
こんにちは。TATです。
今回のテーマは「インスタントラーメンのデータ分析」です。
先日、Kaggleを見ていたらたまたま見つけました。
僕自身も日本が誇るソウルフードであるラーメンに対しては並々ならぬ情熱があります。
Kaggleには世界のインスタントラーメンのレビューをまとめたデータがあったんですね。
Pythonを使ってこのデータを色々と見てみたので、ここではその結果をシェアしようと思います。
データセットとしてはそこまで大きなデータではないので、あまり突っ込んだ分析はできなかったのですが、国別の商品とか色々と知ることができたので、個人的には見ていてとても楽しかったです。
目次
【Pythonでデータ分析】Kaggleでインスタントラーメンのデータを発見したので分析してみました

データはKaggleから入手できます
今回用いたラーメンデータの入手元はKaggleというサイトです。
Kaggle公式サイトより
Kaggleはデータ分析のコンペを運営しているサイトで、データが与えられて、それを参加者が分析して結果を競い合います。
優勝者には、賞金が贈られたり、開催企業の就職面接を受ける権利などが与えられます。
GoogleやFacebook、日本企業ではメルカリなどもKaggleによるコンペを企画しています。
さらに他の参加者のコードも見ることができるので、分析手法はコードの書き方を学ぶ場としても最適です。
ある程度の基礎知識があれば、あとは人のコードを見ながら学ぶことは効率的に学ぶポイントです。
ただ、Kaggle は基本的に英語サイトなので、英語が読めないとしんどいです・・・
そして今回利用したラーメンデータがこちらになります。
ちなみにデータをダウンロードするには登録(Register)が必要です。
まずはデータ全体を把握する
データ分析を始めるにあたってまず一番最初にすべきことはデータ全体の把握です。
どんなカラムがあるのか、データのタイプどうなっているのか、前処理は必要なのか、色々なことを考慮しながら、データ分析を行う準備を行っていきます。
PandasでCSVデータを読み込む
それでは始めていきます。
まずはRamen Ratingsからダウンロードしたファイルを読み込んでいきます。
head関数を使って、読み込んだデータの最初の5行だけ表示してみます。

カラム名から大体意味は推測できるかと思います。Varietyと書かれているのは商品名です。
Top Tenに入っているものは、このカラムに順位データがあります。10位以降は全てNaNです。
「Style」をチェックする
ここでStyleカラムについてみておきます。
どのような値があるのかというと、次の7種類があるようです。
ユニーク値だけを表示する場合には、unique関数が便利です。
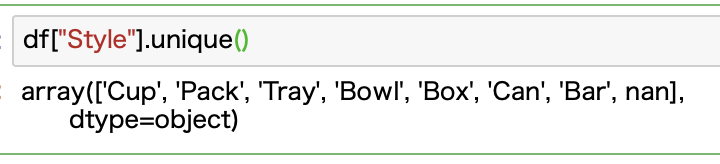
ぶっちゃけ、よくわからないですよね。
Cupは普通のお湯を注ぐだけのカップラーメンですかね。
Packは袋麺的なものかなと思いましたがBowlも同じような感じもします。
TrayかBoxは焼きそばみたいなやつですかね。
CanとかBarは謎ですねw
該当商品を調べる
このままだとよくわからないので、該当商品をググってみます。
馴染みある日本商品で該当するものがあればイメージしやすいですね。
ということで日本商品で絞ったうえでStyleをみてみます。

CanとBarが消えて、5つだけになりました。
順番にみていきます。
Cupはお馴染みのカップヌードル!
まずはCupです。
評価が高い順にトップ10を出してみます。
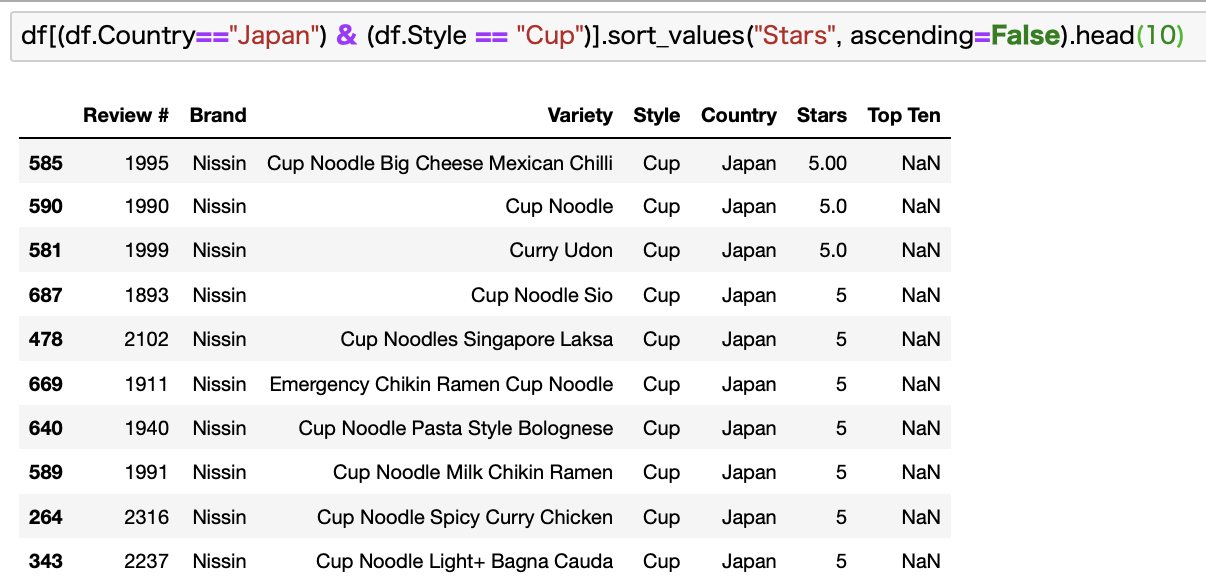
同じ5点でも、整数と少数があるのが気になるところですが、ここでは一旦無視しますw
データを見ると、いわゆる日清のカップヌードルですね。
円柱型の容器に入ってるあのカップ麺です。
お湯を注ぐだけのタイプですね。
Trayは水を切る焼きそば!
次にTrayです。
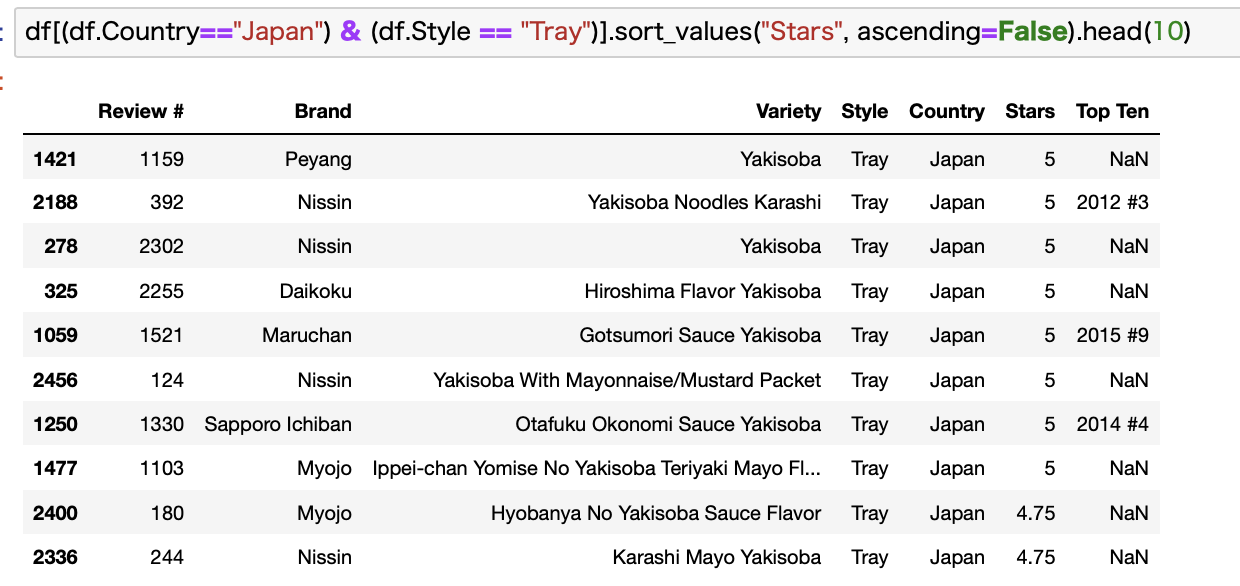
こちらも一目瞭然。
Trayは焼きそばであることがわかります。
水を切るタイプのものがTrayに分類されてるっぽいですね。
Packが茹でるタイプ
次にPackをみていきます。
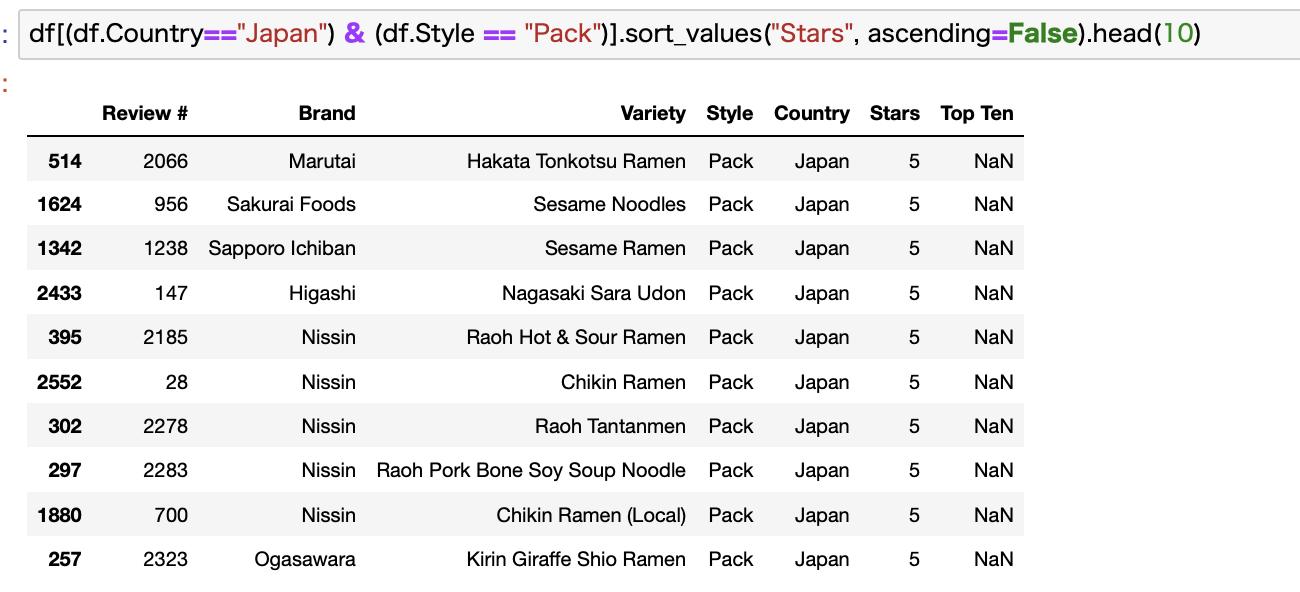
ちょっとわかりにくいですが、チキンラーメンとか入ってますね。
これらはググって確認したところ、いわゆる袋麺です。
自分でお湯を沸かして茹でるタイプです。
Bowlはどんぶり型
次にBowlです。
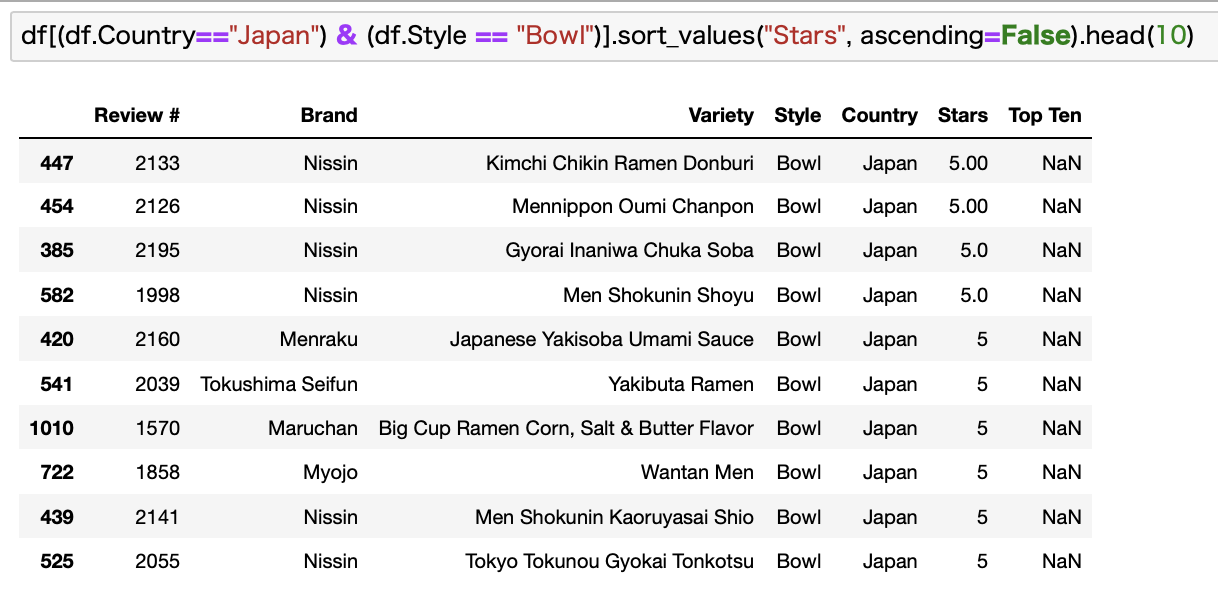
これもわかりにくいのですが、調べたところどんぶり型のカップラーメンみたいです。
Cupである日清カップヌードルは細長い容器ですが、Bowlの方はもっと幅の広いどんぶり型の容器です。
イメージ的には「赤いきつねと緑のたぬき」みたいな容器です。
こちらもお湯を注ぐだけのタイプですね。
BoxはPackとの違いがわからない・・・
お次にBoxです。
こちらは2つしかありませんでした。

