
こんにちは。TATです。
今日はPythonによるプログラミングを解説していきます。
テーマはSUUMOに掲載されている賃貸物件情報のスクレイピングです。
過去にSUUMOから取得した情報を分析する記事をご紹介しました。
-

【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
今回は、これらの記事を執筆する際に書いたPythonプログラムから、特にスクレイピングのために書いたコードにフォーカスして解説していきます。
こんな感じで順番に解説していきます。
目次
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】

1. 取得したいデータの確認(おさらい)
まずは取得したいデータの確認です。
こちらの記事で紹介しているデータを取得するためのプログラムを考えます。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
最終的なアウトプットを確認
最終的に取得するデータはこちらです。
上の記事で使用した写真を引用しました。
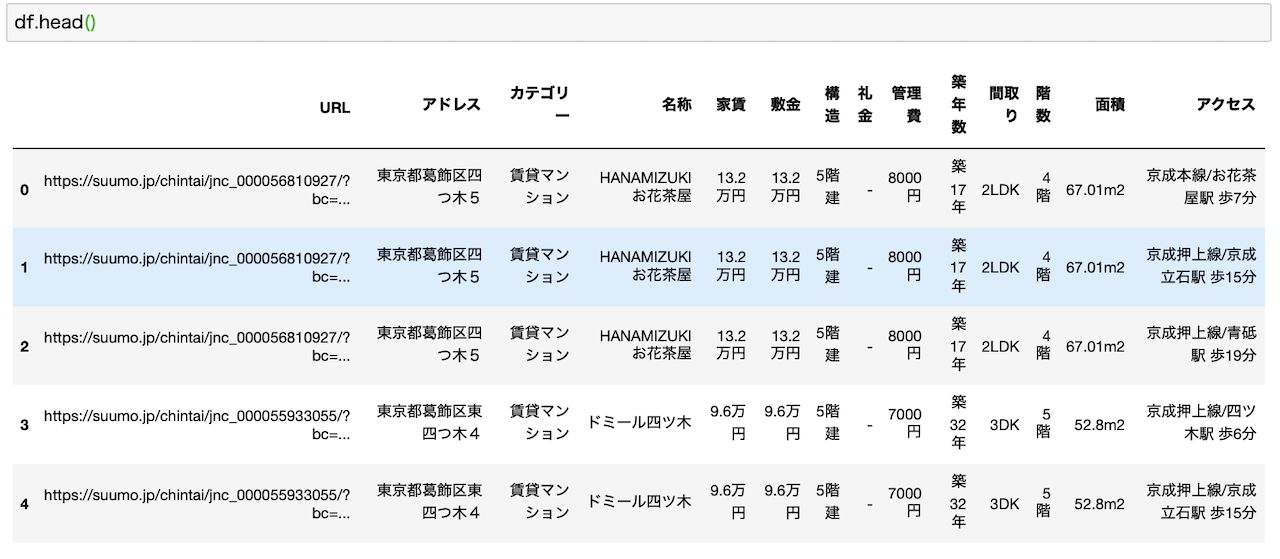
各行に物件名やURL、カテゴリー、名称、家賃、面積など様々なデータが含まれています。
SUUMOのサイトをスクレイピングして、最終的にこのようなデータに整えることを目指してプログラムを書きます。
対象データは東京23区
そして今回対象とした物件は東京23区としています。
元々は都内で良さそうな物件を探すために始めたプログラムなので、エリアは特に23区内に限定しています。
これは僕がこれらの地域に住むことを前提としているからですw
別のエリアを探す際には、URLをちょろっと変更すれば対応できますのでご安心ください。(後述します)
2. SUUMOのサイトの確認
次にサイトを確認します。
今回は別記事で紹介しているので、最終的なアウトプットの紹介から始めていますが、本来であればサイトの確認から始めます。
取得したいサイトの構造をチェックしたり、そもそも必要な情報が取得できるかどうかもここでチェックする必要があります。
ここからもこちらの記事の写真を再利用して解説していきます。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
サイトで対象地域を選択
まずSUUMOのサイトに行くと、物件を探したいエリアを選ぶことができます。
物件の条件も加えることができますが、ここでは全物件を取得したいので設定していません。
都道府県を選択すると、さらに細かい地域を選択できます。
ここではエリア選択を選んでいますが、路線ごとや駅ごとの選択も可能です。
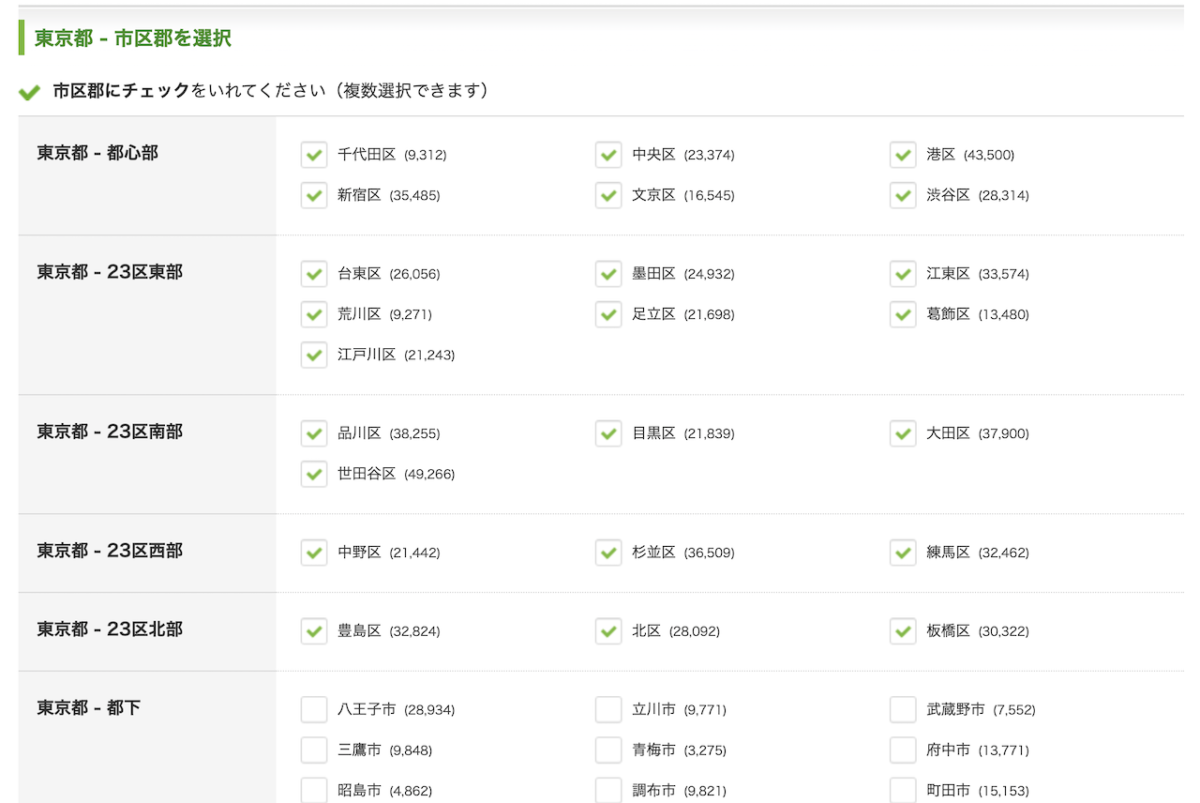
今回は、東京23区が対象なので、全区を選択して検索をクリックします。
