

こんにちは。TATです。
今日のテーマは「食べログとGoogleのレビューデータの比較」です。
結構なグレーゾーンを攻めている感じがしますが気にせずいきますw
先日の記事で、食べログのデータを収集してベストレストランを探してみました。
-

【Pythonでデータ分析】食べログのデータを収集して東京23区で最高のレストランを探す
続きを見る
東京23区にある、様々な最強レストランを探しだしました。
これはこれで面白い企画になったのですが、少し気になる点があります。
それが食べログのレビューの信ぴょう性です。
いつしか、食べログのレビューや口コミに関するいわゆる「やらせ」がピックアップされたことがありました。
お金を払っていいレビューを書いてもらうみたいなことが発生してレビューを操作しようとしていた疑惑です。
興味のある方は「食べログ やらせ」などでググってみてください。
今回はそこまで大掛かりなことはしませんが、少しここに首を突っ込んでみます。
シンプルにGoogleのレビューデータと比較してみようと思います。
どんな違いがあるのかをみていきます。
【禁断の比較】食べログとGoogleのレビューデータを比較する【Pythonでデータ分析】

(おさらい)食べログデータの確認
まずはデータの確認です。
前の記事で収集したデータを確認します。
収集対象としたのは東京23区にあるレストランで、最終的な結果は、99,887件になりました。
データを収集したのは2021年9月21日です。

