

こんにちは。TATです。
今日のテーマは「【Pythonコード解説】Seleniumで国会会議録検索システムをスクレイピングしてみる」です。
国会会議録検索システムでは、国会の議事録が公開されており、ここから過去の発言内容を確認することができます。
これは意外と知らない人が多いのではないでしょうか。
ここには発言した内容が一言一句まで記されています。国会議員は迂闊なことを言ったら一生ここに残ることになります。
ここからデータを収集すれば特定の人物の発言内容を集めたり、さらに肩書き別や所属会派ごとにデータを検索できたりもします。
以前に安倍首相の国会発言を収集してワードクラウドを作ったことがありましたが、このデータは国会会議録検索システムから収集しています。
-

【Pythonでデータ分析】安倍首相の国会発言を集めてワードクラウドにしてみた!
続きを見る
本記事では、この国会議事録データをSeleniumを使って収集する方法を解説します。
目次
【Pythonコード解説】Seleniumで国会会議録検索システムをスクレイピングしてみる

国会会議録検索システムのサイト構造を確認する
まずはスクレイピングを始まる前の下調べです。
今回のデータ収集の対象サイトとなる国会会議録検索システムのサイト構造について少しみておきます。
トップページを確認する
トップページを見ると、このように検索条件を設定できるページが確認できます。
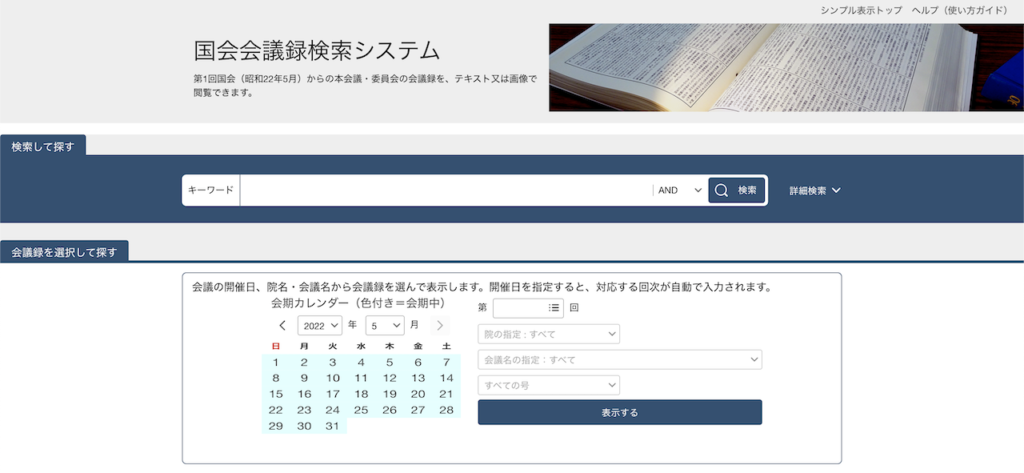
