
しばらく記事の更新が滞っていましたが、久々の更新です。
今回はおふざけ企画で、「安倍首相のこれまでの発言を収集してワードクラウドにしてみよう」というものです。
ちなみにワードクラウドは文字の頻度を可視化したもので、過去の記事でも紹介しています。
-

2020年12月31で活動休止を発表した「嵐」の歌詞を可視化してみた!
-

最近話題になったジャニーズグループの歌詞を歌詞化してみました!
最近ふざけた企画ばかりですみませんw
でも割と評判いいので今後もこういった企画は続けていこうと思います。
あまりお出かけのできない昨今なので、旅行記事などのネタもできず、家の中でこんなことをして日々楽しんでいます笑
さて、安倍首相は2019年の11月で、在職日数が最も長い首相になりました。
実に106年ぶりの記録更新です。
ちなみにそれまでのトップ5は以下の通りです。
- 桂太郎 2,886日
- 佐藤栄作 2,798日
- 伊藤博文 2,720日
- 吉田茂 2,616日
- 小泉純一郎 1,980日
そうそうたる名前が連なっていますが、このトップを安倍首相が塗り替えまして、2020年3月には在職日数が3,000日を突破しました。
ここでは、そんな歴代の在職日数を106年ぶりに更新した安倍首相のこれまでの発言をまとめてワードクラウドにしていきます。
データの収集→データの整形→ワードクラウドで出力といった流れで、各年を四半期ごとにデータをまとめてワードクラウドにしてみました。
結果を眺めていると、これまでの歴史を振り返ることができました。
目次
【Pythonでデータ分析】安倍首相の国会発言を集めてワードクラウドにしてみた!

