
こんにちは。TATです。
今回のテーマは「Pythonで株価のローソク足データを取得する方法まとめ」です。

Pythonで株の分析がしたいです。
株価データを取得する方法を教えてください。
日本株のデータが取得できると嬉しいです。
上記に答えていきます。
Pythonで株価データを取得できると、いろいろな分析に活用することができます。
その気になれば自動売買システムを構築するみたいなことも可能です。
本記事では、Pythonで株価データを取得する方法として4つご紹介します。
Pythonで株価データを取得する方法
- 方法①:ダウンロードしたCSVファイルを扱う
- 方法②:ライブラリを利用する【おすすめ】
- 方法③:スクレイピングする 【取扱注意】
- 方法④:APIを利用する
それぞれの方法のメリットやデメリットについてもまとめていきます。
必要なPythonコードは全て公開するので、ご自由にお使いいただければと思います。
目次
方法①:ダウンロードしたCSVファイルを扱う

1つ目の方法は、ダウンロードしたCSVファイルを扱うです。
世の中には無料で株価データをCSV形式でダウンロードできるサイトがあります。
ここではInvesting.comというサイトをご紹介します。
メリットとデメリット
方法①の特徴をまとめます。
メリット
- コード量が比較的少なくて済む
- CSV形式なので、PythonでなくてExcelなどでも分析できる。
- 日足、週足、月足が選択できる
デメリット
- 会員登録が必要
- 1銘柄ずつしかダウンロードできない。
- PythonでCSVファイル読み込み後にデータ整形が必要(後述)
方法①はシンプルでは手軽に利用できますが、データ読み込み後のデータ整形作業が必要になります。
また、複数の銘柄の株価データを集める際には手間がかかります。
1つの銘柄で、なおかつ1度限りの分析であれば有効と思いますが、繰り返し分析したり、複数銘柄を扱いたい場合には不便です。
データ取得の手順を解説
ここからは、Investing.comから株価データをCSV形式でダウンロードして、Pythonで読み込み、データ整形するまでの手順を解説します。
*無料登録が必要です。
株価データを取得するには無料の会員登録が必要になります。
必要なのはこれだけです。
お金もかからないので余裕ですね。
銘柄を検索してCSVファイルをダウンロード
会員登録を済ませてログインすると株価データをCSV形式でダウンロードできるようになります。
データは日足、週足、月足から選択することができます。
