
こんにちは。TATです。
今日のテーマは「Pythonによるデータの可視化」です。
ここでは過去記事でも登場しているポケモンのデータセットを使って、Pythonによるデータの可視化について解説していこうと思います。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-

【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
-

【Pythonコード解説】Pythonでポケモンのデータセットを集計する
データの集計や加工に慣れてきたら、次に行うべきはグラフなどによるデータの可視化です。
数字の羅列だけではわからないことでも、可視化するとたくさんの発見があります。
ここではPythonの代表的な可視化ライブラリーであるmatplotlibとseaborn(ほとんどseabornになってしまったw)を使った可視化を解説していこうと思います。
目次
【Pythonコード解説】Pythonでポケモンのデータセットを可視化する

ここではグラフの種類別に、こちらの記事でも紹介したグラフを描くためのコードを解説していきます。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
(おさらい)ポケモンのデータセットの確認
データはKaggleから
まずはさくっと今回利用するポケモンのデータセットについておさらいしておきましょう。
データ元はKaggleです。
Pokemon with statsから今回利用するデータをダウンロードすることができます。
ダウンロードするには無料の会員登録が必要なのでご注意ください。
Kaggleはデータ分析のコンペを運営しているサイトで、あるデータが与えられて、それを参加者が分析して結果を競い合います。
優勝者には、賞金が贈られたり、開催企業の就職面接を受ける権利などが与えられます。
GoogleやFacebook、日本企業ではメルカリなどもKaggleによるコンペを企画しています。
さらに他の参加者のコードも見ることができるので、分析手法はコードの書き方を学ぶ場としても最適です。
-

プログラミングを爆速で習得する方法【経験談あり】
Kaggleは基本英語です
Kaggleを利用するにあたって一つ壁となるのが、英語サイトであるということです。