さらに検索ボタンの右にある「詳細検索」をクリックするとさらに細かい条件指定ができるようになります。
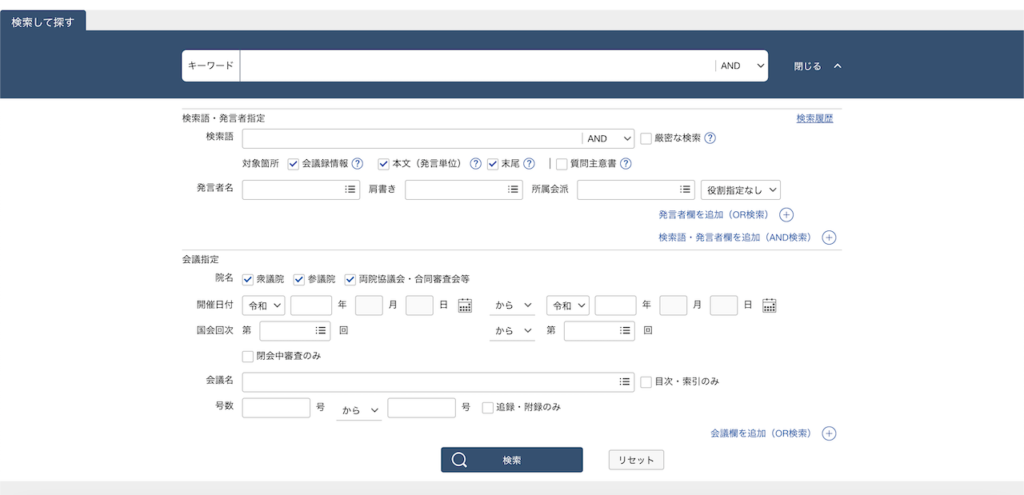
各検索条件にはIDがついている
そして、ここがSeleniumでスクレイピングする際のポイントになってくるところになりますが、それぞれの条件指定用のボックスのソースコードを確認すると、IDが振られていることが確認できます。
例えば、発言者名の入力箇所にはspnmというIDがあります。
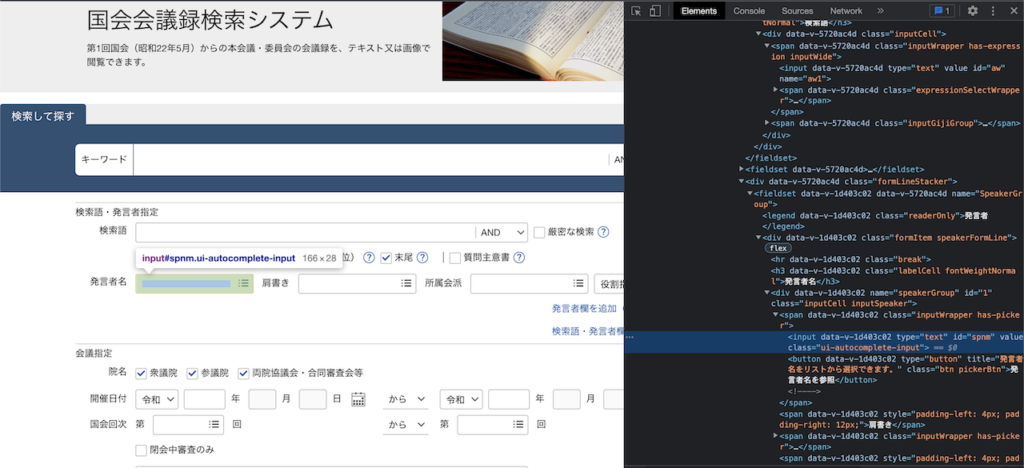
このIDを指定してあげれば、Seleniumを介して任意の箇所に任意の文字を入力することができるようになります。
条件を指定して、最後に「検索」ボタンをクリックすれば、結果を得ることができます。
検索結果ページを確認する
条件を指定した上で、検索結果ページを確認してみます。
例として、発言者名を岸田文雄に指定して検索をかけてみます。
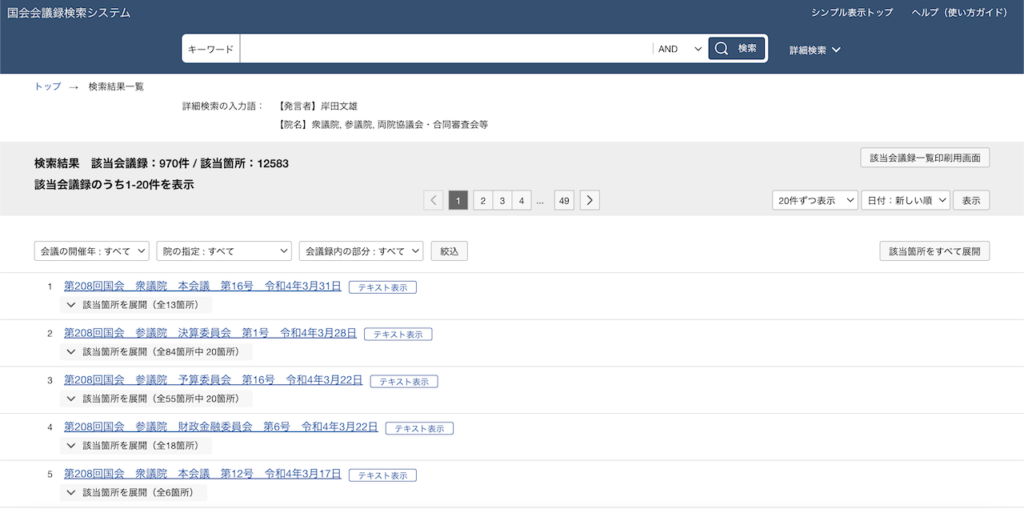
ちなみに検索結果のURLはどんな条件にしても「https://kokkai.ndl.go.jp/#/result」になります。
これではrequestsで取得するのが難しい(できなくはないです)ので、今回はSeleniumを使ってデータを収集してみることにしました。
検索結果ページから分かることとしては、まずは結果の概要ですね。
該当会議録が970件、該当箇所が12,583個あることが確認できます。