Investing.comでログイン後、一番上にある検索ボックスから任意の銘柄を探してダウンロードページにいきます。
こんな感じです。こちらはトヨタ(7203)です。
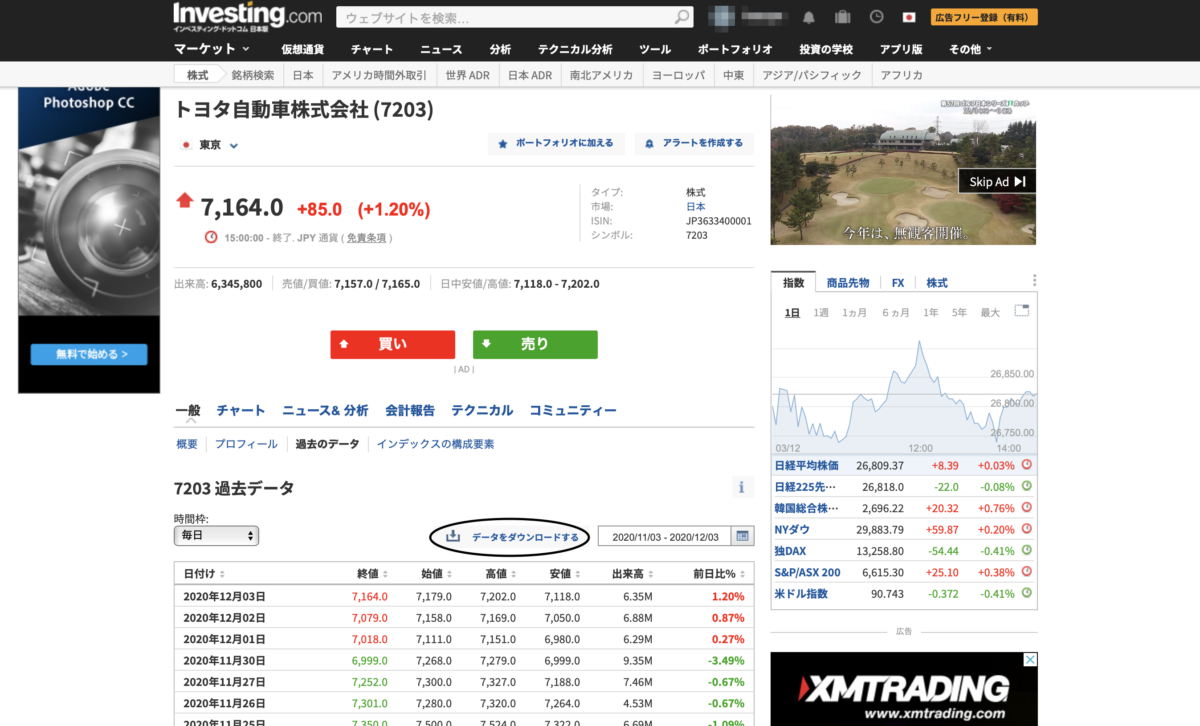
https://jp.investing.com/equities/toyota-motor-corporation-historical-data
時間枠(毎日・毎週・毎月のいずれか)と任意の期間を設定して「データをダウンロードする」を押すと、CSV形式で株価データをダウンロードすることができます。
PythonでCSVファイルを読み込む
次にダウンロードしたCSVファイルをPythonで読み込んでみます。
コードはとてもシンプルです。
import pandas as pd
df = pd.read_csv("7203 過去データ.csv")
pandasはデータ分析用のライブラリです。
通常はpdと略して定義して使います。
pandasのread_csvを使うとCSVファイルを読み込むことができます。
head()で冒頭の5行を確認します。
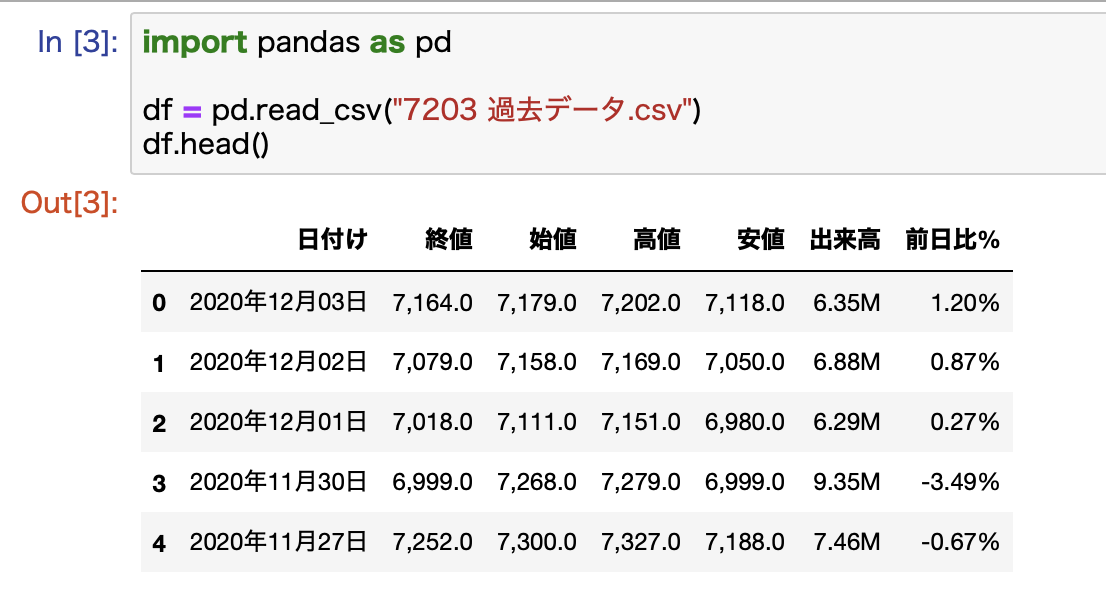
無事に読み込むことができました。
分析のためにデータ整形をする
ここで読み込んだデータを確認すると、いくつか問題点があります。
問題点
- 全てのカラムが文字列
- 日付けはDate型に変換する必要がある
- その他のカラムはfloat型に変換する必要がある
- 日付が新しいものから並んでいる
- 時系列データを扱い際にはデータが古いものから並んでいる方が良い
順番に対応していきます。
株価はint型に変換しても良いのかと思う方もいるかもしれませんが、指数を扱う際にはfloat型になるので、ここは統一しておいた方が後々使いまわしていく時に楽になります。
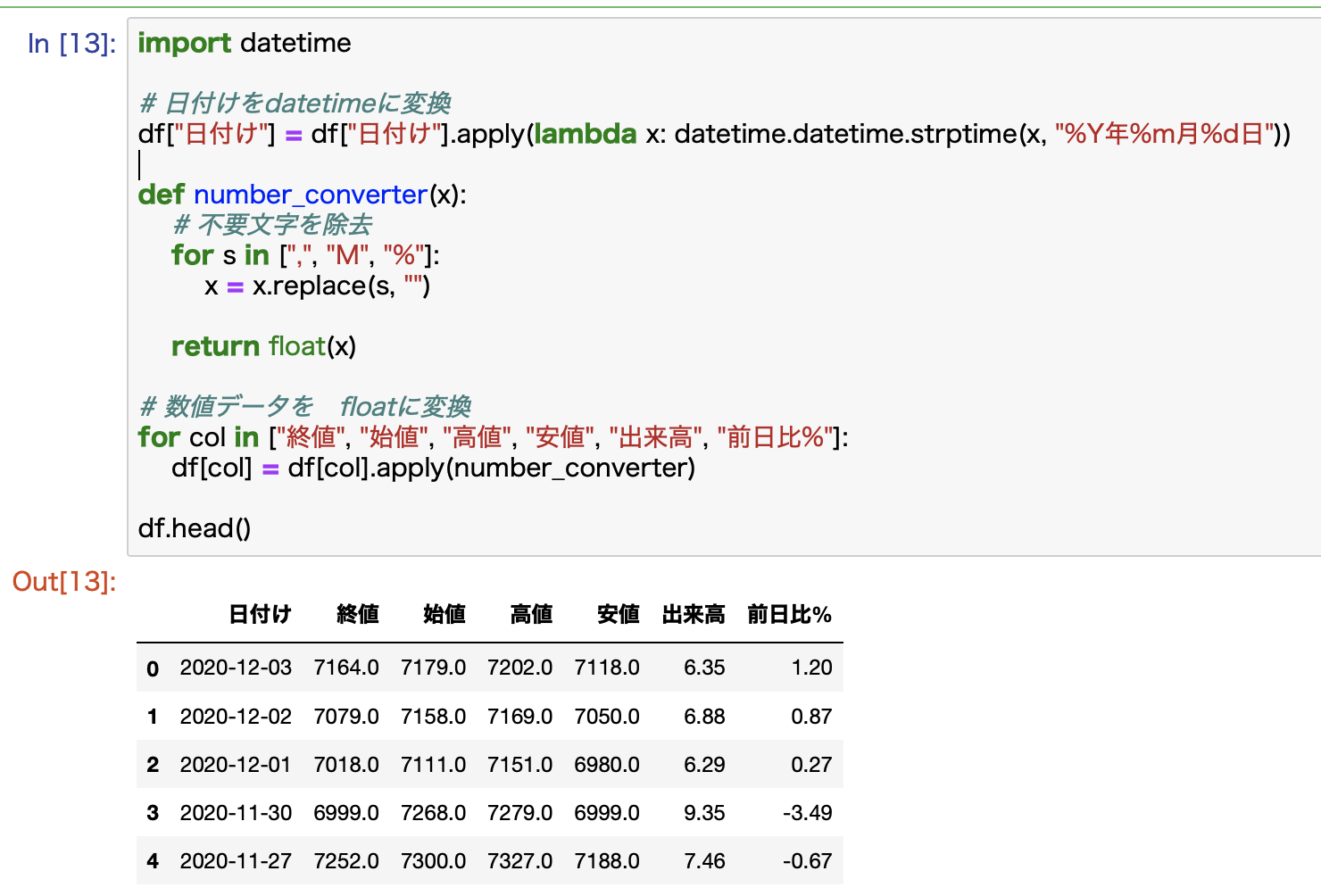
import datetime
# 日付けをdatetimeに変換
df["日付け"] = df["日付け"].apply(lambda x: datetime.datetime.strptime(x, "%Y年%m月%d日"))
def number_converter(x):
# 不要文字を除去
for s in [",", "M", "%"]:
x = x.replace(s, "")
return float(x)
# 数値データを floatに変換
for col in ["終値", "始値", "高値", "安値", "出来高", "前日比%"]:
