

こんにちは。TATです。
今日のテーマは「楽天トラベルから収集した東京23区内のホテルのレビューデータを分析する」です。
楽天トラベルをスクレイピングで収集した東京23区内のホテルデータを分析していきます。
本記事で焦点を当てるのはレビューです。
全体の分布や項目別のレビューとの相関などをみていきます。
最後に、分析結果を踏まえて良さげなホテルもピックアップしてみました。
目次
事前確認
まずは事前確認として使用するデータを確認しておきます。
収集データ
使用するデータはこちらの記事で収集したものです。
-

Pythonで楽天トラベルをスクレイピングして東京23区のホテルデータを収集してみた
続きを見る
楽天トラベルをスクレイピング
楽天トラベルをスクレイピングして、東京23区内のホテルデータを収集しました。
こちらの記事では、スクレイピングで楽天トラベルからデータを収集して次の2つのデータセットを作りました。
データセット
- df_base: 各ホテルのアクセス情報とレビュー情報をまとめたもの
- df_plan_room: 各ホテルのプラン名と部屋情報(広さとか価格とか)をまとめたもの
データの前処理も完了
収集したデータは前処理を行い、分析に活用できるようにきれいに整形しました。
データ整形方法についてはこちらの記事で解説しています。
-

Pythonで楽天トラベルをスクレイピングして収集したデータを整形する【コード解説】
続きを見る
データの確認
データは2022年9月22日夜に収集したものです。
df_base
df_baseはこんな感じです。
カラムが多いので一部排除しました。

ホテル名をはじめ、主にレビューデータがまとまっています。
df_room_plan
そしてdf_room_planがこちらです。

プラン名やルームタイプ、食事や人数、価格などの情報がまとまっています。
レビューデータを分析する
それでは、ここからレビューデータに焦点を当てて分析を行っていきます。
データの全体像を確認する
まずはデータの全体像を確認していきます。
統計値を見る
基本的な統計値の確認からしていきます。
describe関数を使うと楽ちんです。
総評価を示す「総合」カラムで見ていきます。
df_base["総合"].describe().round(2)
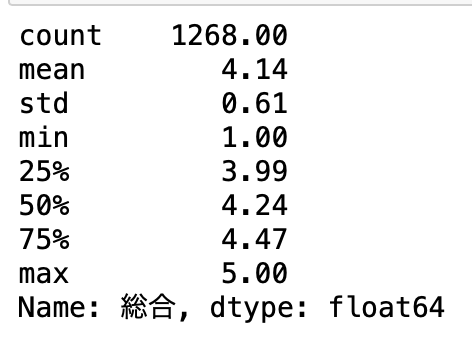
平均点が4.14点、中央値が4.24点です。
結構高いですね。
ヒストグラムで見る
次に「総合」カラムをヒストグラムで見てみます。
ここではplotlyを使います。
ラベル名とか適当ですみません。
import plotly.express as px px.histogram(df_base["総合"])