さらに表示件数を変更したり、データを並び替えすることも可能になっています。
概要の下には条件に一致する会議一覧が表示されています。
各データをクリックすれば議事録を見ることができます。
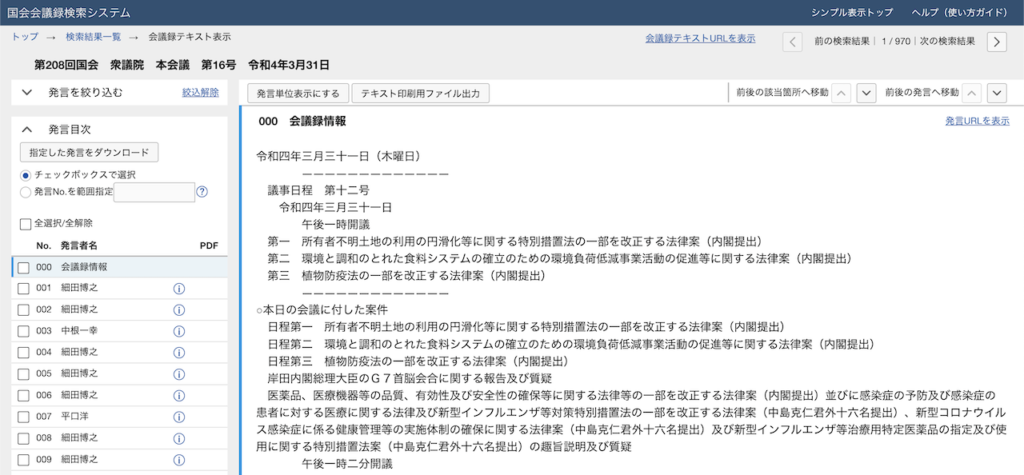
この発言内容を収集すればOKですね。
さらに後からデータをいろいろ分析するにあたって、会議名や日付なんかのデータも収集しておくと便利そうです。
ちなみに上記のスクショの右上ら辺にある「会議録テキストURLを表示」とクリックすると該当会議のリンクが取得できます。
今回の場合はこちらのリンクです。
https://kokkai.ndl.go.jp/txt/120805254X01620220331
これをクリックすると直接会議録のページへ飛ぶことができます。
とりあえずここまでのサイト構造を把握することができればスクレイピングができそうです。
Seleniumによるスクレイピング実装
サイトの確認が完了したので、ここからはSeleniumを使ってスクレイピングを行なっていきます。
作業としては次の通りです。
色々なやり方がありますので、あくまで一例です。
スクレイピングの流れ
- Seleniumの起動 + 「国会会議録検索システム」へ遷移
- 検索条件入力 + 検索をクリック
- 結果から各会議の日付、名前、URL等を取得
- 各URLから発言内容を収集
それでは順番にやっていきます。
-
PythonでSeleniumを利用する方法!セットアップの流れを徹底解説します!
