
こんにちは。TATです。
前回に引き続き、Pythonのコード解説記事です。
前回は、PythonでSUUMOの賃貸物件情報をスクレイピングするためのコード解説を行いました。
-

【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
今回は収集したデータを整形する方法について解説していきます。
ほとんどの場合、収集したデータをそのままデータ分析に利用することはできません。
データ分析ができるように、データをきれいにする作業が必要になります。
そしてここが一番めんどくさかったりします。
ここできちんと使えるデータに整えることが、データ分析や機械学習モデルを作る前の大事な作業になります。
Pythonを使うと、データの整形もとてもシンプルに実行することができるので、実際に僕が書いたコードを紹介しながら解説していこうと思います。
目次
【コード解説】データ分析のためにSUUMOの賃貸物件情報を整形する!【re, pandas, apply, lambda等】

1. SUUMOから収集したデータを確認
PythonでSUUMOをスクレイピング
まずはSUUMOから収集したデータを確認していきましょう。
データ収集にはPythonでスクレイピングを利用しました。
こちらのコードについては前回の記事で解説しています。
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
データを見ると汚いデータのオンパレードw
収集したデータがこちらです。汚いですw
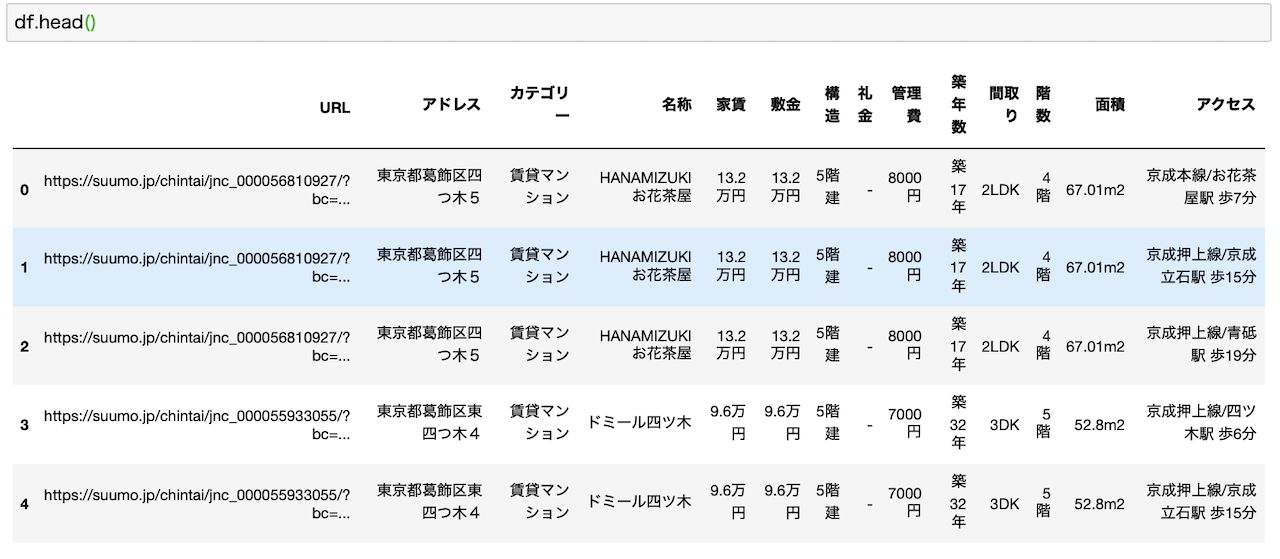
こちらは「【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!」で用いた画像を再利用してます。
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
このデータをよく見ると、家賃とか敷金データに単位(万円)がついてるため、このままでは数値データとして扱うことができません。
管理費とか面積も同様です。
そしてアクセスについては、路線、最寄駅、徒歩○分という3つの情報がごっちゃになっています。
データ分析をするにはこれらは分けられていたほうが便利です。
また、重複データもチェックする必要があります。
データは列で細かく分けたほうが分析しやすい
データ分析を行う際には、なるべく列を細かく分けておいたほうが後々便利になります。
Excelとかで扱う場合には、列が多すぎると煩雑になりますが、Pythonでやる分には扱うコマンドは同じなので問題ありません。
上記の例でいうところの「アクセス」です。
ここは、路線、最寄駅、徒歩○分の3列に分けたほうが、後から路線ごとに集計したり、徒歩7分以内みたいな絞り込みを行うことができますよね。
こうしたデータ整形後の分析をイメージしながら整形していくと良いです。
分析の目的は事前にはっきりさせておくべし
さらに、実際にどういった分析をしたいのか、あらかじめ目的をしっかり設定しておくことが重要です。
