

こんにちは。TATです。
今日のテーマは「整然データが一瞬で作れるPandasのmelt関数の使い方を徹底解説!【Pythonコード解説】」です。
Pandasに備わっている機能であるmelt関数について解説します。
理解できるととっても便利な関数なのですが、いかんせんイメージがつきにくくて理解に苦労しがちな関数なので、本記事で丁寧に解説していきたいとおもいます。
半分は僕の備忘録用ですw
一言で言えば、Pivotの逆のことをしてくれるのがmelt関数です。
本ブログらしく、株価データを例にして解説していきます。
Pandasのmelt関数の概要

まずはmelt関数の概要について見てみましょう。
meltはpivotの逆
melt関数を一言で説明すると「Pivotの逆」です。
Wikipediaで見つけた画像を使って関係図を作ってみました。
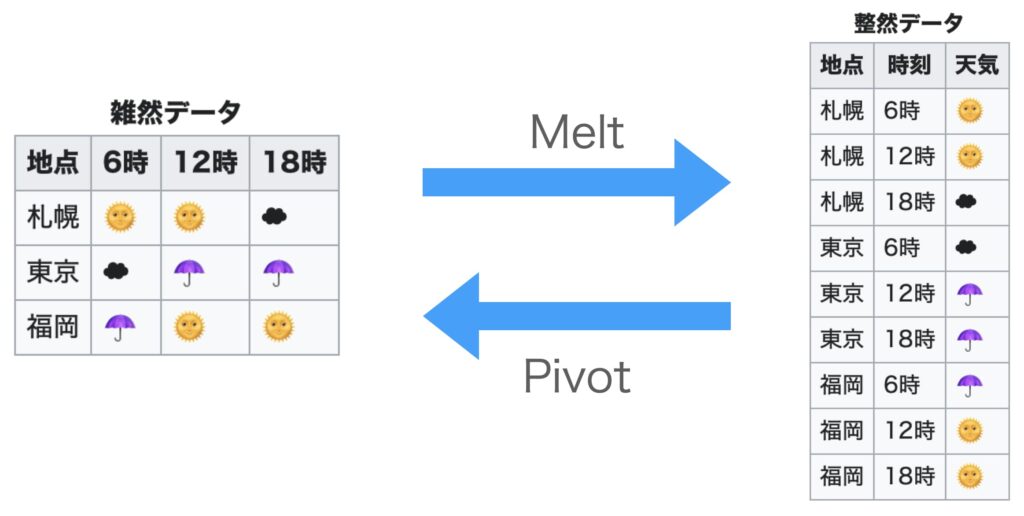
参考:https://ja.wikipedia.org/wiki/Tidy_data
整然データを雑然データに変換するのがPivotです。
Excelとかでもよく使いますよね。
Pandasにもpivot関数があり、Excelのpivotと同じことができます。
一方で、melt関数はこの逆で、雑然データを整然データに変換することができます。
残したいカラムや整然データに変換したいカラムを選択することで、任意の整然データを一瞬で作成することができます。
melt関数の仕様を確認する
次にmelt関数の仕様を確認してみましょう。
公式Documentを見ると詳しい説明があります。
こちらは英語になっているのでざっくりまとめます。
melt関数
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
melt関数ではいくつかの引数が指定できます。
それぞれの意味をこちらにまとめます。
melt関数を実行すると、variableとvalueというカラムが生成されます。
先ほどのWikipediaの例で言うと、variableが時刻で、valueが天気になります。
引数
- id_vars: 整然データに変換したくない、残したいカラムを指定できます(複数指定の場合はリスト)
- value_vars: 整然データにしたいカラムを指定できます(複数指定の場合はリスト)
