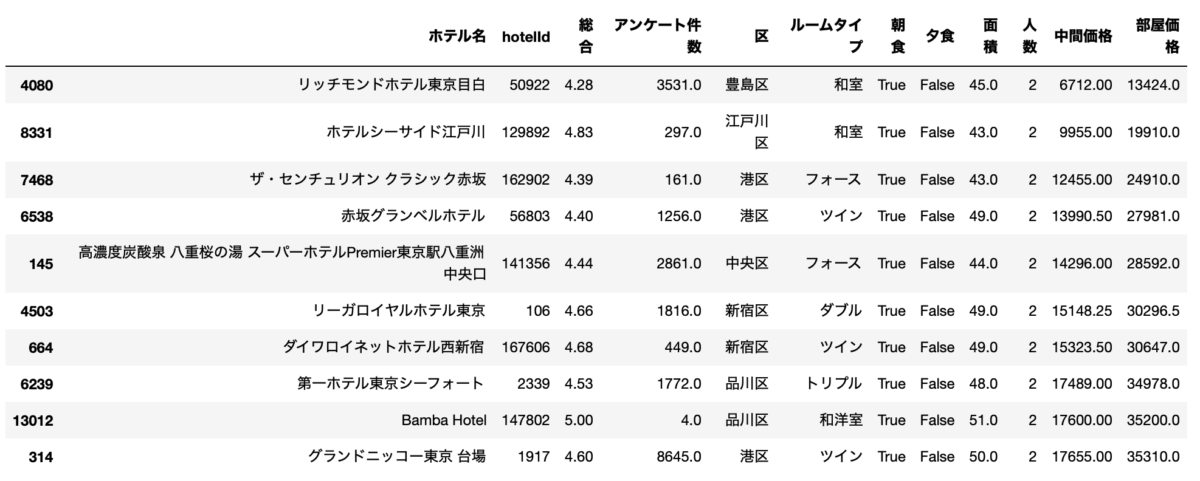
だいぶ価格が下がりました。
1位はリッチモンドホテル東京目白です。
ルームタイプは和室ですが、確認したらベッドがありました。
これはいいですね。
2位は先ほども登場したホテルシーサイド江戸川です。
3位のザ・センチュリオン クラシック赤坂もかなりいいですね。25,000円を切っています。
面積上位10% & 総合上位10% & 人数2人
次に朝食を条件から外してみます。
朝食は持ち込んでもいいですし、ルームサービスでもいいですからね。
まずは最も厳しい条件で見てみます。
面積と総合で上位10%を満たしているホテルです。
該当ホテルは35個ありました。
トップ10を見てみます。
df[(df["人数"]==2) & (df["面積"]>=43.0) & (df["総合"]>=4.67)].sort_values("部屋価格").drop_duplicates("ホテル名", keep="first").head(10)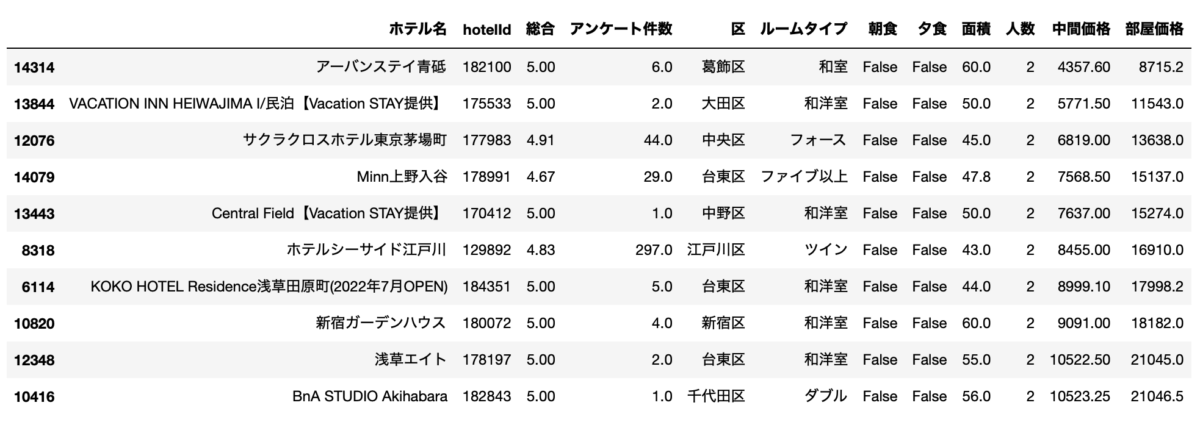
朝食を外しただけで一気に価格が下がりましたw
1位はアーバンステイ青砥です。
良さそうですが、子供連れていくなら青砥はちょっとね、、、という感じがしますw(青砥に住んでる人ごめんなさい)
2位のVACATION IN HEIWAJIMA I/民泊はVacation Stayなんでこれも少し違いますかね。
実質的な1位は3位のサクラクロスホテル東京茅場町でしょうか。
外観は古めですが、内装はとてもきれいです。
家族で過ごすにはとても良さそう。
面積上位10% & 総合平均以上 & 朝食あり & 人数2人
最後に一番緩い条件で探してみましょう。
総合評価を平均以上に落として、なおかつ朝食を外します。
該当ホテルは88個ありました。
上位10個をみてみましょう。
df[(df["人数"]==2) & (df["面積"]>=43.0) & (df["総合"]>=4.262304666817901)].sort_values("部屋価格").drop_duplicates("ホテル名", keep="first").head(10)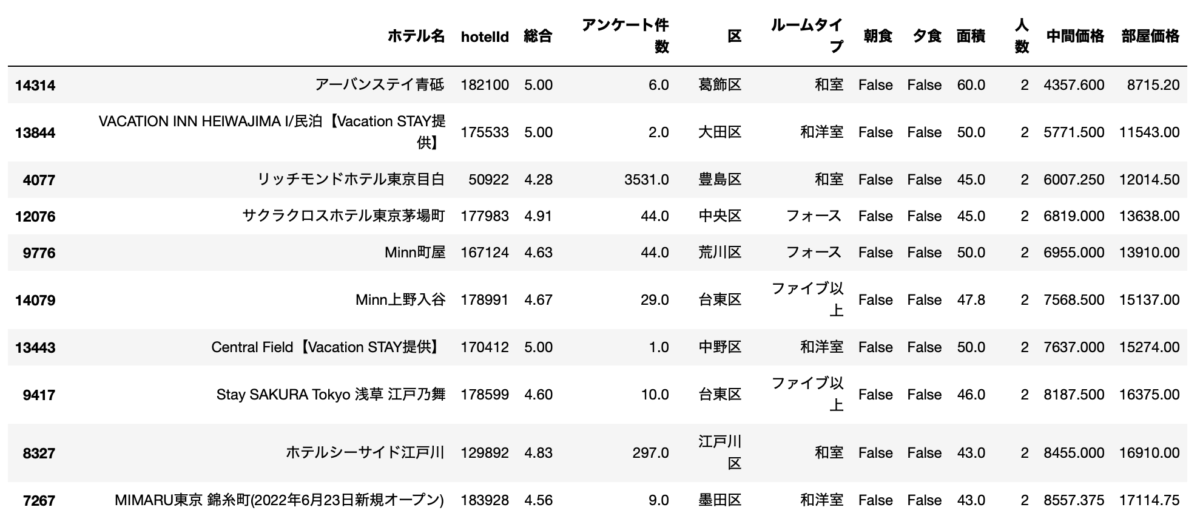
同じようなホテルが並んでいますね。みたことあるホテルばかりですw
違うのが8位のStay SAKURA Tokyo 浅草 江戸乃舞と10位のMIMARU東京 錦糸町です。
結論、この2つがめちゃくちゃいいですね。
どちらもキッチンを完備しているお部屋で、長期滞在をターゲットにしているようです。
ホテルというより、おしゃれできれいなサービスアパートメントみたいな感じです。