全然わからないので1つ目の商品をググりました。
公式サイトを見つけました。
ぶっちゃけPackとの違いがわかりません・・・
これは無視してもいいかもですね。
サイトを見る感じ、本当に日本商品なのかも怪しいw
マレーシアかシンガポールのブランドですかね。
Boxは無視してもいいかもです。
CanとBarも無視しますw
最後にCanとBarです。
これらは該当商品が日本にはなく、さらに全データの中でも1つずつしかありませんでした。
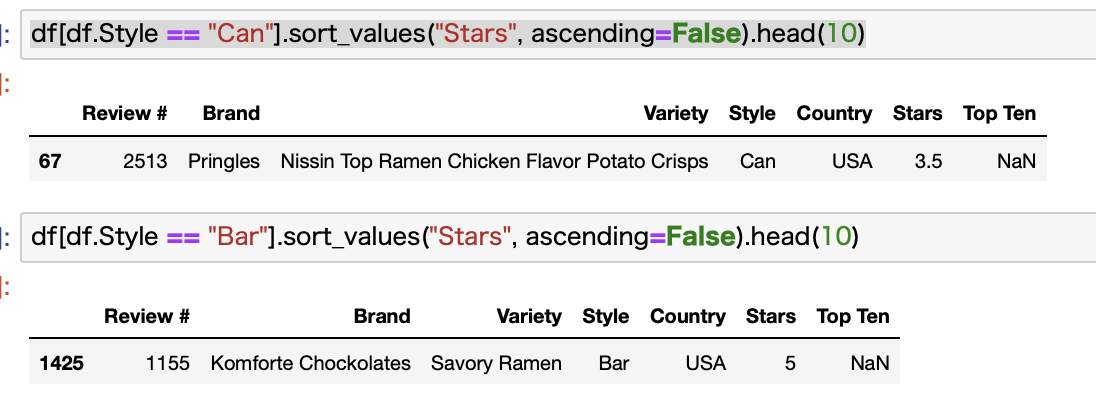
ということでこれらも無視ですね。
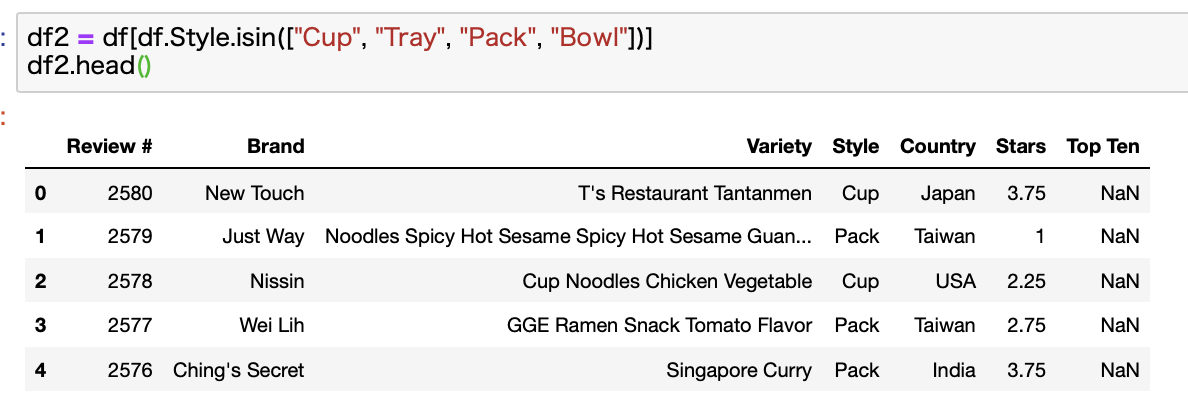
Cup, Tray, Pack, Bowlの4種類のみを使います。
検証の結果として、利用できるStyleはCup, Tray, Pack, Bowlの4種類かなと思います。
その他はかなりマイナーなので無視して進めていきます。
ここまで無駄に時間を使いました・・・
こんな感じで該当Styleのみを抽出してdf2としておきます。
データのタイプを確認する
次にPandasで読み込んだデータをdescribe関数やinfo関数で見てみます。
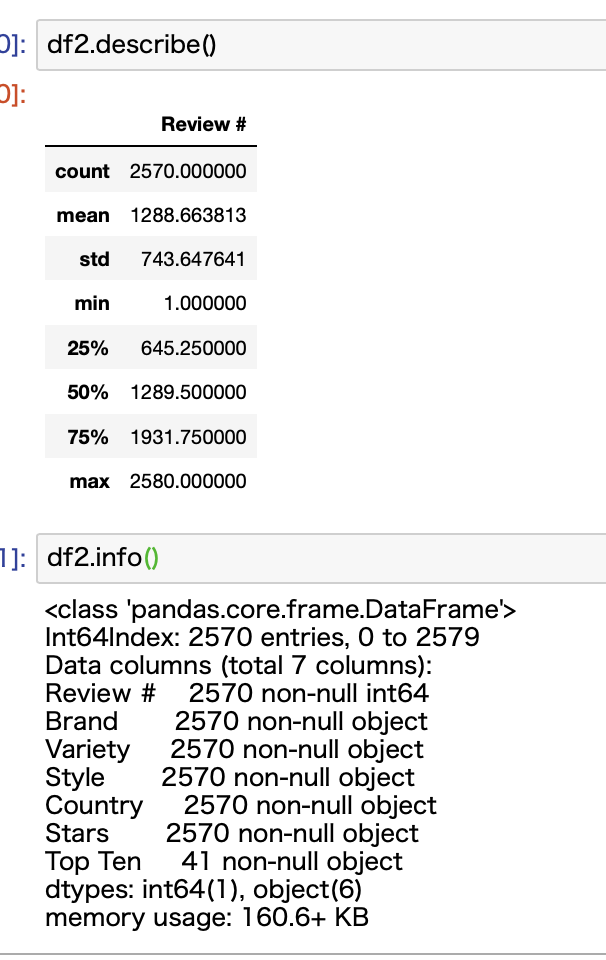
ここで確認したいのが、Starsのデータがdescribe関数で表示されていないことです。
info関数を見てみると、データタイプがobjectであることがわかります。
Starsを整形する
Starsのデータを見ると、Unratedというデータがありますね。