少々いびつですが、おおむね正規分布になっています。
4~4.5にピークがあることがわかります。
レビューなしのホテルについてみてみる
次に「総合」カラムの値がないホテルについてみてみます。
Nullが結構多かった
「総合」カラムがNullとなってるホテルを調べました。
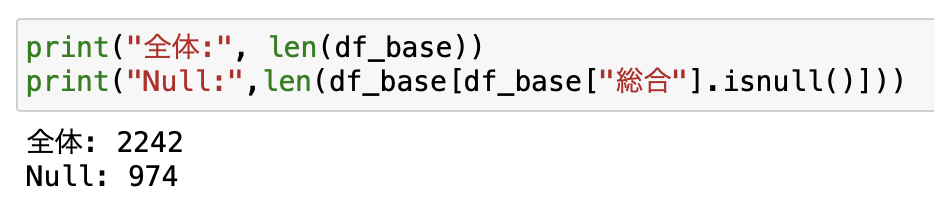
全体で2,242個のホテルがありますが、総合のカラムがNullとなっているホテルが974個もありました。
多すぎますね。4割以上のホテルでレビュー点数がない結果になりました。
レビューがNullになる理由
レビューがNullになる1番の理由はアンケート件数がないからです。
当たり前ですが。。。
px.histogram(df_base[df_base["総合"].isnull()]["アンケート件数"])
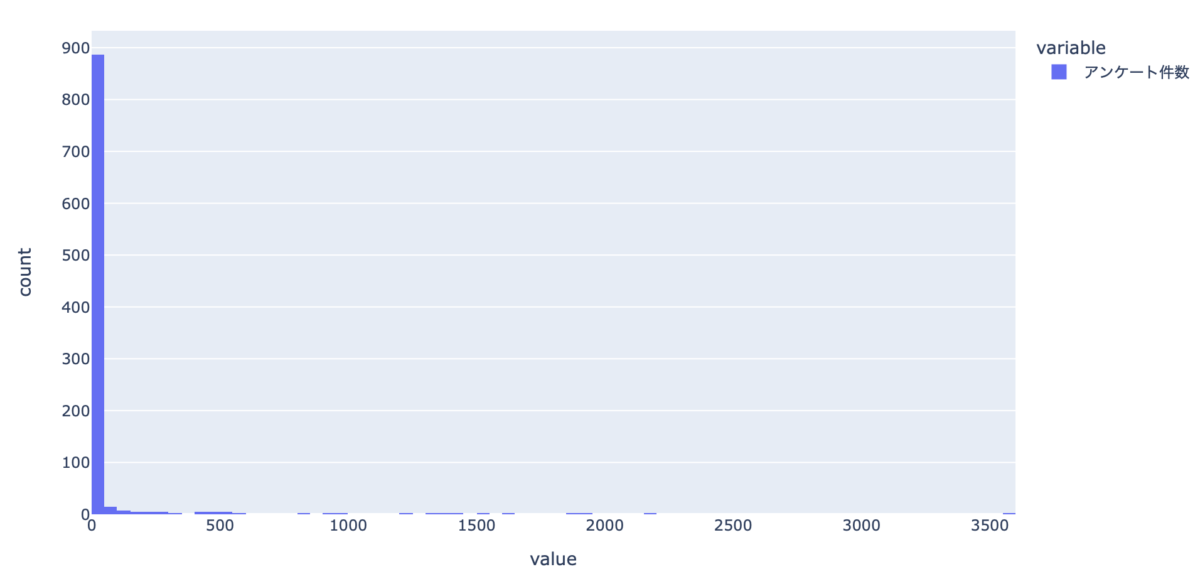
ただ、上記のヒストグラムを見ると3,000件以上のアンケート件数があるのに評価がNullとなっているホテルもあります。
ちなみにこのホテルは「新宿ワシントンホテル 新館」でした。
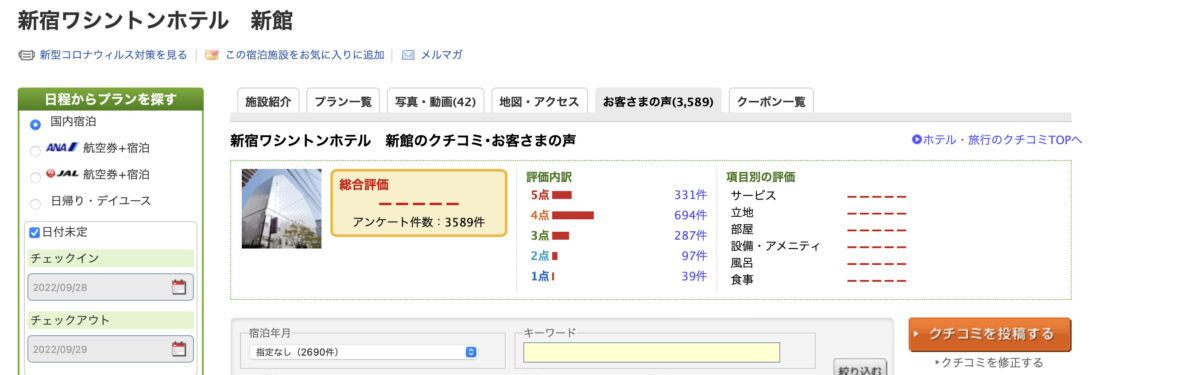
確かに該当ページを見ると総合評価が"-----"となっていました。
アンケート件数は3589件もあるのに謎ですね。
こういうパターンはいくつか存在します。
調べてみたら、アンケート件数が100個以上あって総合評価がないホテルは
47個ありました。

ちなみにアンケート件数が1件でも総合評価がついているホテルも存在します。
ここの理由は謎ですね。。。
一瞬、「最近リニューアルオープンしたホテルとかかな」とも思いましたが、いくつかホテルを見ていたらそんなことはなさそうでした。
謎です。。。
基本はアンケート件数が0のため総合評価もNullになっていますが、結構例外もあります、という結論でした。