物件データを確認
検索をクリックすると該当する物件がずら〜っと出てきます。
調べた時では全部で635,695件ありました。
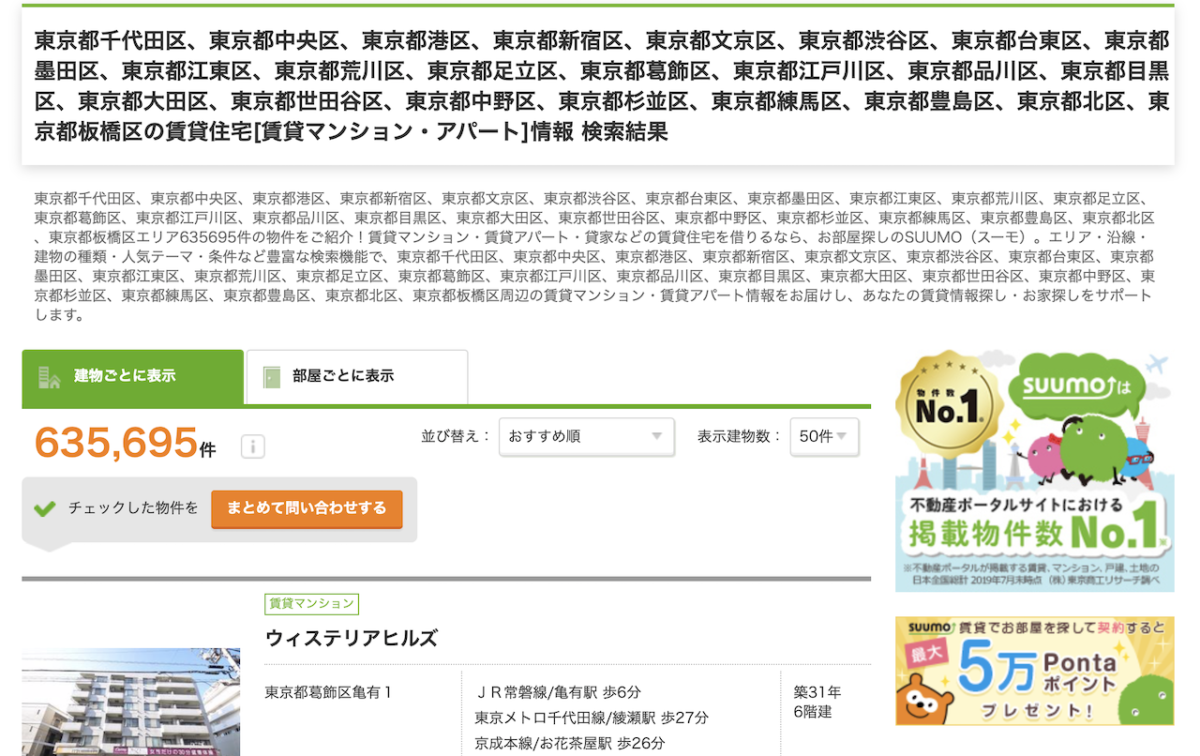
総ページ数を確認
一番下までスクロールすると全部で1,697ページあることがわかります。
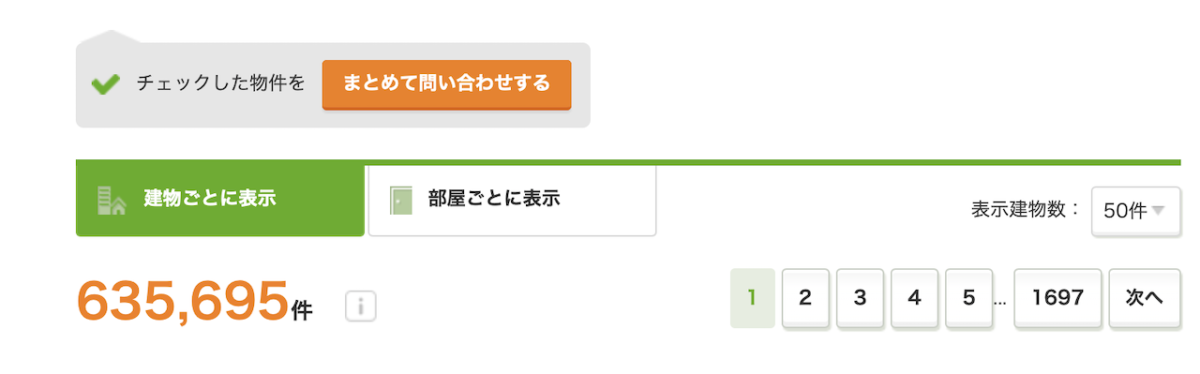
1ページごとに50件の物件が表示されるので、ここからページ数を計算することもできると思われるかもですが、ここで落とし穴がありますw
単純に、635,695を50で割っても1,697にはなりません。
これはSUUMO側で同一物件と思われる物件は排除しているためです。
それでもまだまだ重複はたくさんありますけどねw
なので、ページ数を確認するには、物件数から計算するのではなくて、きちんと最終ページ数を確認する必要があります。
URLの構造を確認
物件情報をチェックしたら次はURLの構造をチェックします。
ページ構造を見るために、2ページ目にいきます。
2ページ目のURLを見ると、次のような構造になっていることがわかります。
ここからいくつかのパターンが見えてきます。
おそらく、scは各エリアを示していると思われます。ここでは区ですね。
そして、pcが1ページあたりに表示する物件数で、pageがページ数です。
このpageを1から1,697まで順番に切り替えていけば、全物件情報が取得できることがわかります。
さらにarやbsやtaはさらに広域のエリアを示してるかもですね(ここは確信ないですw)
よって、ご自身で調べたいエリアを選択して、検索して得られたURLを使えばうまく対応できそうです。
本気を出せばこの対応表を作成することもできます。
それができたら、プログラム内で自由にエリアを選択することができるようになります。
(おまけ)SUUMOを選んだ理由
ここでコード解説へ行く前に、おまけとしてなぜSUUMOを選んだのかというところにお答えしておきます。
物件情報はSUUMOの他にもHOME'Sやアットホームなど様々なウェブサイトがあります。
その中からなぜSUUMOを選んだのかと言いますと、結論はシンプルでサイトが整っていたからです。
特に、物件一覧ページでなるべく多くの情報が取得できるサイトを探しました。
結果としてSUUMOが一番いい感じだったんですね。
SUUMOでは物件一覧のページから取得できるデータでも、他サイトでは物件の詳細ページにいかないと確認できないものもありました。
こういう場合だと、各物件の詳細ページもスクレイピングする必要が出てくるので非常に時間がかかります。
スクレイピングする際には、なるべくデータが整っているサイトを選ぶと良いです。
なおかつ、スクレイピングするページ数を最小化するように心がけると良いですね。
ただ、サイトによってはそもそも物件数がめちゃくちゃ少ないという場合もあるので、ある程度のデータ数があるかどうかもチェックしておく必要があります。
