

こんにちは。TATです。
今日のテーマは「【Pythonコード解説】SeleniumでInstagramの自動いいね!をしてみる」です。
Instagramにログインして、特定のキーワードで検索して、出てきた投稿にいいね!をする、という一連の流れをSeleniumを使って自動化してみます。
Seleniumはブラウザーをプログラムを通してコントロールできるソフトです。
クリックや画面遷移、スクロール、スクショの保存など、普段我々がネットサーフィンの中で行っている作業のほとんどを自動化することができます。
このSeleniumを利用して、Instagramのいいね!自動化に挑戦します。
いいね!を押しまくっていると結構フォロワーが増えるので、うまく使えば効率的にフォロワーを増やすことができます。
ただし、調子に乗りすぎると警告が出てしまう場合もあるのでご注意ください。
ちなみにここで紹介するコードはご自由にコピって使っちゃってください。
Seleniumを導入して、あとはusernameとpasswordさえ変更してしまえばすぐに利用可能です!
目次
【Pythonコード解説】SeleniumでInstagramの自動いいね!をしてみる

まずは自動いいね!までの流れを確認する
まずは自動いいね!までの流れを確認していきます。
自動いいね!までの流れ
- Instagramにログインする
- 特定のタグで検索する
- 検索結果の投稿に順番にいいね!を押す
流れとしてはこんな感じかと思います。
これをプログラムで自動化するとなると少しプロセスを分解していく必要があります。
少し細かくプロセスをまとめてみます。
自動いいね!までの流れ
- Seleniumを起動する
- Instagramログインページに遷移
- UsernameとPasswordを入力してログイン
- 特定のタグの検索結果ページに遷移
- 投稿一覧を取得
- 各投稿に対して、
- 投稿ページに遷移
- いいね!を押す(既に押されてたらスキップする)
上記の流れを実装することができれば、自動でいいね!をすることができます。
早速やっていきましょう。
Seleniumによる実装