これが原因で、列全体が文字列として判断されてしまっていることがわかります。
ここをNaNに変換して、全体をfloatに変換します。
Pythonなら1行で完了します。
import numpy as np
df2["Stars"] = df2["Stars"].replace("Unrated", np.nan).astype(float)
こんな感じで、まずはreplace関数でUnratedをNaNに変換して、カラム全体の型をfloatに変換します。
NaNを指定するにはnumpyのnanを使います。
これでデータの整形は完了です。
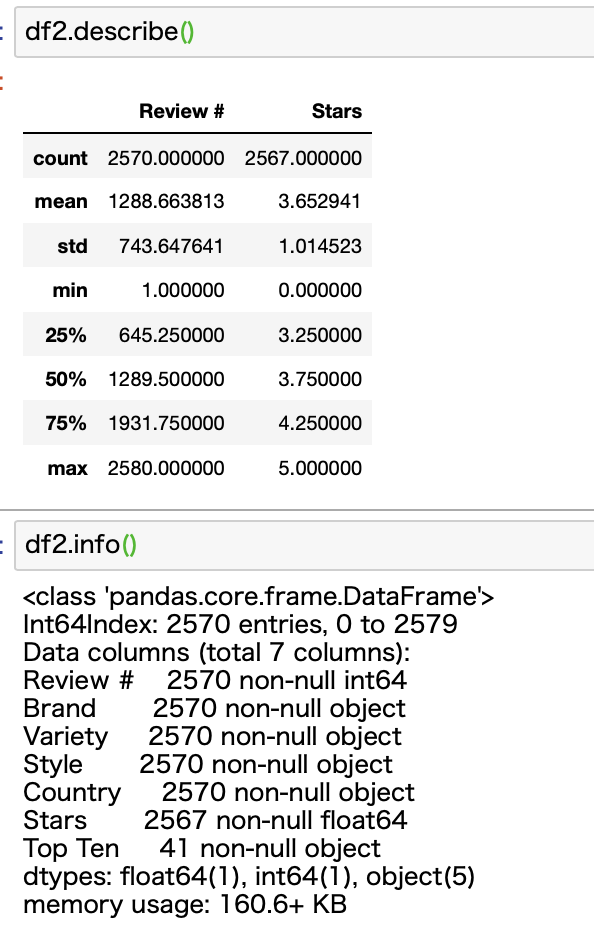
「Reviews #」の分布を確認する
最後の確認として、「Review #」を確認しておきます。
もしこの数字が低いと偏った意見になってしまうので、極端に少ないものがあれば排除しておいたほうが、データ分析の信憑性が上がります。
上記の通り、describe関数で見ると、「Review #」の最小値は1であることがわかります。これはあまり信用できないですよね。
他にもこのようなデータがないかどうか、ここではヒストグラムで見てみます。
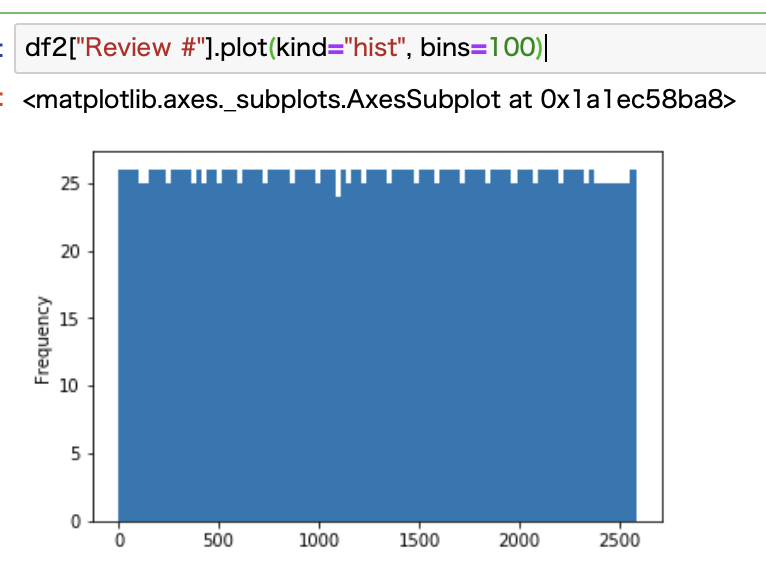
見ての通り、均等配分されてる感じになっていますね。
数十個しか「Review #」がないデータも結構あるようです。
1桁のものもあります。
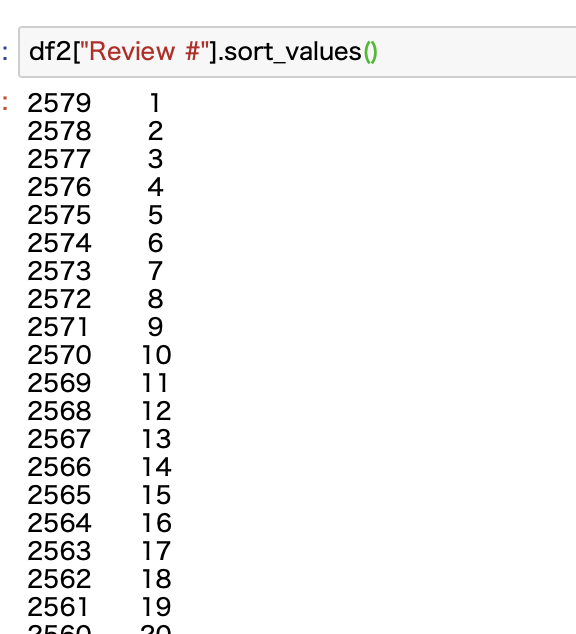
これはある閾値を設けてそれ未満のものは消すのが良いですかね。
ということでdescribe関数で平均や標準偏差などをみてみます。
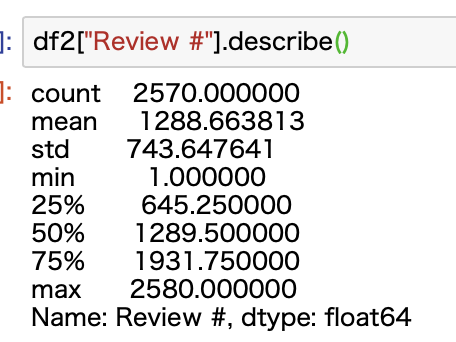
第一四分ぐらい数で645.25ですね。
std(標準偏差σ)を使って、信頼区間が95%ほどである-2σでもマイナスになってしまいますね(1288.663813 - 2*743.647641)。
そもそもヒストグラムが正規分布ではないので、ここでは統計的に外れ値をカットするみたいなやり方は難しいですね。
とりあえず独断で「Review #」数が100個未満のものは排除する方針で見てみます。
残ったデータをdf3とします。

余談ですが、Review数もしっかりあってScoreが1のラーメンが台湾の製品というのは少しショックですね。(僕の妻は台湾出身の方です・・・)
僕自身なんども台湾を訪れてますが、まずいインスタントラーメンに出会ったことがないんですよね・・・w
ちなみに過去記事でも台湾のスーパーを紹介していて、そこでインスタントラーメンもちらっと紹介してます。
普通にめっちゃ美味しかったですよ!
-