収集方法については前の記事で解説しているのでそちらをご参照ください。
-
【Pythonでデータ分析】食べログのデータを収集して東京23区で最高のレストランを探す
続きを見る
レビューのヒストグラムは少しいびつ
収集したデータのレビューのヒストグラムを見てみると、少しいびつな形をしていることがわかります。
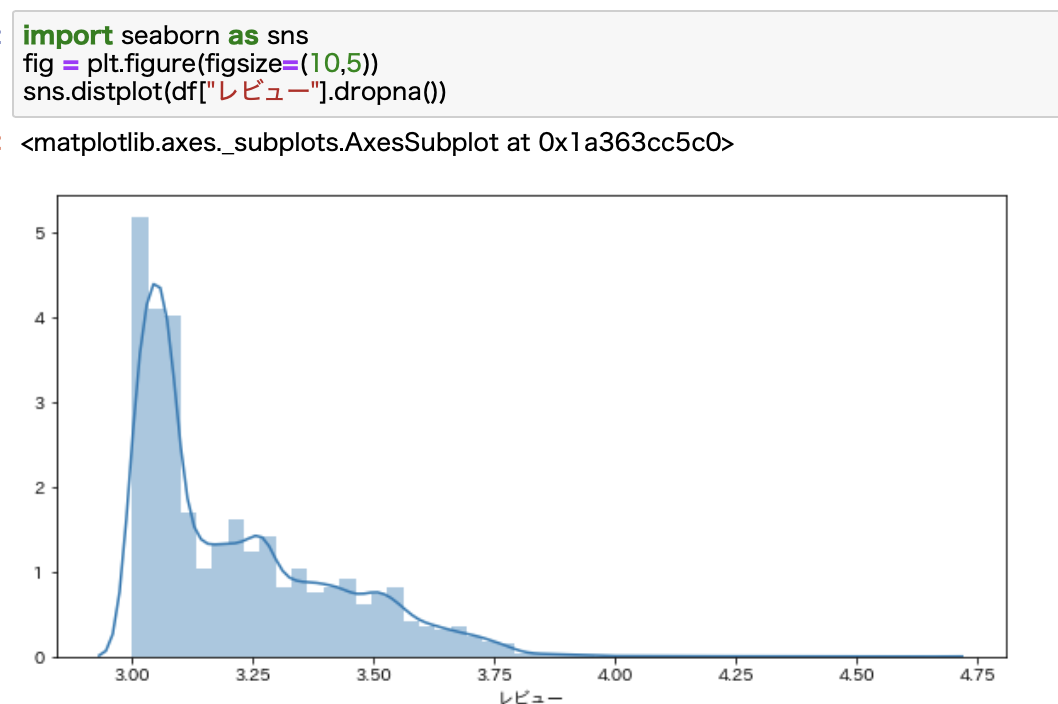
こういったデータは基本的には正規分布になる場合が多いですが、食べログのデータの場合は少し変な形をしています。
3.25くらいでデータが増えているのが気になるところです。
Googleのレビューではどうなるのかを比較していきます。
Googleのデータを収集する
食べログのデータの確認が終わったところで、本題のGoogleデータを見ていきます。
APIを活用する
Googleからレストランのレビューデータを取得するにはAPIを利用する必要があります。
スクレイピングは不可能です。すぐにBot判定されてお陀仏になります。
Googleには色々なAPIが用意されていて、誰でもお金さえ払えばデータを取得することができます。
今回必要となるレストランデータについては、Google Place APIを使います。
→ Google Place API(英語ページへ飛びます)
このAPIを使えば、レストランの検索やレストランの詳細情報の取得をAPI経由で行うことができます。
レビューデータはもちろん、開店時間や口コミ、住所や電話番号、さらに写真などを取得することも可能です。
基本的にGoogleのレストランページにある情報は、APIを通して全て取れると思っていただいて問題ありません。
レストランを検索→レストラン情報の取得
次に今回やるべき作業の流れをご紹介しておきます。
Googleからレストラン情報を取得するためには、各レストランに割り振られたIDを指定する必要があります。
よって、まずはこのIDを取得する作業から開始します。
レストラン名から候補となるIDを検索して取得し、それらIDの詳細情報を取得すればOKです。
これを各レストランで繰り返し行います。
ちなみにレストランの検索方法はいろいろあって、名前検索も可能ですし、緯度経度から半径〇〇km以内みたいな探し方もできます。
お金払いたくないので1,000件に絞ります
ここで一つの欠点というか当然のことなのですが、GoogleのAPIは有料です。
無料のものもありますが、今回使うPlace APIは有料になります。
有料とは言っても、毎月200ドル分は無料で利用することができるので、今回はこの無料枠に収まるようにデータを絞って取得することにします。
全部取得すると確実に課金対象となるので、今回は1,000件のレストランに絞ってデータを取得します。
ちなみに全部で約10万件(正確には99,887件)のレストランがあるのに、1,000件ぽっちのデータで信ぴょう性はあるんですかと思った方、鋭いです。
結論、大丈夫です。
これには少し統計学の知識が必要です。
すごくざっくりご説明すると、統計学を使うと、全体のデータ数からいくつのサンプルデータを取得すれば誤差がどれくらいの範囲内に収まるかを計算することができます。
誤差をゼロにするなら全データを調査する必要がありますが、多少の誤差を許容すれば全データを対象とする必要はありません。
そして、こういった場面でよく出てくるのが許容誤差を5%以内に収めるといったものです。
「まあ5%以内の誤差であれば見逃してやってもいいだろう」といったニュアンスですね。
「5%なんてけしからん」という方は3%とか1%とか、もっと厳しい値を設定してもOKです。
ただ、一般的には5%がよく使われるので、ここでも5%を使います。
統計学については別記事で解説してもいいかもですね。
ここでは細かい説明は抜きにして、母集団を10万件、許容誤差を5%、信頼度を95%、回答比率0.5とすると、必要なサンプルデータは383と計算することができます。
つまり、383件以上のデータで検証すればそれなりの信ぴょう性のある結果が得られるということになります。
ここでいう1,000件を取得すれば十分な信ぴょう性を持つ結果が得られると言えます。
1,000件は無作為抽出
サンプル対象とする1,000件についてはランダムで無作為抽出します。
これにはPythonのrandomというライブラリを使うと便利です。名前の通りですね。
randomのchoicesを使うと、リスト形式のデータの中から指定した数のデータを無作為抽出することができます。
ここでは全データのindexをリスト化して、そこから1,000件選びました。
選ばれしデータをdfに格納します。
これで準備OKです。
選ばれたレストランを1つずつGoogle APIで検索して詳細情報を取得していきます。
取得データの確認
GoogleのAPIを通じて取得したデータがこちらです。
必要なデータだけに絞ってまとめました。