それでは、実際に実装していきます。
流れがわかるように順番にコードを解説していきます。
実装するにはSeleniumが必要です。
"pip install selenium"でSeleniumをインストールしてください。
さらにWebdriverのダウンロードが必要です。こちらからダウンロードしてください。
特にこだわりがなければChromeで良いかと思います。
ダウンロードしたらPythonファイルと同じ場所に保存してください。
Seleniumの準備が完了したら、早速コードを書いていきましょう。
-
PythonでSeleniumを利用する方法!セットアップの流れを徹底解説します!
続きを見る
Seleniumを起動する
まずはSeleniumを起動するコードを書きます。
これをするには、次のコードを実行すればOKです。
from selenium import webdriver # SeleniumでChromeを起動 driver = webdriver.Chrome()
これでChromeが起動します。ちなみにWebdriverが別のフォルダーに保存されている場合はexecutable_pathで指定してあげればOKです。
この状態では、何のページも開いていないのでこんな感じで何も表示されません。
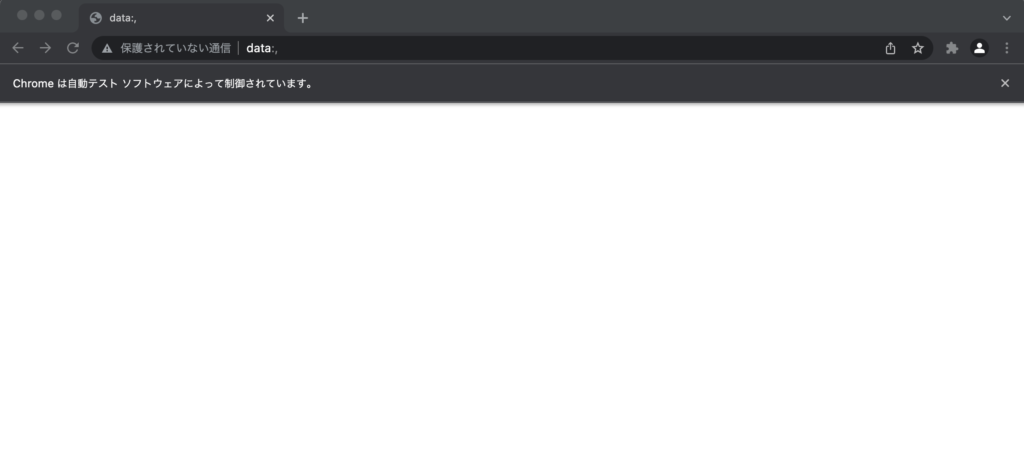
driverという変数にクラスが格納されているので、今後はこれを弄ってブラウザを操作していきます。
Seleniumで起動すると、「Chromeは自動テストソフトウェアによって制御されています。」という警告が表示されます。
これでSeleniumによるChromeの起動は完了です。
Instagramログインページに遷移
次にInstagramのログインページに遷移します。
get関数を使えば終了します。
ここに任意のURLをセットすればページ遷移できます。
# Instagram ログインページへ移動 loginUrl = "https://www.instagram.com/" driver.get(loginUrl) driver.implicitly_wait(30)
これでInstagramのログインページが表示されました。