df[col] = df[col].apply(number_converter)
これで完了です。
サクッと解説しておくと、まず、datetimeというライブラリーを利用して日付けデータをdatetimeに変換します。
lambda関数を使うことでコードがスッキリします。
次にその他のカラムをfloatに変換します。
ここには、共通で利用できるnumber_converterという関数を定義して、ここで不要な文字(,とか%とか)を除去してfloatに変換します。
これをapply関数を使って「日付け」以外の各カラムに適用すれば変換完了です。
データがきれいに変換されていることが確認できます。
最後にこのデータを日付けでソートします。
これは、時系列データを扱う際に便利なためで、古いものから順に表示されるようにします。
これをやっておくと、後に行うデータ分析が楽になります。
コードとしては1行で完了します。
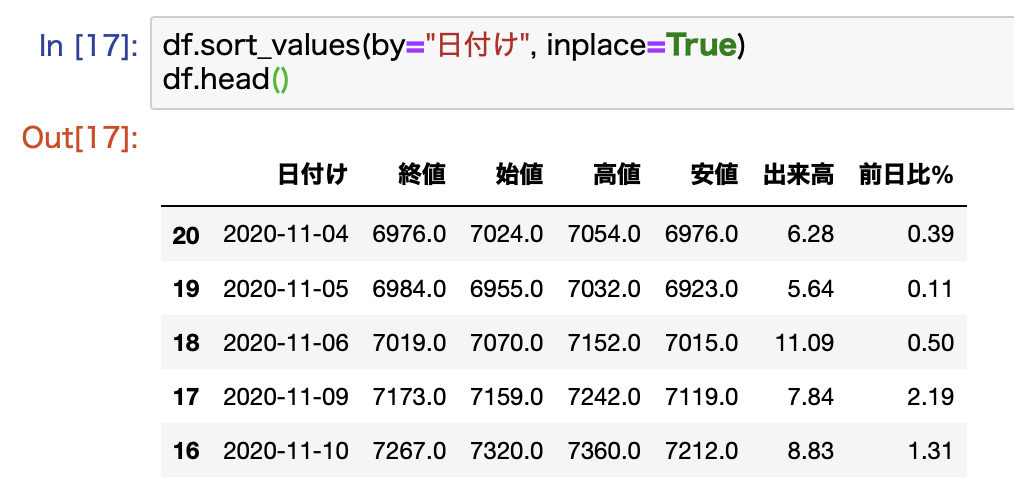
日付けでソートして、データを置き換えます。
df.sort_values(by="日付け", inplace=True)
これでデータのソートが完了です。
以上でデータ整形はすべて終了です。
これでデータ分析の準備万端です。
方法②:ライブラリを利用する【おすすめ】

2つ目の方法はライブラリを利用するです。
これが一番おすすめです。
Pythonには、株価を扱えるライブラリーが存在しており、それらを利用することで株価データを簡単に取得することができます。
Pythonまじで神ですね。データ整形が必要ないので楽ちんです。
ここでは2つのライブラリをご紹介します。
ポイント
- pandas_datareader
- yahoo_finance_api2
pandas_datareader
まずはpandas_datareaderについてご紹介します。
これは、経済データや金融商品(株とか指数とか)の価格データを取得することができるライブラリです。
こんなに素晴らしいライブラリーがPythonにはあるんですね。
メリットとデメリット
pandas_datareaderの特徴とまとめます。
メリット
- コードがシンプルでわかりやすい
- 日本株にも対応している
- 調整後終値が取得できる
デメリット
- 日足しか取れない
- 短期間で乱発すると制限がかけられる可能性がある
コードがシンプルでわかりやすいのが1番のメリットです。
日本株にも対応しています。
日足データしか取得できないのがデメリットです。