続きを見る
Seleniumの起動 + 「国会会議録検索システム」へ遷移
まずはSeleniumを起動して、「国会会議録検索システム」のページへと遷移します。
from selenium import webdriver # SeleniumでChromeを起動 driver = webdriver.Chrome() # 国会会議録検索システムへ遷移 url = "https://kokkai.ndl.go.jp/#/" driver.get(url)
これでChromeを起動して、国会会議録検索システムへ遷移できます。
無事に遷移できました。
Seleniumで起動すると、上部に「Chromeは自動テストソフトウェアによって制御されています」と表示されます。
邪魔なら消しちゃってOKです。
検索条件入力 + 検索をクリック
次に検索条件を入力していきます。
ここでは例として、発言者名に現首相の「岸田文雄」、肩書きに「内閣総理大臣」と入力して検索してみます。
from time import sleep
# 検索詳細を表示する
driver.find_element_by_class_name('searchModeSwitch').click()
driver.implicitly_wait(10)
# 条件入力
driver.find_element_by_id("spnm").send_keys("岸田文雄") #発言者名
driver.find_element_by_id("sopt").send_keys("内閣総理大臣") #肩書き
driver.implicitly_wait(10)
# 検索をクリック
sleep(3)
driver.find_element_by_id("asbSearch").click()
コメントもつけたのでどこで何をやってるのか想像ができるかと思います。
まず、詳細検索ボタンをクリックして、詳細検索の画面を表示します。
次に条件の指定です。
前述の通り、それぞれIDが振られているのでこれを指定してsend_keysで任意の値を入れたらOKです。
他の条件も指定する際にはIDを指定すればできます。
最後に検索をクリックすれば完了です。
また、ここで使ってるimplicitly_wait(10)というのは、処理が終わりまで10秒間待つという意味になります。
Seleniumを使う場合、プログラムの処理が早すぎて、文字入力が完了してないのに次の処理へうつろうとしてエラーが発生します。
implicitly_waitを使うと、処理が完了するまで待ってくれるのでこういったエラーを防ぐことができます。
検索をクリックする前のsleep(3)は3秒間待機という意味ですが、これも処理がきちんと終えていない状態にボタンをクリックしてしまうのを防ぐためです。
これで無事に検索結果が表示されます。
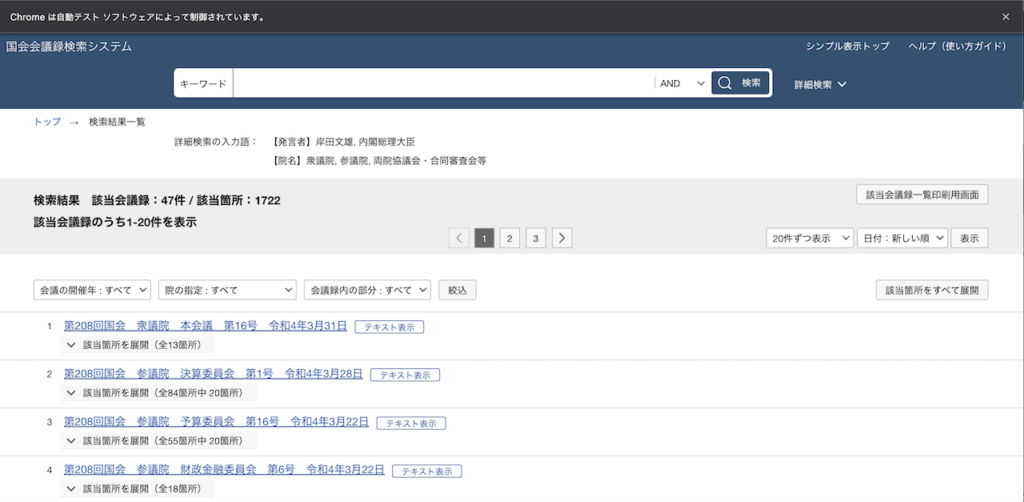
結果から各会議の日付、名前、URL等を取得
検索結果が表示されたら、次にやるべきことは各会議のデータを収集することです。
検索結果が複数ページある際には、ページ遷移あるいは表示件数を変更するなどして対応する必要があります。
今回の例では、該当会議録は47件と、表示件数を変更すれば対応できるのでページ遷移なしでいけます。
ただ、今後さらに多くのデータを収集する際には表示件数だけでは対応できなくなり、ページ遷移が必須になります。
そういったことも考慮すると、基本的にはページ遷移で対応した方が良さそうです。
ということで、ここでページ遷移で対応します。
タイトルと記事へのリンクを収集します。
from bs4 import BeautifulSoup
import pandas as pd
all_data = []
is_next_page_available = True
while is_next_page_available:
# htmlを取得
soup = BeautifulSoup(driver.page_source, "html.parser")