- var_name: variableのカラム名を指定できます。指定しなければカラム名はvariableになります。
- value_name: valueのカラム名を指定できます。指定しなければカラム名はvalueになります。
- col_level: カラムがマルチインデックスの際に、melt(整然データに変換)する階層を指定できます
- ignore_index: Trueなら元のIndexが無視されます。Falseなら元のIndexが残されます。
ざっくりとこんな感じです。
これだけだとなかなかピンとこないと思うので、実際のデータを使ってmelt関数の動きを見ていきましょう。
株価データを使ってmelt関数を使ってみる
実際のデータを使ってmelt関数を実行してみます。
ここでは株価データを使ってmelt関数の動きを確認していきます。
データの準備
まずはデータの準備です。
株価データを収集するにはpandas_datareaderを使います。
複数銘柄も指定できるので便利です。
import plotly.express as px
from pandas_datareader import data
import pandas as pd
# 期間設定
start = "2022-07-01"
end = "2022-07-10"
# 銘柄設定 日本株の場合は{証券コード.T}になります
tickers = ["^N225", "7203.T", "6758.T"]
df = data.DataReader(
tickers,
"yahoo",
start=start,
end=end
)
# Adj Closeだけを抽出
df = df["Adj Close"]
df.head()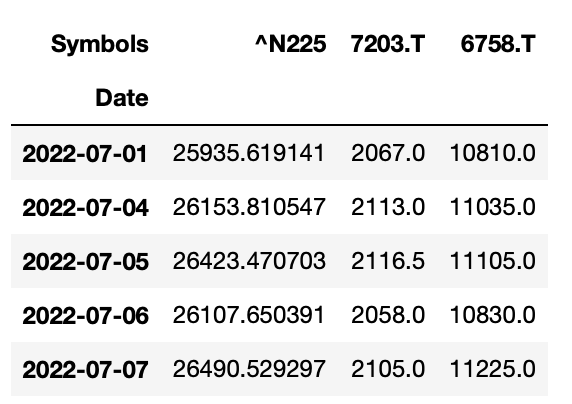
これでデータの準備は完了です。
大きなデータは必要ないので、適当に日付は2022年7月の10日分にしました。
ちなみに使用した銘柄は^N225が日経平均株価、7203.Tがトヨタ自動車、6758.Tがソニーです。
銘柄は適当に選んでます。
-
【日本株対応】Pythonで株価のローソク足データを取得する方法まとめ【CSV、ライブラリ、スクレイピング】
続きを見る
引数なしでそのままmelt関数を適用してみる