コード例:ダウ平均を取得してみる
実際のコード例をご紹介します。
pandas_datareaderの中にあるdataを使います。
例としてダウ平均を取得しています。
from pandas_datareader import data
df = data.DataReader("^DJI","yahoo")
このまま実行すると、過去10年分のデータが取れます。
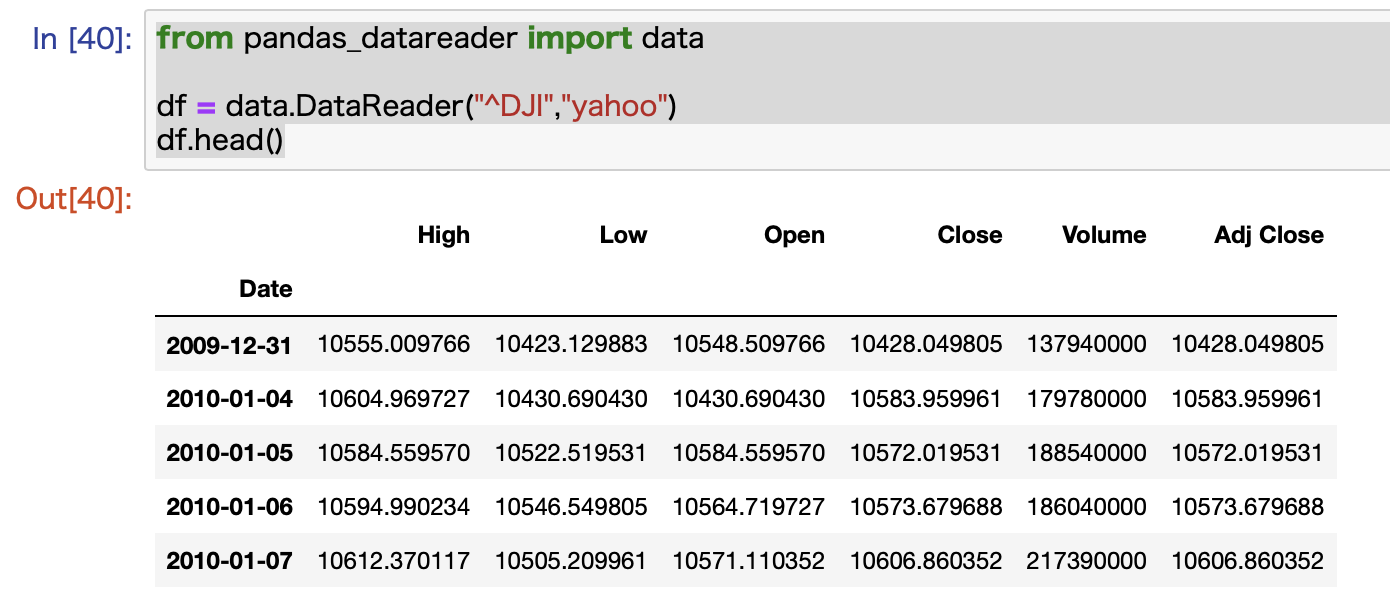
このデータの場合は、すでに古いものから順番に並んでいますので、整形の必要はありません。
このまま使えます。
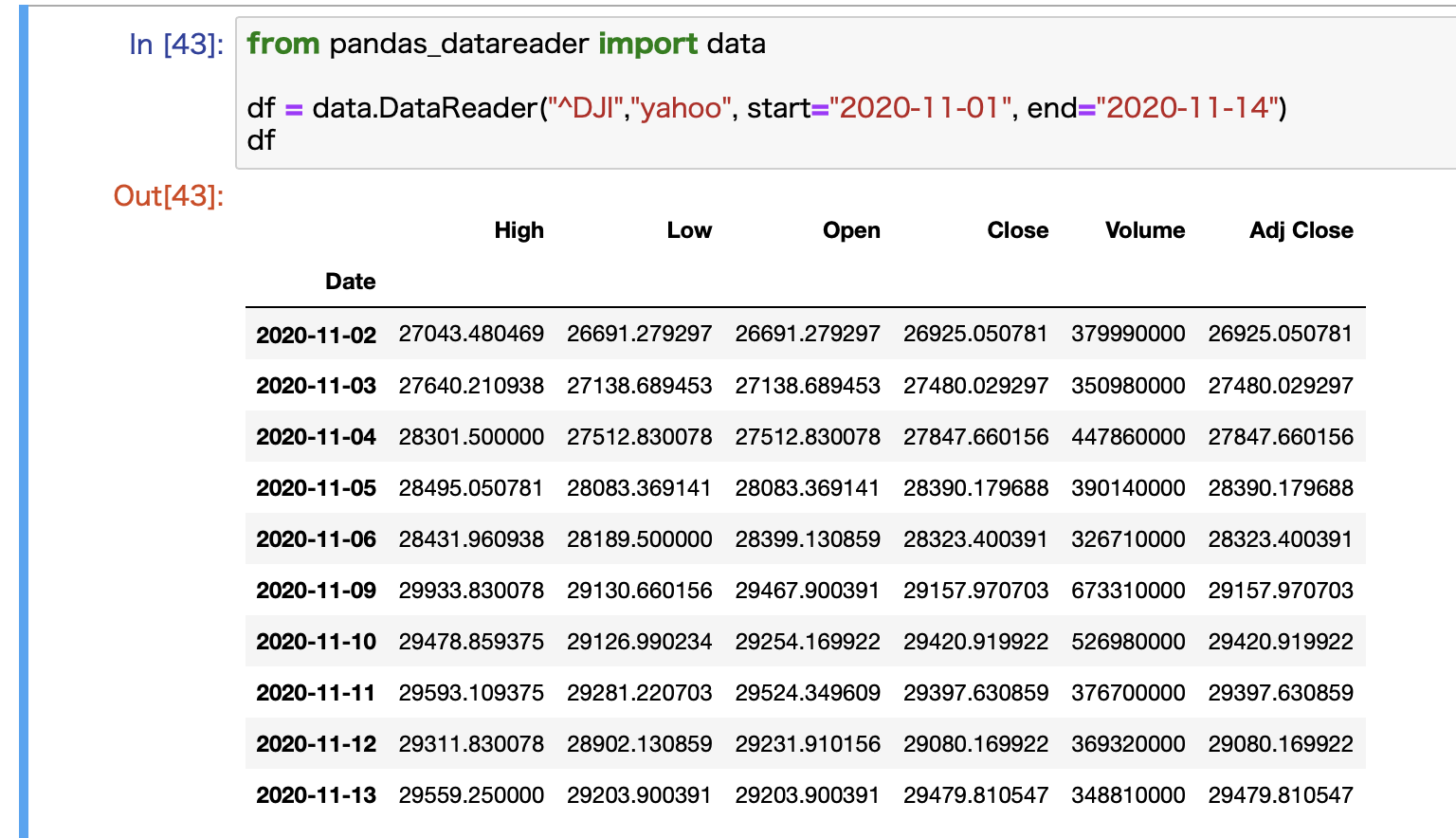
コード例:日付の指定も可能
日付の指定もできます。
from pandas_datareader import data
df = data.DataReader("^DJI","yahoo", start="2020-11-01", end="2020-11-14")
これで2020年11月1日から14日までの2週間分のデータを取得することができます。
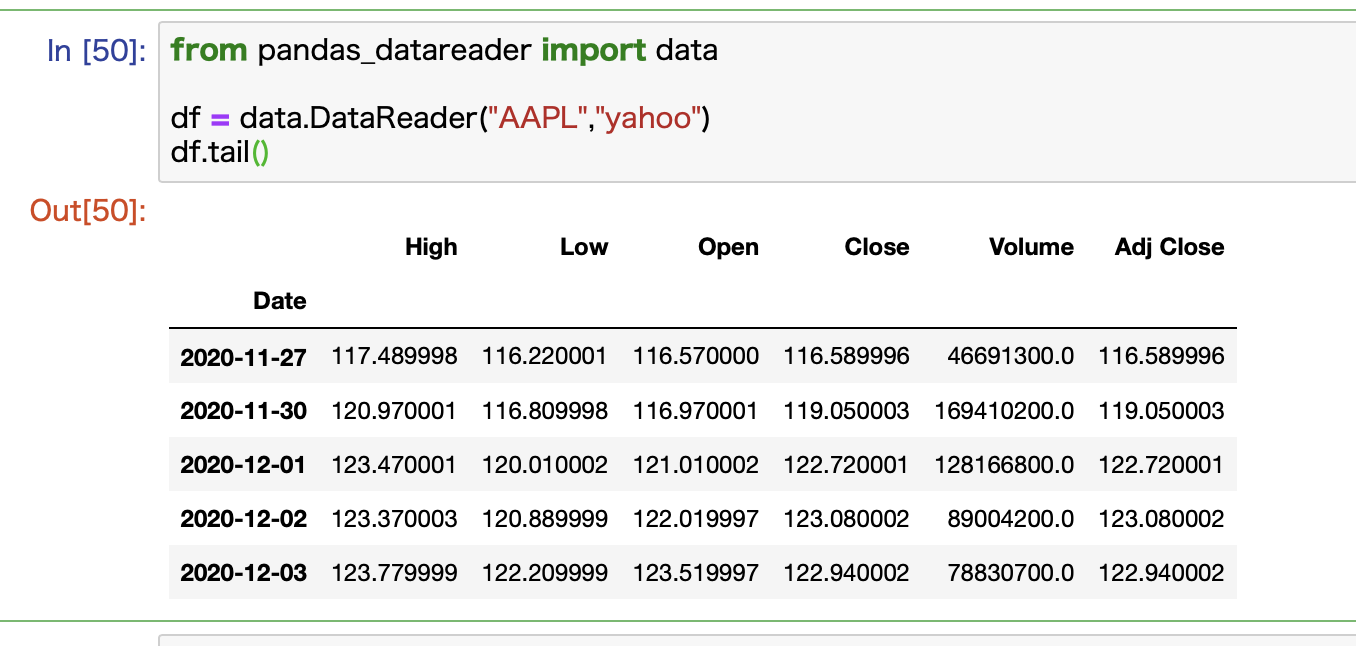
コード例:個別株(例:アップル)を取得する
個別株の株価データも取得できます。
例としてアップルの株価を取得してみます。
アップルのティッカーシンボルはAAPLなので、これを指定すればOKです。
from pandas_datareader import data
df = data.DataReader("AAPL","yahoo")
こんな感じで取得できています。
最新データを表示するために、headではなくてtailを使っています。
これはラスト5行を表示します。
日付の指定は先ほどと同様です。
コード例:日本株の株価データを取得する
pandas_datareaderを使うと日本株のデータをyahooから取得することも可能です。
日本株を指定する際には、{証券コード}.Tの形で指定します。
トヨタなら7203.Tといった具合です。
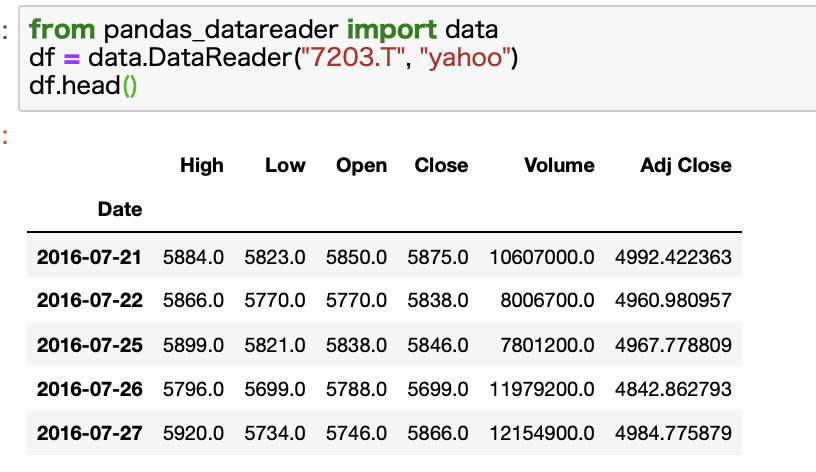
期間の指定も可能です。startとendをいう引数を利用すればOKです。
指定せずとも、証券コード、情報ソース元、開始日、終了日の順番に指定すればOKです。
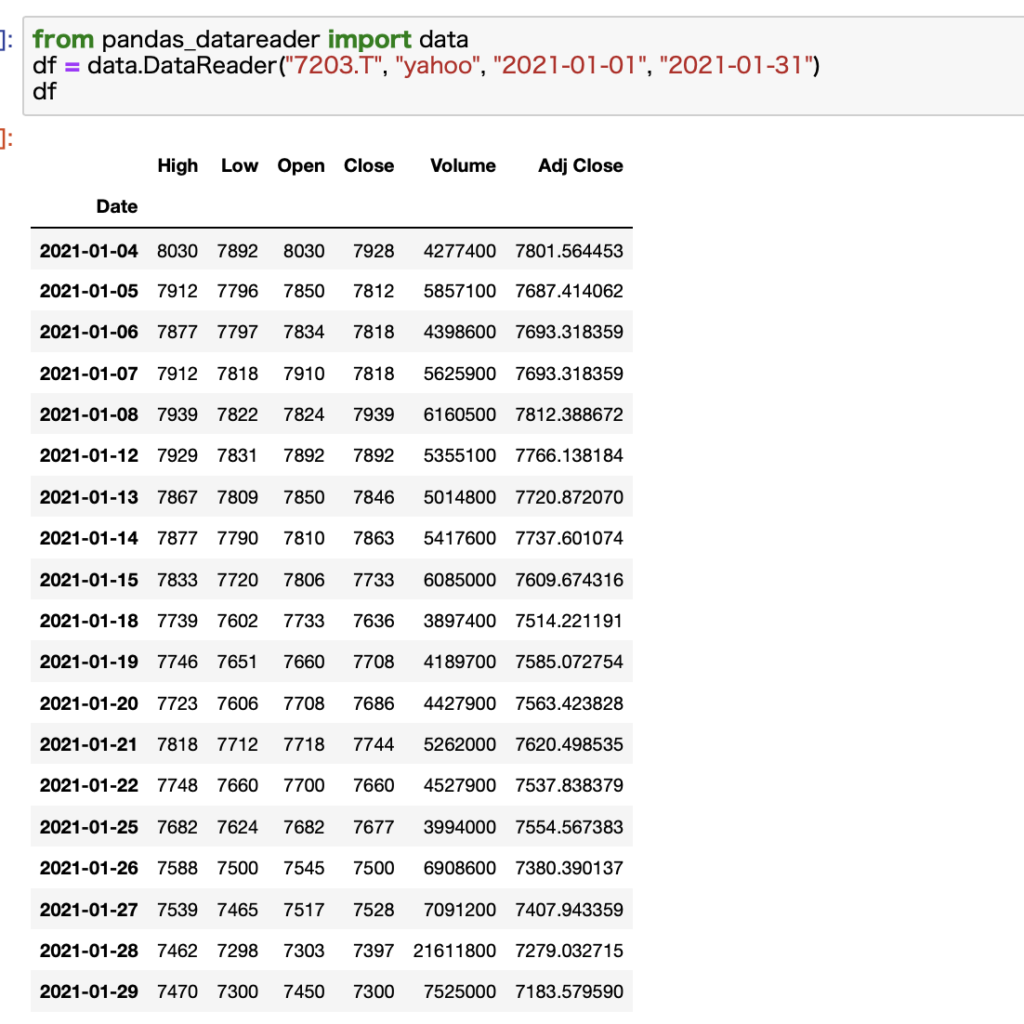
使い勝手抜群ですね。
コード例:複数の証券コードを指定することが可能!