目的がはっきりしていると、どういったデータが必要なのかが明確になります。
仮に、その目的に必要としない場合には、無理にデータを整形して列を増やす必要がありません。
このあたりは、性格にもよるかもですが、僕の場合は目的を設定して、それに必要なことをあぶり出して一番エネルギーを使わない効率的な方法を探します。
仮に今回の目的が、「路線と間取りごとの平均家賃を見たい」のようにピンポイントのものでしたら、面積を数値データに変換するみたいな作業は必要なくなります。
無駄な作業は極力しないように、あらかじめ目的を明確にしてからデータ分析を始めるようにしましょう。
むしろ、ここがはっきりしていないと、どこまでやればいいのかがわからないので、結果として無駄な作業をしてしまいがちです。
趣味とかならいいかもですが、仕事となると時間は限られるので、なおさらここは重要な考えです。
2. 実際に行ったデータ整形作業をおさらい
次に、実際に記事の中で行ったデータ整形作業を改めてご紹介しておきます。
上記のデータの状況を踏まえて、データ整形のためにしたことはこちらの通りです。
- 「家賃」「管理費」「敷金」「礼金」「面積」「築年数」を数値データへ変換(さらに「管理費」は単位を万円へ変換)
- 「アクセス」から「沿線」「駅」「徒歩」を抽出(さらに「徒歩」は数値データに変換)
- 「アドレス」から「区」を抽出
- 「アクセス」が駅でないデータ(バスとか)は除外
- 徒歩圏内でないでデータ(車で3分とか)は除外
- "URL", "アクセス"をキーにして重複データを除外
- ["アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"]が一致する行を除外
こちらは過去の記事で紹介しているものを同じです。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
最後の1行はこちらの記事で機械学習モデルを作る際に追加した作業になります。
これを追加するとさらに重複データを排除できるので実行しました。
-

【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!
3. 順番にPythonコードを解説
それでは、順番にコードを解説していきます。
ここからがメインです。
今回は、上記で紹介したそれぞれのデータ整形作業ごとに分けてコードを解説していきます。
必要なライブラリーの確認
まずは、今回利用するライブラリーの解説です。
こちらです。今回は2つだけです。
- pandas
- re
pandas
1つ目はpandasですね。
これはdataframeを扱うために使います。
dataframeを使うと、Excelで行うような計算が一瞬でできるようになります。
データ分析では必須のライブラリーです。
行や列単位でデータを処理するにもとても便利なので重宝します。
データ分析を行うためにPythonを学んでいる方は、基礎的な文法を習得後は、こちらのpandasについて学ぶと良いです!