総合評価と相関の高い要素を調べる
次に少しデータの見方を変えてみます。
総合評価の高いホテルにはどのような特徴があるのか、相関の高い要素を見てみます。
項目別の評価との相関を見てみる
レビューデータには項目別のものがあります。
サービス, 立地, 部屋, 設備・アメニティ, 風呂, 食事の6項目があります。
「総合」とこれらの相関を見てみます。
df_corr = df_base[['総合', 'サービス', '立地', '部屋', '設備・アメニティ', '風呂', '食事',]].corr()["総合"].round(2).sort_values(ascending=False) px.bar(df_corr, text=df_corr)
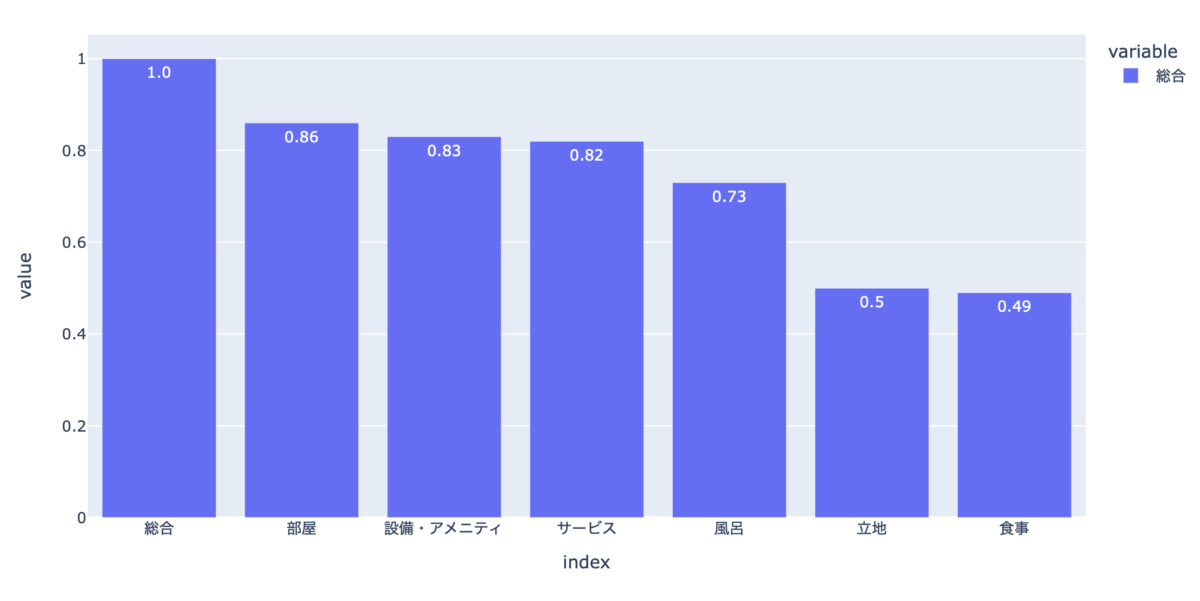
相関を見ると、総合は当然1なのでおいておいて、それ以降ですと、部屋や設備・アメニティ、サービスが高い相関を出しています。
少し下がって風呂が0.73、最後は立地と食事が0.5くらいの結果となりました。
面白いですね。
やはりホテルですから一番気にされるのは部屋です。
そこに備わっている設備とアメニティも大事になってきます。
総合評価を上げるには、立地とか食事よりもまず部屋が一番大事です。
逆を言えば、立地がそこまで良くなくても部屋とかサービスが素晴らしければ十分に戦えるとも捉えることができますね。
価格別で相関を見てみる
次に価格を加味して相関を見てみます。
これには、df_plan_roomにある中間価格を使います。
各ホテルに対して人数1人の場合の平均中間価格を計算してdf_baseに結合します。
df_price = df_plan_room[df_plan_room["人数"]==1].groupby("hotelId").agg({"中間価格": "mean"}).reset_index()
df = pd.merge(
df_base,
df_price,
on="hotelId",
how="left"
)
df.drop(["住所", "交通アクセス", "駐車場", "url"], axis=1).head()
統計値を見てみます。
df["中間価格"].describe().round(2)
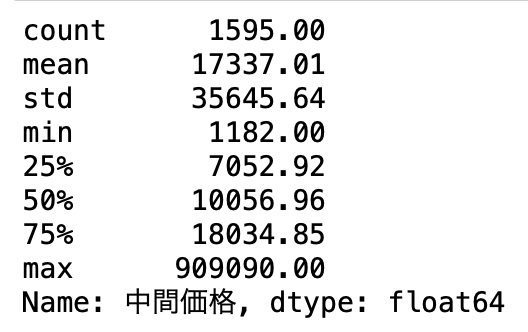
平均価格が17,337.01円です。中央値はおよそ1万円ですね。
最低価格は1,182円で最高価格は909,090円ですw
安すぎても高すぎてもよろしくないので、いい感じに収めるために、ここでは下位5%と上位5%を排除します。
それぞれ3,499.1125円と45,615円でした。