アメリカで始まったサービスなので基本的は全て英語になります。
ゆえに、ここで入手できるポケモンのデータセットも英語です。
英語であるということで躊躇してしまうこともあるかもですが、英語ができるとプログラミングスキルを高めるチャンスは広がります。
特に最先端の話題は英語で発信されるので、これができると最新情報をいち早くキャッチすることができ、周囲と差をつけることができます。
また、英語ができると、プログラムを書いて問題にぶち当たった際に、簡単に解決策を見つけられることもよくあります。
と言いますのも、日本語ではググってもなかなか出てこない情報でも、英語でググるとあっさりと見つかってしまうケースが多々あるためです。
英語の方が情報量としては圧倒的に多いので、英語で検索した方が見つかる可能性は高いです。
よって、英語ができると色々な面で重宝します。外資系に転職できたら年収アップと働きやすい職場環境も狙えますw
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
取得データの確認
さて、少し話が逸れましたが、ここで利用するデータを確認します。
ダウンロードしたデータをPythonで読み込みます。
冒頭の5行だけ表示するhead関数を使ってデータを確認します。
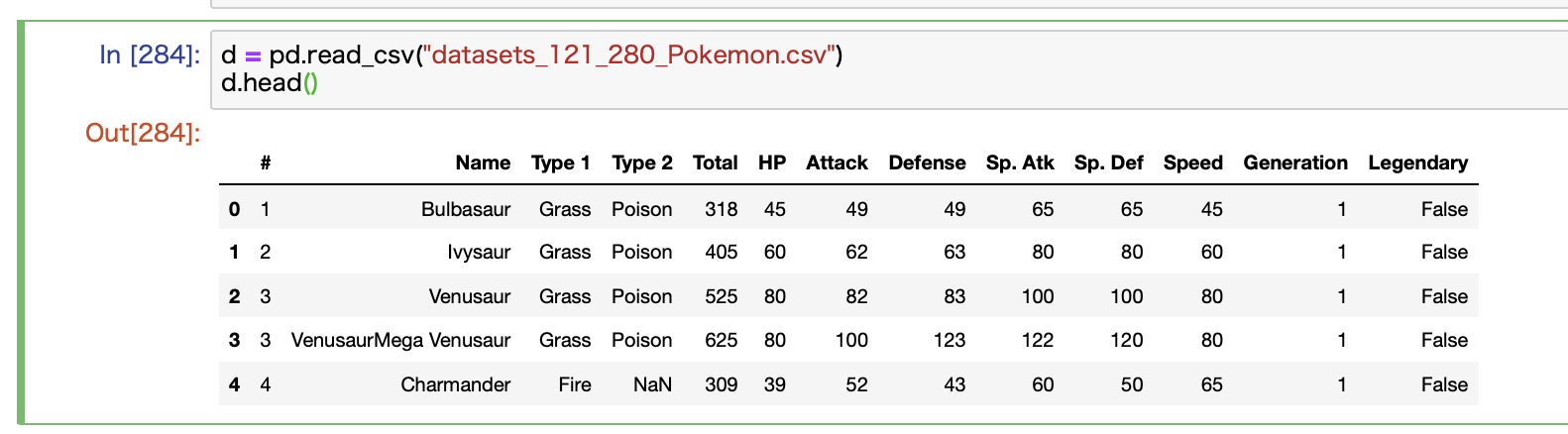
これだと名前が英語でさっぱりわからないので、こちらの記事で紹介しているように英和辞書を作って日本語に変換します。
-
【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
さらに日本語に変換できないメガ進化とかのポケモンを取り除いたデータを利用することにします。
出来上がったデータがこちらです。
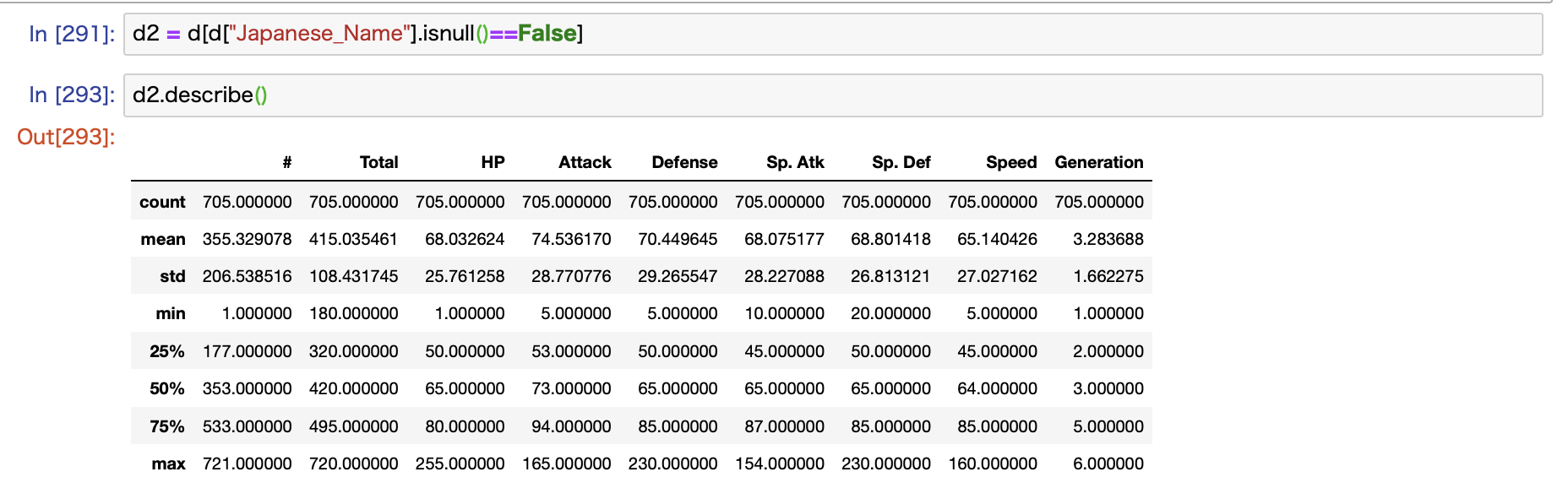
こちらのデータを使って、様々な可視化方法について解説していきます。
データ全体を把握できるpairplot
まずはデータの全体を把握します。
とりあえずデータを分析するとなると全体を把握することから始めます。
可視化せずともdescribe関数などを使えば全体の傾向は把握できますが、可視化した方が直感的に理解することができます。
各カラムのヒストグラムと相関を1発で表示
これにはseabornのpairplotが便利です。