re
次が、reというライブラリーです。
これはPythonで正規表現を用いるために利用します。
reは正規表現(regular expression)を頭文字を取ったものです。
これで、テキストデータの中から、特定のパターンにマッチングするデータを効率的に抽出することができるようになります。
今回り要するライブラリーは以上です。
シンプルですね。
pandasでCSVファイルを読み込む
それではここからコードの解説に入っていきます。
まずは収集したデータの読み込みです。
前回の記事で、収集したデータをpandasを利用してCSVファイルとして保存しました。
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
今回は、ここで保存したデータを読み取ることから始めます。
CSVやExcelデータの読み込みには、pandasが便利で1行で完了します。
import pandas as pd df = pd.read_csv(“tokyo_23words_raw_data.csv”)
シンプルですよね。
Excelファイルを読み込む場合は、pd.read_excel("ファイル名")とすればOKです。
これでCSVやExcelファイルをdataframeに一発で変換することができます。
楽勝ですね。
一応、データを読み込んだ後は確認をするようにしましょう。
df.head()を使うと、最初の10行だけを確認できます。
その他、データの概要を確認するには、describe()やinfo()が便利です。
それでは、ここから読み込んだデータを整形していきます。
「家賃」「管理費」「敷金」「礼金」「面積」「築年数」を数値データへ変換(さらに「管理費」は単位を万円へ変換)
まずはコードを紹介
まずは数値データへの変換です。
変換するべき列は「家賃」、「管理費」、「敷金」、「礼金」、「面積」、「築年数」です。
管理費については単位を統一するために「万円」に変換します。
こちらがコードです。
import re
def get_number(value):
n = re.findall(r"[0-9.]+", value)
if len(n)!=0:
return float(n[0])
else:
return 0
df["家賃"] = df["家賃"].apply(get_number)
df["管理費"] = df["管理費"].apply(get_number)
df["管理費"] = df["管理費"] / 10000
df["敷金"] = df["敷金"].apply(get_number)
df["礼金"] = df["礼金"].apply(get_number)
df["面積"] = df["面積"].apply(get_number)
df["築年数"] = df["築年数"].apply(get_number)
ここでreを使います。
人によって色々なやり方があるかと思いますが、僕の場合は数値データに変換できる関数を一個作って、そこに各列をapply関数を使ってぶっこんでいきました。
管理費だけは、単位を「円」から「万円」に変換するために、10,000で割っています。
簡単に解説します
ここでやっていることを簡単に解説しておくと、get_number関数で、まずはテキストデータから数値データを抽出します。
reで小数点を含むデータを抽出して、一致するデータがある場合はその数値をfloatに変換して返します。
一致するデータがない場合は0として返します。
データがない場合は、管理費が「-」となっていたり、築年数が「新築」となっているなどのパターンがありました。
apply関数で列単位で処理
関数を作ったら、あとは列ごとに計算していくだけです。
ここにはapply関数を利用します。
これは、dataframeで列ごとの処理を可能にしてくれる便利な関数です。