フィルターした結果、価格がNullのホテルも排除されて1436個になりました。
ちなみにNullは予約受付を停止しているホテル、あるいは1人の価格が設定されていないホテルで全部で647個ありました。
多いですね。

データを見やすくするために、ちょっと工夫して価格を5つのグループに振り分けて比較してみました。
# 中間価格を5つのグループに分ける
df2["グループ"] = pd.cut(df2["中間価格"], 5)
# 相関を計算
df2_corr = df2[['総合', 'サービス', '立地', '部屋', '設備・アメニティ', '風呂', '食事','グループ']].groupby("グループ").corr()[["総合"]].reset_index()
# 可視化
px.bar(data_frame=df2_corr[df2_corr["level_1"]!="総合"].round(2), x="level_1", y="総合", color="グループ", barmode="group", text="総合")
結構差が出ましたね。
立地や食事だとほとんどの場合は相関が低いですが、オレンジ色の37192.1円以上のちょっと高級なホテルでは相関が高い結果となりました。
高級ホテルだと立地も食事も重要になってくるようです。
というより、高級ホテルだと全ての項目で相関が高くなりますね。
期待値も高いでしょうから当然と言えば当然です。
立地が悪いところに高級ホテルを作ったらダメということがわかりますねw
総合評価と各点数の分布との関係を見る
次に総合評価と各点数の分布をみてみます。
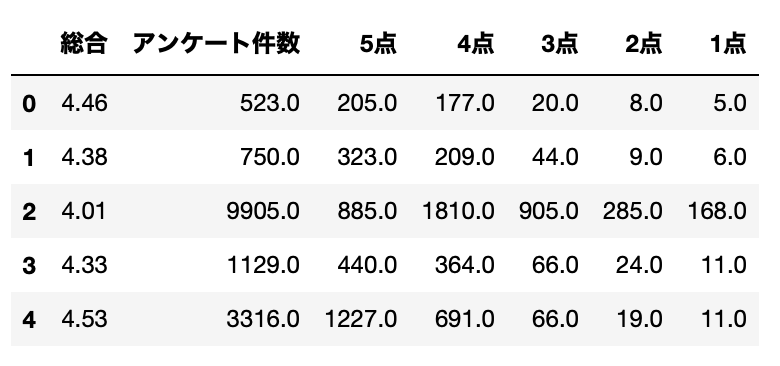
df_baseには、「総合」カラムにある総合評価と、各点数の件数があります。
df_base[["総合", "アンケート件数", "5点", "4点", "3点", "2点", "1点"]].head()
各点数の平均点を算出する
まず、各点数の平均点を計算してみます。
import re
def calculate_average_review_rate(x):
l = []
for col in ["5点", "4点", "3点", "2点", "1点"]:
num = int(re.findall(string=col, pattern=r"[0-9]")[0])
if not pd.isnull(x[col]):
l.extend([num]*int(x[col]))
return round(np.mean(l), 2)
df_base["平均点"] = df_base.apply(calculate_average_review_rate, axis=1)
リストに各点数を件数分格納して平均を計算しました。
総合評価と平均点の差分を調べる
次に総合評価と先ほど計算した平均点の差分を計算します。
結果をヒストグラムで見てみます。
df_base["差分"] = df_base["総合"] - df_base["平均点"] px.histogram(df_base["差分"])
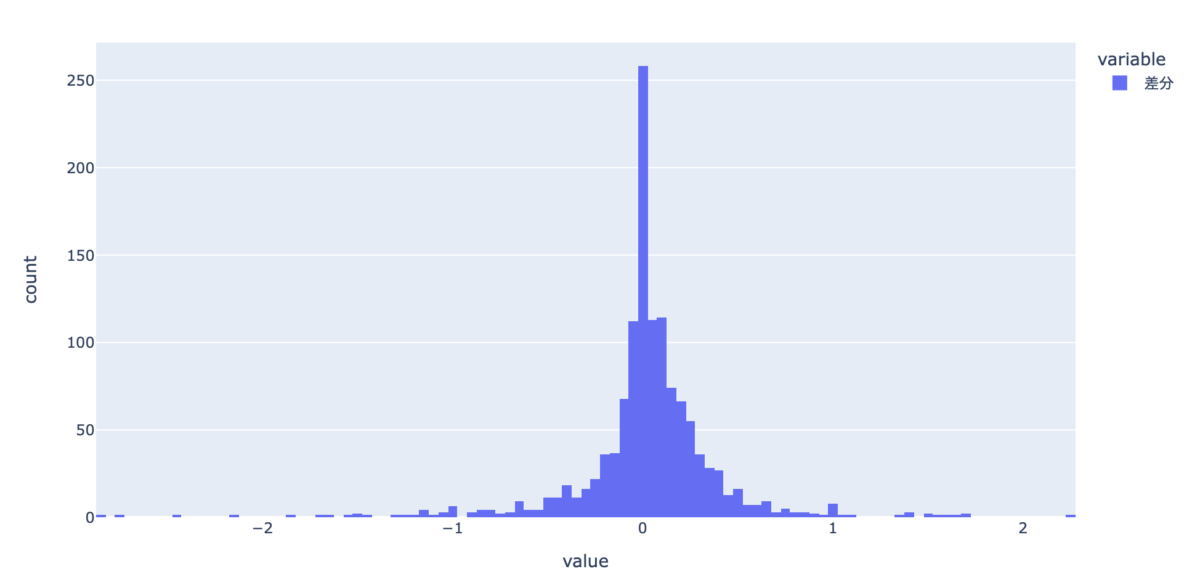
綺麗な正規分布になりました。
ただ差分がかなり大きいホテルも存在します。
統計値を確認したら、平均で0.03、中央値で0.02、最小値は-2.83、最大値は2.25でした。