こういった様々な角度から見た結果、SUUMOがベストだろうという結論に至りました。
3. スクレイピング用のプログラミングを解説
それでは、取得するデータやサイトの確認ができたので、プログラミングの解説に進みます。
ここがメインですね。
先に申し上げておきますが、ここで紹介するプログラミングコードは趣味のために遊びで書いたものです。
ゆえに、仕事で書くような綺麗さとかは求めていませんw
もっといいやり方があればじゃんじゃん改良してください。
そしてどんどんコードはパクっていただいて大丈夫です!
まずは全コードを公開
ただ、コード解説をブログでするのが初めてなので、どんな感じで進めていけばいいのか迷っていますw
とりあえず全部どかーんと公開して、その後にちまちまと解説していくスタイルにします。
それではコードをどうぞ!
スクレイピングに関するコードのみです。一応できる限りコメントもつけました。
from retry import retry
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 東京23区
base_url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&sc=13109&sc=13110&sc=13111&sc=13112&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=25&pc=50&page={}"
@retry(tries=3, delay=10, backoff=2)
def get_html(url):
r = requests.get(url)
soup = BeautifulSoup(r.content, "html.parser")
return soup
all_data = []
max_page = 1697
for page in range(1, max_page+1):
# define url
url = base_url.format(page)
# get html
soup = get_html(url)
# extract all items
items = soup.findAll("div", {"class": "cassetteitem"})
print("page", page, "items", len(items))
# process each item
for item in items:
stations = item.findAll("div", {"class": "cassetteitem_detail-text"})
# process each station
for station in stations:
# define variable
base_data = {}