df["家賃"].apply(get_number)
こんな感じで列を指定して、apply(関数名)と呼ぶと、該当列の各値が関数に投げられます。
for文とかで一個ずつ計算する必要がないので、コードもとてもスッキリして便利です。
ちなみにapply関数は並列処理をするので、一般的にはfor文で一個ずつ計算するよりも高速になります。
無事に数値データに変換
そしてのこれらのコードを実行すると、各列のデータは数値に変換されます。
こんな感じです。
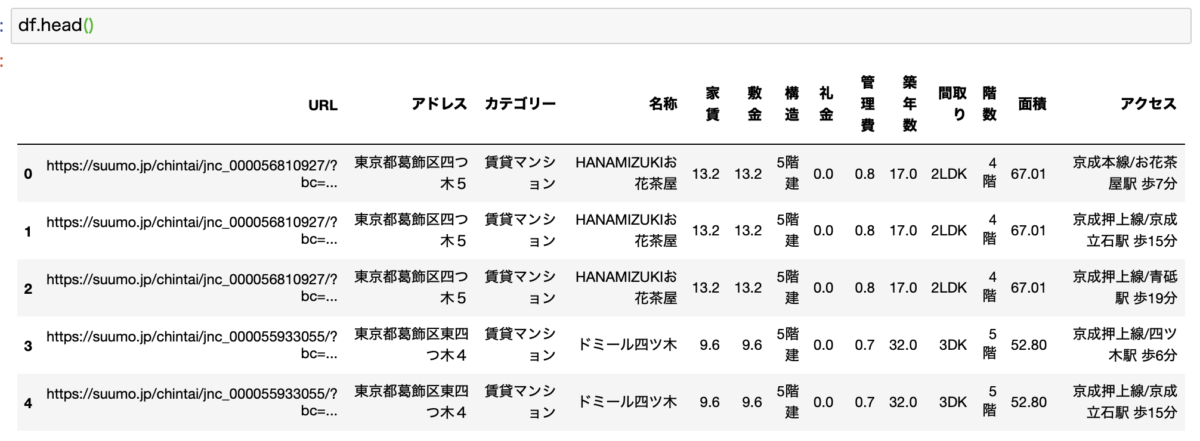
いい感じに数値データに変換されていることがわかります。
「アクセス」カラムを整形する
次に「アクセス」カラムを見ていきます。
ここでは次の3つの作業をまとめて行います。
- 「アクセス」から「沿線」「駅」「徒歩」を抽出(さらに「徒歩」は数値データに変換)
- 「アクセス」が駅でないデータ(バスとか)は除外
- 徒歩圏内でないでデータ(車で3分とか)は除外
まずはコード紹介
次の作業は、「アクセス」列から「沿線」「駅」「徒歩」を抽出します。
さらに徒歩圏内にない物件(自動車で○分など)は排除します。
それではコードを解説します。ちょっと見にくかったのでコメント増やしました。
# アクセスがNullの行を排除
df = df[df["アクセス"].isnull()==False]
# 沿線を抽出
df["沿線"] = df["アクセス"].apply(lambda x: x.split("/")[0])
# 沿線に線が入ってる行のみを抽出 *バスとかを排除
df = df[df["沿線"].str.contains("線")]
# アクセスから駅を抽出
df["駅"] = df["アクセス"].apply(lambda x: x.split(" ")[0].split("/")[1])
# 徒歩圏内でない物件を排除
df = df[df["アクセス"].str.contains("歩")]
# アクセスから徒歩を抽出
df["徒歩"] = df["アクセス"].apply(lambda x: int(re.findall(r"[0-9]+", x.split(" ")[1])[0]))
コード解説
順番に見ていきます。
やってることはどれも似ています。
いらない行の排除→データの抽出の繰り返しです。
コメントをつけたのでどこで何をやっているのかおわかりいただけるかと思います。
ここではlambda関数について簡単に解説しておきます。
lambda関数は無名関数と言われていて、定義することなく関数を書くことができます。
よくわからないですよねw
先ほどでは、get_numberという関数を記述しました。
これは各行で使いまわしたいためです。
今回の場合は各行に対して一回しか使わない関数なので、いちいち関数として定義する必要がありません。(定義しても問題にはなりませんがw)
この場合はlambda関数が便利で、xを引数に定義して、:に続いて処理を記します。
よって、例としてこちらのコードは同じことをしています。
"""
lambda関数を使う場合
"""
df["沿線"] = df["アクセス"].apply(lambda x: x.split("/")[0])
"""
lambda関数を使わない場合
"""
def get_line(x):
return x.split("/")[0]
df["沿線"] = df["アクセス"].apply(get_line)
Python特有の書き方なので、最初は慣れないかもしれません。
その間はlambdaを使わないで書いてもOKです。
それでも一目瞭然ですが、lambda関数を使うとコードがとてもスッキリするので、慣れたらこっちを使ったほうが便利です。
僕の場合はできる限りlambda関数を使います。
きれいにデータが抽出されました!