1. まずは安倍首相に任期をざっくり振り返りましょう
まずは安倍首相の任期についてざっくり振り返っていきます。
まとめるのだるいので、Wikipedia先生から拝借しますw
- 第1次安倍政権
- 第1次安倍内閣 : 2006年(平成18年)9月26日 - 2007年(平成19年)8月27日
- 第1次安倍内閣 (改造) : 2007年(平成19年)8月27日 - 2007年(平成19年)9月26日
- 第2次安倍政権
- 第2次安倍内閣 : 2012年(平成24年)12月26日 - 2014年(平成26年)9月3日
- 第2次安倍内閣 (改造) : 2014年(平成26年)9月3日 - 2014年(平成26年)12月24日
- 第3次安倍内閣 : 2014年(平成26年)12月24日 - 2015年(平成27年)10月7日
- 第3次安倍内閣 (第1次改造) : 2015年(平成27年)10月7日 - 2016年(平成28年)8月3日
- 第3次安倍内閣 (第2次改造) : 2016年(平成28年)8月3日 - 2017年(平成29年)8月3日
- 第3次安倍内閣 (第3次改造) : 2017年(平成29年)8月3日 - 2017年(平成29年)11月1日
- 第4次安倍内閣 : 2017年(平成29年)11月1日 - 2018年(平成30年)10月2日