【お土産を格安でゲット!】台北発祥の大型スーパー「大潤發」を探検!
-

現地の生活感が感じられる!台北市内の大型スーパーへ行ってみました。
とりあえずこれでデータ分析の準備は完了したので、次からデータをいろいろとみていこうと思います。
各カラムの分布を見る
まずは各カラムごとの分布を見てみます。
BrandやStyle、Countryでそれぞれどれくらいのデータがあるのかをみてみます。
ここでは棒グラフで見てみます。
Brandでは我らがNissinが圧倒的
まずはBrandを見てみます。
Brand数が多すぎたのでトップ20をみてみます。
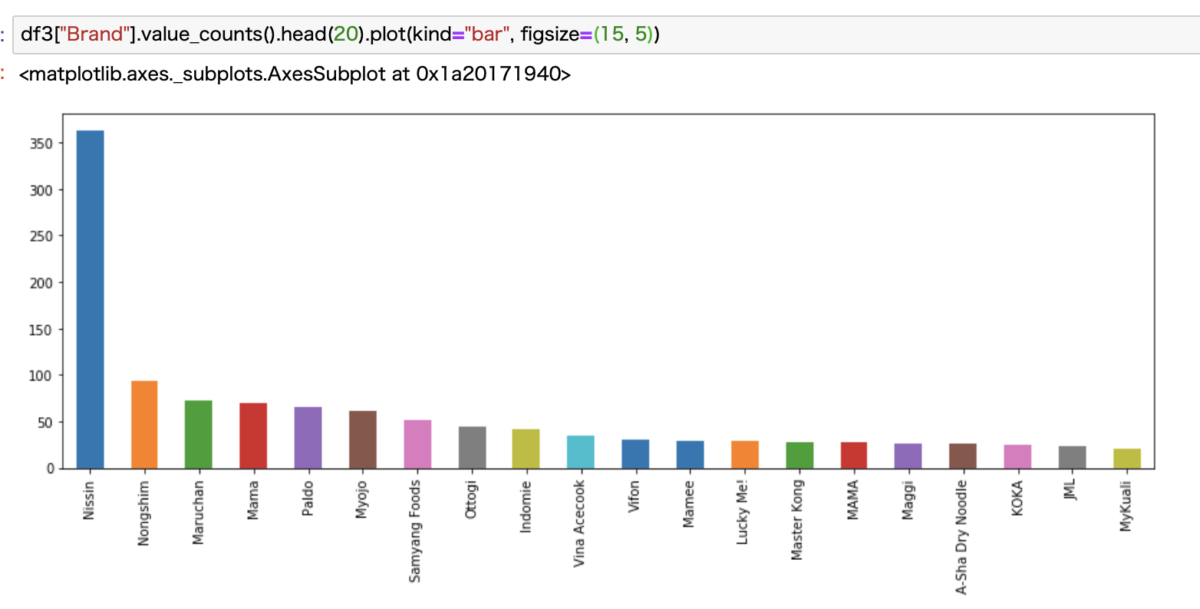
我が国が誇る日清の圧勝ですね。誇らしいです。
マルちゃん正麺とか明星とかも入ってますね。
さすがはインスタントラーメン大国です(聞いたことないですが)。
StyleではPackの圧勝
次にStyleで見てみます。
さっきのコードパクったのでhead(20)がそのままですが、ここでは4種類しかないので全部表示されています。
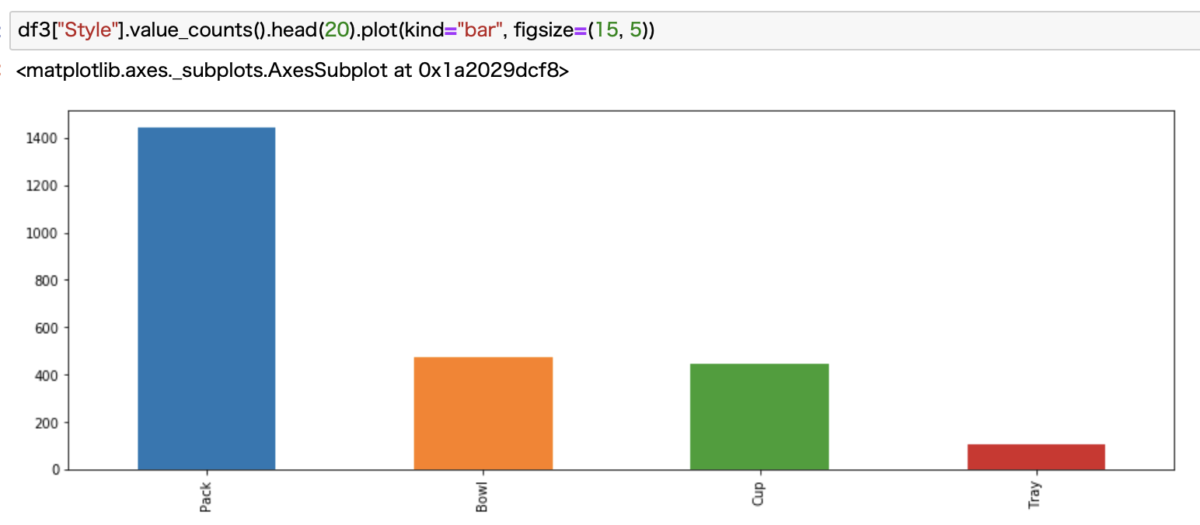
Pack、いわゆる袋麺が圧倒的に多いですね。
焼きそばとかのTrayは、日本以外ではあまり見ることがないので、少ないのも納得です。
BowlとCup足してもPackには敵いません。
たしかに海外に行くとお湯を入れるだけのインスタントラーメンはあまりみないような気もします。
Countryでは日本が僅差で勝利
次にCountryでみてみます。
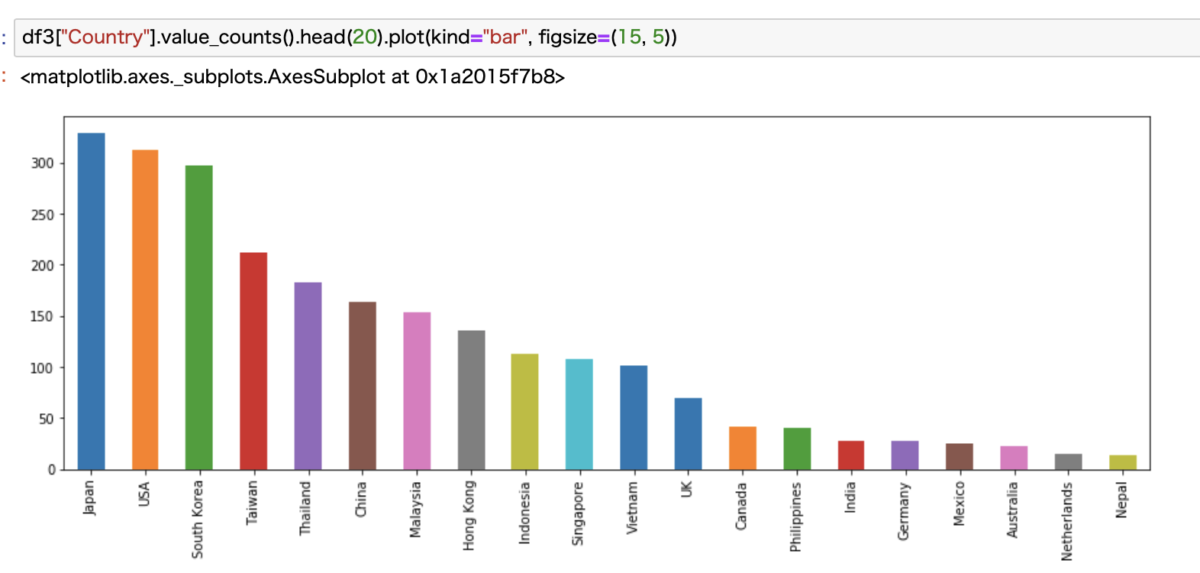
僅差で日本が優勝です。
アメリカが2位というのは意外でした。
韓国は納得ですね。ここまでは僅差です。
そして少し離れて台湾、タイ、中国、マレーシア、香港と続いています。
各カラムで集計する
次にそれぞれのカラムごとでデータを集計してみます。
特にレビュースコアであるStarsが気になりますよね。
Countryごとの集計データ
まずはCountryごとにみてみます。
最初は単純にReviewの平均の高いCountryトップ20を見てみます。
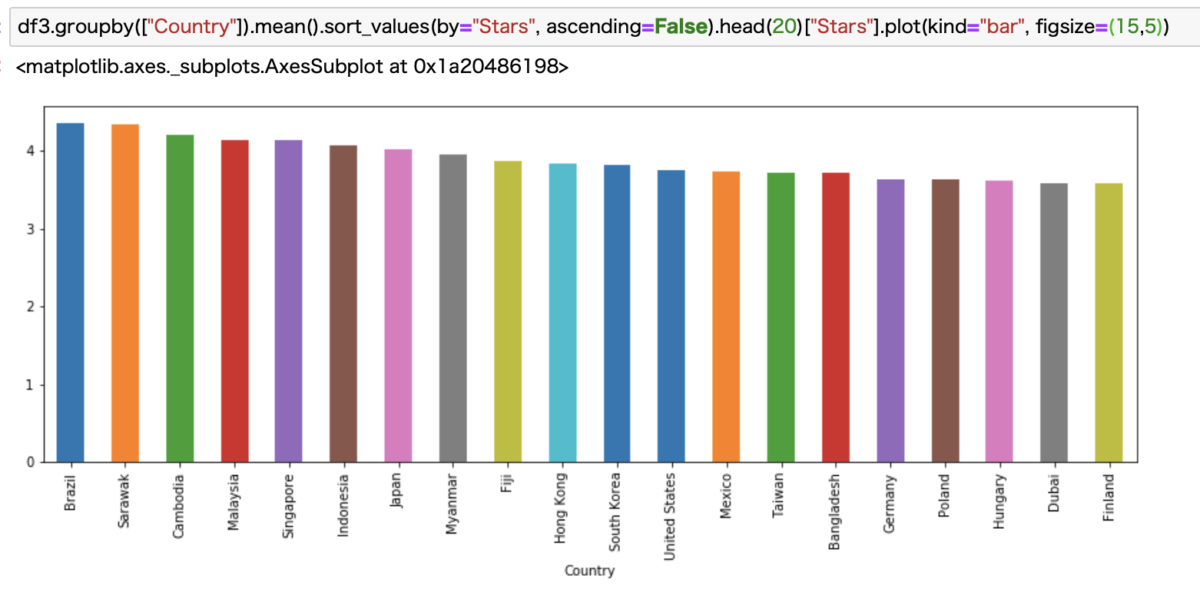
なんと意外にも1番はブラジルでした。
これだけだと商品数とかが見えないので、数値データでもお見せします。
この場合はagg関数を使うと便利です。複数のカラムを指定して計算することができます。
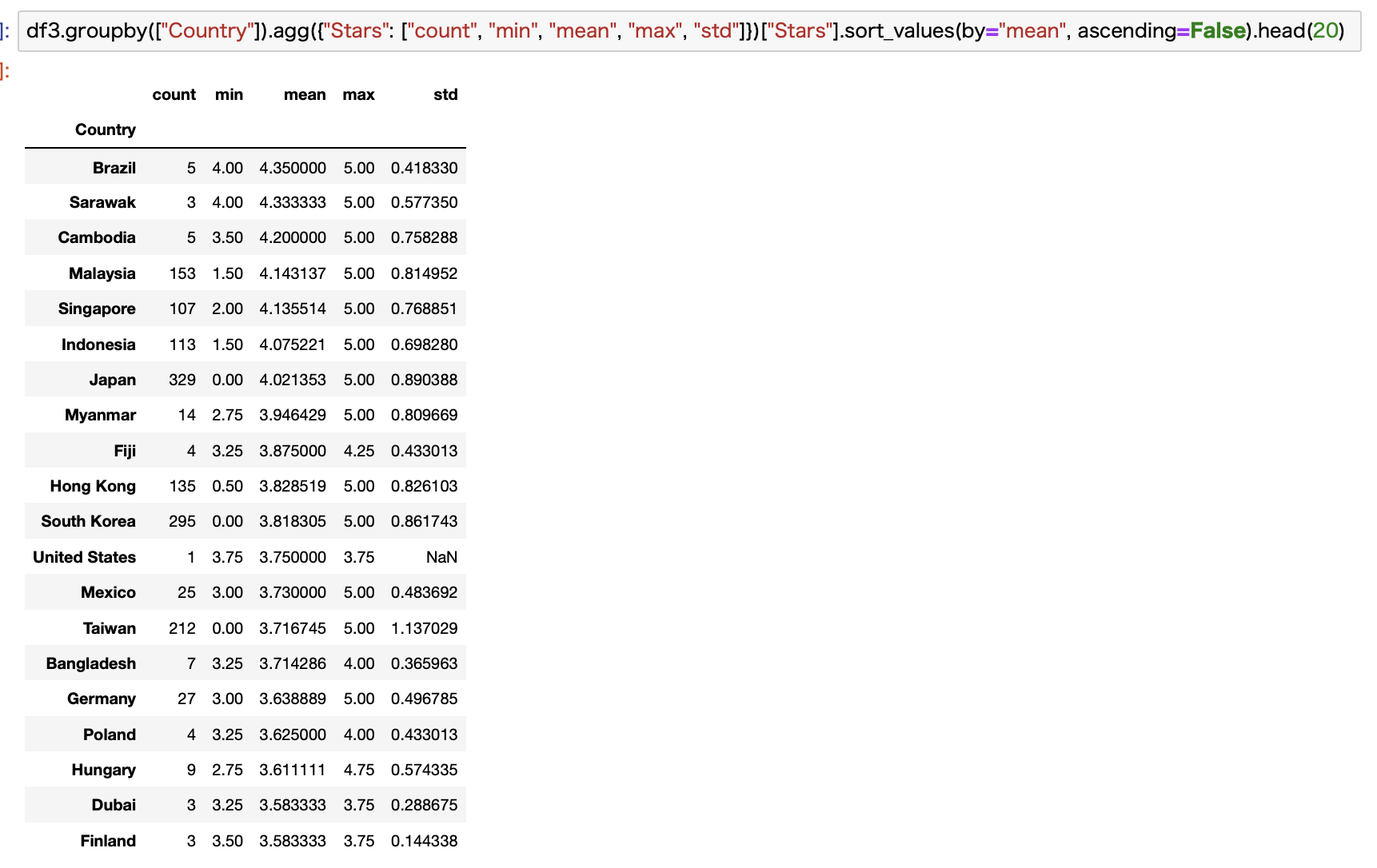
これを見ると3位までは商品数が少なすぎてあまり信憑性はありませんね。
こういったマイナーなCountryも排除しておくべきでしたね。反省です。
実質的な1位はマレーシアでしょうか。
ちなみに、僕は学生時代にマレーシアに滞在経験があって、現地のインスタントラーメンを食べましたが、わりと美味しかった印象があります。激辛でしたが。
商品数ではやはり圧倒的に日本が一番で、なおかつ平均点も高いので全体的なレベルが高そうな感じがします。
ちなみに対象データが10個以上あるBrandに絞った場合はこんな感じになります。
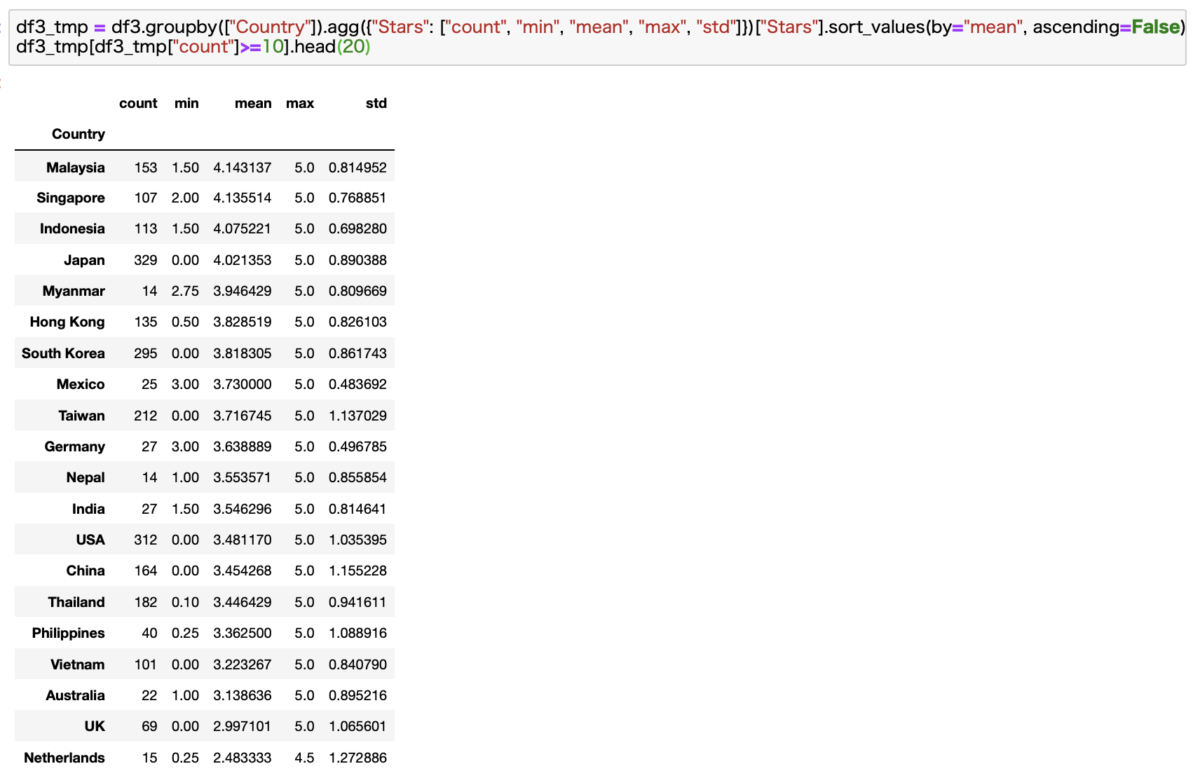
日本は4位でした。
Brandごとの集計
次にBrandごとに見ていきます。
先ほど同様に、対象データが10個以上あるものに絞りました。
ちなみに平均値は7.15でしたw
ちっちゃいメーカーが多いんですね。
もう数値データでお見せします。
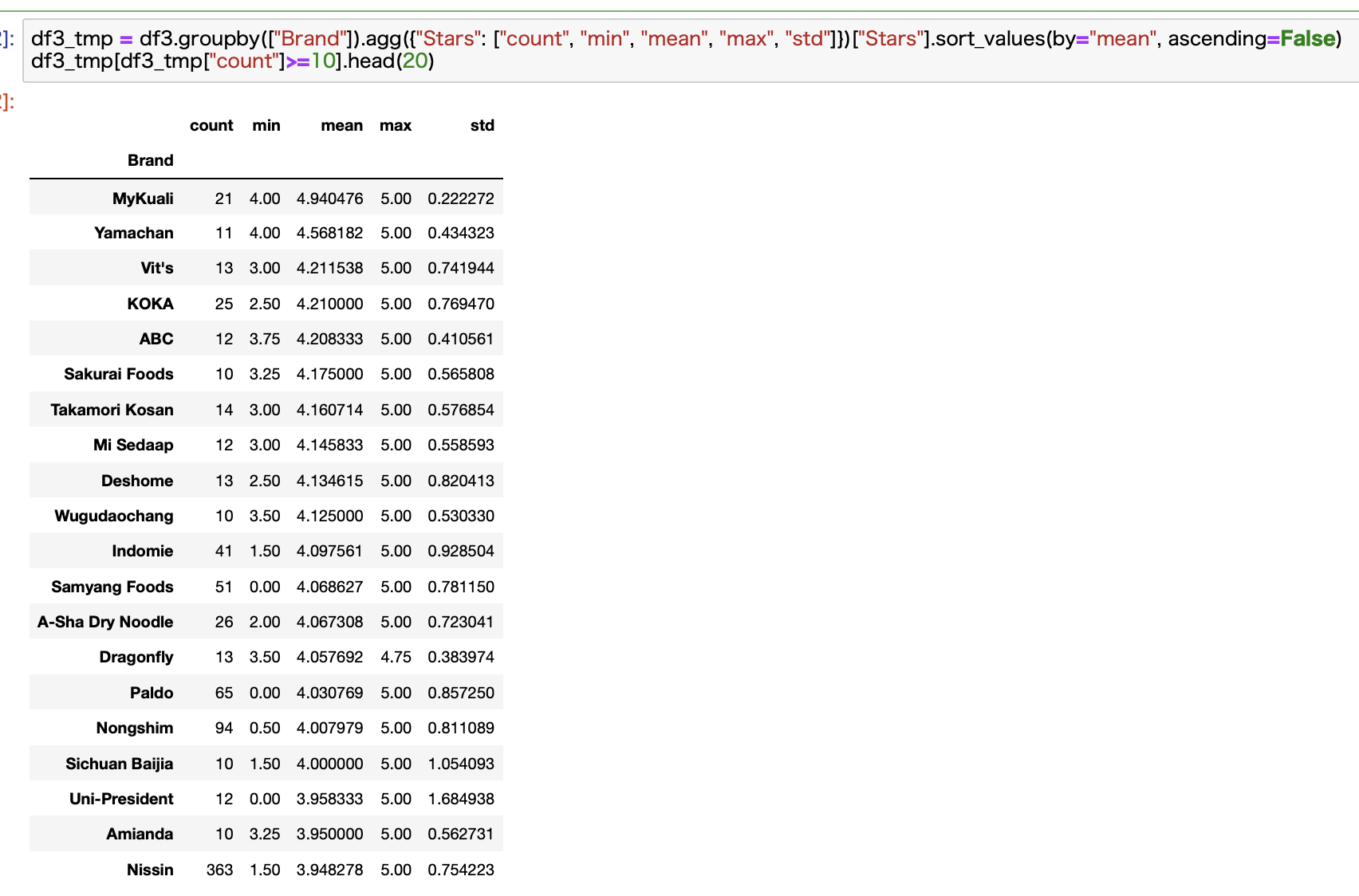
日清が20位に滑り込みました。
それ以外は全て商品数が100個未満でさらに20個未満のBrandも多いですね。
Styleごとの集計
最後にStyleを見ていきます。
これはあまり面白みがないですねw