こちらのコードを実行すると、アクセスとアドレスから必要なデータを別カラムに抽出することができます。
こんな感じです。
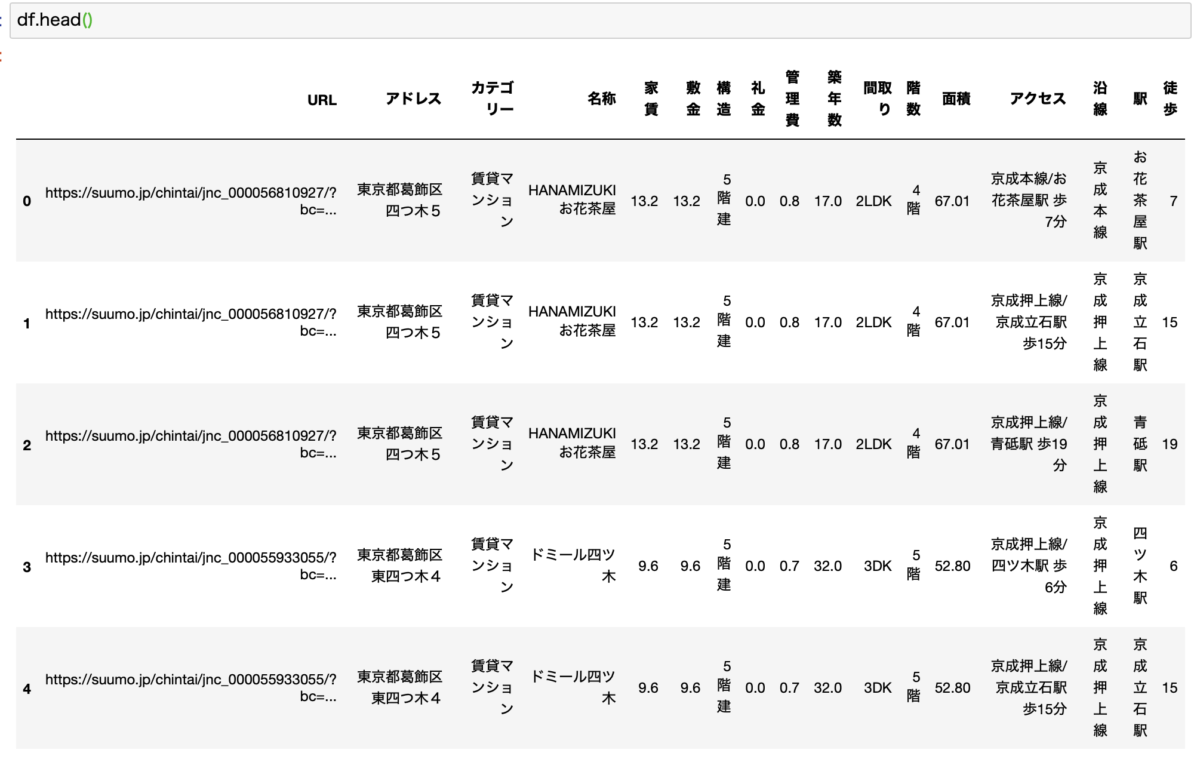
「沿線」「駅」「徒歩」のカラムが追加されました!
「アドレス」から「区」を抽出
まずはコード紹介
次の作業は「アドレス」カラムから「区」を抽出します。
各行のアドレスを見ると、東京都〇〇区XXXXXみたいなフォーマットになっていることがわかります。
正規表現を使って、〇〇区の部分を抽出します。
このデータを使うことで、区ごとでデータを集計することができるようになります。
こちらが使用したコードです。1行のみでシンプルです。
df["区"] = df["アドレス"].apply(lambda x: re.findall(r"東京都(.*区)", x)[0])
reを使って、正規表現で〇〇区を抽出し、「区」というカラムにぶっこんでいます。
「区」カラムが完成!