早速melt関数を実装してみます。
まずは引数なしでそのままいきます。
df.melt()
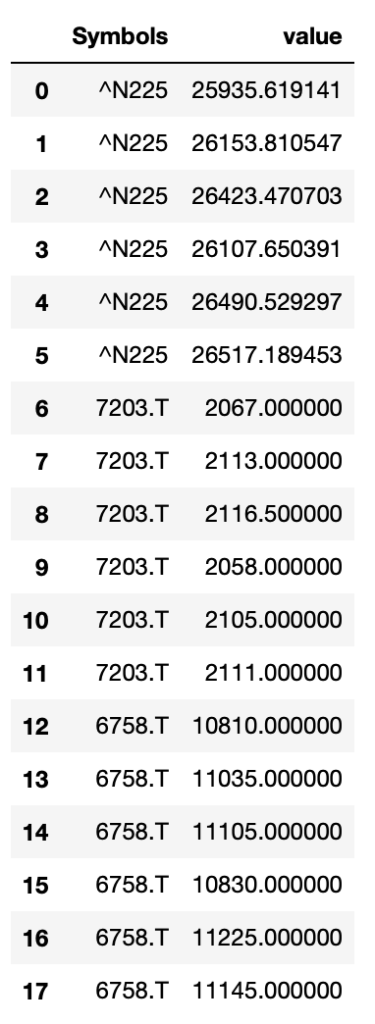
元のデータでカラムの名前(df.index.name)がSymbolsになっているので、variableのカラム名もSymbolsとなっています。
Symbolsカラムには、もともとカラムにあった値(銘柄)が順番に入っていることがわかります。
valueカラムにはそれぞれの銘柄に対応した株価が格納されています。
もともとIndexには日付データがありましたが、melt関数適用後には消えています。
これがmelt関数の基本動作です。
ignore_indexで日付データを残す
日付データがなくなってしまうと困るので、ここは残すように引数を指定しましょう。
ignore_indexを指定するとindexを残すことができます。
df.melt(ignore_index=False)

これで日付データを残すことができました。
indexを残したいときはignore_index=FalseにすればOKです。
id_varsで整然データに変換しないカラムを指定する
次にid_varsを使ってみます。
これで、整然データに変換せずに残しておきたいカラムを指定することができます。
試しに日経平均を選んでみます。
df.melt(ignore_index=False, id_vars="^N225")
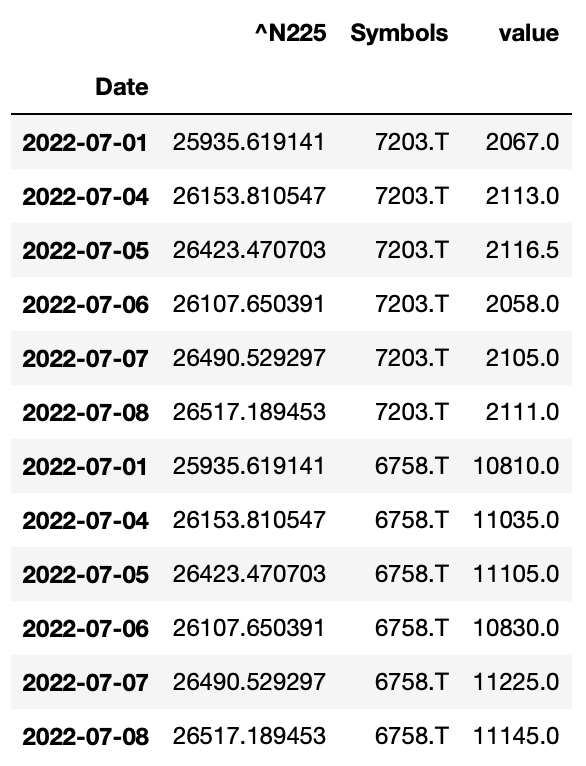
ご覧の通り、^N225というカラムは残っています。
残りの7203.Tと6758.Tが整然データに変換されました。
^N225は7203.Tと6758.Tで同じデータが繰り返し登場していることが確認できます。
value_varsで整然データに変換したいカラムを指定する
次にvalue_varsを使ってみます。
これで整然データに変換したいカラムを選ぶことができます。
試しに7203.Tを選んでみます。
df.melt(ignore_index=False, value_vars="7203.T")
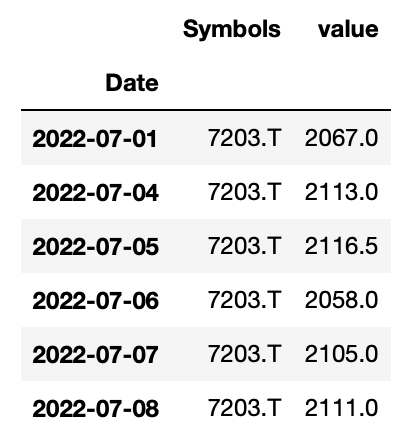
ご覧の通り、7203.Tだけが残り、他のデータは消えます。
残したいデータはid_varsで指定すればOKです。