こんな感じできちんとデータが取得できていることがわかります。
ちなみに取得できたデータは全部で1,053個です。
「なんで1,000を超えるんだ?」と思いますよね。
これはレストラン名で検索した際に候補となるレストランが複数出てくることがあるためです。
この場合、どちらかが目的のレストランでどちらかが似たような名前の別物であることが考えられます。
あるいはどっちも違っていることもありますw
よって、ここから分析を行う前に、食べログのデータとGoogleのデータが同じレストランを指しているのかを確認する必要があります。
誤ったデータが入ってると結果がおかしくなってしまうので、あらかじめ排除しておく必要があります。
地獄の確認作業
確認するにはいくつかの方法があります。
ここでは、双方にあるデータとしてレストラン名と住所を使ってデータが一致しているかを確認します。
ここで一致しない場合は違うレストランを指している可能性もあるので排除します。
電話番号とかもあるとさらに確認作業の幅が広がりましたね。。。後悔ですw
さて、この作業を行うためにいくつかの工夫を行いました。
ポイント
- 大文字小文字を全て小文字に統一
- 全角半角は全て半角に統一
- Googleの住所は丁目を-に変換する
- 住所はビル名などを除き、番地までで確認する
上記の工夫をすることで精度が上がります。
Googleでは住所の番地は全角ですが、食べログでは半角です。
このままでは一致せずに別レストランを区別してしまうことになりますが、全角半角を統一することができれば一致できます。
店名か住所が一致したら同一レストランと判断します。
それぞれ、formatted_addressとformatted_nameというカラムを作りました。

これらが一致するデータをチェックしていきます。
一致するデータは半分以下になりました・・・
データ照合の結果、同一レストランを指していると判定できたレストランは合計で409件となりました。。。