データが圧倒的に多いPackが平均点も高い結果となりました。
焼きそばとかのTrayは商品数は少ないですが頑張っていますね。
Cupは特に海外だと激安のものがよくあるので、味もイマイチなものが多いのかなと思ったりもしますw
複数カラムで集計する
次に少しレベルアップして複数のカラムで集計してみます。
全パターンを試すと結構な量になるので、ここでは僕が気になるところを独断と偏見でピックアップしました。
ご興味があればご自身でも集計してみてください。
本記事で紹介しているコードをそのまま書いてもらえば再現できます。
あとはカラム名をいじくれば任意のカラムで集計することが可能です。
Country × Brand
まずはCountryとBrandで見てみます。
これをみたいと思った理由が、「日本のメーカーだけ異常に商品数が多いんじゃないか?」と思ったためです。
この疑問を確認するために、Countryごとの商品数をBrand数で割った数値を並べてみます。
ちょっとめんどくさいですがデータをいじくります。
実際に行ったコードがこちらです。
# CountryとBrandで各値を集計
df3_tmp = df3.groupby(["Country", "Brand"]).agg({"Stars": ["count", "min", "mean", "max", "std"]})["Stars"].reset_index()
# CountryごとのBrand数と商品数を集計
df3_tmp2 = df3_tmp.groupby(["Country"]).agg({"Brand": "count", "count": "sum"})
# 商品数とBrand数の比を計算
df3_tmp2["Products / Brand"] = df3_tmp2["count"] / df3_tmp2["Brand"]
# 比でソート
df3_tmp2.sort_values(by="Products / Brand", ascending=False).head(20)
これで得られた結果がこちらです。
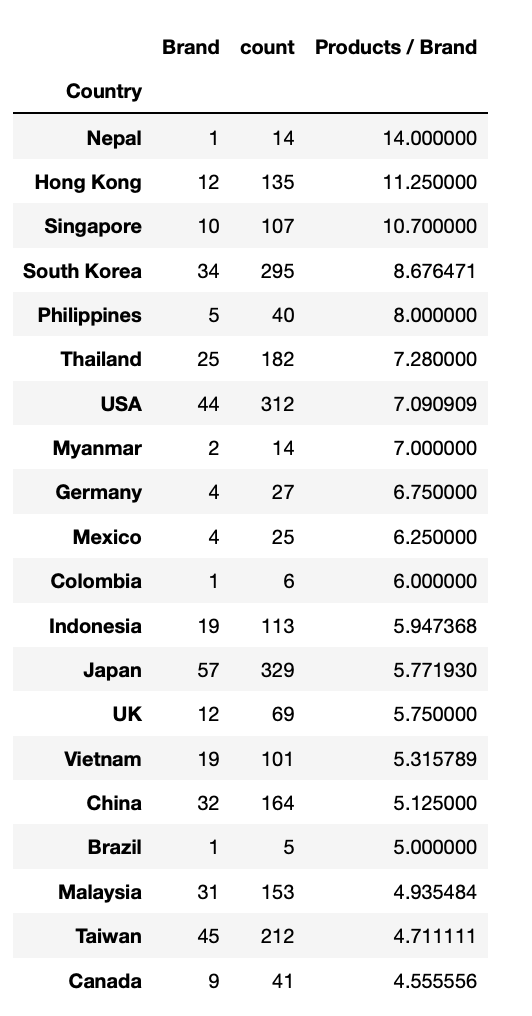
見ての通り、予想と外れましたw
こんな感じで疑問を持って、それを確認するためにデータを弄って見るというのがデータ分析の基本になります。
疑問なしでただデータを見ていると、自分がどこに向かっているのかがわからなくなってしまいますw
ちなみにみた感じだと、人口や経済規模(市場規模)に比例して商品数やブランド数が増えていそうな感じがしますね。
当然といえば当然ですがw
Style × Country
次にStyleとCountryで見ていきます。
ここで確認したいのが、国ごとに得意分野が違うのではないかということです。
Trayだと日本の圧勝だけど、Packでは日本はぼろ負けみたいな状況もありえるかもしれないので確認してみます。
Cup
まずはCupです。