# 会議一覧を抽出
itemList = soup.findAll("li", {"class": "itemBodyColContents"})
# 各会議からタイトルとリンクを取得
for item in itemList:
# リンクはminIdを抽出して会議リンクへ変換
minId = re.findall(r"minId=(.*?)&", item.find("a", {"class": "itemTitle"}).get("href"))[0]
# unicodedataで文字コードを統一
title = unicodedata.normalize("NFKC", item.find("a", {"class": "itemTitle"}).getText())
all_data.append({
"title": title,
"url": "https://kokkai.ndl.go.jp/txt/" + minId
})
# 次ページがあるかチェック
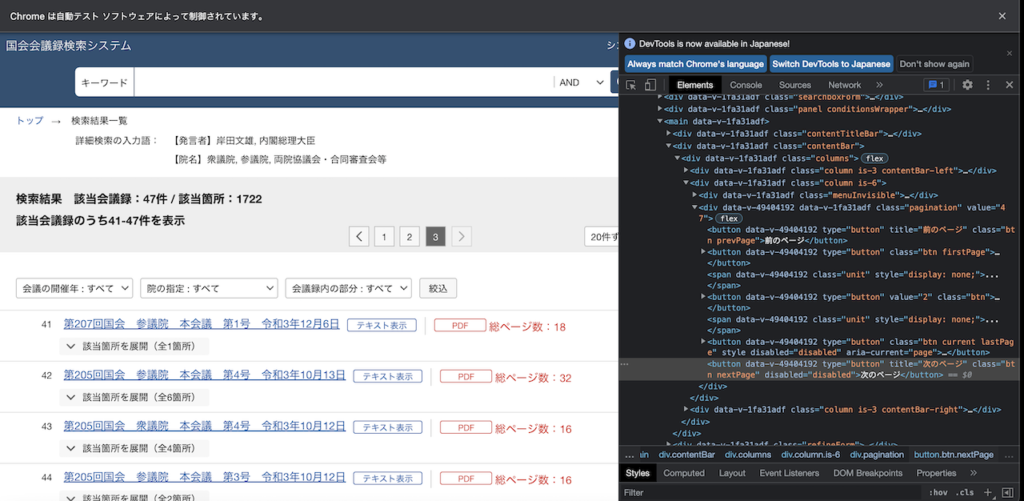
nextPage = soup.find("button", {"class": "btn nextPage"})
if nextPage.get("disabled") is None:
driver.find_element_by_class_name("nextPage").click()
sleep(3)
else:
is_next_page_available = False
# dataframeに変換
df = pd.DataFrame(all_data)
これで会議一覧のタイトルとリンクが収集できます。
各ページにおいて、会議一覧のliを取得して、それぞれのタイトルとリンクを取得します。
タイトルについては文字コードを統一するために、unicodedataを使って正規化しました。
使わないと\u3000という文字が出てきますが、normalizeすると消えます。

ちなみにこれを使えば全角数字も半角に統一できたりするので、知っておくとわりと使える場面が出てきます。
また、リンク先については先ほど確認したこちらのリンクを生成しています。
https://kokkai.ndl.go.jp/txt/120805254X01620220331
最後にあるIDみたいなものは、それぞれのaタグのリンクにあるminIdであることがわかったので、正規表現を使ってこれを抜き出してURLを作っています。
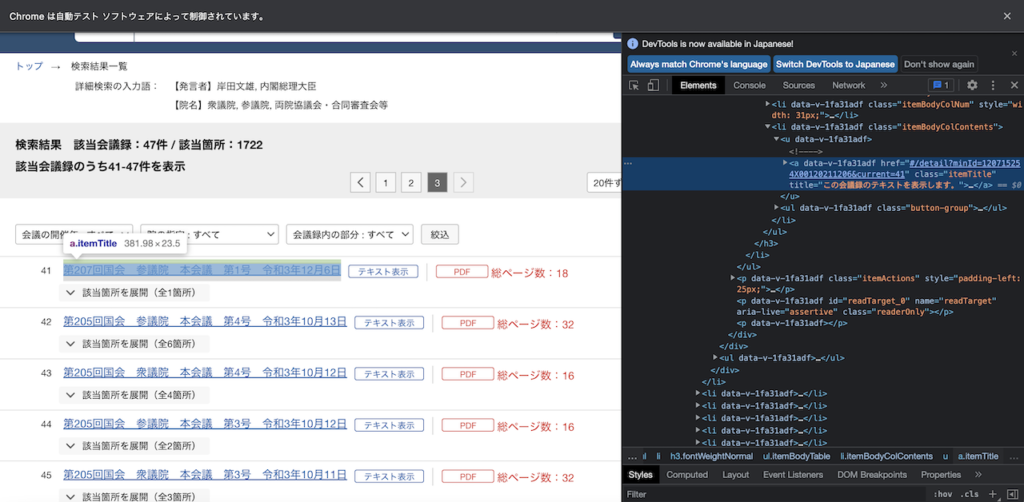
上記の通り、minId=の後に続くものが会議のIDのようなものであることがわかります。
最後に次ページがあるかを確認します。
リンクがあればクリックして、なければプログラムを終了します。
最後のページを確認すると、次ページがない場合はリンクが無効化されてdisabled="disabled"という要素が追加されていることがわかったので、これを発見するまでWhileループで処理を繰り返します。
最後の収集したデータをDataFrameに変換すれば完了です。
取得できたデータがこちらです。

各URLから発言内容を収集
最後に、取得したURLに1つずつアクセスして、発言内容を収集すれば完了です。
all_data = []
for i in range(len(df)):
# 行を抽出
row = df.iloc[i]
# ページ遷移
driver.get(row["url"])
sleep(3)
# html取得
soup = BeautifulSoup(driver.page_source, "html.parser")
# 発言データを1つずつ抽出
itemList = soup.findAll("div", {"class": "speachBlockBody"})
for item in itemList:
# 文字列を正規化
text = unicodedata.normalize("NFKC", item.getText())
data = row.copy()
data["text"] = text
all_data.append(data)
取得データはこちらです。