# collect base information
base_data["名称"] = item.find("div", {"class": "cassetteitem_content-title"}).getText().strip()
base_data["カテゴリー"] = item.find("div", {"class": "cassetteitem_content-label"}).getText().strip()
base_data["アドレス"] = item.find("li", {"class": "cassetteitem_detail-col1"}).getText().strip()
base_data["アクセス"] = station.getText().strip()
base_data["築年数"] = item.find("li", {"class": "cassetteitem_detail-col3"}).findAll("div")[0].getText().strip()
base_data["構造"] = item.find("li", {"class": "cassetteitem_detail-col3"}).findAll("div")[1].getText().strip()
# process for each room
tbodys = item.find("table", {"class": "cassetteitem_other"}).findAll("tbody")
for tbody in tbodys:
data = base_data.copy()
data["階数"] = tbody.findAll("td")[2].getText().strip()
data["家賃"] = tbody.findAll("td")[3].findAll("li")[0].getText().strip()
data["管理費"] = tbody.findAll("td")[3].findAll("li")[1].getText().strip()
data["敷金"] = tbody.findAll("td")[4].findAll("li")[0].getText().strip()
data["礼金"] = tbody.findAll("td")[4].findAll("li")[1].getText().strip()
data["間取り"] = tbody.findAll("td")[5].findAll("li")[0].getText().strip()
data["面積"] = tbody.findAll("td")[5].findAll("li")[1].getText().strip()
data["URL"] = "https://suumo.jp" + tbody.findAll("td")[8].find("a").get("href")