該当商品数のブラジルやミャンマーは除くと香港が一番ですね。
日本は4番目です。
Pack
次にPackです。
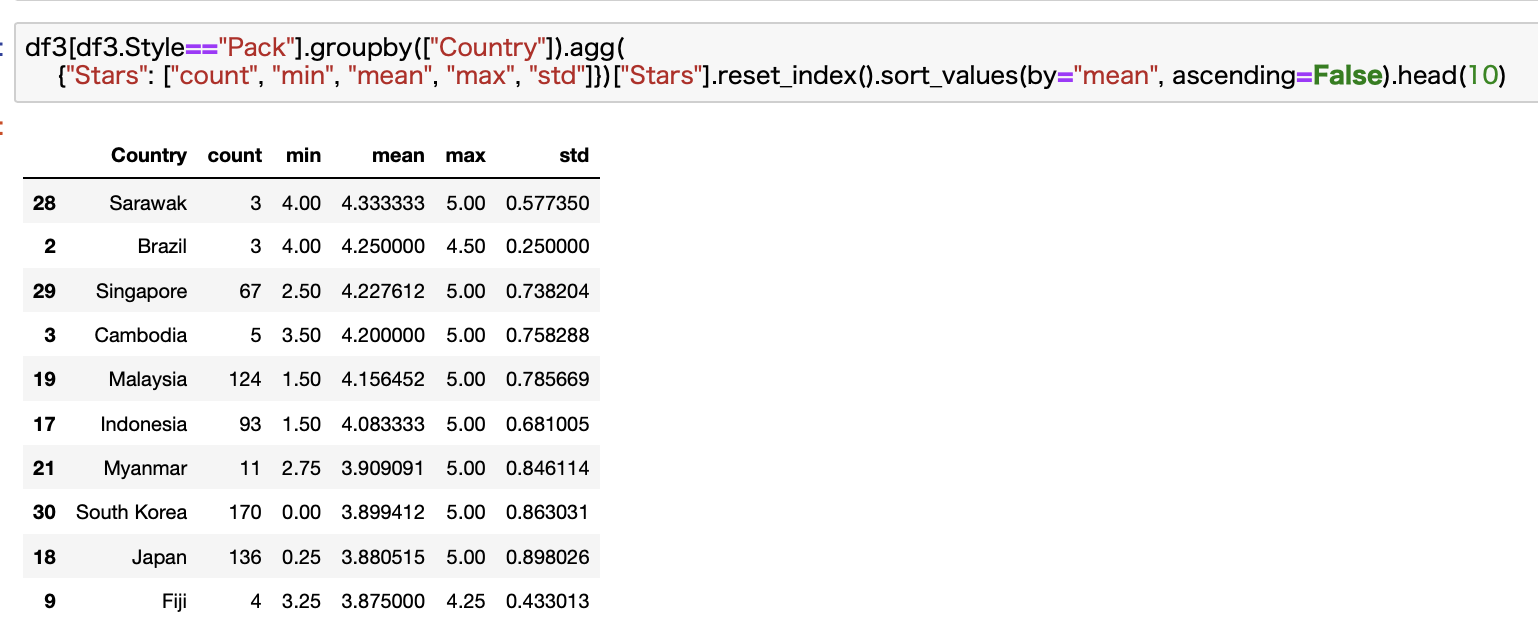
商品数を考慮するとシンガポールが一番ですね。
日本は結構低い・・・
Bowl
お次にBowlです。
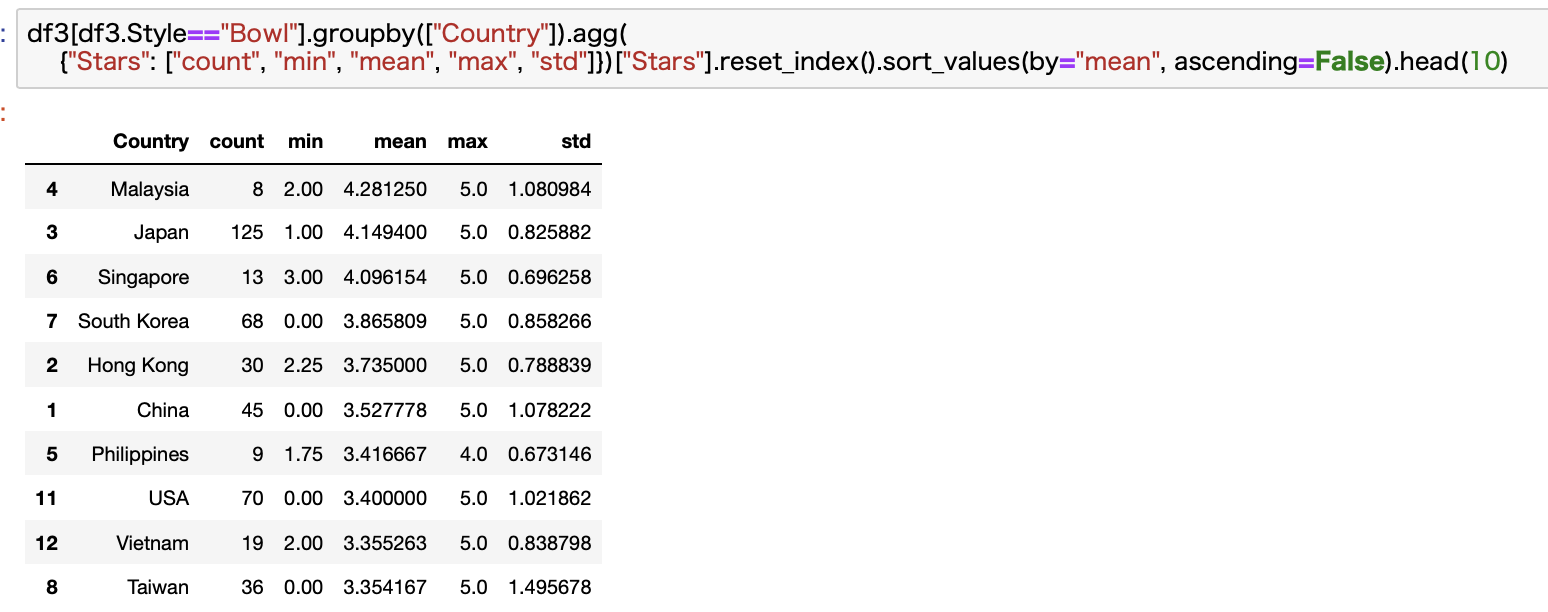
ついに来ました。
商品数も断トツで、点数も2位につけています。
マレーシアは商品数が少ないので、日本がNo.1といってもいいかもですね。
Tray
最後にTrayです。
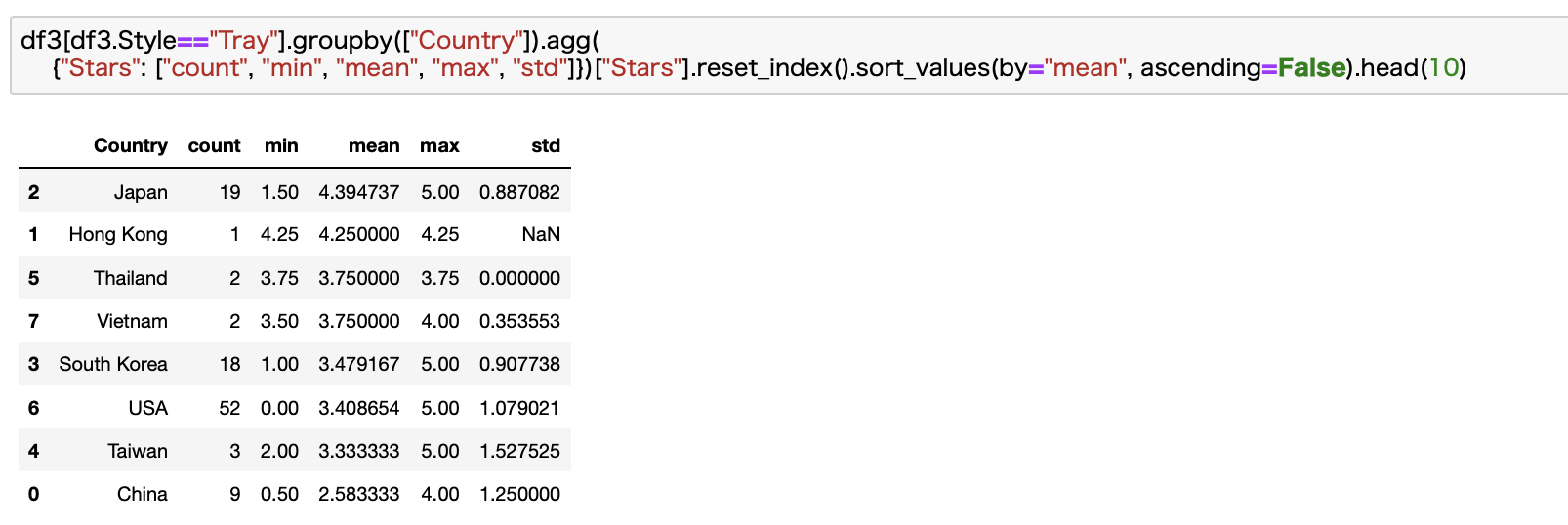
やりました。商品数、点数共に日本が圧勝です。
Japanのソウルフード「Yakisoba」を舐めないでいただきたいですねw
想像通り、Trayは日本の圧勝でした。
それでもそのほかのStyleでは日本よりも点数の高いものが色々とありましたね。
いつか試食してみたいものです。
複数カラムの集計はこれくらいにしておきたいと思います。
もしご興味があれば、ここで紹介している記事を参考に色々と集計してみてください。
面白い発見があるかもしれません。
一応、「Top Ten」カラムも見る
最後にここまでずーっと無視されていた「Top Ten」カラムについてみておこうと思います。
何も触れずに終わるのはかわいそうですからねw
Top Tenに該当するデータが、最初のデータ整形で排除されてしまったものがあったので、ここではOriginalデータであるdfを使います。
まずは値を確認します。
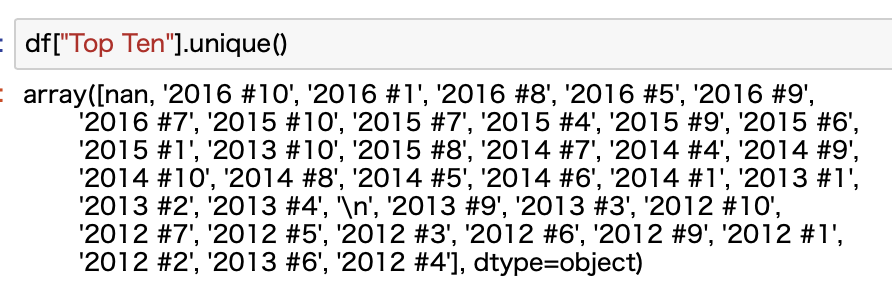
これを見ると2012年〜2016年の各年のTop Tenがあるようです。
Kaggleを見ると、このデータは3年前のものとなっているので、2017年か2018年のものになります。
当時の過去5年分のデータということになりますね。
年と順位を分割する
まずは集計の利便性を考慮して年と順位を分割しておきます。
これにはapply関数を使って、カラム単位で一気に処理します。
ついでに上のデータを見ると、nan以外に\nという謎データもあるのでこれをnanに変換します。
ちなみにこれは改行を意味するコードです。
# \nをnanに変換
df["Top Ten"] = df["Top Ten"].replace("\n", np.nan)
# 年を抽出
df["Year"] = df["Top Ten"].apply(lambda x: x.split(" ")[0] if isinstance(x, str) else x)
#順位を抽出
df["Rank"] = df["Top Ten"].apply(lambda x: x.split("#")[1] if isinstance(x, str) else x)
ここではsplit関数を使ってデータを分割して抽出しましたが、このほかにもreを使って正規表現を利用して抽出するやり方とかもあります。
ここは人によって好みが分かれるかと思います。
ちなみにreを使う場合はこんな感じです。
import re
# \nをnanに変換
df["Top Ten"] = df["Top Ten"].replace("\n", np.nan)
# 年を抽出
df["Year"] = df["Top Ten"].apply(lambda x: re.findall(r"[0-9]{4}", x)[0] if isinstance(x, str) else x)
#順位を抽出
df["Rank"] = df["Top Ten"].apply(lambda x: re.findall(r"#([0-9]{1,2})", x)[0] if isinstance(x, str) else x)
結果こんな感じになります。
Top Tenデータを集計する
次にTop Tenデータを集計します。
"Unrated"になってるStarsをNaNに変換した上で集計しています。
Country
まずはCountry別で見てみます。
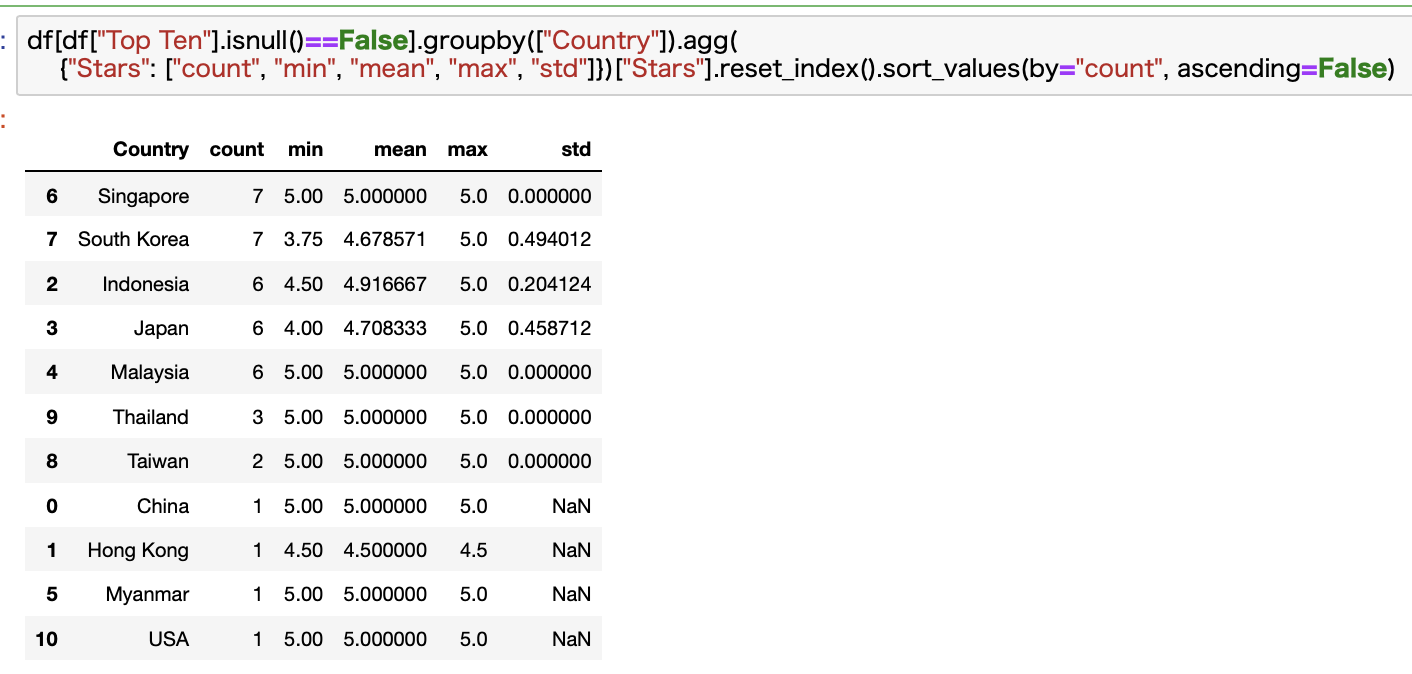
1位は同点でシンガポールと韓国ですね。
韓国のインスタントラーメンもレベルがかなり高いですよね。
辛ラーメンとか日本でも人気の商品も多いですね。
日本も健闘しています。
Brand
次にBrand別で見てみます。
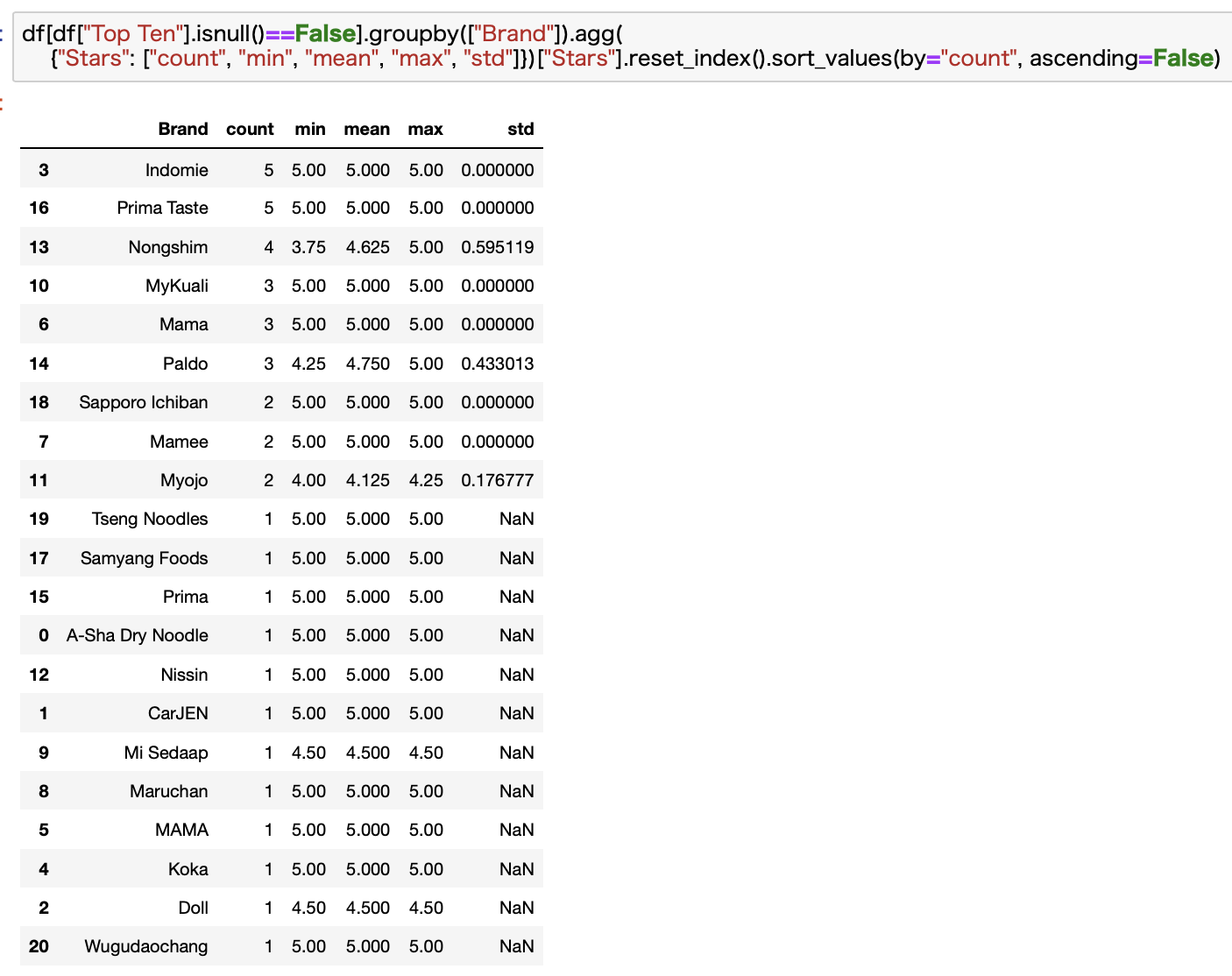
残念ながら日本のメーカーはあまり目立っていませんね。。。
Style
最後にStyleです。