implicitly_waitを入れておくと、次の処理を行う際に、設定した秒数分処理を繰り返しながら待ってくれます。
ページが読み込む前に次の処理を行おうとするとエラーになってしまうので、この1行を入れることで動作が安定します。
ページ読み込み時間によるエラーが予想される箇所にはこれを入れておくことをお勧めします。
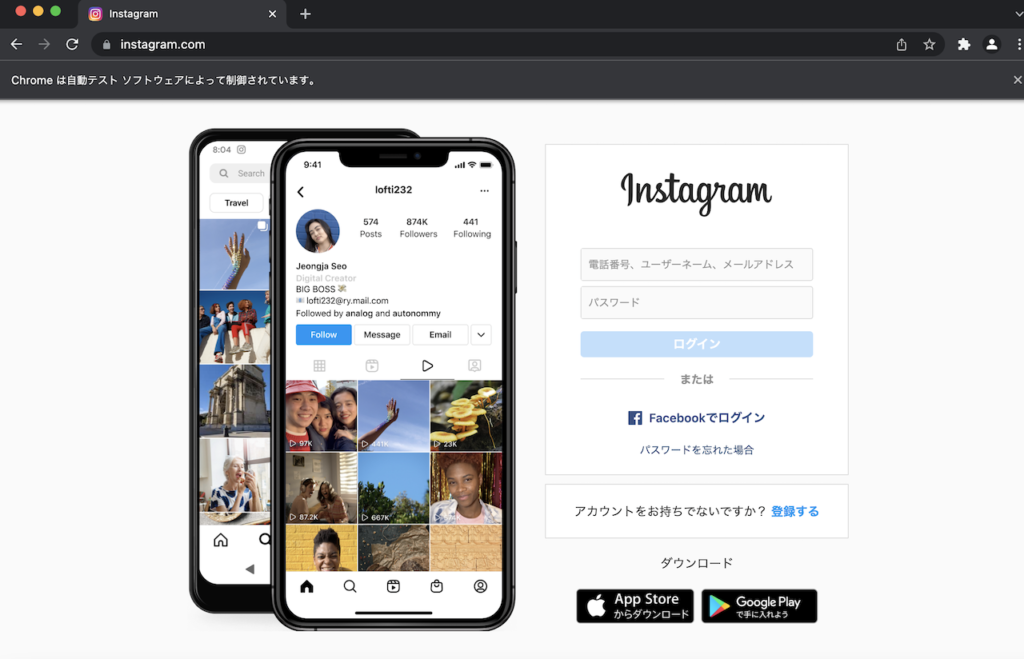
UsernameとPasswordを入力してログイン
次にUsernameとPasswordを入力してログインします。
ソースを見ると、usernameとpasswordという名前のinputがそれぞれあることがわかります。
ここを指定して文字を入力すればOKです。
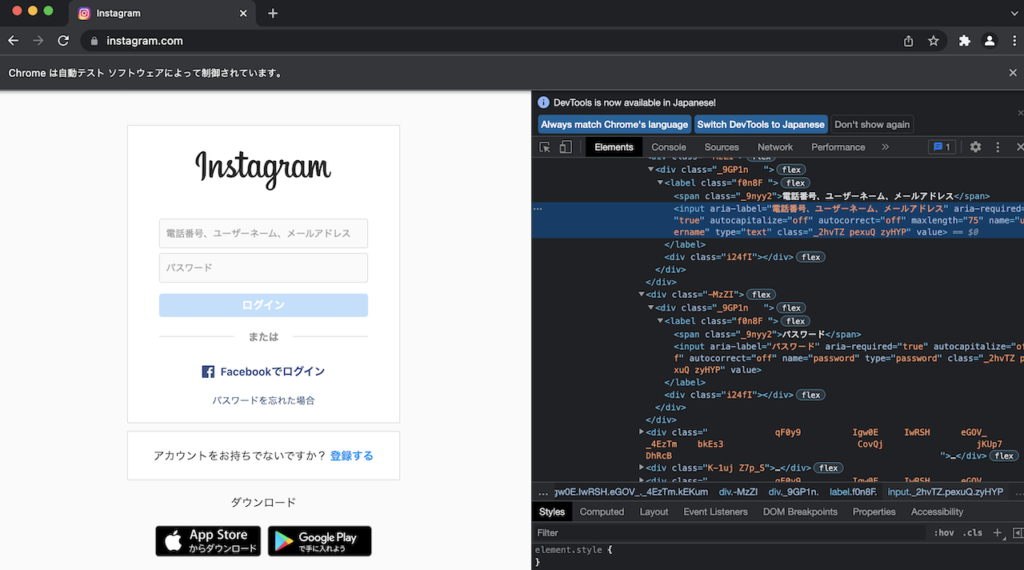
文字を入力するには、send_keys関数を使います。
入力したい要素を取得して、send_keys関数で任意を文字を入力すればOKです。
username = "username"
password = "password"
# Usernameを入力
usernameInput = driver.find_element_by_css_selector("input[name=username]")
usernameInput.send_keys(username)
# Passwordを入力
passwordInput = driver.find_element_by_css_selector("input[name=password]")
passwordInput.send_keys(password)
UsernameとPasswordがそれぞれ書き換えてください。
driver.find_element_by_css_selectorを使えば、条件にマッチしたタグを取得することができます。
この場合は、nameがusernameをinputタグを取得すると言った具合です。