特に小さい子供がいると、キッチンあるとめちゃ便利なんですよね。
ちょっといいところを見つけてしまいました!
そしてこのStay SAKURAとMIMARUは東京だけでなく、京都や大阪(2022年10月現在では大阪はMIMARUだけ)にもあるようです。
旅行するときに利用したらめちゃくちゃ便利そうです。
データを見ながらいいホテルが見つかりました。
大満足ですw
そして少し調べてみたら、MIMARUはウェルカムベビーのお宿に認定されていました。
最高すぎる。。。!
データを通して、かなり良さそうなホテルを見つけることができました。
チャンスがあれば利用してみようと思います。
【追記】京都旅行でMIMARU京都 Stationを利用してきました
この分析を踏まえて、2022年11月下旬に京都旅行へ行った際にMIMARU京都 Stationを利用してみました。
めちゃくちゃよかったです!データ分析で発見したホテルに実際に泊まることができてワクワクしました。
-

【赤ちゃん・子連れに最高】「MIMARU京都 STATION」宿泊記【データ分析で発見したホテル】
続きを見る
まとめ
本記事では、「楽天トラベルから収集したデータを使って東京23区内のコスパ最強のホテルを探す」というテーマで、楽天トラベルをスクレイピングしたデータを使って、東京23区内にあるコスパ最強のホテルを探してみました。
結論、僕が求めている条件にマッチするとても良いホテル(Stay SAKURAとMIMARU)を見つけることができました。
どちらも東京だけではなく、大阪や京都にも展開しているので、旅行の時に重宝しそうです。
今後別のエリアにも進出して欲しいですね。
データからホテルを探していくと、サイトからでは見つけることが難しいホテルを見つけ出すことができます。
サイトではできないいろいろな条件を設定して、マッチするホテルを抽出することができます。
ここでは僕の利用のために子連れとかを考慮したお部屋選びになりましたが、出張時に利用するビジネスホテルとか、1人旅に使えるホテルとか、さまざまな条件でホテルを探してみると楽しそうです。
やっぱりPythonは便利ですね。
スクレイピングもデータ分析もデータの可視化も比較的に短いコードで実装できてしまいます。
結果として、普通とは違う方法で、サイトを見てるだけではなかなか見つけることができなさそうなホテルを見つけることができました。
データ分析最高です。
今後もこういったデータ分析関連の記事は積極的に増やしていこうと思います。
何より僕自身がやっていて楽しいのでw
ここまで読んでくださりありがとうございました。
-
【赤ちゃん・子連れに最高】「MIMARU京都 STATION」宿泊記【データ分析で発見したホテル】
続きを見る




{kind=link}