Packが圧倒的ですね。
これは商品数も多いので当然の結果かなと思います。
以上でデータ分析は終了です。
今更ですが、reset_index()の位置がおかしいw
ここでお知らせです。
ここまで紹介したコードのreset_index()の位置がおかしいんですね。
この記事を書いてる終盤で気づきましたw
もうしんどいのでこのままいきますw
上記のやり方だと、reset_index()の後にsort_index()をしているので、indexがバラバラになってしまいます・・・
正しくはこうあるべきでした。
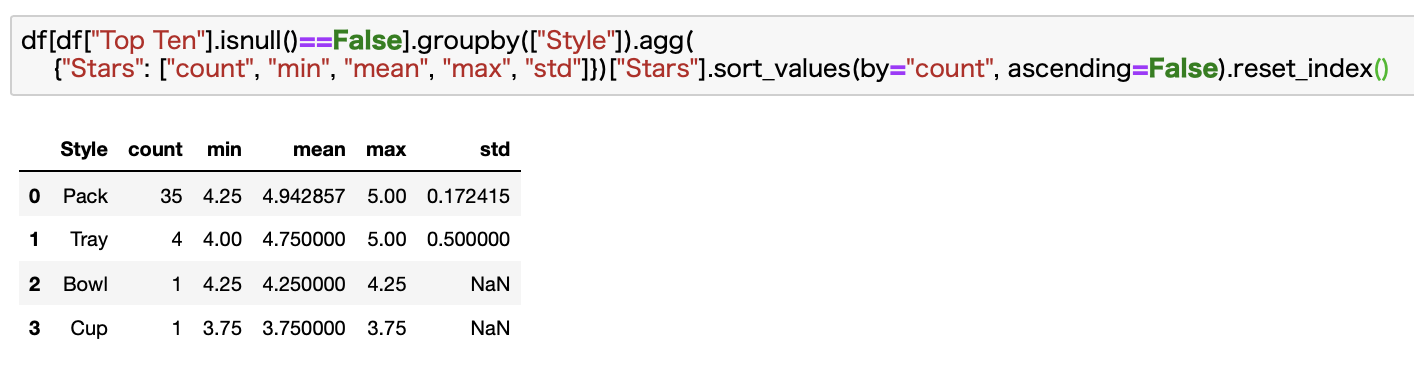
これならindexの順番が正しく振り直されていることがわかります。
ここまで紹介した全てのコードでこうするべきでした。すみません。
データ分析はPythonが最適です。
最後にこの記事で利用しているプログラミング言語であるPythonについて紹介させてください。
この記事で紹介しているコードは全てPythonで書かれています。
Pythonは初心者にも学びやすい
ここまで紹介してきたように、Pythonを使うと複雑な計算処理もシンプルなコードで一瞬で計算することができます。
Pythonはデータ分析やAI関連に強くて、世界中で人気を集めている言語です。
すっきりとしたコード体系で、誰でもきれいなコードが書けるような設計になっています。
過去の記事では、データ分析としてPythonをご紹介している記事や、Pythonでできることをまとめたものがありますので、もしPythonにご興味があれば合わせてご覧ください。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
データ分析に関する記事を発信しています
Pythonを使った様々なデータ分析について発信しています。
本記事の他にもデータ分析に関する記事を書いているので、もしご興味があれば合わせて読んでくださると嬉しいです。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
-