試しに^N225だけ残してみます。
df.melt(ignore_index=False, id_vars="^N225", value_vars="7203.T")
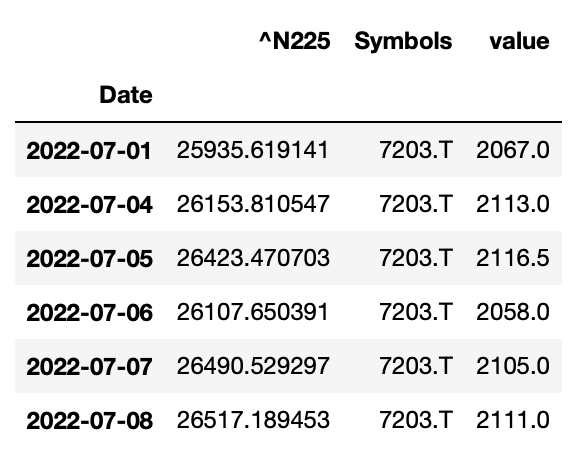
^N225のカラムは残りました。
指定されてない6758.Tだけ消えていることが確認できます。
value_nameとvar_nameでカラム名を指定する
次にvalue_nameとvar_nameを指定してカラム名をつけてみます。
今はSymbolsとvalueになっていますが、ここを任意の名前に変更することができます。
df.melt(ignore_index=False, var_name="銘柄", value_name="株価")
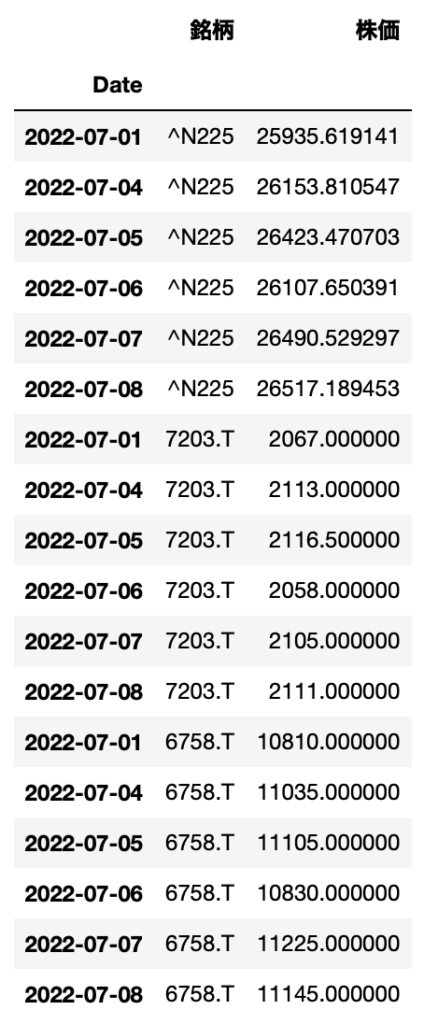
これでわかりやすくなりました。
【ちょっと応用編】col_levelでマルチカラムのデータを整然データに変換する
最後に少し応用編としてcol_levelを使って例をご紹介します。
col_levelは、マルチカラムになっているデータフレームを整然データに変換するときに階層を指定することができます。
データの用意
まずはマルチカラムのデータを用意します。
先ほどはAdj Closeを取り出しましたが、この抽出を行わなければマルチカラムのデータになっています。
import plotly.express as px
from pandas_datareader import data
import pandas as pd
# 期間設定
start = "2022-07-01"
end = "2022-07-10"
# 銘柄設定 日本株の場合は{証券コード.T}になります
tickers = ["^N225", "7203.T", "6758.T"]
df = data.DataReader(
tickers,
"yahoo",
start=start,
end=end
)
# Adj Closeだけを抽出
# df = df["Adj Close"] ここを削除
df.head()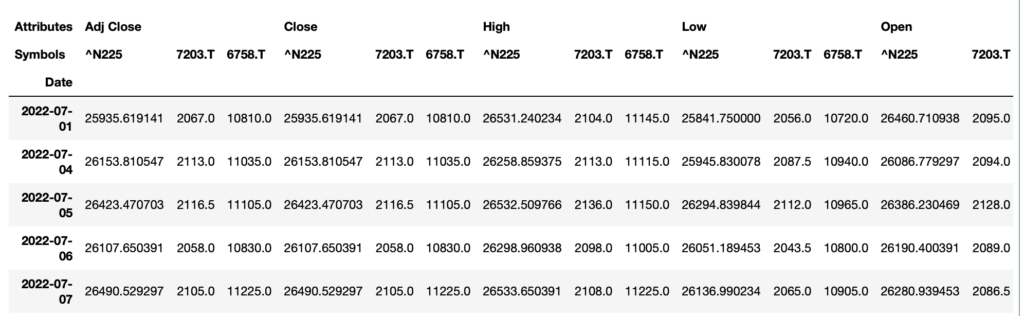
カラムはAttributesとSymbolsという2階層になっています。