ワンコマンドでデータ全体を把握することができます。
import seaborn as sns sns.pairplot(d2)
コードはこれだけです。
基本的に、seabornをimportする際にはsnsという名前を使います。
これで表示されるデータがこちらです。細かくてすみません。

ちなみにpairplotを使う際にはデータサイズによっては表示まで少し時間がかかります。
各カラムごとの相関を把握することができ、さらに各カラムのヒストグラムを確認することができます。
当然ながら、数値データ以外は表示されません。
なので、ここで狙ったカラムが表示されていない場合にはデータの型をチェックしてみてください。
このデータを眺めて、「〇〇と△△の相関が強そうだ。調べてみようかな」みたいな感じで、どこから攻めていくのか目星をつけたりしていきます。
ヒストグラムはカーネル密度推定に変更できます
先ほど表示されていたヒストグラムは変更できます。
diag_kindという引数を使えば、例えばカーネル密度推定に変更することもできます。
import seaborn as sns sns.pairplot(d2, diag_kind= 'kde')
こちらで表示されるグラフはこちらになります。
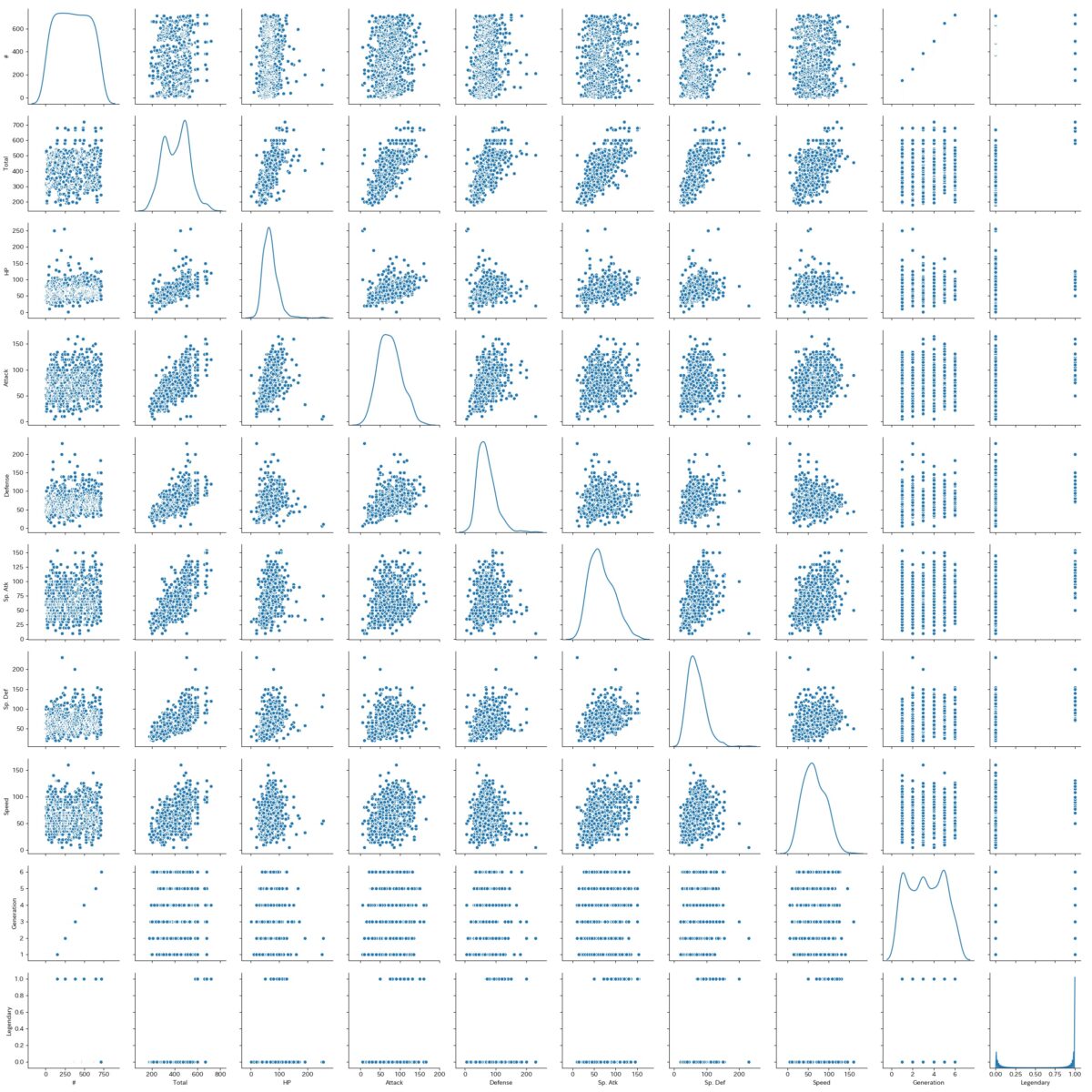
ヒストグラムの部分がカーネル密度推定に変更されていることがわかります。
hueでグルーピングする
最後にhueという引数についてもご紹介しておきます。
これはhueに指定したカラムの値ごとにグループ分けして集計してくれる機能になります。
例えば、hueに伝説のポケモンを示すLegendaryを指定してみます。
import seaborn as sns sns.pairplot(d2, hue= 'Legendary')
これで表示されるグラフがこちらです。

オレンジが伝説のポケモン、青色がそれ以外を示します。
こう見ると、伝説のポケモンとそれ以外のポケモンの比較が簡単にできます。
とりあえず伝説のポケモンめっちゃ強いことがわかりますね。
他にも色々なカスタマイズができます
ここではpairplotのdiag_kindやhueについてご紹介しましたが、この他にもたくさんのカスタマイズが可能です。
ここでは紹介しきることはできませんが、公式サイトを見るとたくさんの情報が見つかります。