アンケート件数と差分を関係を見てみる
お次にアンケート件数と差分の関係を見てみます。
差分を絶対値にして散布図で可視化しました。
df_base["差分(絶対値)"] = df_base["差分"].abs() px.scatter(data_frame=df_base, x="アンケート件数", y="差分(絶対値)", log_x=True)
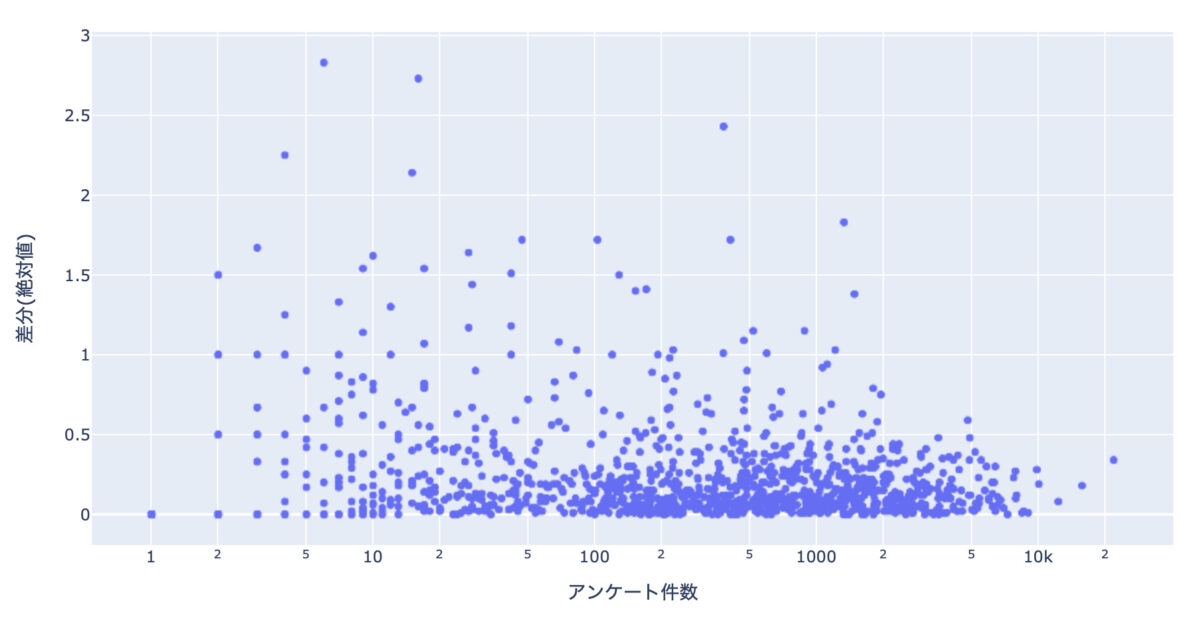
アンケート件数(x軸)は対数表示にしています。
みた感じ相関はなさそうですね。。。
個人的に、「もしかしたらアンケート件数が多いと昔にレビューよりも最近のレビューを重視するようになって、そうなってくると件数が多くなると差分も大きくなるのかな」と勝手に思っていましたが、違ったようでした。
差分を大きいホテルを見てみる
次に差分の大きいホテルをピックアップしてみます。
先ほどの統計値を使って外れ値を計算します。
平均(m)と標準偏差(s)からm±2sを計算します。