- 第4次安倍内閣 (第1次改造) : 2018年(平成30年)10月2日 - 2019年(令和元年)9月11日
- 第4次安倍内閣 (第2次改造) : 2019年(令和元年)9月11日 -
(Wikipedia参照)
忘れている方もいるかもですが、一番最初の安倍政権は2006年です。
しかしながらこの時は約1年で終わりました。
その後は安倍晋三→福田康夫→麻生太郎→鳩山由紀夫→菅直人→野田佳彦→安倍晋三の流れで、2012年12月26日に再び政権を掴み取ります。
ちなみに歴代の首相については首相官邸ホームページにまとまっています。
2012年12月26日が第2次安倍内閣であり、ここからこの記事を書いている2020年7月まで続いています。
今は第4次安倍政権です。
一度撤退はしていますが、諸々合計すると約10年間に渡って首相の座に就いていることになります。
長いw
2. 国会の議事録は誰でも簡単に確認できます!
国会の議事録については、「国会会議録検索システム」というサイトから誰でも簡単に見られるようになっています。
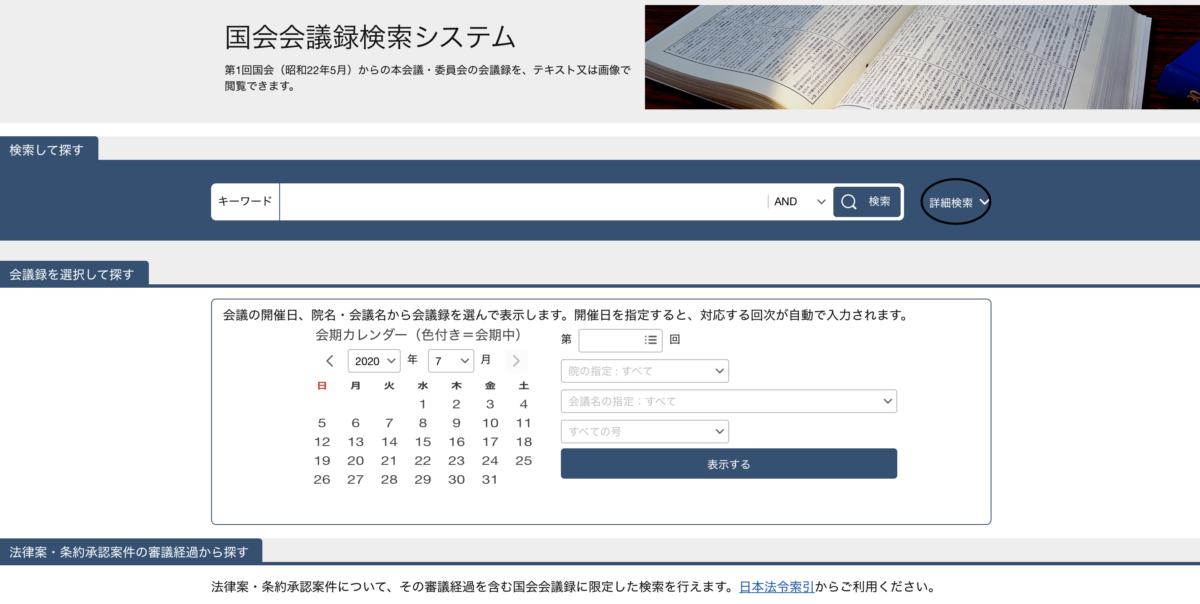
意外と知らない方が多いのではないでしょうか。
このサイトはなかなかリッチな検索機能も有していて、「詳細機能」を選択すると、名前で検索することはもちろんのこと、肩書きや所属会派等も指定して検索することもできます。