ただ、基本的に公式サイトは英語なので、ここでも英語ができると有利です。
Google翻訳を使ってもある程度の理解はできます。
公式サイトはこちらに貼っておくので、もしご興味があればのぞいてみてください。
heatmapで相関係数を可視化する
次に相関係数を1発で可視化できるheatmapについてみていきます。
corr関数で相関係数を計算する
Pandasではカラムごとの相関係数が計算できるcorr関数というものがあります。
こんな感じです。
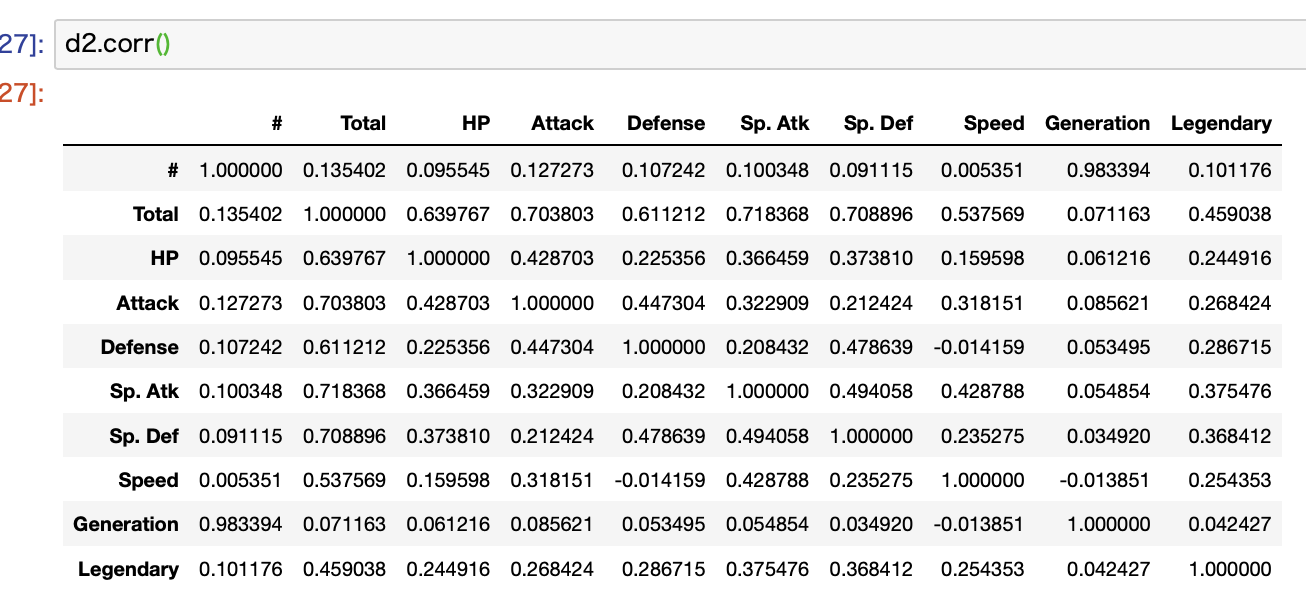
プラスであれば正の相関、マイナスであれば負の相関を意味します。
ただ-0.5~0.5だと相関は低いので無視です。0.7以上、-0.7以下だと強い相関と判断します。
ただ、先ほど見たpairplotでは伝説のポケモンが圧倒的に強いことがわかるのに、相関で見るとそうでもないことがわかります。
これはデータ数があまりにも違うためです。
そういう意味では、やはり可視化しないと見えてこない部分もあるので、双方で確認することが重要になります。
この辺は人によって感覚は変わってきますので、データを見ながら判断していただければと思います。
seabornのheatmapが便利
上記のデータを見ると、数字の羅列だけになるのでなかなかわかりづらい部分もあります。
これをより見やすくするにはヒートマップで可視化するのがおすすめです。
seabornだとheatmapを1発で作成することができます。
import seaborn as sns fig = plt.figure(figsize=(20,10)) sns.heatmap(d2.corr())
これで表示される図がこちらです。
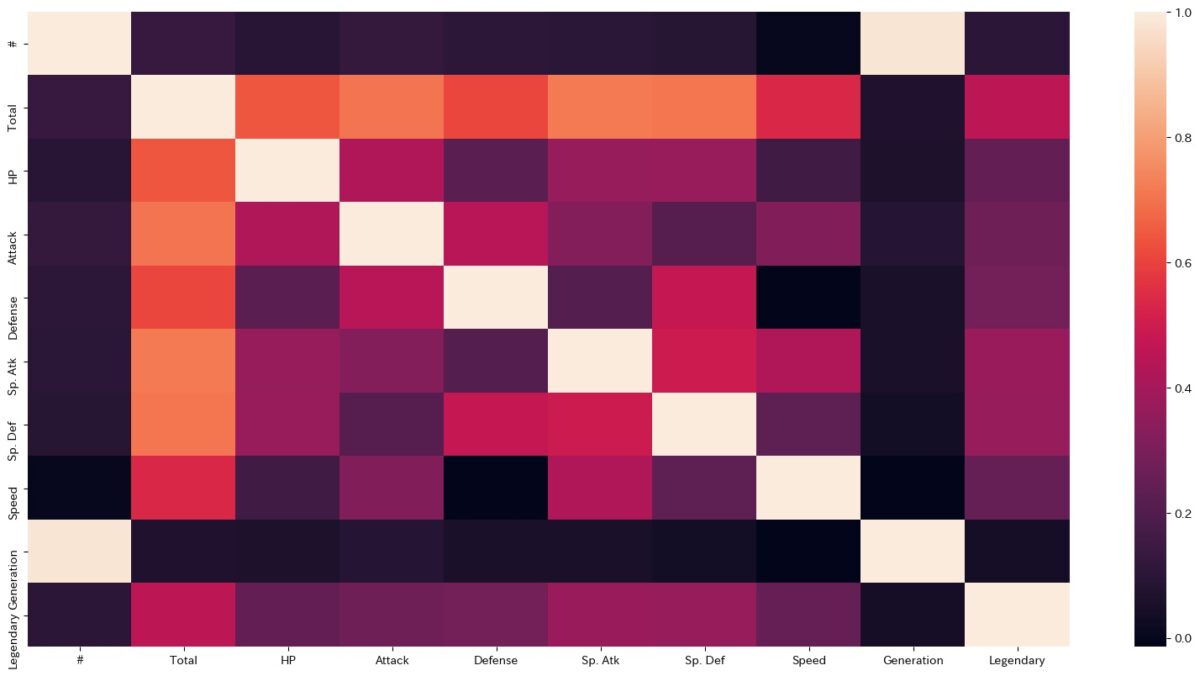
色の濃淡で相関係数の強弱を表しています。
これなら関係性が一目でわかりますよね。
それぞれの相関係数を表示する
ここでは便利な引数として1つだけannotをご紹介しておきます。
これをTrueとするとヒートマップを生成した上で相関係数も表示されます。
fig = plt.figure(figsize=(20,10)) sns.heatmap(d2.corr(), annot=True)
生成される図がこちらです。