all_data.append(data)
# convert to dataframe
df = pd.DataFrame(all_data)今、見返すとやたらfor分が何重にも重なってますねwww
まあ、それぞれのページの処理は全然重くないので、今回はこれで全然OKです、たぶん。
max_pageだけ自分で入力する感じです。
それでは順番に解説していきます。
利用するライブラリ
まずは利用するライブラリについてです。
今回使っているのは次の4つです。
- from retry import retry
- import requests
- from bs4 import BeautifulSoup
- import pandas as pd
retry
一つ目のretryはプログラムがエラーした際の処理を書く際に使います。
今回はget_htmlという関数で用いていますが、これでしくじったら10秒後にもう一回、合計で3回試せといったような使い方をします。
スクレイピングをする際には、特にサーバーが不安定な場合はデータ取得に失敗することもあるので、こうした際の保険としretryが使えます。
ちなみにSUUMOをスクレイピングした時には、retryが使われることはありませんでした。
それでもこいつをいれとく癖はつけておいて損はないです。
requests
次のrequestsはhttp通信をするためのライブラリです。
平たく言えば、これで指定したURLにリクエストを投げてあげると、該当ページのhtmlを取得することができます。
コード内にあるr = requests.get(url)がそれに該当します。
BeautifulSoup
3つ目のBeautifulSoupはhtmlの解析するために使います。
これを利用すると、htmlのデータに簡単にアクセスできるようになります。
後述しますが、class名が〇〇のpタグを取得するみたいなことが簡単にできるようになります。
コード内にあるsoup = BeautifulSoup(r.content, "html.parser")が、requestsで取得したhtmlを解析できるように変換してくれる役割を果たしています。
今後は、このsoupという変数にアクセスしてデータを解析していきます。
Pythonでスクレイピングする際には、requestsとBeautifulSoupがセットで使われることが多いです。
pandas
最後のpandasは、データ分析によく利用されるライブラリです。
データサイエンスをするなら必須となるライブラリになります。
ここでは、取得したデータをdataframeに変換するために利用しています。
ざっくりと言えば、エクセルでできるような計算がpandasではもっとスマートにできるようになります。
各ページの処理
次にページごとの処理について見ていきます。
ここが分かれば、あとは1,697ページまで同じことを繰り返していけばOKです。