これにmelt関数を適用してみましょう。
何も指定しないと階層ごとにカラムになる
まずは何も指定せずにやってみます。
df.melt()
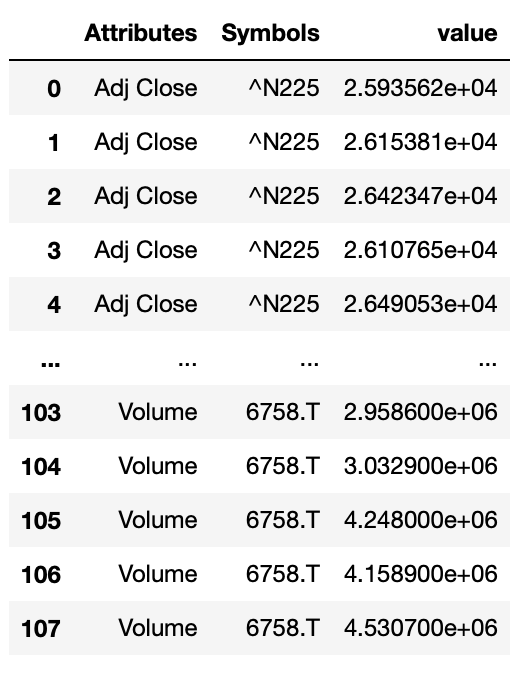
この場合はカラムの各階層がvariableとして扱われます。
今回は2階層になってるので整形後のカラムもAttributesとSymbolsの2つになります。
col_levelで階層を指定する
それではcol_levelで階層を指定してみます。
df.melt(col_level=0)

df.melt(col_level=1)
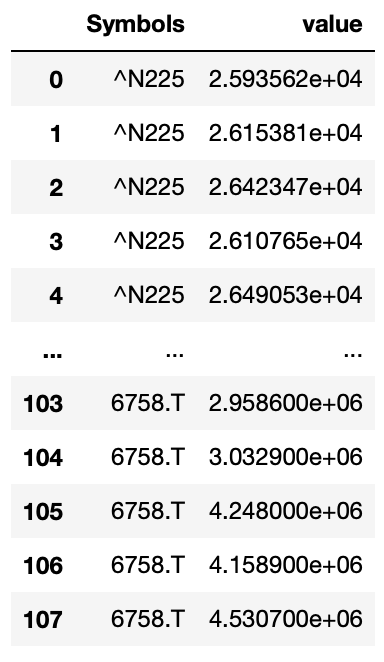
0を指定すると1階層目にあるAttributesだけが使われます。
1にすれば2回層目にあるSymbolsになります。
このように、マルチカラムで一部のカラムだけを使いたい場合にはcol_levelを指定すれOKです。
【おまけ】meltはいつ使うのか
最後におまけです。
melt関数はどういう場面で使うのか、ということです。
最初はイメージがつかないかもしれません。
僕の経験上、いろいろな場面で出番が出てきますが、最も利用するのはデータを可視化するためにデータ整形している時です。
特にPlotlyやSeabornで可視化する際には、Plotlyならcolor、Seabornならhueを指定してグラフを色分けする場面がよくあります。
この場合、整然データが必要になってきます。
本記事で紹介した株価データは、最初の銘柄ごとにカラムが分かれている状態で、PlotlyやSeabornで可視化するには不便です。
melt関数で整然データに変換してあげると、colorやhueに銘柄を指定してあげれば簡単に可視化することができます。
import plotly.express as px df_melt = df.melt(ignore_index=False, var_name="銘柄", value_name="株価") px.line(data_frame=df_melt.reset_index(), y="株価", x="Date", color="銘柄")
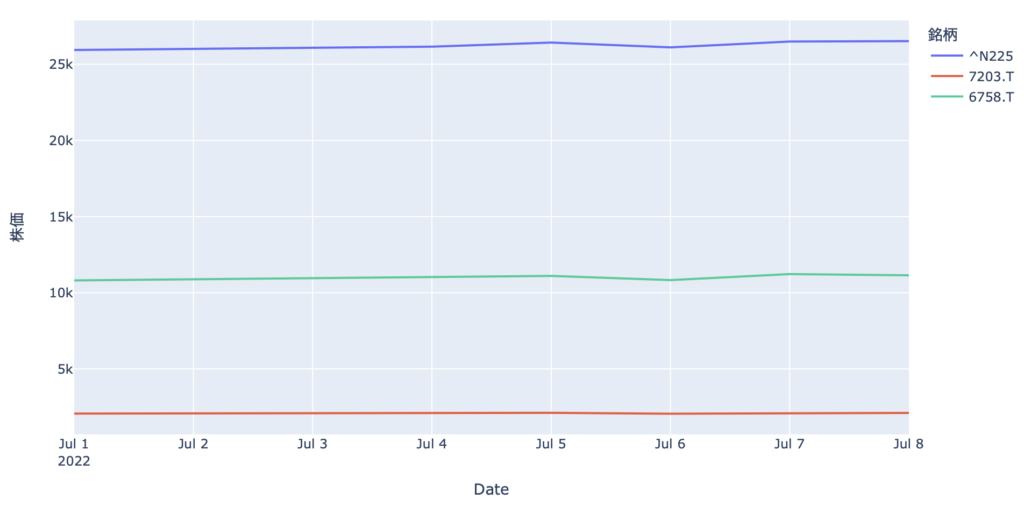