最近話題になったジャニーズグループの歌詞を歌詞化してみました!
Pythonのコード解説記事も増やしています
さらに最近はPythonのコード解説記事も増やしているので、Pythonを学んでいる方のお役に立てれば幸いです。
-

【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
-

【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
ちなみにこの記事で多用しているgroupby関数の使い方については、過去記事でポケモンのデータを使って解説しています。
-

【Pythonコード解説】Pythonでポケモンのデータセットを集計する
まとめ
いかがでしたでしょうか。
今回はKaggleで発見したインスタントラーメンのデータを分析してみました。
データ自体はそこまで大きなものではなかったので、あまり突っ込んだ分析はできませんでしたが、それでも色々な方法で集計したり可視化したりすると様々なことが見えてきます。
Kaggleにはこのようなデータセットがたくさんあります。
ここから面白そうなデータを見つけて自分で分析するととても良い勉強になります。
色々な人のコードも見ることができるので、パクりながら学ぶことも可能です。
ただし、サイトは英語なので英語が苦手だと苦労するかもです。
過去記事でも紹介しましたが、プログラミングを学ぶには英語ができると強いです。
-

【経験談あり】プログラミング学習者が英語を学ぶべき理由!【メリットばかりです】
今回もかなり記事が長くなってしまいました。
データ分析系の記事になるとどうしても長くなってしまいますねw
ここまで読んでくださりありがとうございました。




{kind=link}