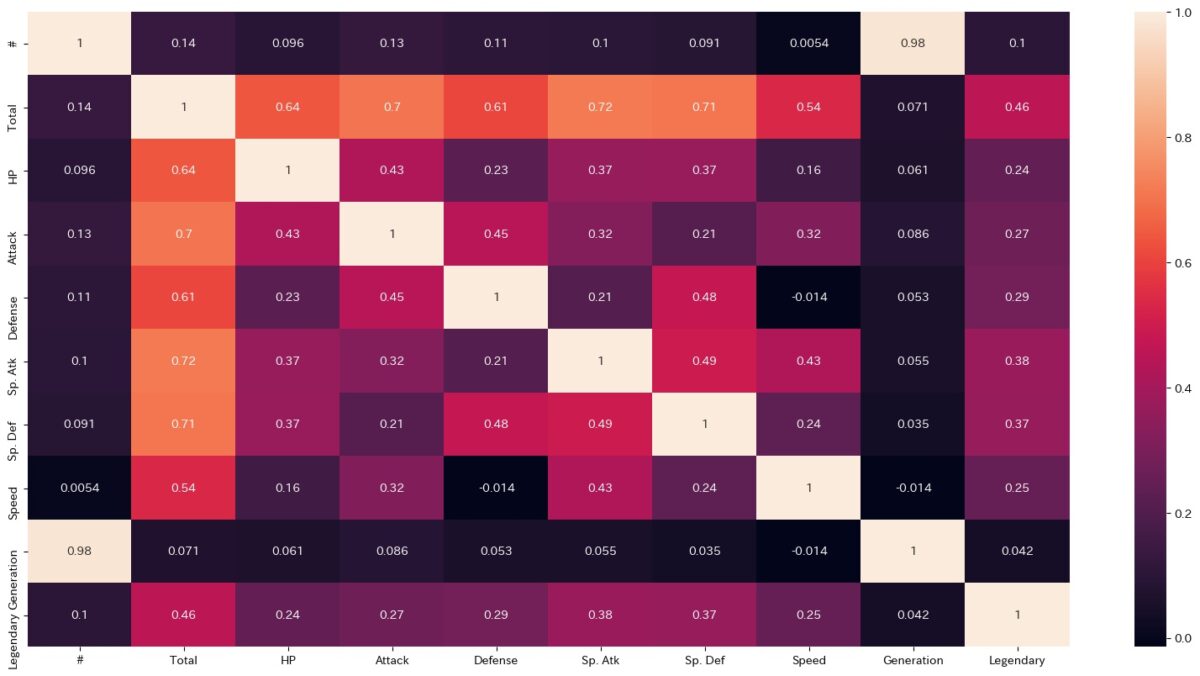
明らかにこちらの方がわかりやすいですよね。
基本的に、seabornを使ってheatmapを生成する際には、常にannotをTrueにしておくことをおすすめします。
その他も便利は引数がたくさんあるので、気になる方は公式サイトをのぞいてみてください。
カラムを指定してヒストグラムを描画する
次に各カラムごとにデータを可視化する方法をみていきます。
ヒストグラムをみてみます。
データのばらつきとか構成を見るにはヒストグラムが最強です。
describe関数で平均とか標準偏差などを見た上で、さらにヒストグラムを確認するとデータの特徴が見えてきます。
ここでは総合的な能力値を示すTotalカラムを見てみます。
describe関数で基礎的な統計値を確認
まずは可視化の前に基礎的な統計値を確認しておきましょう。
describe関数を使えば一瞬です。
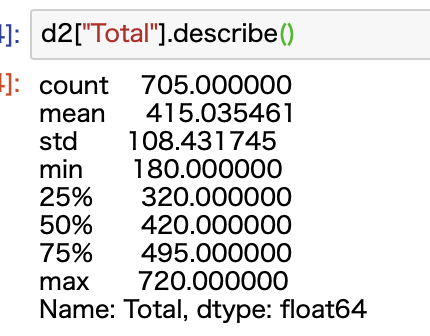
データの個数や平均値などが表示されています。
これでデータの雰囲気をつかみます。
seabornのdistplotでヒストグラムを見る
次にヒストグラムを描きます。
これにはseabornのdistplotを使います。
import seaborn as sns sns.distplot(d2["Total"])
ちなみにここでは毎回import seaborn as snsを書いてますが、一回書いちゃえばその後は記載しなくてもOKです。
これで表示されるグラフがこちらです。
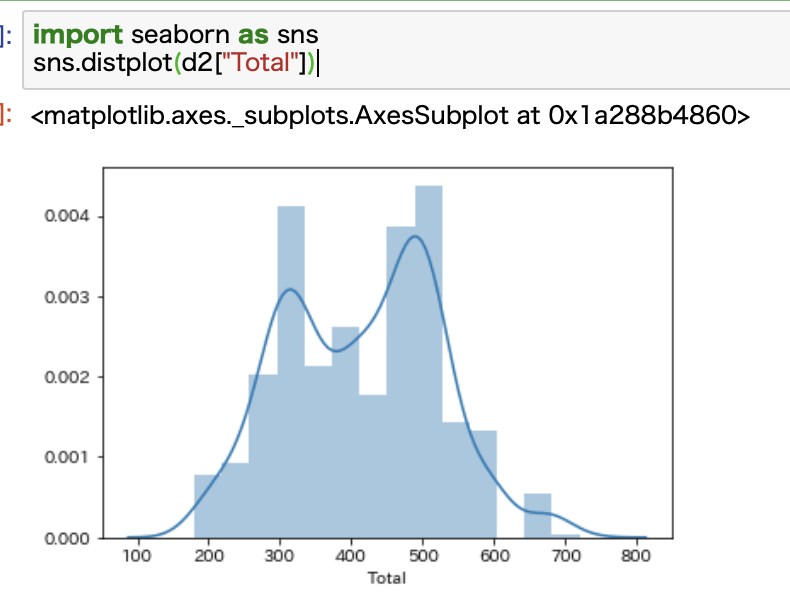
カーネル密度推定も一緒に表示されていることがわかります。
カーネル密度推定を非表示にする
このカーネル密度推定は非表示にすることも可能です。
これにはkde=Falseという引数を追加します。
import seaborn as sns sns.distplot(d2["Total"], kde=False)
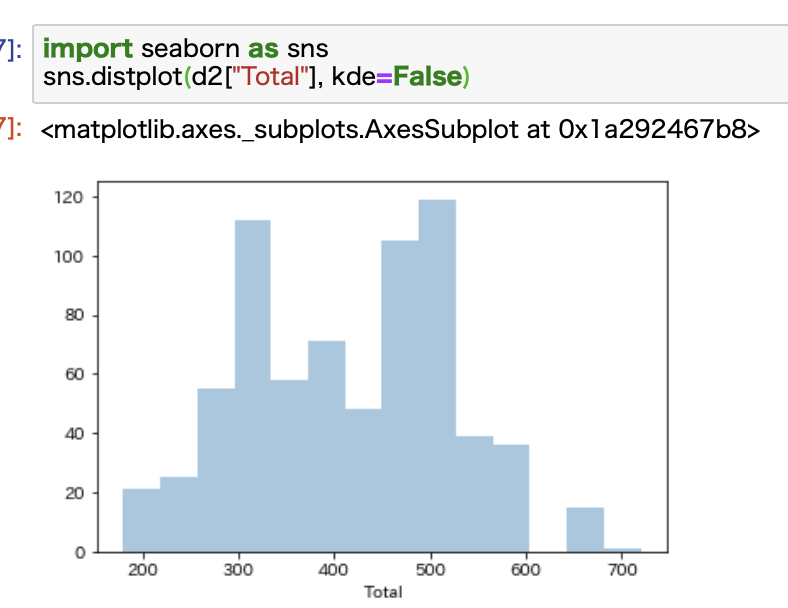
binsで粒度を調整する
もう一つ便利な引数をご紹介しておきます。
それがbinsです。
これを使うとデータの粒度を設定することができます。
上の図だと結構ざっくりしていますよね。