ちょっとここからはfor分がいくつも出てきてわかりにくいので、処理している単位を可視化してみました。
こちらに示すA~Eの単位で処理しています。
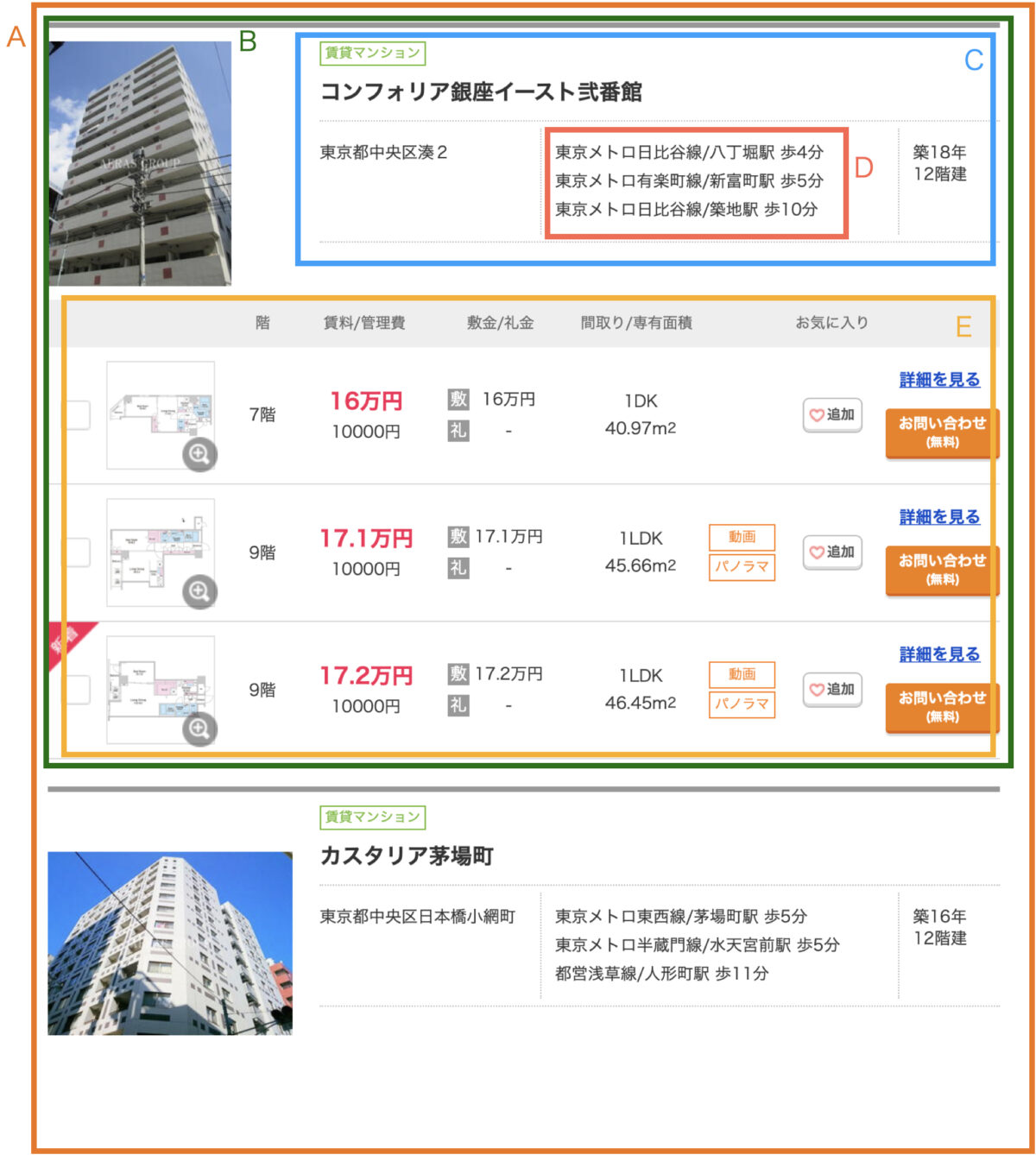
まずは各ページのHTMLを取得
まず、Aに行く前に一覧ページのHTMLを取得します。
それが最初のfor文であるfor page in range(1, max_page+1)になります。
これで、pageに数値を1から順番に代入して、それに該当するページのurlを作成します。(20行目、# define urlのところ)
このURLのHTMLを取得して、解析できる形に成形するのが次の文です。(23行目、# get htmlのところ)
各物件のHTMLを取得
次に、一覧ページから物件情報(A)を取得します。
各ページに50件の物件が掲載されているので、このデータ数は50になります。
この50個あるデータの1つ1つがBに該当します。
items = soup.findAll("div", {"class": "cassetteitem"})で各物件情報を取得しています。
これは、divタグで、なおかつclass名がcassetteitemであるものを全て取得せよという命令になります。
Google Chromeの「検証」を使うとこんな感じで確認できます。
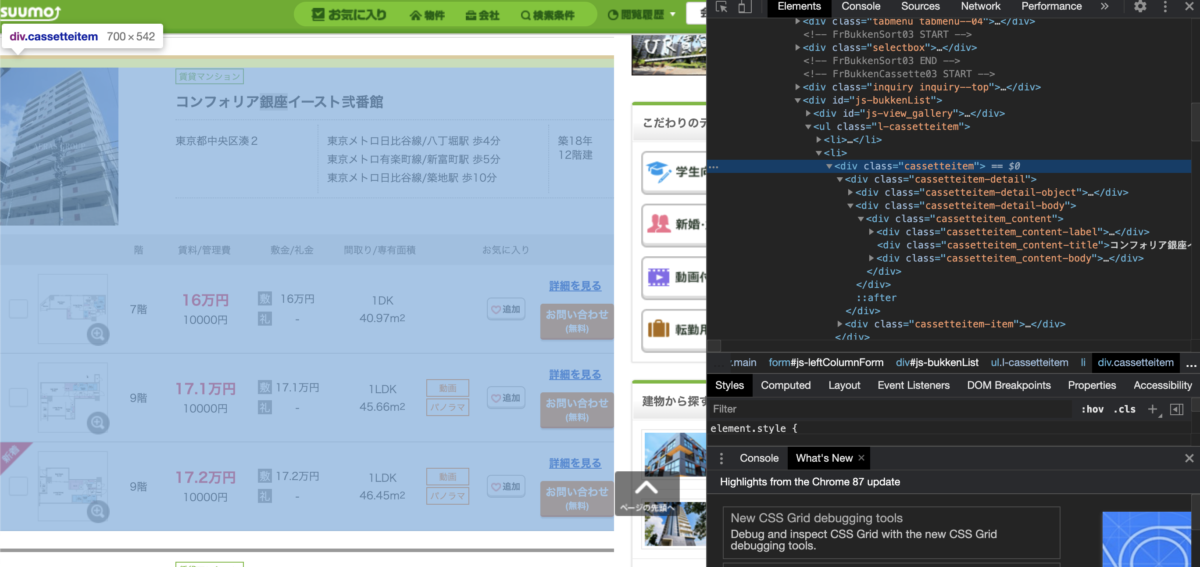
HTMLを解析するということは、このようなページを確認して、どのようにタグを指定すれば必要とされるデータが取得できるかを考える必要があります。
よって、スクレイピングを行うには最低限のHTMLの知識は必要になってきます。
ここで取得できた物件がBに該当します。50個あるはずです。
各物件単位のデータにアクセス
次に各物件ごとのデータ(B)にアクセスして、必要な情報を抽出していきます。
まずは物件単位でアウトプット用の関数を定義(36行目、# define variableのところ )して、基本情報(C)を取得します。(39〜44行目、 # collect base informationのところ)
部屋とアクセスでデータを分ける
次にやるのが、アクセス(D)ごとおよび各部屋のデータ(E)を取得することです。
複数のアクセスがある場合には、それぞれ別の行としてカウントします。
部屋も同様です。
この図の場合にはアクセスと部屋がそれぞれ3つずつあるので、行数としては合計で9行(3×3)のデータになります。
僕の場合はこのようなデータフォーマットにしましたが、これが正解なわけではないので、やりやすい形に整形していけばOKです。
この処理を各ページに繰り返し行うことで、全物件情報を取得することができます。
ちなみに結構時間かかります。うる覚えですが2〜3時間はかかります。
その時の物件数やネットワーク環境、パソコンのスペックなどによってこれは変わります。