取得したものを別の変数に格納し、send_keysで文字を入力しています。
このコードを実行するとこんな感じで文字が入力されていることが確認できます。
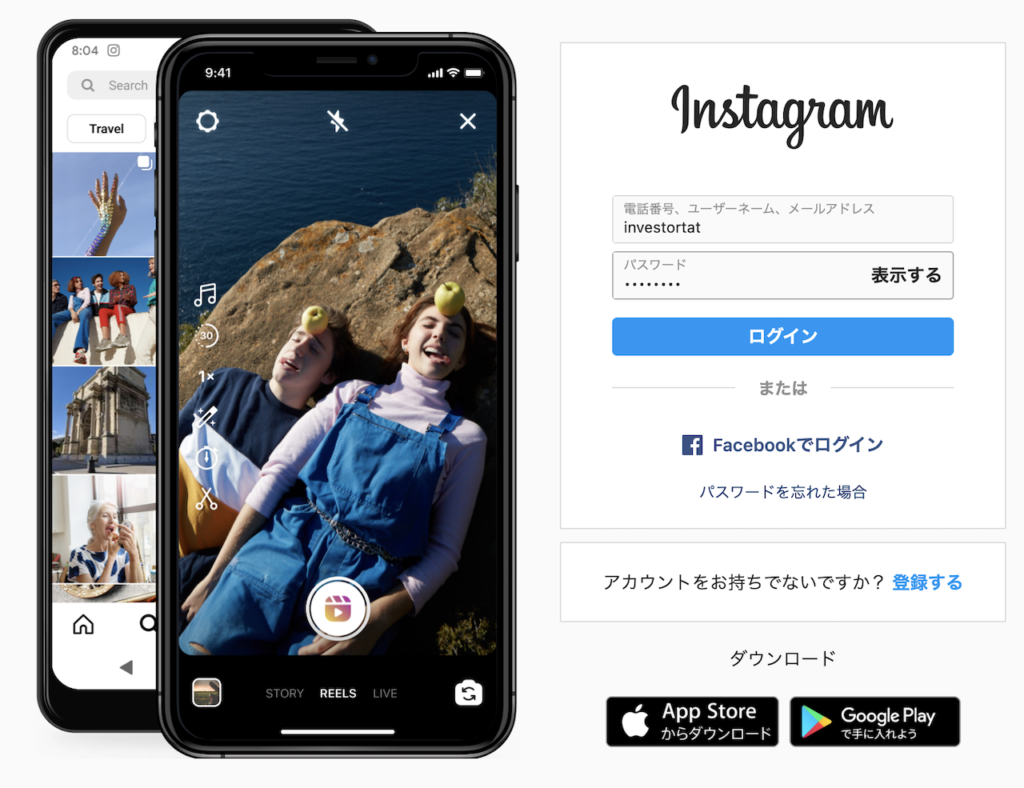
最後にログインボタンをクリックすればOKです。
ソースを見ると、typeがsubmitであるinputがあることがわかります。
submitボタンはここのソース内だと1つしかないので、これを指定すればうまくいきます。
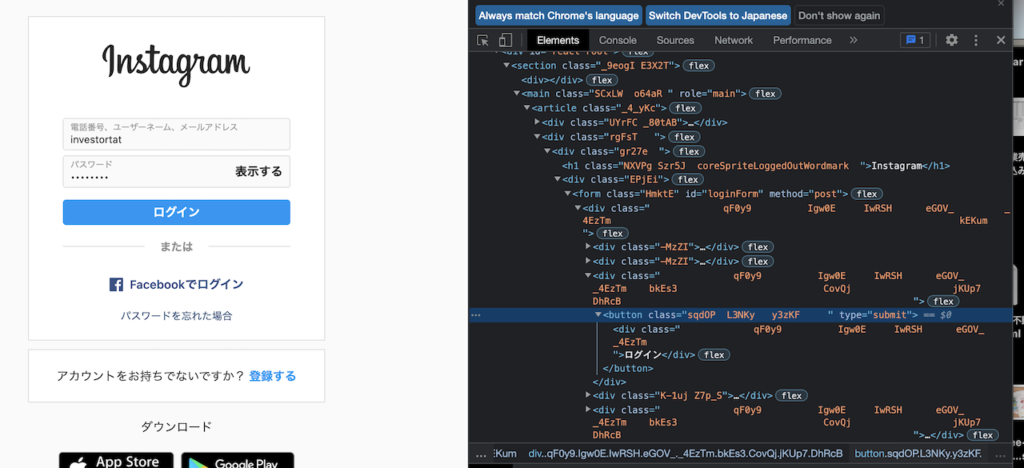
ボタンをクリックするにはclick関数を使います。
# ログインをクリック
loginButton = driver.find_element_by_css_selector("button[type=submit]")
loginButton.click()
このコードを実行すればログインが完了します。
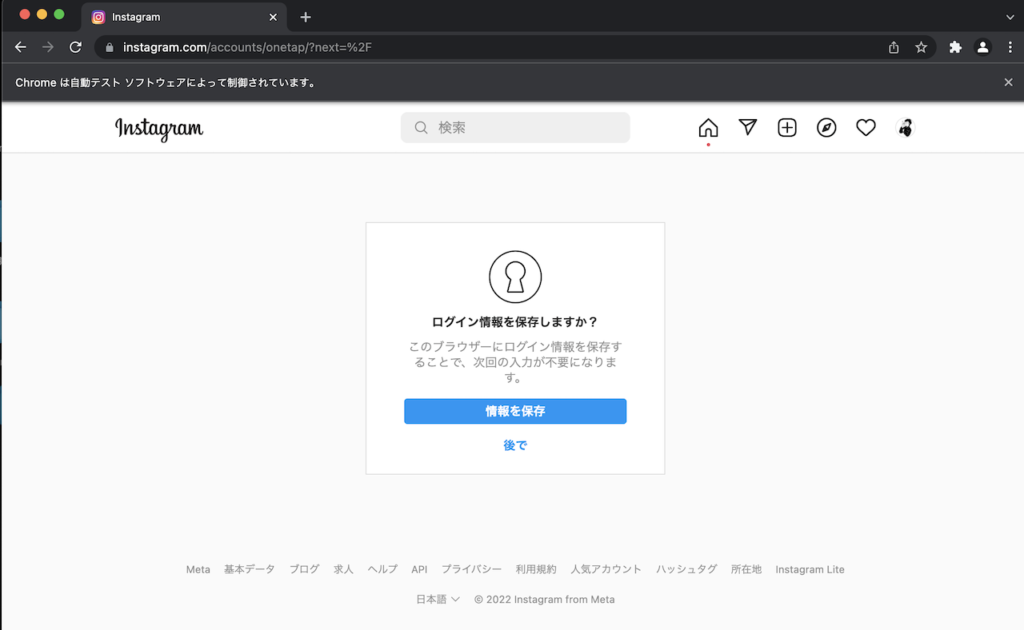
無事にログインできました。
特定のタグの検索結果ページに遷移
次に特定のタグの検索結果ページに遷移します。
Instagramのタグページはhttps://www.instagram.com/explore/tags/{{タグ名}}/となっています。
さらに最後にhl=jaをつけてあげると、日本語版で表示されます。これはあってもなくてもOKです。
ページ遷移をするにはget関数を使えばOKでしたね。
例として、"株式投資"で検索してみます。
この場合、https://www.instagram.com/explore/tags/株式投資/ に遷移すればOKです。
# tagページへ移動
tag = "株式投資"
tagUrl = "https://www.instagram.com/explore/tags/{}/?hl=ja"
driver.get(tagUrl.format(tag))
driver.implicitly_wait(30)
これでタグ一覧のページが取得できます。
一応画像にはモザイクかけました。