binsを使えばさらに細かく表示したり、さらに荒くしたりすることができます。
例えば、binsを50に指定するとこんな感じになります。
import seaborn as sns sns.distplot(d2["Total"], bins=50)
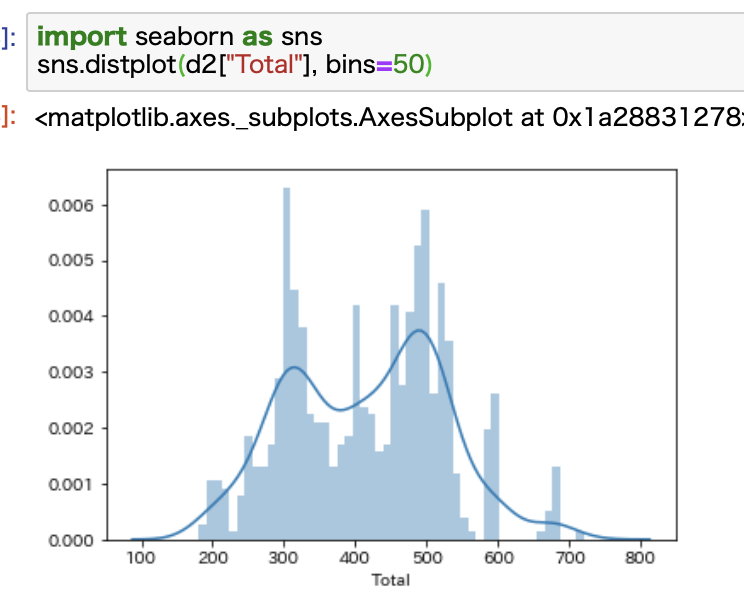
ご覧の通り、データがかなり細かくなっていることがわかります。
ヒストグラムのデータが荒すぎるあるいは細かすぎる場合には、binsで調整しましょう。
Type 1のデータの要素数を棒グラフで表現する
次に棒グラフを描いてみます。
これにはType 1のデータの要素数を使ってみます。
value_countsでデータの要素数を集計する
データの要素数を集計するにはvalue_counts関数を使います。
Type 1で使うとこんな感じになります。

各タイプの個数が1発で集計できます。
matplotlibで棒グラフ(barh)を描く
次にこのデータを棒グラフで描画します。
これにはmatplotlibのbarhグラフを利用します。
通常はbarを使いますが、barhだと横向きの棒グラフになります。
ここでは棒グラフの描き方を2つご紹介します。
どちらのやり方でも棒グラフが描けます。
import matplotlib.pyplot as plt # 方法1 d2["Type 1"].value_counts().plot(kind="barh", figsize=(10,5)) # 方法2 fig, ax = plt.subplots(figsize=(10, 5)) ax.barh(d2["Type 1"].value_counts().index, d2["Type 1"].value_counts())
ただ見え方には少し違いがあります。
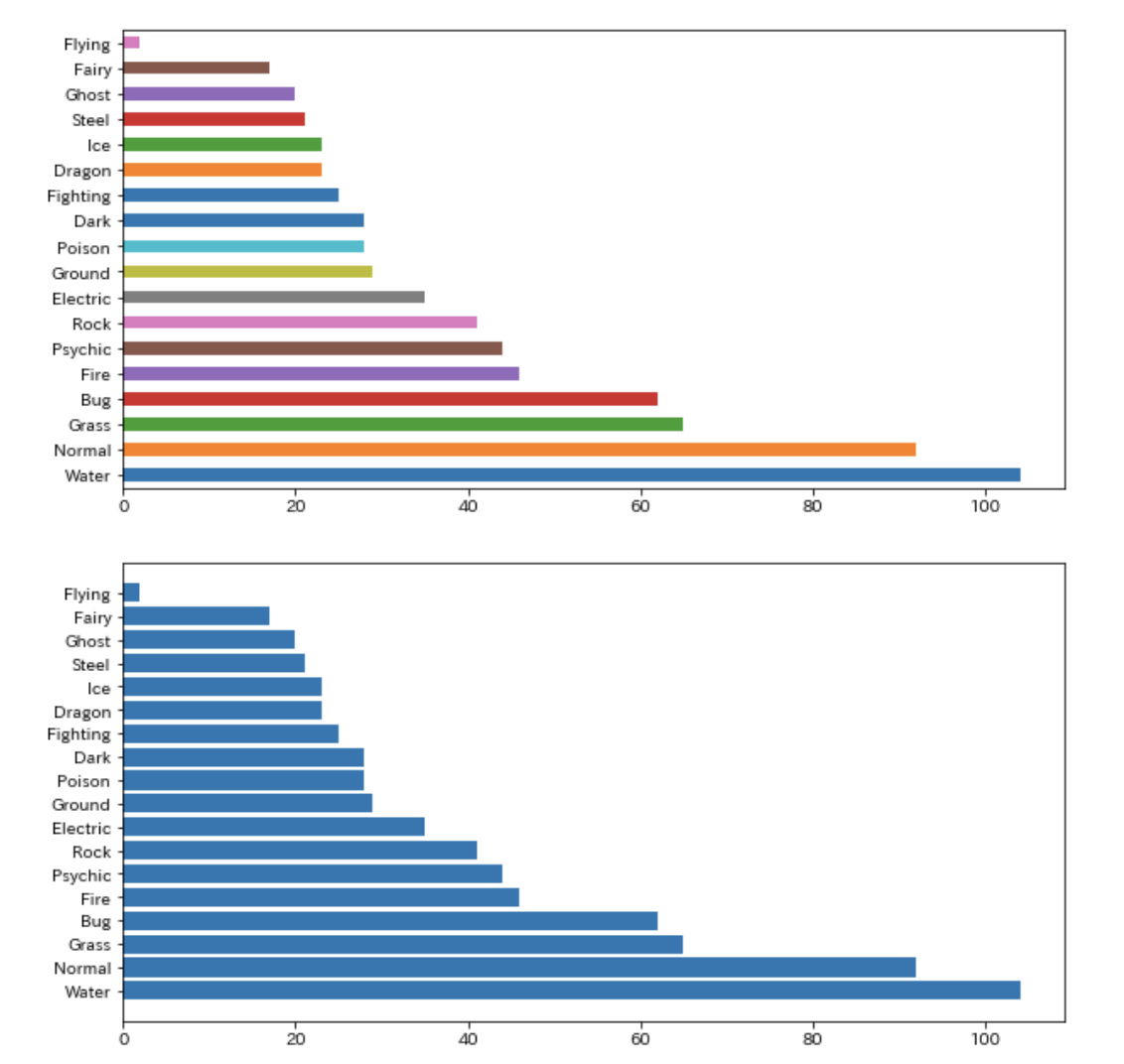
色(color)や幅(width)を調整する
前者はカラフルになりますが、後者はブルーになります。
これは仕様の問題なのでいくらでも調整可能です。
どちらもcolorとwidthを調整すれば同じになります。