これで「区」カラムが完成します。
こんな感じです。これで必要なカラムで見るとデータ整形は完了です。

重複データを除外
最後の作業が、重複データの排除になります。
こちらの2つが該当します。
- "URL", "アクセス"をキーにして重複データを除外
- ["アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"]が一致する行を除外
コード紹介
まずはコードを見てみましょう。
重複の除外にはdrop_duplicates()という名前の通りの関数を使います。
このあたりのデータ整形もPythonであれば1行でできるので便利です。
# "URL", "アクセス"をキーに重複データを削除 df.drop_duplicates(subset=["URL", "アクセス"], inplace=True) # "アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"をキーに重複データを削除 df.drop_duplicates(subset=["アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"], inplace=True)
コード解説
ここではdrop_duplicatesという関数を2回使っています。
これは重複を取り除くために使われるもので、名前の通りですねw
subsetにカラムを指定して、それらが全て一致している場合には重複データとして排除されます。
1回目は"URL"と"アクセス"だけをみて、重複してたら問答無用で削除です。
URLだけで見ると、同じ物件でもアクセスが異なる物件(徒歩圏内の駅が複数ある場合)では、1駅だけを残してその他は排除することになってしまうので、アクセスもキーに加えます。
2回目は、アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"をキーとして、これらが全て一致した場合に重複データと判断して除外します。
この作業をすることで、おおよその重複データを一気に取り除くことができます。
そしてinplaceという引数にも触れておきます。
これは英語のままですが、データの置き換えをするかどうかを指定するものになります。
Trueだったら、新しいデータとして書き換えを行い、Flaseの場合はデータを表示するだけでデータそのものは変更しません。
よって、Flaseの場合は、drop_duplicatesで重複データを削除して表示されても、再びdfを表示すると重複データは残ったままになります。
デフォルトではFalseになっているので、置き換えたい場合は必ずTrueに設定するようにします。
ちなみにこの2つの書き方では結果は同じになります。
# inplace を使う df.drop_duplicates(subset=["URL"], inplace=True) # inplaceを使わない df = df.drop_duplicates(subset=["URL"])
どっちでも構いませんが、なるべくコードはスッキリさせた方が見やすいので、inplaceを使った方がスッキリします。
データ整形が完了!
以上の作業でデータ整形の作業が全て終了です。
データの型変換、カラム追加、重複削除など、データの整形では基本的な作業ばかりです。
今回はこれだけですが、これでも重複データはあります。
どこまでやるかは作業をする人と、最終的な結果で求められる精度とかで決まってくる感じです。
一応、完成品がこちらです。
こちらのデータを使って、集計データを可視化したり、機械学習モデルを使って家賃予測をしたものが過去の記事になります。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
-
【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!
4. データ分析にはPythonが最高です
ここで紹介してきたコードは全てPythonで書かれています。
Pythonは、シンプルでスッキリとしたコードが書けて、なおかつ汎用性がとても高い言語です。
本記事を読んでいただくとお分かり頂けると思いますが、いろいろな作業を行なったわりには、プログラムとしての量はかなり少ないですよね。
特に今回紹介したデータ分析や、さらにはAI関連の分野を得意とするので、昨今のデータサイエンスやAIブームで人気急上昇中のプログラミング言語です。
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
他言語に比べても比較的学びやすいので、初心者でもとっつきやすい言語です。
僕自身も社会人になってから独学で習得して、さらに転職にも成功して今では仕事でもバリバリPythonを使っています。
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】
-

【副業は神です】2度の転職において副業が内定の決め手になったお話。
実際に僕自身が社会人になってから独学して、そこそこ使えるレベルになっているので、いつから学び始めても遅すぎることはありません!
-

【迷っている方へ!】プログラミングに興味を持ったらとりあえずやってみよう!
まとめ
いかがでしたでしょうか。
今回は、Pythonのスクレイピングで収集したSUUMOの賃貸物件情報を分析するための下準備として、データ整形するためのPythonコードを解説しました。
やっぱりPythonは短いコードで高度な処理ができてしまうので便利ですね。
ここで整形したデータは、集計して可視化したり、機械学習モデルを作って家賃予測をしたりするために使いました。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
-
【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!
ここまできたら可視化のコード解説とかも行いたいですね。
とりあえず今回はかなり長くなってしまったのでここまでにしておきます。
ここまで読んでくださってありがとうございました!
ちなみにここで紹介しているコードは、僕が趣味で書いているだけで決して完璧なものではないので、どんどんパクりつつ改良していっちゃってください!
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
-
【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
-
【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-
プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】
-
【副業は神です】2度の転職において副業が内定の決め手になったお話。
-
【迷っている方へ!】プログラミングに興味を持ったらとりあえずやってみよう!




{kind=link}