さらに複数の証券コードを指定することも可能です。
これは日本株に限らず、あらゆる銘柄に適用できます。
この場合はリスト形式で指定します。
例として、トヨタと日産のデータをまとめて取得してみます。
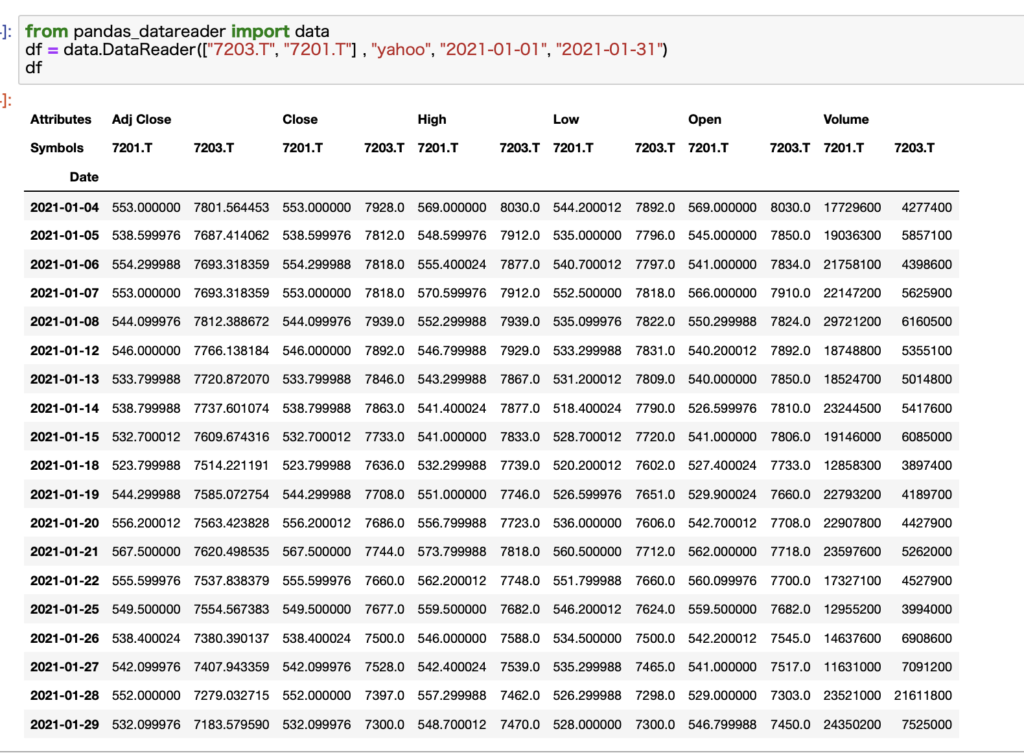
こんな感じでそれぞれのデータがきちんと取得できていることがわかります。
【朗報】Pythonで日足データを週足・月足に変換することができる!
ざっと見たとこ、pandas_datareaderでは日足データしか取得できないことがデメリットと思います。(指定方法わかる方いたら教えてください)
ただ、日足データさえ取得してしまえば、Pythonで週足や月足に変換することが可能です。
こちらの記事で解説しているのでご興味あればご参照ください。
結論、日足データさえ手に入れば、週足データとか月足データは後から加工して作ればOKです。
-

【コード解説】Pythonで株価データを日足から週足・月足に変換する!
続きを見る
yahoo_finance_api2
次にはyahoo_finance_api2についてご紹介します。
名前の通り、yahoo_financeからデータを取得できるライブラリになります。
先ほどのpandas_datareaderはさまざまなサイトからデータを取得できますが、yahoo_finance_api2はYahoo!ファイナンスに特化しています。
メリットとデメリット
yahoo_finance_api2の特徴をまとめます。
メリット
- 分足・時間足・日足・週足・月足と幅広いデータに対応している
- 日本株にも対応している
- リアルタイムに近いデータが取得できる
デメリット
- pandas_datareaderに比べるとコードが少し複雑
- 調整後終値がない
- 短期間で乱発すると制限がかけられる可能性がある
yahoo_finance_api2の1番の特徴は、取得できるデータの柔軟性です。
日足だけではなく、週足や月足、さらに分足や時間足も取得することが可能です。
さらに、2時間おきとか5日おきみたいなトリッキーなデータの取得もできます。
一方で、設定が柔軟なゆえ、コードは少し長くなります。
それでも一度プログラムを書いてしまえば使いまわすことができるので、ぜひ本記事のコードを活用してください。
コード例:トヨタ自動車(証券コード:7203)の株価を取得してみる
例として、トヨタ自動車の株価を取得してみます。
この際、pandas_datareaderと同様、日本株を指定する際には、証券コード.Tという形式になります。
次の例では、5分足のデータを過去10日分取得しています。
import sys
from yahoo_finance_api2 import share
from yahoo_finance_api2.exceptions import YahooFinanceError
my_share = share.Share('7203.T')
symbol_data = None
try:
symbol_data = my_share.get_historical(
share.PERIOD_TYPE_DAY, 10,
share.FREQUENCY_TYPE_MINUTE, 5)
except YahooFinanceError as e:
print(e.message)
sys.exit(1)
df = pd.DataFrame(symbol_data)
df["datetime"] = pd.to_datetime(df.timestamp, unit="ms")
df.head()
share.PERIOD_TYPE_DAYで期間を指定しています。PERIOD_TYPE_DAYで10となっているので10日間を意味します。
share.FREQUENCY_TYPE_MINUTEは頻度を指定しています。FREQUENCY_TYPE_MINUTEで5となっているので、5分足の意味になります。
取得したデータはjson形式になっているので、DataFrameに変換しています。
また時間がタイムスタンプになっているため、Datetime型に変換する作業も必要です。
これで、取得したデータが分析に使える状態になります。
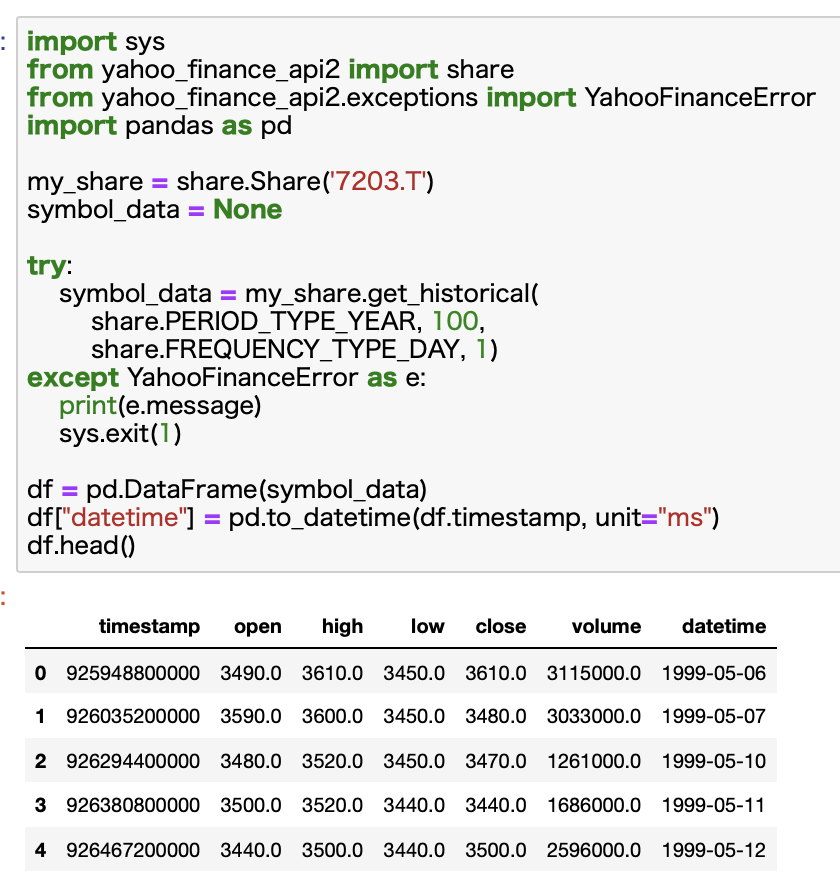
コードが長くなって複雑に見えるかもしれませんが、こちらのコードを使いまわしていただければすぐに利用できるので、是非ともコピーしていってください。
1分足とかで取得すればリアルタイムに近いデータが取得できる
yahoo_finance_api2では、分足でデータを取得することができるため、1分足とかで株価データを取得すればリアルタイムに近いデータを取得すること可能です。
ただし、完全なリアルタイムデータではありません。
Yahoo!ファイナンスでは株価データは20分の遅れがあります。
したがって、yahoo_finance_api2でデータを取得した際にも、これと同じかそれ以上の遅れがあることが確かです。
しかし、Pythonで無料で最もリアルタイムに近いデータを取得できるのがyahoo_finance_api2なのかなと思います。
別記事で詳しく解説しています。
yahoo_finance_api2はpandas_datareaderに比べると、コードが複雑ですが、カスタマイスできる要素も多いです。
使い始めは困惑すると思います。
こちらの記事では、yahoo_finance_api2について詳しく解説しています。
変数のカスタマイズの方法も全て網羅しています。ご興味あれば是非ともご参照ください!