import matplotlib.pyplot as plt # 方法1 d2["Type 1"].value_counts().plot(kind="barh", figsize=(10,5), color="blue", width=0.8) # 方法2 fig, ax = plt.subplots(figsize=(10, 5)) ax.barh(d2["Type 1"].value_counts().index, d2["Type 1"].value_counts(), color="blue")
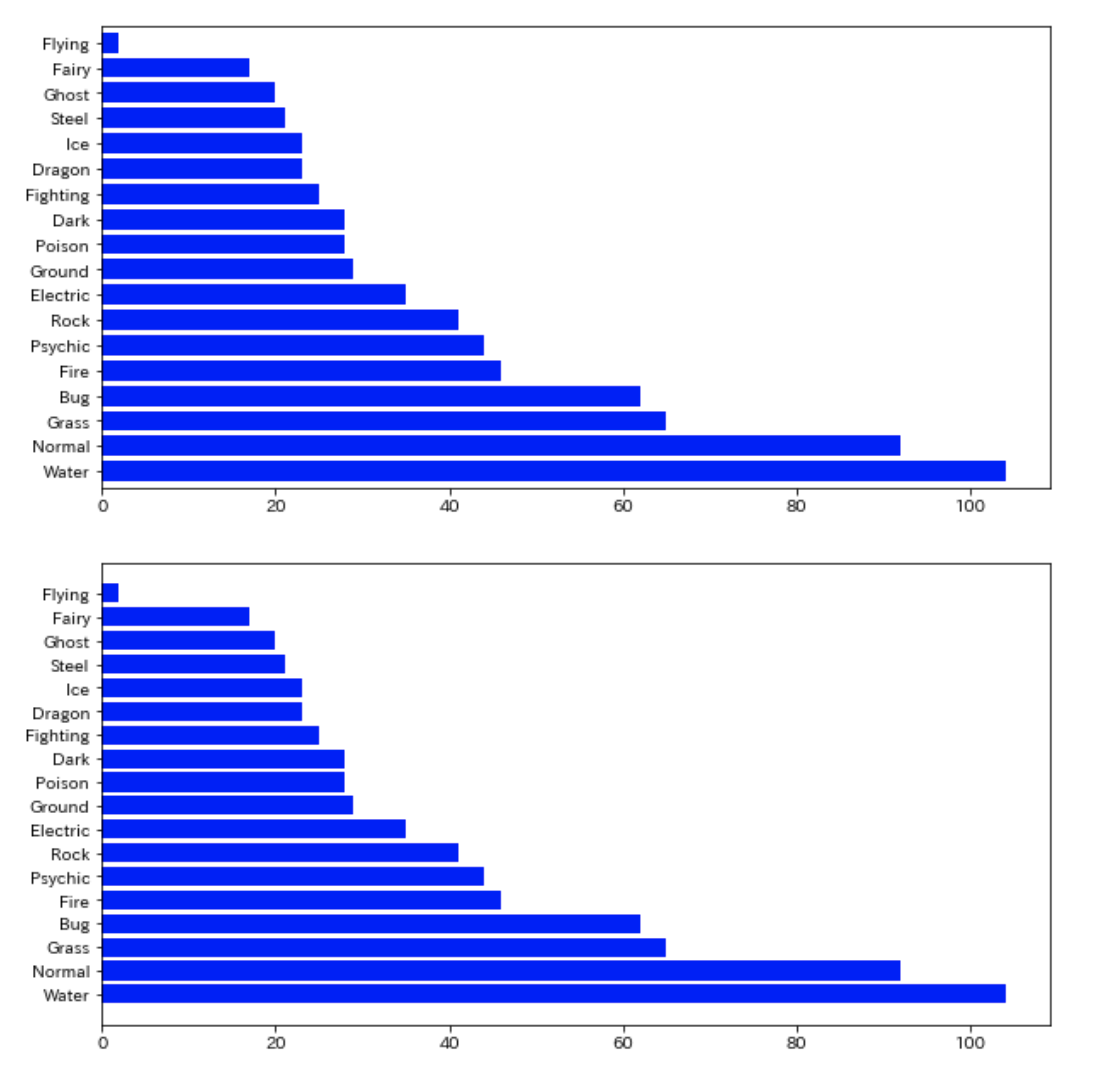
この辺は好みなので好きなように編集してください。
どちらの書き方でもOKです。
boxplotでType 1ごとのばらつきを可視化する
次に少しレベルアップしてboxplotを見てみます。
これはdescribe関数で表示される中央値や最小値、最大値、中央値などを可視化できるグラフです。
boxplotを使えばデータのばらつき具合をイメージすることができます。
boxplotでTotalをType 1ごとに描く
boxplotを描くのはとっても簡単です。
seaborn.boxplotを使えば一瞬で完成します。
コードはこんな感じです。
import seaborn as sns plt.figure(figsize=(20,10)) sns.boxplot(data=d2, y="Total", x="Type 1", color="orange")
dataを指定して、あとはxとyにカラムを指定すればOKです。
デフォルトだとカラフルになってしまうので、colorをorangeに指定してみました。
これで得られるグラフがこちらです。
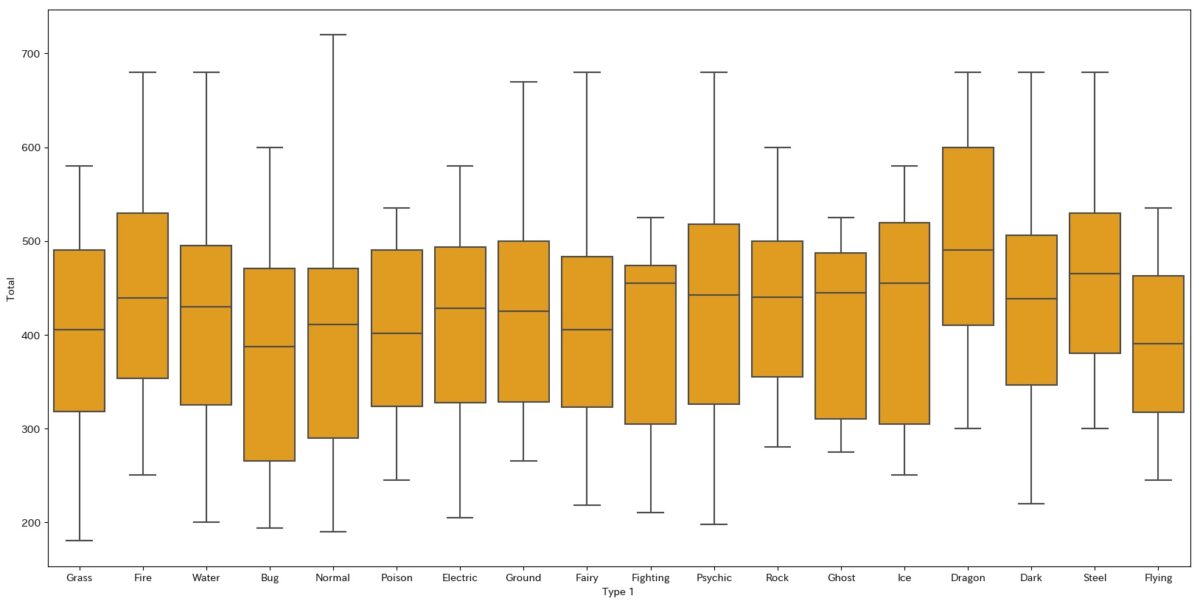
一番下と上がそれぞれ最小値と最大値を示します。
ボックス内にある線は中央値です。
ボックスの上と下は第1四分位数と第3四分位数を示します。
このように、boxplotを使うとデータの構成をイメージすることができます。
hueでグルーピングする
次にpariplotでも登場したhueを使ってみます。
このboxplotでもhueは利用可能です。
Legendaryを指定してみます。
import seaborn as sns plt.figure(figsize=(20,10)) sns.boxplot(data=d2, y="Total", x="Type 1", hue="Legendary", color="orange")