(おまけ①)ページ数を自動取得することもできます
次におまけとして改善点を上げておきます。
それがmax_pageの設定です。
今回はだるかったので、手動入力にしてしまいましたが、これを自動化することも可能です。
自動化したら、データを取得するたびにいちいち変更する手間がないので便利です。
前述の通り、物件数を表示物件数で割ると計算が狂ってしまうのでこれは使えません。
ではどうするか。
僕がパッと考えつくアイデアは、「次へ」のリンクが存在するかどうかです。
存在すれば、pageに1を加えて処理を繰り返し、これがなければ処理を終了します。
for文ではなくて、while文として、「次へ」があるかどうかでloop処理を抜けるかどうかを判断すれば、この作業は自動化できます。
もし興味があればトライしてみてください。
数行で実装できます。
(おまけ②)HTML構造について
次にHTMLの構造について触れておきたいと思います。
慣れるとどうってことないのですが、最初のうちはここに苦労します(僕のことw)
特にHTMLの知識がないと絶望しますw
ポイントは、HTMLは階層型の構造になっているということです。
一番大きな枠に<html></html>があり、その配下に<head></head>や<body></body>があります。
基本的にbody内のデータを取得することが多いです。
ここからさらにみていきます。
これにはGoogleの「検証」が便利です。
先ほどお見せしたこちらです。
これを利用すれば、取得したデータにカーソルを合わせて「右クリック」→「検証」を選択すると該当するHTMLコードが表示されます。
これにアクセスするにはどうすればいいかを考えればいいわけです。
idがあればピンポイントで取得できます。
classであれは複数ある可能性があります。
こういったことに注意しながら該当するデータへアクセスする手段を考えていきます。
最初は戸惑うかもですが、すぐに慣れます。
ちなみにスクレイピングはHTMLを解析してデータを抽出するので、サイトがリニューアルなどされてHTMLが変わったらプログラムの全て書き直しになりますw
4. 取得データはCSVで保存
上記のコードを実行すると、SUUMOの物件情報を取得できます。
取得したデータをdataframeに変換したらあとはデータを保存して完成です。
データの保存にはpandasを利用します。
pandasにはdataframeフォーマットのデータをExcelやCSVに一発で変換して保存できる必殺技があるので便利です。
今回はCSVで保存します。
コマンドはこれだけです。
df.to_csv("tokyo_23words_raw_data.csv")
""内にファイル名を入れたらOKです。
csvで保存する場合には拡張子の.csvを忘れないようにしましょう。
ちなみにExcelに保存する場合はこんな感じです。
df.to_excel("tokyo_23words_raw_data.xlsx")