-
【Pythonコード解説】yahoo_finance_api2で日本株の株価データを取得する
続きを見る
方法③:スクレイピングする【取扱注意】

3つ目の方法が、スクレイピングするです。
ちなみにこれが一番だるい方法ですw
スクレイピングはリスクもあるのであまりおすすめしませんが、一応ご紹介しておきます。
基本は方法②で良いかと思いますw
【要注意!】スクレイピングを禁止しているサイトに注意!規約をチェックした方がいいです
そして、スクレイピングを禁止しているサイトもあるので、使うには注意が必要です。
Yahoo!ファイナンスは確実にアウト
Yahoo!ファイナンスは1発アウトですw
こちらのページに明確にスクレイピングは禁止と書かれています。
→ Yahoo!ファイナンス掲載情報の自動取得(スクレイピング)は禁止しています
株探は明記はされていないけど、調子乗ったらダメ
また、僕が大好きな株探もスクレイピングはグレーです。
株探の規約では、「スクレイピングは禁止」との明確な表記はありませんが、サーバーへの負担をかけるような行為はアウトと書かれています。
→ 株探利用規約
スクレイピングは調子に乗るとサーバー側に負担をかけてしまうので、非常に怪しいところです。
スクレイピングしないほうが無難ですね。
ミンカブも同様
ミンカブも同様です。
ミンカブと株探は運営会社が同じなので、規約もほぼ一緒です。
株探がグレーならミンカブもグレーです。
やらないほうが無難です。
基本的にはファイナンス系のサイトはスクレイピングしないほうがよいです(涙)。
「株式投資メモ」:スクレイピングできるサイトはここです。
じゃあどのサイトならスクレイピングしていいんだよ!と思われるかもしれません。
安心してください。
「株式投資メモ」というサイトはスクレイピングを禁止していません。
URLの構造
「株式投資メモ」をスクレイピングするには、URLの構造を理解しておく必要があります。
例としてトヨタの株価データを見ると、URLはこんな感じです。
https://kabuoji3.com/stock/7203/
トヨタの証券コードは7203なので、ここを任意の証券コードを切り替えればデータは取れることが想像できますね。
ページの切り替えなども行いたい場合はさらにURL構造の解析が必要になりますが、ここでは割愛します。
最初のページだけスクレイピングする方法を例としてご紹介します。
コードの一例を公開
とりあえず、簡単にコードを書いてみたのでご紹介します。(美しさは求めてないですwww)
ご参考になれば嬉しいです。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
ticker = 7203
# URLを定義
base_url = "https://kabuoji3.com/stock/{}/"
url = base_url.format(ticker)
# headersの設定
headers = {"User-Agent": "ご自身で設定してください"}
# HTML取得
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.content, "html.parser")
# 株価データ抽出
rows = []
for tr in soup.findAll("tr"):
# thあればコラム、なければ株価データ
if tr.find("th"):
columns = [x.getText().strip() for x in tr.findAll("th")]
else:
rows.append([x.getText().strip() for x in tr.findAll("td")])
# DataFrameに変換
df_latest = pd.DataFrame(rows, columns=columns)