今回は、こちらのサイトからデータを収集します。
3. Pythonで議事録をスクレイピング!
データの収集にはPythonのスクレイピングという技術を使います。
これは、ウェブから情報を抽出する技術で、過去の記事でも紹介しています。
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
スクレイピングができると、膨大な量のデータでもプログラムで自動収集することができます。
プログラムを走らせてしまえば、あとはボケーっと待ってれば収集が完了しますw
そして、今回はサイトの構造が少し厄介だったので、Seleniumというブラウザーをプログラムで遠隔操作する荒技を使いました。
Seleniumを使うと収集スピードがめっちゃ遅くなってしまうのですが、今回は一回きりのデータ収集ということで、「とにかくスピード重視でさっさとプログラムを作る」ということでSeleniumを採用しました。
遅くても、走らせてほっとけばいいだけなので、こちらとしては余裕ですw
さて、安倍首相の発言を収集するには、まずはサイトの確認が必要です。
「国会会議録検索システム」の「詳細検索」をクリックすると、こんな感じで色々な条件を設定できる画面が出てきます。
ここに発言者名に「安倍晋三」、肩書きに「内閣総理大臣」とセットして検索すると議事録データがゲットできます。
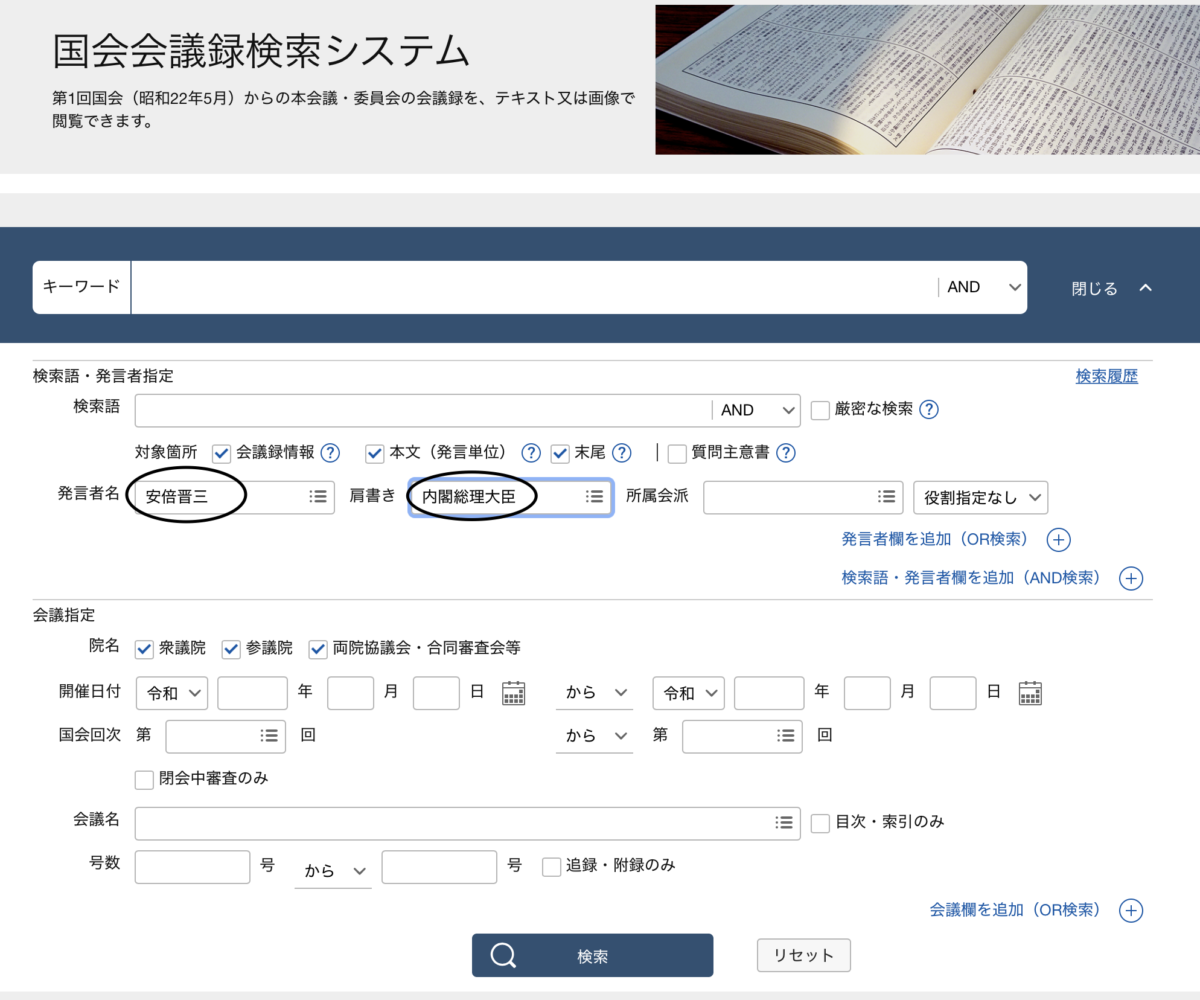
肩書きをセットしないと、首相になる前の発言も含まれてしまいます。
結果はこんな感じでいい感じにまとまっています。
全部で680件のヒットがありました。
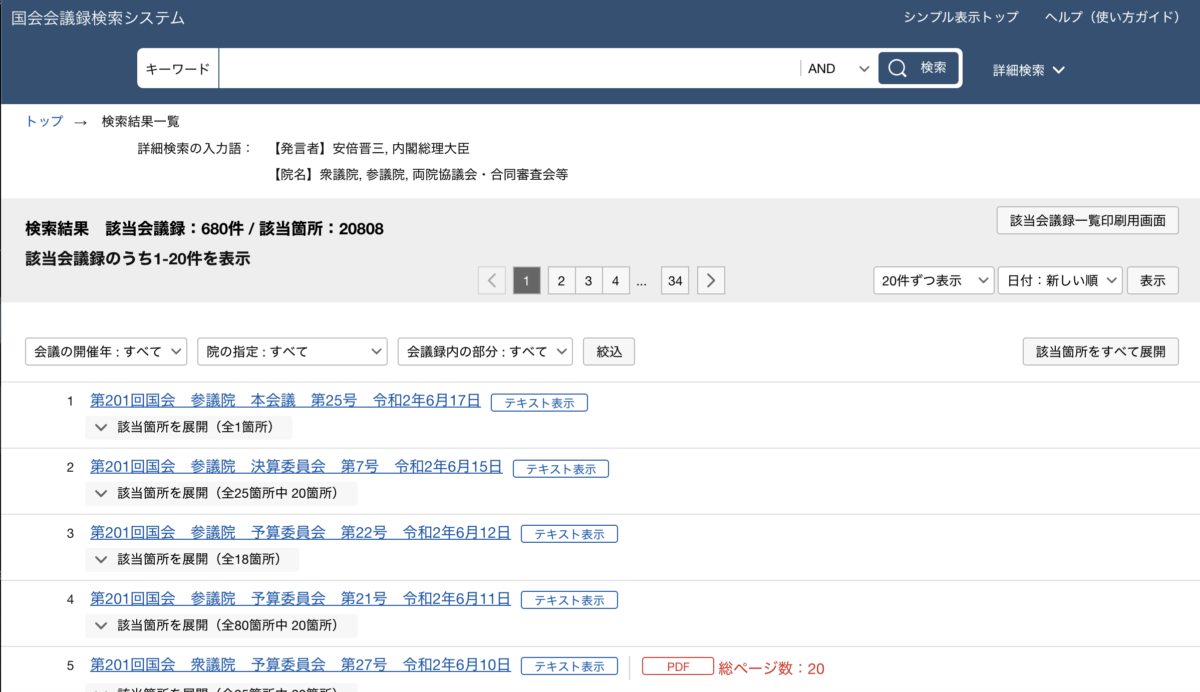
結果は会議単位なので、一つの結果に複数の発言があることもあります。
680個というのは、680個の会議を意味します。
そしてそれぞれの結果をクリックすると詳細情報が見れます。
とりあえず全情報が出力されます。
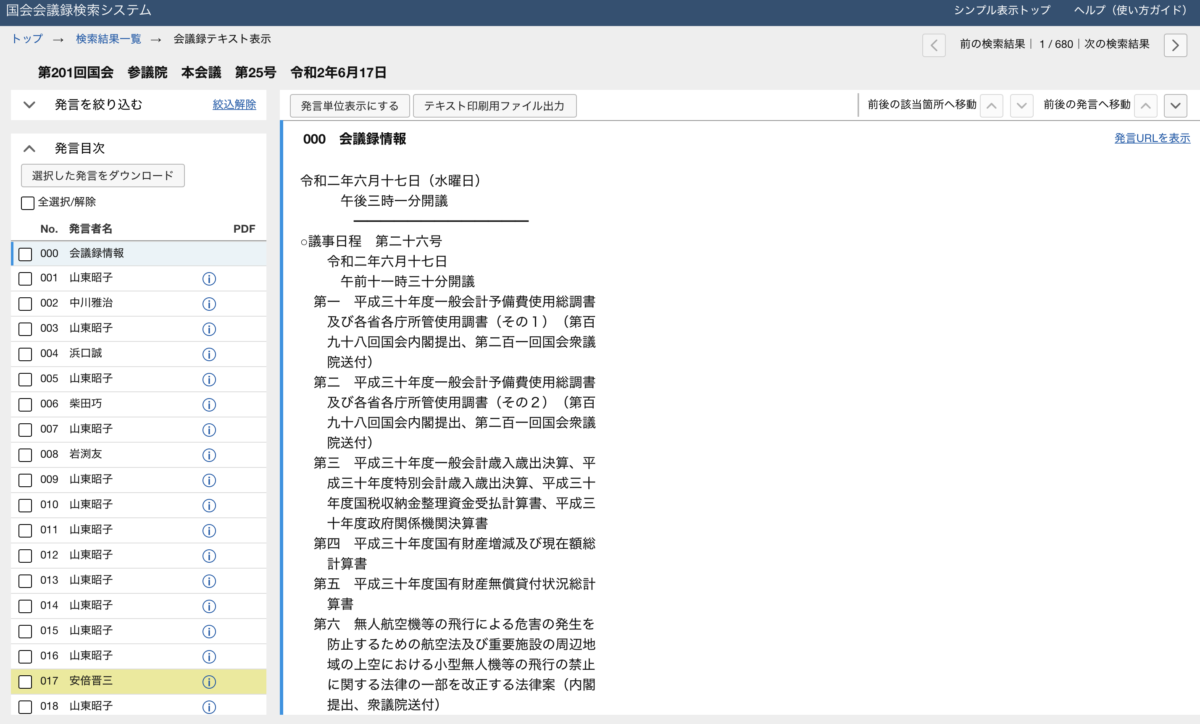
該当箇所が黄色でハイライトされているので、ここをクリックするとピンポイントで情報を表示できます。
こんな感じです。最後の(拍手)ってのが軽くツボりましたw
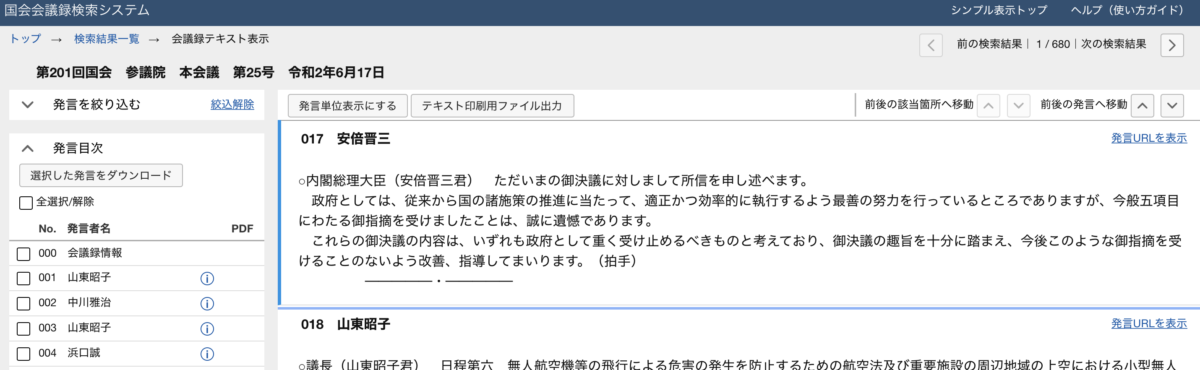
そして右上の「次の検索結果」を押せば、次の結果ページに遷移します。
つまりこれを680回繰り返せばいいわけですw
となるとプログラムでやるのは結構簡単で、情報取得→ページ遷移→情報取得→ページ遷移・・・とひたすら繰り返すだけです。
ここでは、プログラムをちゃんと書くのはめんどくさかったので、安倍首相に限定せずに全議事録データを根こそぎ取得しました。
汚いですが、こんな感じで取得できました。