まさかの半分未満。。。
残念ですが、こればかりは仕方ありません。
あとは電話番号とかのデータも取得していればさらに一致させることができたかもしれませんね。
半分未満とはいえ、先ほど算出した条件の383件はキープできているので、そこそこ信ぴょう性のある結果は出せるのではないかと思っています。
1,000個分取っておいて助かりましたw
データの検証
ようやくデータの準備が整ったので、食べログとGoogleのデータを比較していこうと思います。
ようやく本題ですw
ヒストグラムで比較
まずはそれぞれのレビューをヒストグラムで比較してみましょう。
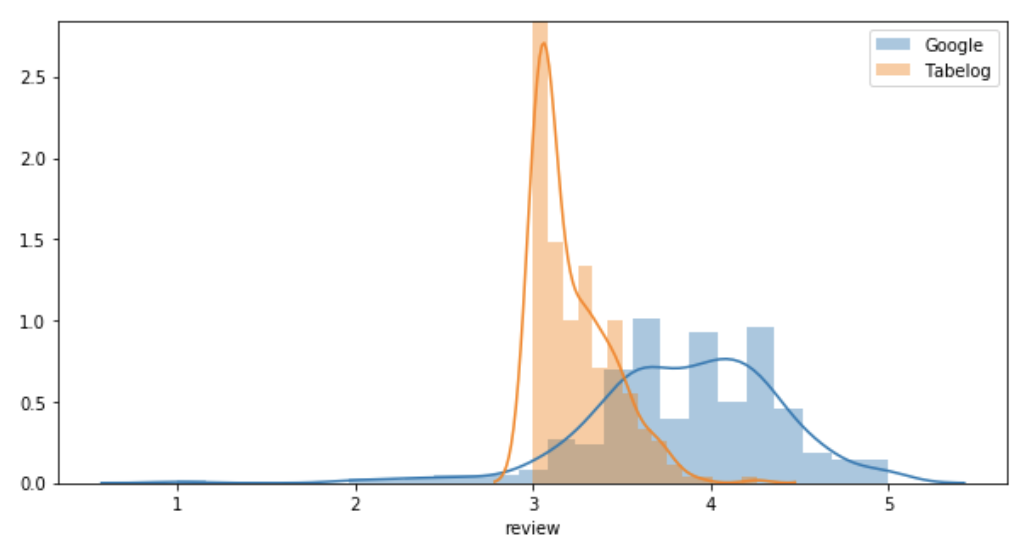
データ数が少なく、Googleのレビューも正規分布までとはいきませんが、3.8あたりをピークとして左右対称のヒストグラムとなっています。
また、食べログデータと比較すると、全体的にGoogleのレビューの方が高いことがわかります。
差分を可視化する
Googleのレビューの方が高い傾向にあることがわかったので、次に差分を可視化してみます。
Googleのレビューから食べログのレビューを引いて、結果をdiffというカラムに入れます。
これをヒストグラムで可視化してみます。
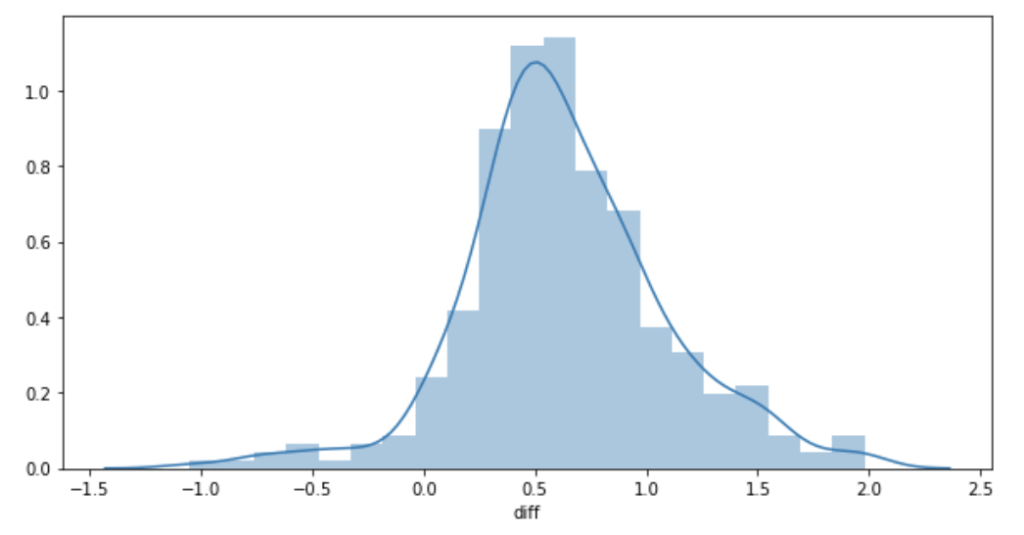
こちらはきれいな正規分布になりました。
0.5あたりが中央値となっていることが確認できます。
describe関数で中央値や平均値などを計算してみました。