# 日付をdatetimeに変換
df_latest["日付"] = df_latest["日付"].apply(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d"))
# 日付以外のデータをfloatに変換
for col in ["始値", "高値", "安値", "終値", "出来高", "終値調整"]:
df_latest[col] = df_latest[col].astype(float)
# "終値調整"を削除
df_latest.drop("終値調整", axis=1)
コメントをたくさんつけたので、順番に追っていくと理解しやすいかと思います。
適当に書いたので、関数もなしにベタ書きですがw
注意点:スクレイピング時にheadersを入れないとエラーになります
ここでrequestsで使用しているheadersについて解説しておきます。
「株式投資メモ」の場合は、これがないとこんな感じでエラーになります。
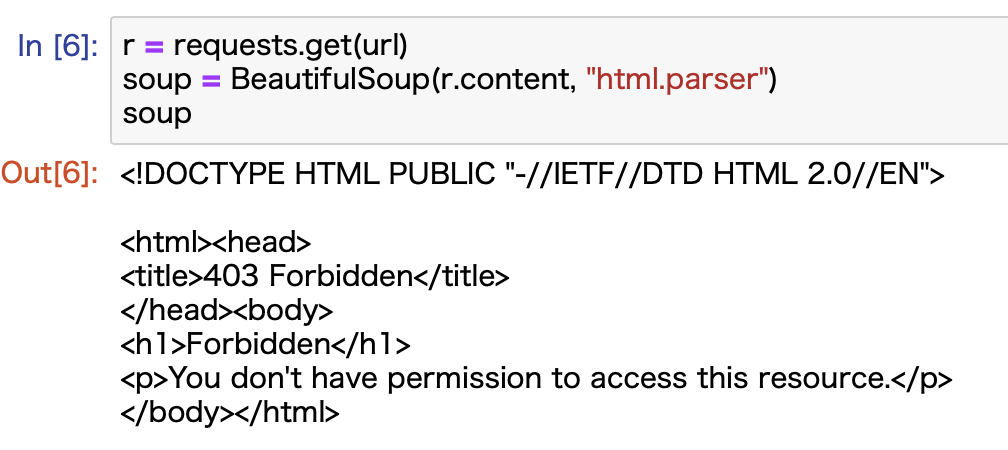
403エラーなのでアクセス拒否ですねw
この場合は、リクエストを送る際にheader情報としてUser-Agent情報を付与してあげると解決できます。
header情報は、サーバーがリクエストを受けた時に利用されており、「どんな奴がリクエストを送ってきたのかな〜」とチェックするために使います。(その他の使い方もあります)
そして条件に合致しない場合にはリクエストを拒否するみたいな処理ができるんですね。
今回はそれにぶちあたったので、ここを突破します。
そのためにはUser-Agent情報を付与します。
これは自分が利用しているブラウザ情報です。
Chromeをお使いなら、右クリックして「検証」をクリックし、Networkタブから確認することができます。
僕の場合だとこんな感じですね。
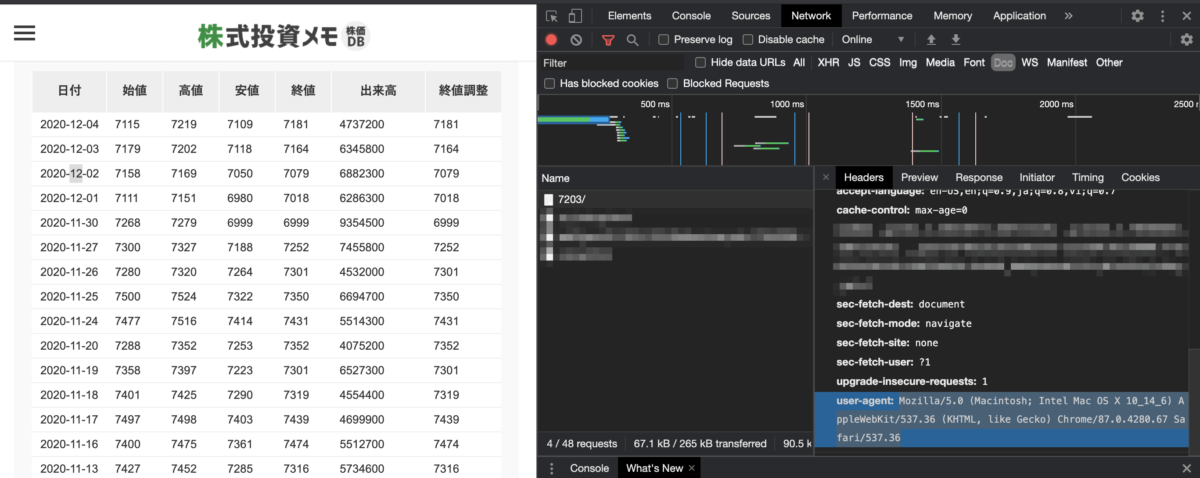
ここの「Mozilla~~~」の部分をガバッとコピーしてコードの「"ご自身で設定してください"」と置き換えてください。
これでブラウザ情報を送ることができ、きちんとデータを取得することができるようになります。
方法④:APIを利用する

4つ目の方法として、APIを利用する、があります。
東証はAPIを提供しているけど有料です
東京証券取引所(以下、東証)はAPIを提供をしています。
株価データにもアクセスでるようですが、無料で利用できるものではなく、有料です。
そして料金が高いです。
サクッと調べた感じ、約定情報とかが取得できる約定値段情報APIサービスでは、基本料金で月額8万円です。
これにさらにAPI利用料とかネットワーク端末料がかかってきます。
そして、TDNETのAPIサービス(適時開示情報(TDnet))は月額 36,740 円(税込) です。
*料金は2022年9月現在の情報
よほどお金に余裕があるか、あるいは企業でないと導入できないレベルです。
個人ユーザ位には現実的な選択肢ではありません。
日本だとauカブコム証券がAPIを提供してます
日本の証券会社では、この記事を書いている2020年12月4日時点ではauカブコム証券株式会社が提供しています。
auカブコム証券株式会社を利用するとAPI経由で株価データを取得できるので、簡単に株価データを取得できるようになります。
感覚的には方法②のライブラリーに近いようなイメージです。
さらにAPIを経由して株の売買注文などもできるので、完全な自動売買ができるようになります。
僕自身、自動売買にはとても興味があるので、いつか挑戦してみたいですね。
楽天証券だとRSSが利用できる
少しずれてしまうかもしれませんが、楽天証券だと、RSSを使った機能が使えたりもします。
Excelにアドインして利用できる機能になるので、Excel上でリアルタイムに株価を表示したりすることができるようになります。