ちなみにこちらのサイトは日付とかもタグづけされてなかったり割と変な構造をしています。
おかげでデータ整形は大変ですw
とりあえずデータ収集はこれで完了です。
4. データ整形〜ワードクラウド作成の下準備です〜
データが集まったところで、ここから汚いデータを排除しつつ、分析に使える形にしていきます。
過去の記事でもご紹介していますが、このデータの整形作業が一番だるいんですねw
-

【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!
でもこれをきちんとこなさないと結果がズタボロになってしまうので気合い入れてやっていきます。
今回行った作業は以下の通りです。
- titleから日付の抽出
- 和暦を西暦へ変換
- 日付から年、月を抽出
- 月から四半期を判定
- (全データ取ってきてしまったので)安倍首相の発言だけを抽出
- 不要な単語を削除
なかなかだるい作業ですw
まず、議事録データを見てみると、必ず文章は発言者名から始まっていて、安倍首相の場合は必ず「内閣総理大臣(安倍晋三君)」から始まっています。
ゆえに各発言データを見ていって、「内閣総理大臣(安倍晋三君)」から始まっていれば、安倍首相の発言であると判断できます。
また、titleには日付データがありますが、和暦です。
ゆえにこれを西暦に変換して、そこから年、月、四半期のデータをあぶり出します。
最後にいらない単語を消せば完成です。
結果がこちらです。
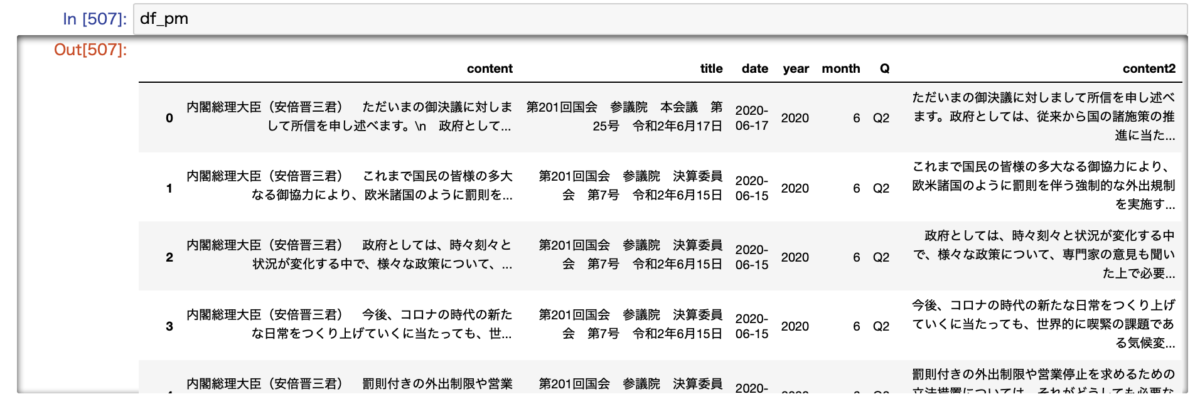
必ず「内閣総理大臣(安倍晋三君)」から始まっていることが確認できるかと思います。(「content」列です)
そしてここには不要な単語が結構ありまして、「内閣総理大臣(安倍晋三君)」という言葉もワードクラウドを作る際には不要です。
これを消しておかないと、全ての結果に「内閣総理大臣(安倍晋三君)」が一番でかく表示されることになりますw
また、「content」列をよくみると"\n"などの改行コードも含まれていることがわかります。
こういった不要な単語を削除したものが「content2」列になります。
ここまできれいになればデータ整形としては十分です。
次にいよいよワードクラウドの作成に入ります。
5. 各年の四半期ごとにワードクラウドにしてみました
MeCabを使って形態素解析→名詞だけを抽出
まずワードクラウドを使うためには、文字列からいい感じのものだけを選ぶ必要があります。
Pythonでは、MeCabというパッケージがありまして、これを使うと文章を簡単に形態素解析をすることができます。
形態素解析とは、文章を単語ごとに分けて、それぞれの品詞を判定することです。
文章による説明だとわかりにくいと思うので、例をお見せします。
こちらは安倍首相の発言の1つをMeCabで形態素解析した結果です。
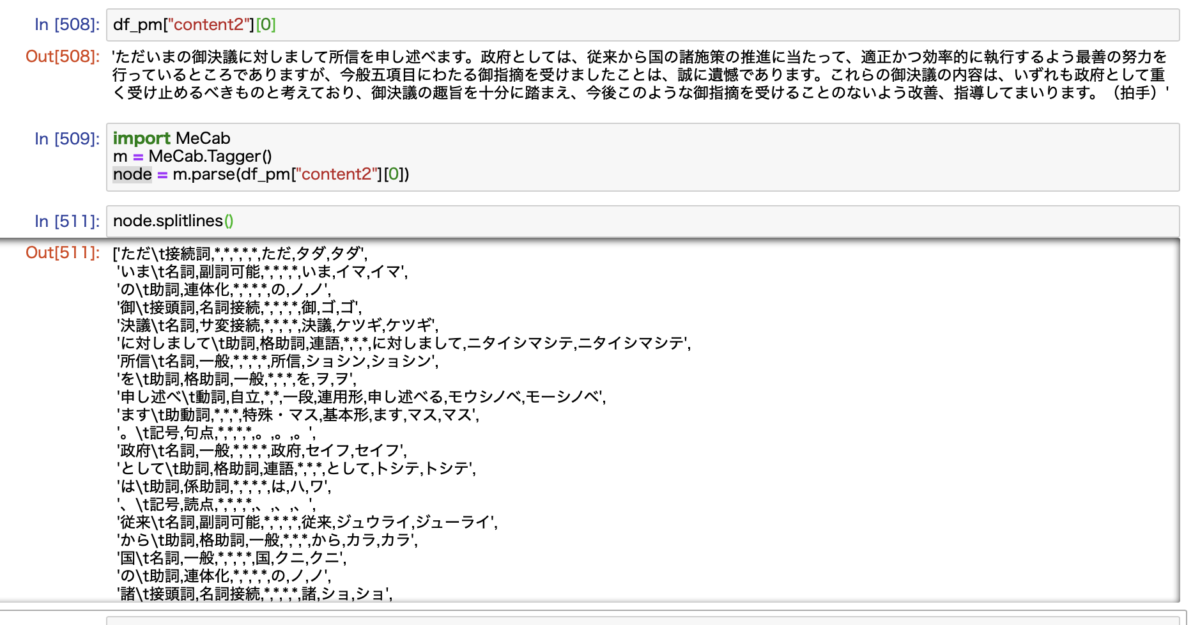
(ちょっと見づらくて申し訳ないのですが)元々の文章に対して、MeCabを使うと、単語に分割されて、それぞれの品詞が判定されていることがわかります。
ワードクラウドをきれいに作るには、ここでいかに意味のある単語だけを抽出できるかがポイントになります。
助詞、接続詞、接頭語などはさほど意味をもたないので不要です。
ここではシンプルに名詞だけを抽出してワードクラウドを作りました。
各年の四半期ごとにワードクラウドを作成
そして、今回は各年の四半期ごとにワードクラウドを作成しました。
全体で1つだとざっくりすぎるし、かといって1年ごとだと大雑把すぎてあまり時代の流れを捉えることができませんでした。
1ヶ月ごとだと多すぎる感じもするし、まあちょうどいいのは四半期ごとかなと思ってこの判断になりましたw
また、ワードクラウドを作成する際にはMeCabで名詞と判定されたものだけを利用しましたが、その中でも不要な単語が結構出てきます。
この除外作業は手作業になります。
結果を見つつ、「これいらなくね?」という単語があれば取り除いていきます。
いい感じの結果が出るまでこれを繰り返しました。
ちなみにこの作業で取り除いた単語はこちらです。
"もの", "こと", "よう", "これ", "わけ", "ところ", "それ", "必要", "日本", "我が国", "ため", "お尋ね", "国民", "皆様", "承知", "場合", "お答え", "様々", "たち",
"重要", "我々", "今後", "対応", "意味", "大切", "基本", "問題", "現在", "活動", "政府", "実現", "拍手", "検討", "指摘",
これで完璧とは言えませんが、大体は取り除かれたんじゃないかなと思います。
それでは出来上がったワードクラウドを順番に見ていきましょう。
各年で1枚でまとめていますが、それでも全部で10枚あるのでサクサクいきます。
データがないのは、任期でない、解散総選挙等で国会がやってない等の理由によるためです。
2006年