この基準値を超えるものを外れ値を判断して抽出します。
該当ホテルは70個ありました。

差分の大きいホテルのサイトを確認したら直近のレビューが影響しているっぽい
差分が大きいと判定したホテルを確認してみます。

冒頭5行だけですが、差分の大きいものが並んでいます。
平均点に対して総合がやたら高いものと低いものが存在しています。
ここから先はデータからでは調べようがないので、サイトを確認してみます。
レビューのスクショは載せていいのかわからないので、調べた結果だけお伝えします。
結論、直近のレビューの影響が大きいと思います。
総合点が平均点よりも低いホテルは、直近のレビューでネガティブなものが多かったです。
逆に総合点が平均点よりも高いホテルは直近のレビューがとても良いものが多かったです。
差分が大きいホテルは直近で変化が起きてる可能性が高い
ここまでの内容を踏まえると、計算ロジックまではわかりませんが、何かしらの方法で直近のレビューに重みをつけて総合点を評価しているのではないかと思いました。
そしてこの方がいいですよね。
リニューアルをしたり、サービスが改悪したり、何かしらの変化があれば、ホテルの評価にも大きく影響を与えます。
楽天トラベルの総合点を見れば、直近のレビューがより重視されているので、こういった変化を加味した上での点数をパッと判断できるわけです。
逆に総合点と平均点の差分が少ないホテルは安定しているとも言えそうです。
特にレビュー数が多くて差分が少ないホテル、なおかつ総合点数が高いホテルは安定感抜群のホテルと言えますね。
分析に基づいて良さげなホテルを探してみた
ここまで分析で色々わかってきました。
ここからは分析結果に基づいて良さそうなホテルを探してみます。
安定感抜群のホテルTOP5
まずは安定化抜群のホテルを弾き出してみます。
これは、アンケート件数がある程度あって、なおかつ総合点と平均点の差分が少ないホテルです。
アンケート件数が多い上位10%(1,666.6個以上)のホテルで、なおかつ差分(絶対値)が小さい下位25%(0.04以下)のなかで、総合点数の高いホテルTOP5を出してみます。
cols = ["ホテル名", "総合", "平均点", "差分", "アンケート件数"]
df_base[(df_base["アンケート件数"]>=1666.6) & (df_base["差分(絶対値)"]<=0.04)].sort_values("総合", ascending=False).head()[cols]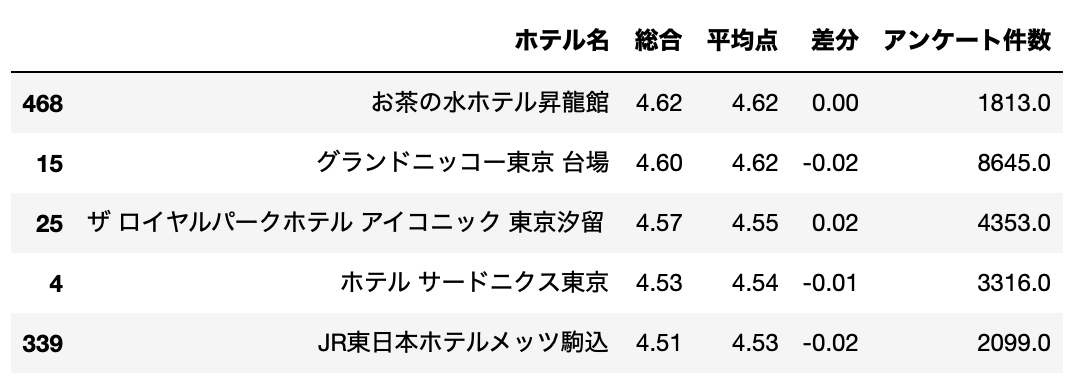
1位はお茶の水ホテル昇竜館でした。
サイト見るとわかりますが、お茶の水という東京のど真ん中にあるにもかかわらず隠れ家みたいなお宿です。