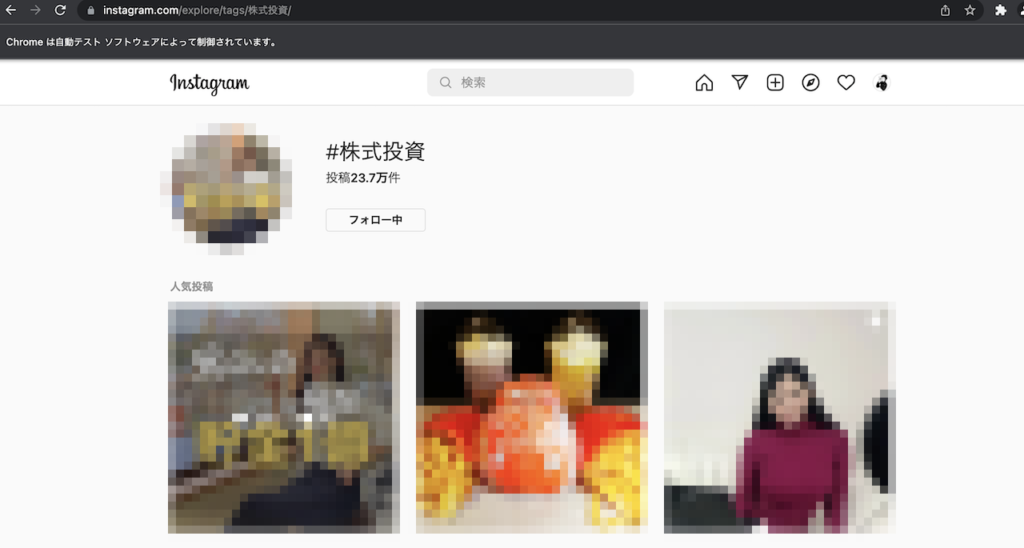
投稿一覧を取得
次の作業は表示された投稿一覧を取得することです。
ここでは、各投稿のURLがわかればOKです。
ソースコードを見ていくと、それぞれの投稿にはaタグがあることがわかります。
つまり、全部のaタグを取得すればOKです。
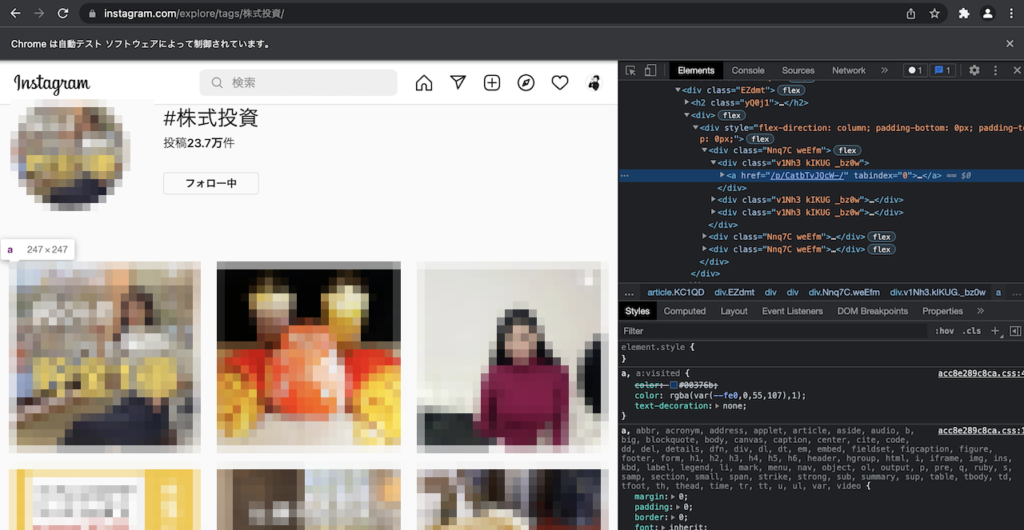
これをするにはfind_elements_by_tag_nameを使います。
find~にはelementとelementsがあります。
elementは最初にマッチする要素を、elementsはマッチする要素一覧をリスト形式で取得します。
ここでは、複数個あることが自明なのでelementsにします。
# aタグを取得
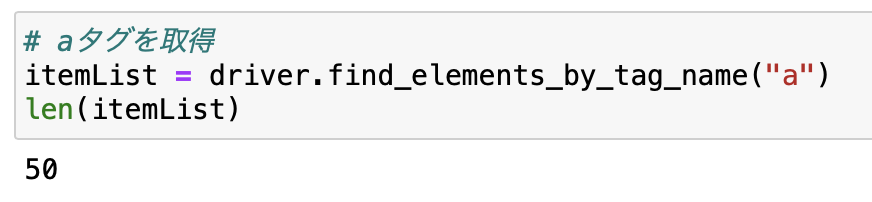
itemList = driver.find_elements_by_tag_name("a")
全部で50個取得できました。
それぞれの要素からリンクを取得できるので、これで準備はOKです。

ちなみにそれぞれのリンクを見てみると、投稿ページではないリンクも取得してしまっていることがわかります。
投稿ページだとURLの途中に/p/が入ります。
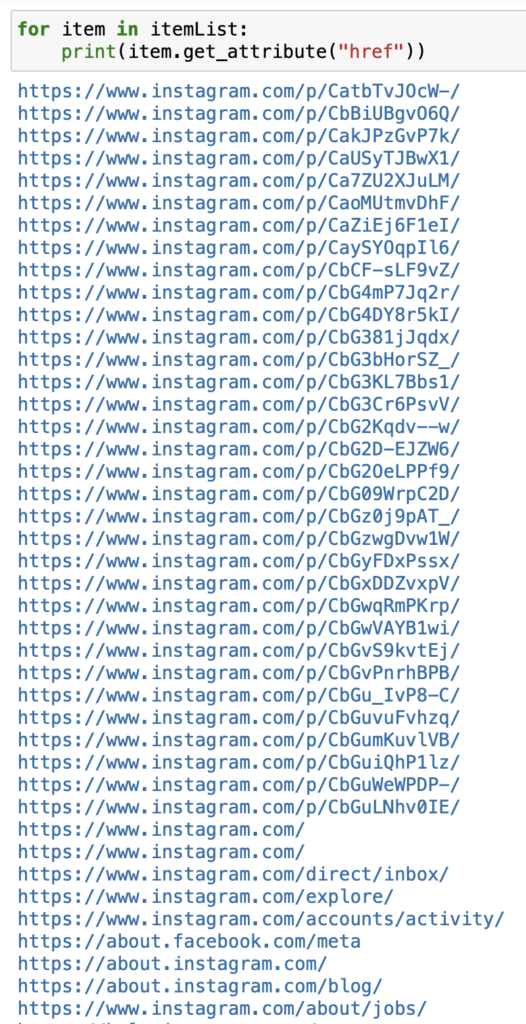
これを回避するには、そもそもaタグの取得方法を見直すか、リンクの確認ロジックを導入する必要が出てきます。
今回は確認ロジックをいれます。こっちの方が楽なのでw
各投稿に対して、投稿ページに遷移していいね!を押す
あとは各投稿に遷移して、いいね!を押していけばミッション完了になります。
いいね!を押す
まずはいいね!を押す手順を確認します。
適当なタグページに遷移します。
他人の投稿を晒すのは忍びないので、僕のアカウントの画像でみていきます。
こちらです。
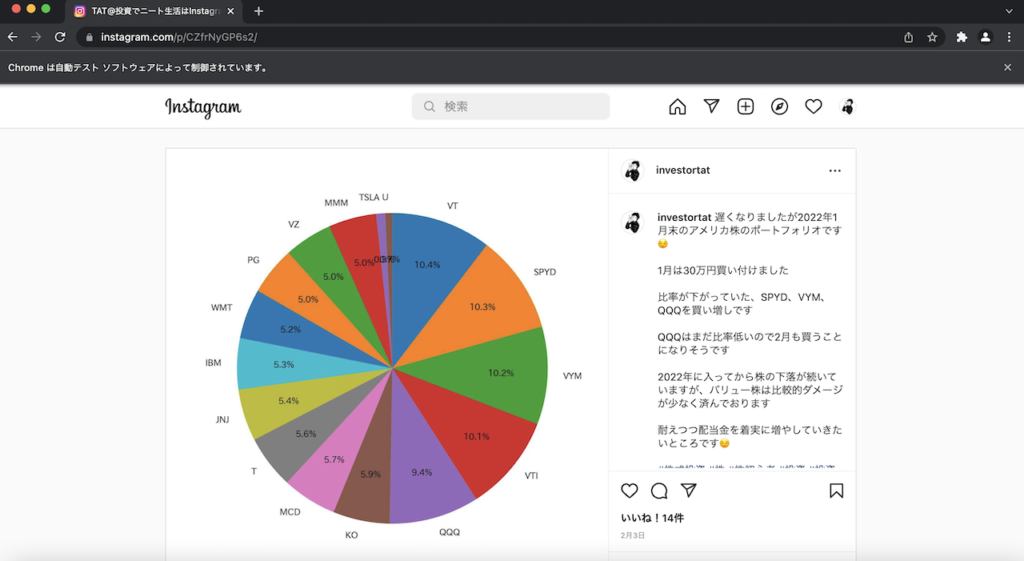
ここでいいね!のソースコードを確認します。
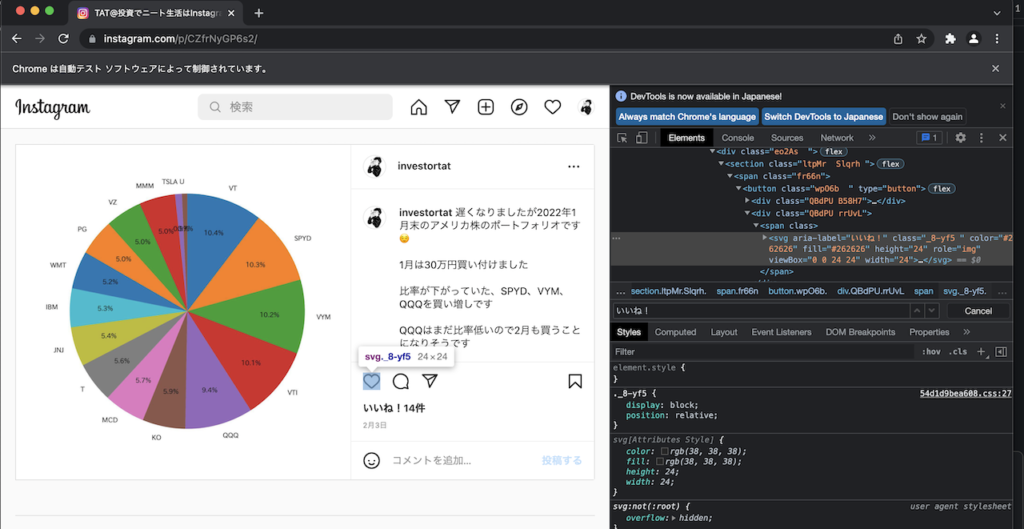