この結果だと株価が全然違うので単純に横並びで比較することはできませんが、整然データに変換することでcolorで銘柄を指定すれば簡単に可視化することができるようになります。
ちなみに横並びで比較するには相対値に変換する必要があります。
その際には雑然データで行った方が便利です。
その後にmelt関数で整然データに変換してあげるとスムーズに可視化できます。
状況に合わせてうまくデータを変換していくと、短いコードでデータの準備ができます。
import plotly.express as px # 相対値に変換 df = df / df.iloc[0] * 100 # 整然データに変換 df_melt = df.melt(ignore_index=False, var_name="銘柄", value_name="株価") # 可視化 px.line(data_frame=df_melt.reset_index(), y="株価", x="Date", color="銘柄")
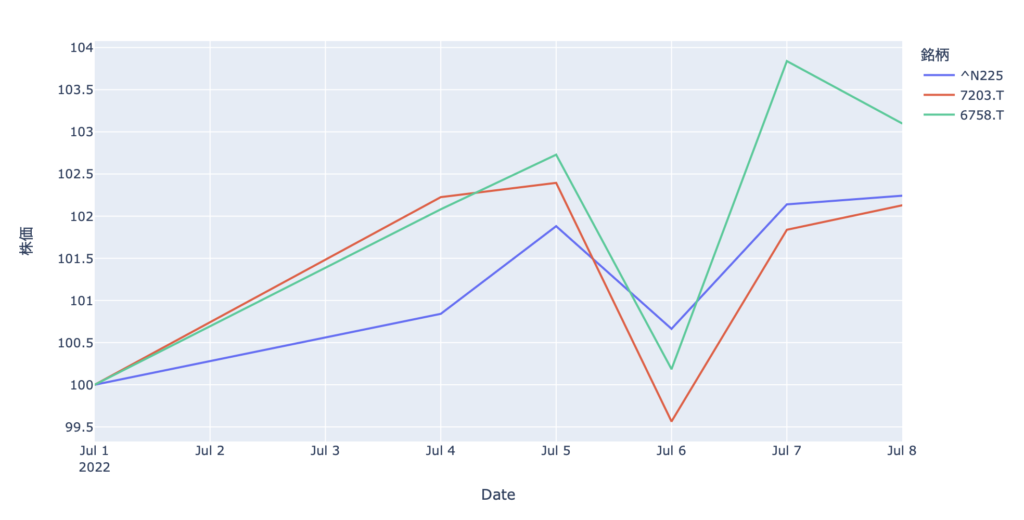
こちらのコードの場合は、最初の値を100とした相対値に変換して可視化しています。
これなら株価が違っても横並びで比較できますね。
相対値への変換、整然データへの変換、可視化、それぞれの作業が1行のコードで完了します。
このように、データの処理はデータの形によってとっても簡単になったりします。
melt関数を駆使して、必要に応じて雑然データと整然データを行き来することができれば、データ処理の効率性も上がります。
まとめ
本記事では、「整然データが一瞬で作れるPandasのmelt関数の使い方を徹底解説!【Pythonコード解説】」というテーマで 、Pandasのmelt関数について解説してきました。
一見わかりにくい関数ですが、使いこなすことができればとっても便利な関数です。
特に可視化の際には整然データの方が都合が良い場合がよくあります。
PlotlyとかSeabornで可視化する際には整然データを用意する必要が出てくる場面がたくさんあります。
melt関数を使えば、数行のコードで整然データを準備することができます。
使いこなせるととっても便利な機能なので、是非とも活用してみてください。
本記事がmelt関数の理解の助けになれば幸いです。
ここまで読んでくださり、ありがとうございました。




{kind=link}