まずは2006年です
安倍首相が初めて総理大臣になった年ですね。
この時はデータを見ると「地方の改革」とか「教育」や「北朝鮮」などが目立ちます。
この時は小泉さんの次でしたからね。
プレッシャーもすごかったと思います。
2007年

次に2007年です。
ここも2006年とそこまで変わっていないように見えます。
そしてQ3で政権は終わったのでQ4データはありません。
この時のデータは目立った功績もなく終わってしまったので、データを見てもそこまで面白みがありませんでした。
データを見ても何も思い出せることがない・・・w
2013年

次に2013年です。
ここにたどり着くまでには首相がころころと変わって安定しない政権が続いていました。
そんな中、再び首相の座を勝ち取った安倍首相は、アベノミクスをぶち上げました。
「経済再生」、「財政健全」、「年金」などよく耳にしましたね。
2014年

2014年は「医療」、「女性」、「沖縄」、「派遣」、「労働」などが目立ちます。
医療費の拡大とか、男女格差、沖縄の米軍基地、労働力不足などが叫ばれていたことを思い出します。
やっぱりこうやってみると、その当時にあったことをなんとなく思い出すことができます。
2015年

2015年は「地方」、「自衛」、「経済」、「TPP」あたりが目立ちます。
自衛はISによるテロなどの影響もあって、かなり意識された年でした。
そしてTPPが大筋合意されたのもこの年です。
2016年