aria-labelがいいね!となっているsvgタグがあることがわかりますね。
構造をみるとsection→button→span→div→span→svgとなっていますね。
ちなみにHTMLを見るとこのsvgタグはなぜか2つあり、片方はクリックができますが、もう片方はクリックできない仕様になっています。
この仕様は謎です。
クリックできるのはspanの中にあるものなので、これを明確に指定してあげる必要があります。
こんな感じで取得できます。
![]()
これをクリックすればOKです。
クリックするにはClick関数を使います。

これでいいね!を押すことができます。
ちなみにすでにいいね!が押されている場合、aria-label=いいね!の要素がなく、『aria-label=「いいね!」を取り消す』という内容に変わっています。
よって、『「いいね!」を取り消す』を含む要素がある場合には、既にいいね!がされているのでスキップすればOKです。
これを行うにはBeautifulSoupでhtmlを解析して確認します。
from bs4 import BeautifulSoup
# htmlの取得
soup = BeautifulSoup(driver.page_source, "html.parser")
if soup.find("svg", {"aria-label": "「いいね!」を取り消す"}) is None:
driver.find_element_by_css_selector("section span button div span svg[aria-label=いいね!").click()
上記のコードを実行することで、既にいいね!がされている投稿をスキップすることができます。
各投稿に繰り返す
この動作を各投稿に繰り返せばOKになります。
ついでに投稿のURLを確認するロジックも加えます。
投稿URLでない場合はスキップします。
from bs4 import BeautifulSoup
from time import sleep
import random
# urlが投稿ページかどうかを確認
def is_post_url(url):