平均値で0.63、中央値は0.57であることがわかります。
ざっくりGoogleの方が0.6点くらい点数が高いことがわかりますね。
食べログで点数がない場合は、Googleの点数から0.6くらい引いた数値がざっくりとした目安となりそうです。
また、基本的にGoogleの方が食べログよりも点数が低いというケースはほとんどありません。
該当したのは、全409件中15件のみでした。
食べログとGoogleのレビューを散布図で可視化する
次に、食べログとGoogleのデータを散布図で見てみます。
こうすると少し見え方が違ってきます。
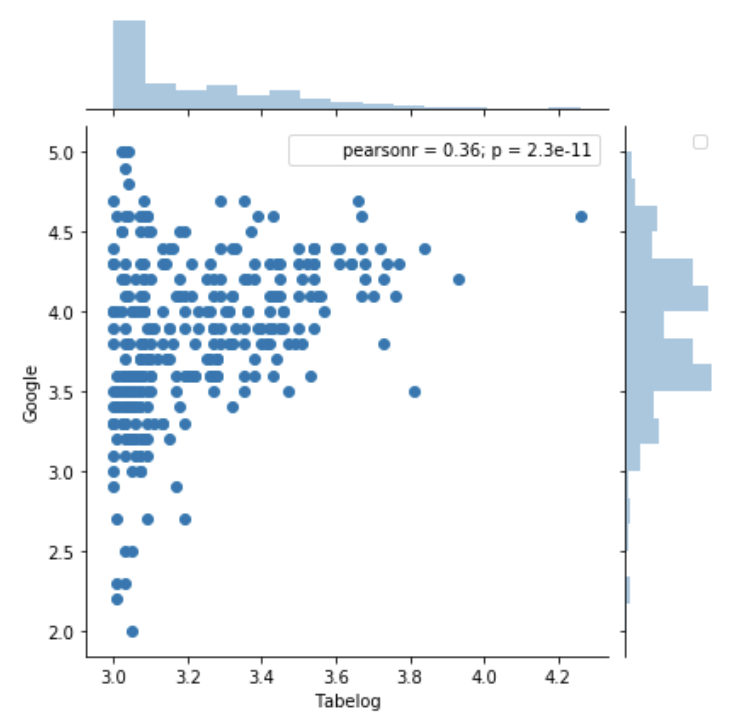
パッとみた印象はどんな感じでしょうか。
僕の個人的な感想としては、「右下がスカスカやないかい!!!」といった印象ですw
右下とは、つまり「食べログの点数は高いけどGoogleの点数が低い」エリアになります。
こういったレストランはないということですね。
ここの該当するものがあれば、ワンチャン食べログに献金して点数あげてんじゃねと思いましたが、そういう都合のいいデータはありませんでしたw
そして左下のレストラン。これはどちらも点数も低い、つまりはあまりおいしくないレストランである可能性があります。
名誉のため、店名を出すのは控えますw
右上にあるのが文句なしの最高のレストランであることがわかります。
どっちも評価も高いですからね。
ちなみに一番右上にポツンと1件だけ鎮座しているのが、「USHIGORO S. NISHIAZABU」というお店でした
焼肉屋です。いつかいってみたい。。。
左上にある食べログでは低いけどGoogleは高いレストランはどういう位置付けなんですかね。
食べログにそこまで力を入れていないということなのでしょうか。
以上で、分析はおしまいです。
その他、口コミ数や価格帯なども考慮に入れたらもっと詳しい分析ができるかと思います。
今回は、長くなりそうなので、そこまで突っ込んだ分析はしないこととします。
まとめ
いかがでしたでしょうか。
ここでは、「食べログとGoogleのレビューデータの比較」というテーマで簡単な分析結果をご紹介しました。
かつて、話題になった食べログのやらせ疑惑に迫ろうとしましたが、確固たる証拠を見つけられるには至りませんでした。
そもそも疑惑に過ぎないので、もともとそんなことはしていなかったかもしれませんし、今はレビューの計算方法が変わっている可能性もありますから。
真実は闇の中です。
3点未満の点数が公開されない仕様になっていたので、ここも公開すると意外ときれいな正規分布になったりするのかなと思ったりもしました。
いずれにしても、こういったデータ分析は楽しいですね。
ふと疑問に感じたことをデータに基づいて検証していく作業には非常に面白いです。
今後もこういった記事は増やしていこうと思います。
なんかリクエストとかありましたらTwitterやお問い合わせページからご連絡ください。
ここまで読んでくださり、ありがとうございました。




{kind=link}