2016年は熊本で起こった大地震やトランプ大統領の当選など、歴史的な一年になりましたね。
ブレグジットが起きたのもこの年です。
ちなみにこの年に小池知事が当選して初の女性知事になりました。
その後の豊洲移転問題とかはみなさんご存知の通りですw
2017年

2017年は、前半はトランプ大統領で持ちきりだった気がしますw
僕は株式投資をやっているので、この頃から株価がイケイケだったことをよく覚えています。
この年はブレグジットを皮切りに、各国でEU離脱の動きが高まって、世界が分裂してしまうのだろうかとちょっとビクビクしてた記憶があります。
さらにISによるテロ行為がヨーロッパなどでも広がり、国際的に緊張状態になりましたね。
そして年後半には家計学園問題が登場しました。
Q3なんて家計学園関係の単語ばっかりですw
Q4では北朝鮮のミサイル発射が相次いで緊張状態となりました。
ちなみにこの年の流行語大賞に「働き方改革」が選ばれましたw
小池知事が満員電車解消とか色々言ってましたからね。
今となっては全く実現してないですが・・・
2018年

2018年で話題になったのはやはり「IR」、「人材問題」、「首脳会談」あたりですかね。
後半はもはやIRとかカジノで持ちきりでした。
カジノで依存の話とかも出てましたけど、「じゃあパチンコとかはどうなん?」とずっと思っていましたね〜(今でも思ってますw)
Q4になると労働力不足を解消するために外国人労働に頼るという動きも出てきました。
そしてこの頃から消費税増税の話も話題に出てきました。
2019年

2019年前半は消費税で持ちきりですw
「教育無償」や「待機児童」とかも話題に出てきてますね。
徴用工問題とか毎月勤労統計の不正も個人的には記憶に残っています。
2020年

2020年は言わずもがなですが、新型コロナウイルスで持ちきりです。
個人的に「オリンピック」が微塵も出てこなくて笑いましたw
現在も続いていますが、2020年2月あたりから新型コロナウイルスで世界中が大パニックになりました。
早く終息してほしいものです。
ワードクラウドにすると簡単にハイライトがわかる
ここまで四半期ごとでワードクラウドにしたものを紹介してきましたが、やはり結果をみると「そういえばこんなことあったな〜」と思い出せるものが多いことがわかります。
ワードクラウドにすると、話題になった言葉(つまり繰り返し使われていた言葉)が大きく表示されるので、その時のトレンドをうまく反映することができるんですね。
時代のトレンドを掴むためには、ワードクラウドは有効な手段の一つであると改めて実感しました。
6. データ分析にはPythonがおすすめです!
さて、ここまで安倍首相の発言をワードクラウドにしたものを紹介してきましたが、今回行ったデータ収集、データの整形、ワードクラウドの作成は全てPythonというプログラミング言語を使って行いました。
Pythonは特にデータ分析やAI関連に強くて、今回のようなテキスト分析にも非常に強い言語です。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
多言語に比べて学びやすくて、体系的なすっきりとしたコードが書けるので世界中で人気を集めています。
今もっともホットな言語といっても過言ではないと思います。
身につけておくと、転職時にも有利になるのでオススメです。
僕自身も独学でPythonを習得し、今では仕事でもPythonをメインで利用し、プライベートでは今回のようなふざけたこともやっていますw
-

【副業は神です】2度の転職において副業が内定の決め手になったお話。
Pythonはデータ分析だけでなく、ウェブサイトの構築など様々な用途にも対応することができるので、Pythonを身に付けることで多くの場面で役立ちます。
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
まとめ
いかがでしたでしょうか。
ここでは安倍首相の発言を各年の四半期ごとにワードクラウドにしてみました。
ワードクラウドを使うと、その時代のトレンドがうまくハイライトされて、様々なことを思いかえすことができました。
トレンドを確認するためには、ワードクラウドはなかなか使えそうなことが今回の企画でよくわかったので、今後も色々と応用していこうと思います。
(くだらない企画でしたが、)ここまで読んでくださって、ありがとうございました。
-
【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【挫折しないために!】プログラミングを学習するためには目的意識が重要!途中で挫折する人の特徴とは?
-

【迷っている方へ!】プログラミングに興味を持ったらとりあえずやってみよう!
-

プログラミング学習は独学とプログラミングスクールどちらにすべきか?【結論、全部試すべし!】
-
【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】




{kind=link}