残念ながらPythonでは利用できなさそうですが、例としてご紹介させていただきました。
Excelに慣れている方なら楽天証券のRSSを利用するとかなり便利かと思います。
株価データを取得したら?

Pythonで株価データを取得したら、そこからさまざまな分析に活用することができます。
テクニカル分析をすることもできますし、ローソク足チャートとしてグラフ化することもできます。
オリジナルの売買シグナルを研究して自動売買のシステムを構築することもできます。
テクニカル指標を計算する
株価データをそのまま利用する人はあまりいません。
移動平均線やMACD、一目均衡表など、さまざまなテクニカル分析を組み合わせて分析することがほとんどだと思います。
本ブログでは、さまざまなテクニカル分析をPythonで行う方法について解説しています。
-

【コード解説】Pythonで株価データから主要なテクニカル分析を計算して可視化する【移動平均線、MACD、RSI】
続きを見る
-
【コード解説】Pythonで一目均衡表を計算してチャートで可視化する
続きを見る
-
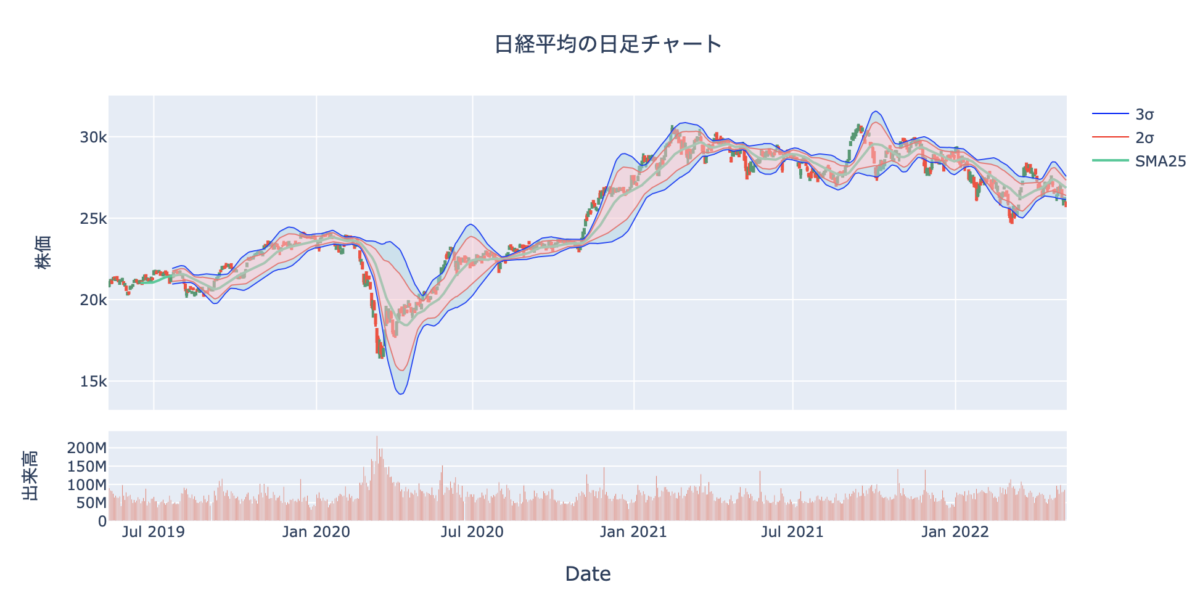
【Pythonで株式投資】株価データからボリンジャーバンドを計算して可視化する【コード解説】
続きを見る
チャートで可視化する
Pythonならデータを可視化することも容易です。
ローソク足チャートを描くことはもちろん、さまざまなテクニカル指標も併せて表示することができます。
「気ままなブログ」ではさまざまなライブラリで株価データを可視化する方法を解説しています。
-
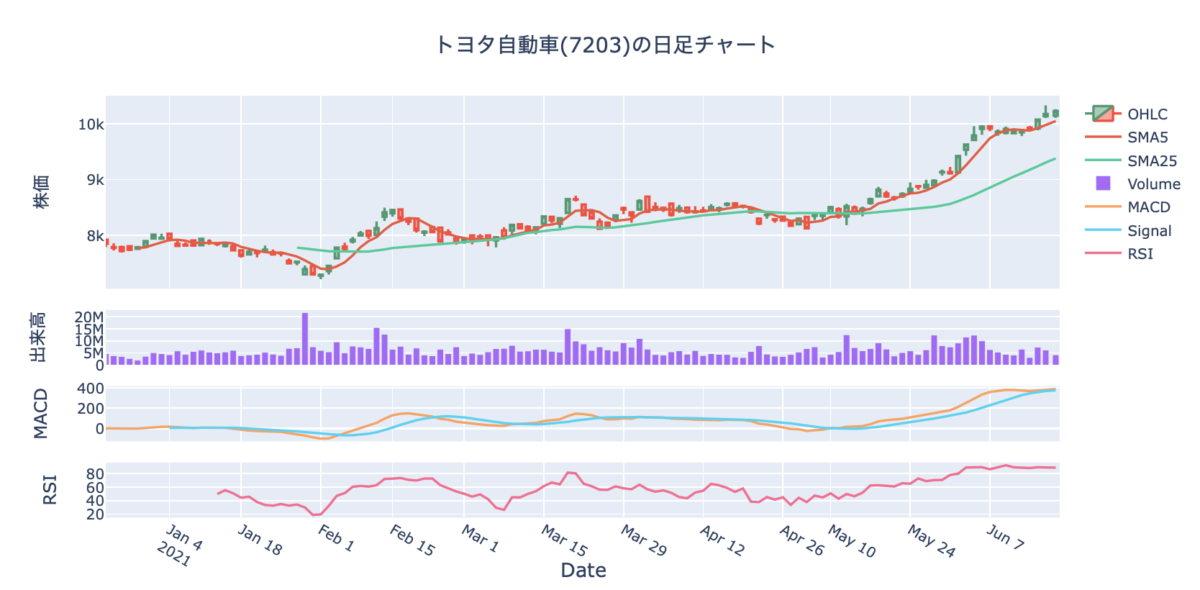
PythonのPlotlyでインタラクティブな株価のローソク足チャートを描く【コード解説】
続きを見る
-
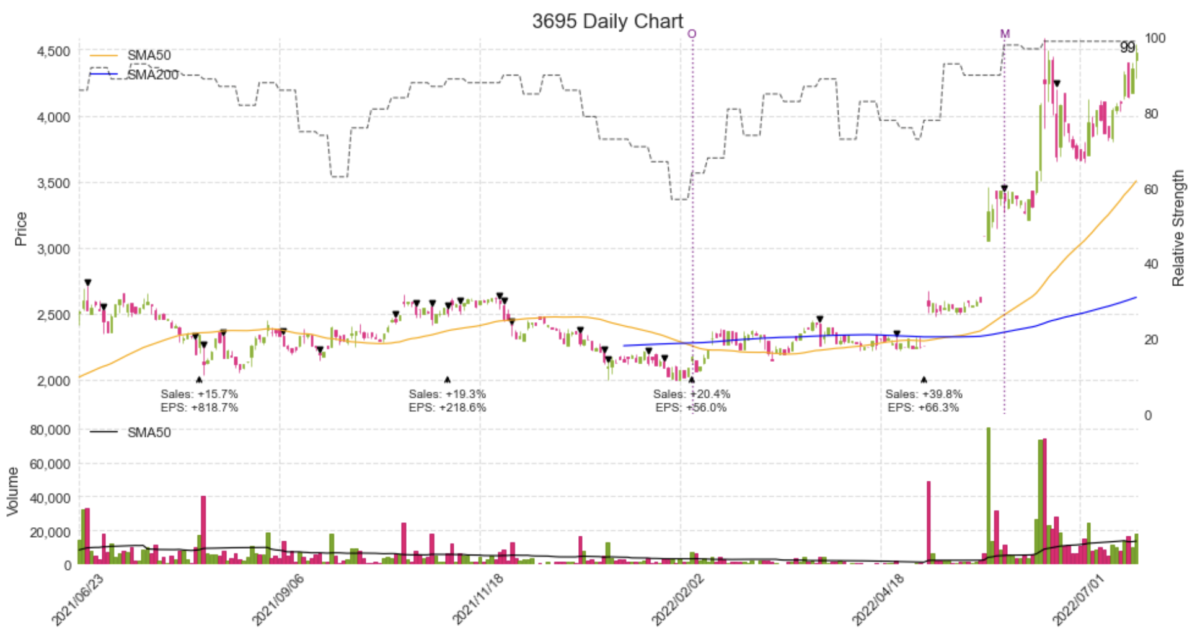
日本株でMarket Smith(マーケットスミス)みたいなチャートをPythonで自作してみた
続きを見る
売買戦略を考える
株価データがあれば、自動売買のシステムを作ることもできます。
いろいろな売買戦略を考えて、Pythonでバックテストすることもできます。
良い結果が出れば実際にトレードしてみても面白いと思います。
-

【Pythonで株式投資】52週高値と出来高を組み合わせると最強シグナルになるかもしれない
続きを見る
-
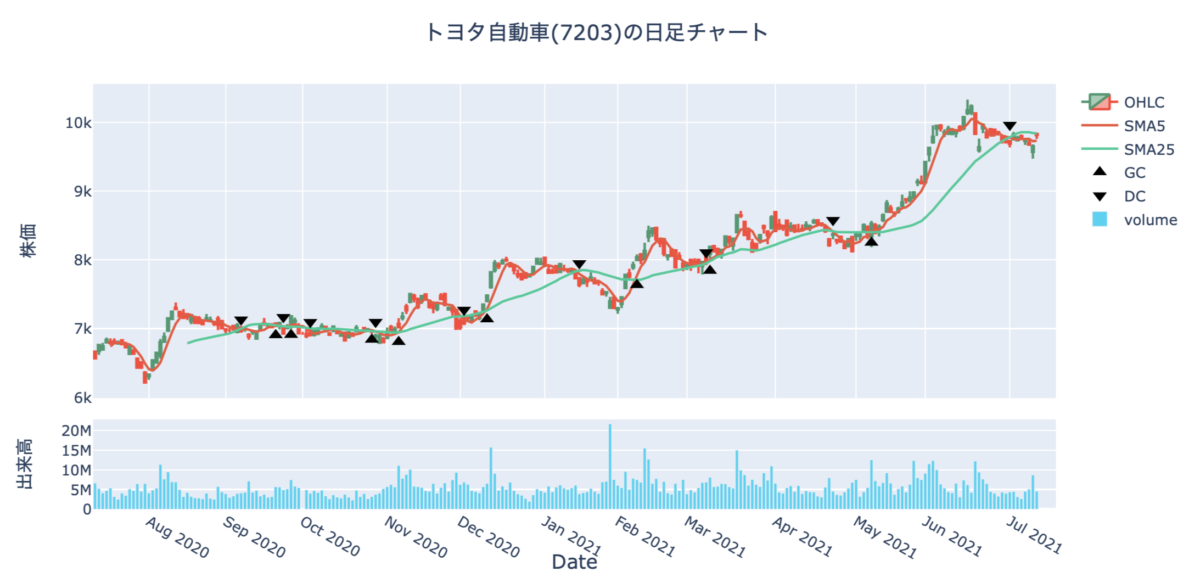
【コード解説】Pythonでゴールデンクロスとデッドクロスを判定する
続きを見る
-
Pythonで移動平均線の押し目・上放れ・下放れを自動検出する方法
続きを見る
記事一覧は「Pythonで株式投資」というタグから見れます!
上記で紹介した記事はごく一部です。
一覧については「Pythonで株式投資」というタグで検索していただけると確認することができます。
ご興味あれば見てあげてください。
まとめ
本記事では、Pythonを使って株価データを取得する方法についてまとめました。
いろいろな方法を紹介しましたが、ダントツでおすすめなのが「方法②:ライブラリを利用する」です。
比較的短いコードで株価データが簡単に取得できますし、日本株にも対応しています。
yahoo_finance_api2を使えば分足や時間足のデータも取得することができます。
pandas_datareaderでも日足データを取得すればPythonで週足・月足データに変換することも可能です。
Pythonはシンプルなコードで複雑な処理ができるので、株の分析に活用できると重宝します。
本ブログでは、株価データの取得方法だけでなく、株価データを分析する方法や可視化する方法なども解説しています。
もしご興味あれば、「Pythonで株式投資」というタグから探してみてください。
ここまで読んでくださってありがとうございました。









{kind=link}