まだまだデータ整形が必要な感じがぷんぷんしますが、とりあえずデータの取得はできました。
データ分析を行うにはデータ整形が必要
ここまでで、Seleniumを使って「国会会議録検索システム」のデータを収集することができました。
ただ、今の状態では分析に使うことはほぼできません。
カラムがタイトルとURLのテキストのみで、条件を指定してデータを絞ったり、日付ごとのデータを抽出したりすることができません。
これを行うには少しデータ整形をしてデータを整えてあげる必要があります。
データ整形のやり方については、人によって個性が出てきます。
また、目的によって必要なデータも変わってくるので、データ整形のやり方も変わってきます。
今回は一例として次のようなデータ整形を行ってみました。
データ整形
- 議院(衆議院or参議院)を抽出
- 会議名(本会議など)を抽出
- 会議の日付を抽出
- 日付を西暦に変換
- 発言者名を抽出
上記をプログラムで処理すると次のようになります。
import numpy as np
import re
import datetime
def convert_date(x):
date = re.search(r"令和(?P<year>[0-9]{1})年(?P<month>[0-9]{1,2})月(?P<day>[0-9]{1,2})日", x)
return datetime.date(int(date.group("year"))+2018, int(date.group("month")), int(date.group("day")))
df_text["議院"] = df_text["title"].apply(lambda x: x.split(" ")[1])
df_text["会議名"] = df_text["title"].apply(lambda x: x.split(" ")[2])
df_text["日付"] = df_text["title"].apply(lambda x: x.split(" ")[4])
df_text["発言者名"] = df_text["text"].apply(lambda x: x.split(" ")[0] if x.startswith("○") else np.nan)
df_text["日付"] = df_text["日付"].apply(convert_date)
カラムから必要なデータを抽出するだけなので、コードしてはとてもシンプルです。
1つ触れるとすれば和暦から西暦に変換するためのconvert_dateという関数についてでしょうか。
これは和暦(ここでは令和だけ)を西暦に変換しているのですが、正規表現を使って必要データを抽出して変換しています。
?P<year>を使うと、yearという名前をつけることができて、この名前を使ってデータを指定することができます。
これらをintに変換してdate型に変換すればOKです。
これで日付でデータを抽出することができます。
また、発言者については、データを見ると、必ず「○発言者名」から始まっていることがわかります。
これを利用して発言者名を抽出しています。
データ整形後の最終データはこちらになります。

これでデータ分析できるレベルまである程度整形することができました。
まとめ
いかがでしたでしょうか。
ここでは「【Pythonコード解説】Seleniumで国会会議録検索システムをスクレイピングしてみる」というテーマで、Seleniumを使って国会会議録検索システムをスクレイピングする方法について解説しました。
Seleniumを使うと複雑なサイトでもわりと短いコードで簡単にスクレイピングすることができます。
検索ボックスへの文字入力やボタンのクリックなども可能です。
使いこなすには待機時間を設けたり多少の工夫は必要になりますが、うまく使いこなせるとかなり強力なツールになります。
PythonとSeleniumを使うとデータ収集の幅が大きく広がるのでとてもおすすめです。
そして本記事が少しでも参考になれば幸いです。
ここまで読んでくださり、ありがとうございました。




{kind=link}