if "/p/" in url:
return True
else:
return False
def is_liked(soup):
if soup.find("svg", {"aria-label": "「いいね!」を取り消す"}) is None:
return True
else:
return False
urlList = [item.get_attribute("href") for item in driver.find_elements_by_tag_name("a")]
for url in urlList:
if is_post_url(url):
print(url)
driver.get(url)
driver.implicitly_wait(30)
sleep(3)
# htmlの取得
soup = BeautifulSoup(driver.page_source, "html.parser")
# いいね!が押されていなかったら押す
if is_liked(soup):
driver.find_element_by_css_selector("section span button div span svg[aria-label=いいね!").click()
# 数秒待機
waitTime = random.choice(range(1, 6))
print("{}秒待機...".format(waitTime))
sleep(waitTime)
上記のコードを実行すると、各投稿に対していいね!を実行します。
is_post_url関数でURLが投稿ページでないかどうか、is_likedで既にいいね!が押されているかどうかをチェックしています。
これでミッション完了です。
これを定期的に繰り返せば、自動でいいね!をつけまくることができます。
ただし注意点として、あんまり調子こいてやりまくるとBot判定される場合があります。
それを回避するためにも、数秒待機するためのロジックをいれています。
これは1〜5秒のランダムの値を待機するという内容になります。
コードをまとめて公開!