わかりやすいですね。
これで取得したデータはローカルに保存できたので安心です。
のちに作業を再開する際には、またスクレイピングをせずとも保存したデータを読み取ればOKです。
もちろん、日々掲載されている物件情報は変わるので、毎回取得した方が最新データを集めることができます。
(おまけ)データ分析にするにはデータの加工が必要
せっかくデータが収集できたところ水を差すようで恐縮ですが、本記事で取得したデータはそのまま分析に使うことはできません。
スクレイピングで収集したデータを分析に用いるためには、データの型変換などの前処理が必要になります。
今のままだと基本的には全て文字列になりますので、ここを整形して、分析に利用できる形に変換してあげる必要があります。
こちらの方法については、下記の記事で解説しておりますのでご参照ください。
正直、データの収集よりもこの前処理の方がだるいですw
-

【コード解説】データ分析のためにSUUMOの賃貸物件情報を整形する!【re, pandas, apply, lambda等】
続きを見る
5. Pythonはスクレイピングに最適!
こんな感じで、Pythonを使うとスクレイピングが簡単に実装することができます。
ただ、サイトによってはスクレイピングを禁止しているので注意しましょう。
モラルの範疇で行うようにしてください。
あまり調子に乗りすぎるとサーバー側からアクセスブロックされることもあるのでご注意くださいw(経験済みw)
Pythonは汎用性が高くて学びやすい
話が逸れましたが、Pythonはスクレイピングやデータ分析等を得意とするプログラミング言語です。
比較的に学びやすくてなおかつ汎用性が高いのでオススメです。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
独学も可能です
僕自身も社会人になってから独学で取得できちゃったくらい学びやすい言語です。
気がついたら仕事でもPythonを使うまでになっています。
Pythonのおかげで転職にも成功しました。
-

【決定版】Python独学ロードマップ【完全初心者OK】
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】
日常業務の効率化など様々な場面でPythonの利用シーンはあります。
知っておくとわりと便利で、職場でも重宝されます。
まとめ
いかがでしたでしょうか。
ここでは、PythonでSUUMOの物件情報をスクレイピングするためのコードの解説をしました。
少しでもお役に立てれば嬉しいです。
ここで紹介しているコードはあくまでも僕が趣味的にババっと書いたものなので、もっと良い書き方もたくさんあります。
僕のコードを参考にしつつ、適宜いい感じに進化させていただければと思います。
パクる分には全然オッケーです。
ここまで読んでくださってありがとうございました!



{kind=link}