めちゃ行ってみたい。。。
2位以降は、グランドニッコー東京 台場、ザ ロイヤルパークホテル アイコニック 東京汐留、ホテル サードニクス東京、JR東日本ホテルメッツ駒込でした。
こういう探し方は結構面白いですね。
評価が急回復してるホテルTOP5
次に少し角度を変えて、評価が急回復しているホテルTOP5を見てみます。
アンケート件数が多い上位10%(1,666.6個以上)のホテルでなおかつ差分が最も大きい上位25%(0.35以上)のなかで、総合点数の高いホテルTOP5を出してみます。
cols = ["ホテル名", "総合", "平均点", "差分", "アンケート件数"]
df_base[(df_base["アンケート件数"]>=1666.6) & (df_base["差分"]>=0.35)].sort_values("総合", ascending=False).head()[cols]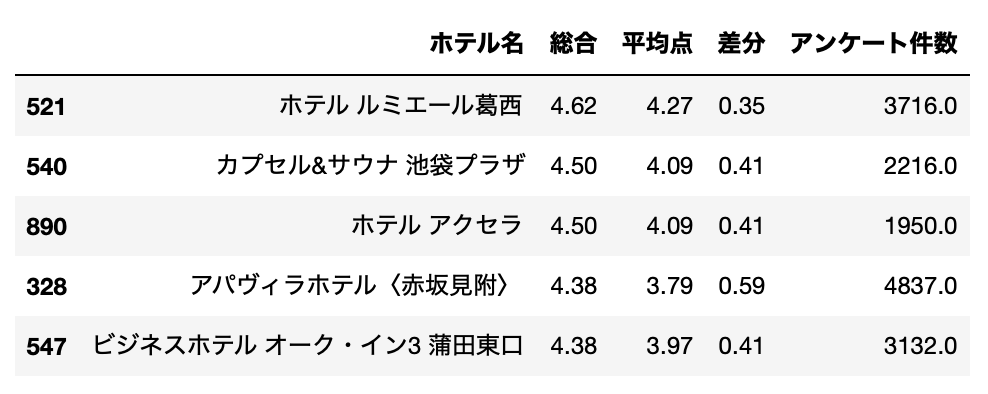
1位はホテル ルミエール葛西でした。
レビューを見ていると改装工事をして内装がかなり綺麗になったようです。
結果として直近のレビュー評価が上がり、平均点も大きく上回る結果となっています。
2位以降は、カプセル&サウナ 池袋プラザ、ホテル アクセラ、アパヴィラホテル 〈赤坂見附〉、ビジネスホテル オーク・イン3 蒲田東口でした。
この平均点と総合点の差分を見たら、直近で変化のあったホテルを効率的に探せそうです。
まとめ
ここでは「楽天トラベルから収集した東京23区内のホテルのレビューデータを分析する」というテーマで、先日楽天トラベルをスクレイピングして収集した東京23区内のホテルを対象に、レビューデータを分析してみました。
いろいろな発見がありました。
特に直近のレビューが総合点により影響しているという発見は個人的に面白かったです。
この特徴を活用して、新しいホテルの探し方も発見することができました(いつ必要になるのかはわかりませんがw)。
本記事ではレビューデータに焦点を当てましたが、次は別の角度からデータを分析したいですね。
とりあえず今回はここまでにします。
最後になりますが、本記事の分析には全てPythonを使っています。
データ分析にはPythonが最適です。
比較的短いコードでデータ処理も可視化も簡単に実装できるので、少し勉強すれば結構使えます。
僕自身、Pythonは社会人になってから独学で習得したので、興味のある方は是非ともトライしてみてはいかがでしょうか。
データ分析やデータサイエンス、AIに興味のある方にもPythonはおすすめです。
最後まで読んでくださり、ありがとうございました。




{kind=link}