最後にこれまで解説したコードをまとめて公開します。
みやすくするために、機能ごとに関数で分けました。
Seleniumを導入したうえ、こちらをコピーしてUsernameとPasswordを変更いただき、searchWordで任意の検索ワードを設定いただければすぐに動作するかと思います。
動作しない場合は動作環境の確認など、エラーメッセージに従って対応してみてください。
from selenium import webdriver
from bs4 import BeautifulSoup
from time import sleep
import random
username = "username"
password = "password"
searchWord = "検索ワード"
# ログイン
def login(driver):
# Instagram ログインページへ移動
loginUrl = "https://www.instagram.com/"
driver.get(loginUrl)
driver.implicitly_wait(30)
# Usernameを入力
usernameInput = driver.find_element_by_css_selector("input[name=username]")
usernameInput.send_keys(username)
sleep(3)
# Passwordを入力
passwordInput = driver.find_element_by_css_selector("input[name=password]")
passwordInput.send_keys(password)
sleep(3)
# ログインをクリック
loginButton = driver.find_element_by_css_selector("button[type=submit]")
loginButton.click()
return driver
# urlが投稿ページかどうかを確認
def is_post_url(url):
if "/p/" in url:
return True
else:
return False
def is_liked(soup):
if soup.find("svg", {"aria-label": "「いいね!」を取り消す"}) is None:
return True
else:
return False
# SeleniumでChromeを起動
driver = webdriver.Chrome()
# ログイン
driver = login(driver)
"""
定期的に実行する際には、ログインした状態を維持したまま、これより下のコードを繰り返した方がいいです。
毎回ログインしてるとすぐに怪しまれます。
"""
# tagページへ移動
tagUrl = "https://www.instagram.com/explore/tags/{}/?hl=ja"
driver.get(tagUrl.format(searchWord))
driver.implicitly_wait(30)
# aタグを取得
urlList = [item.get_attribute("href") for item in driver.find_elements_by_tag_name("a")]
# 各投稿へアクセスしていいね!を押す
for url in urlList:
if is_post_url(url):
print(url)
driver.get(url)
driver.implicitly_wait(30)
sleep(3)
# htmlの取得
soup = BeautifulSoup(driver.page_source, "html.parser")
# いいね!が押されていなかったら押す
if is_liked(soup):
driver.find_element_by_css_selector("section span button div span svg[aria-label=いいね!").click()
# 数秒待機
waitTime = random.choice(range(1, 6))
print("{}秒待機...".format(waitTime))
sleep(waitTime)
定期的に実行する際には、ログイン状態を維持したままタグページの検索といいね!を繰り返した方がいいです。
毎回ログインしているとすぐにBotと怪しまれます。
Bot判定されるとログインできなくなります。その際にはパスワードを変更する必要が出てきたりと面倒なのでお気をつけください。
いずれにしても、利用する際には自己責任でお願い致します。
やり方は他にもたくさんあります
ここまでで、Seleniumを使ってInstagramで自動いいね!をする方法について解説してきました。
ここでお伝えしたやり方はあくまでの数多あるうちの1つに過ぎません。
このほかにもいろいろなやり方があります。
僕の場合は投稿URLに遷移していましたが、クリックして投稿を表示してからいいね!をすることも可能ですし、一度に多くの投稿を対象にしたいのであれば、スクロール機能を活用してさらに写真を読み込むことだってできます。
その気になればここで紹介した内容はすべてSeleniumなしで実装することも可能です。
あくまでもここで紹介した方法は一例に過ぎないので、参考にしていただきつついろいろな方法を試していただければと思います。
結局はPythonが最強!
本記事で紹介したコードは全てPythonです。
Pythonを使うと複雑な処理でも比較的短いコードで実装することができます。
今回解説したSeleniumを使った処理の他にも、Webスクレイピングやデータ分析、AI関連に強くて、Pythonは今世界中で人気を集めている言語です。
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
Pythonは世界中で需要が高まっている言語であり、習得しておくと仕事や転職でも有利になります。
僕自身も社会人になってからPythonを独学しました。それくらい学びやすい言語でもあります。
もし興味があれば、とてもおすすめです。
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】
-

【まとめ】Pythonが学べるおすすめプログラミングスクール4選
まとめ
いかがでしたでしょうか。
ここでは「【Pythonコード解説】SeleniumでInstagramの自動いいね!をしてみる」というテーマで解説してきました。
Seleniumを活用すれば、ログインなどの複雑な処理も比較的に短いコードで実装できることがおわかりいただけたのではないでしょうか。
うまくこのコードを使えば、定期的にいいね!を押して効率的にフォロワーさんを増やすことも可能です。
ただし、調子に乗り過ぎるとBot判定されてしまうので、あくまで自己責任でご利用ください。
ここまで読んでくださり、ありがとうございました。




{kind=link}