これで得られるグラフがこちらです。
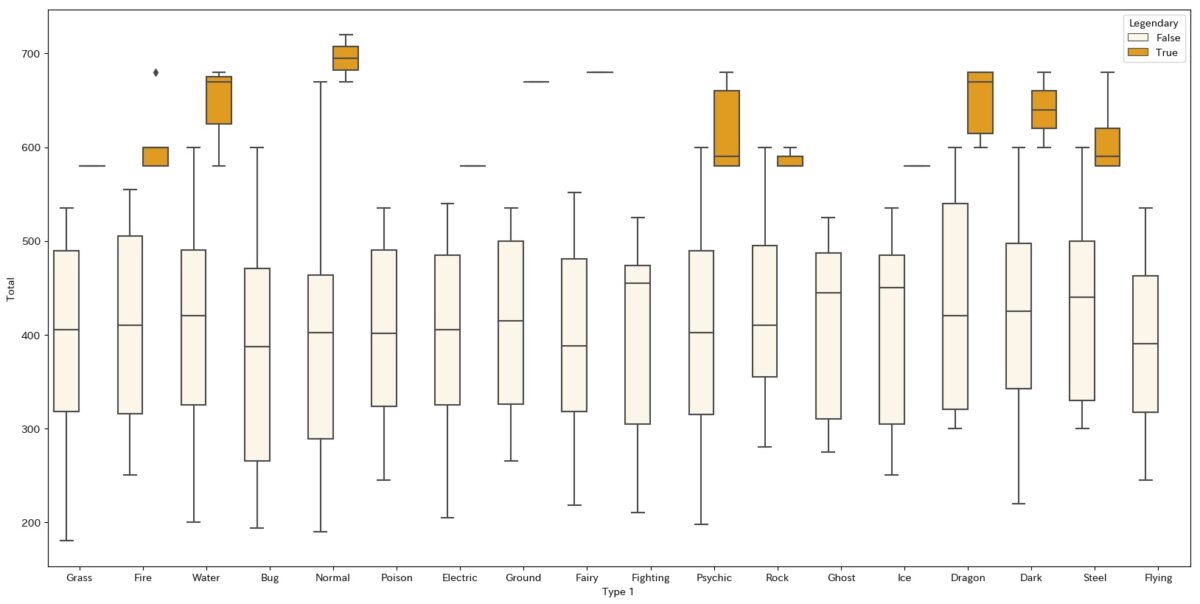
伝説のポケモンとそれ以外のポケモンで区別されていることが確認できます。
伝説のポケモンは数が少ないにで、boxplotで見るとスカスカになりますねw
stripplotあるいはswarmplotを組み合わせる
次にboxplotの弱点について触れておきます。
それが、データの分布が全く把握できないということです。
全体的な雰囲気はつかむことができても、ヒストグラムのようなイメージはつきません。
describe関数でわかることが可視化されただけになります。
この弱点を補うために複数のグラフを重ねるという必殺技があります。
ここではstripplotとswarmplotをご紹介します。
実際に見た方が早いかと思いますのでとりあえずお見せします。
stripplot
まずはstripplotです。
組み合わせるとこんな感じになります。
使い方はboxplotとほとんど同じです。
import seaborn as sns plt.figure(figsize=(20,10)) sns.boxplot(data=d2, y="Total", x="Type 1", color="orange") sns.stripplot(data=d2, y="Total", x="Type 1", color="blue")
出来上がるグラフがこちらです。
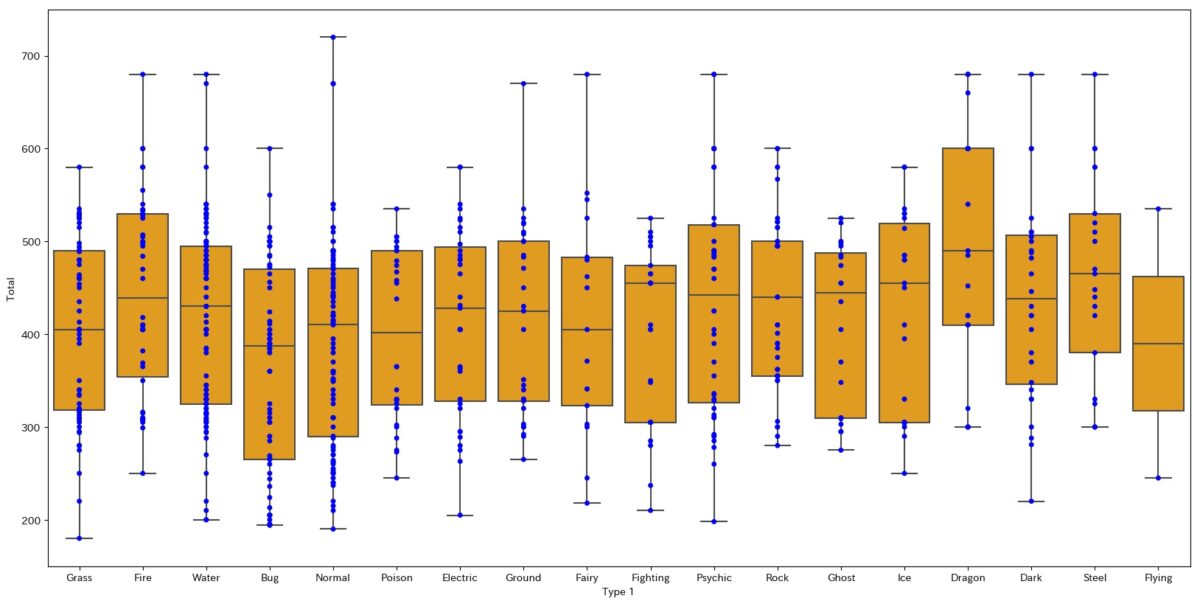
ご覧の通り、データの分布が表示されています。
点が密集している箇所はデータが多く存在していることを意味します。
これでヒストグラムを想像することができますよね。
stripplotと組み合わせることで、boxplotの弱点を補うことができます。
swarm plot
次にswarmplotです。
これもstripplotと似ています。
import seaborn as sns plt.figure(figsize=(20,10)) sns.boxplot(data=d2, y="Total", x="Type 1", color="orange") sns.swarmplot(data=d2, y="Total", x="Type 1", color="blue")
出来上がるグラフがこちらです。
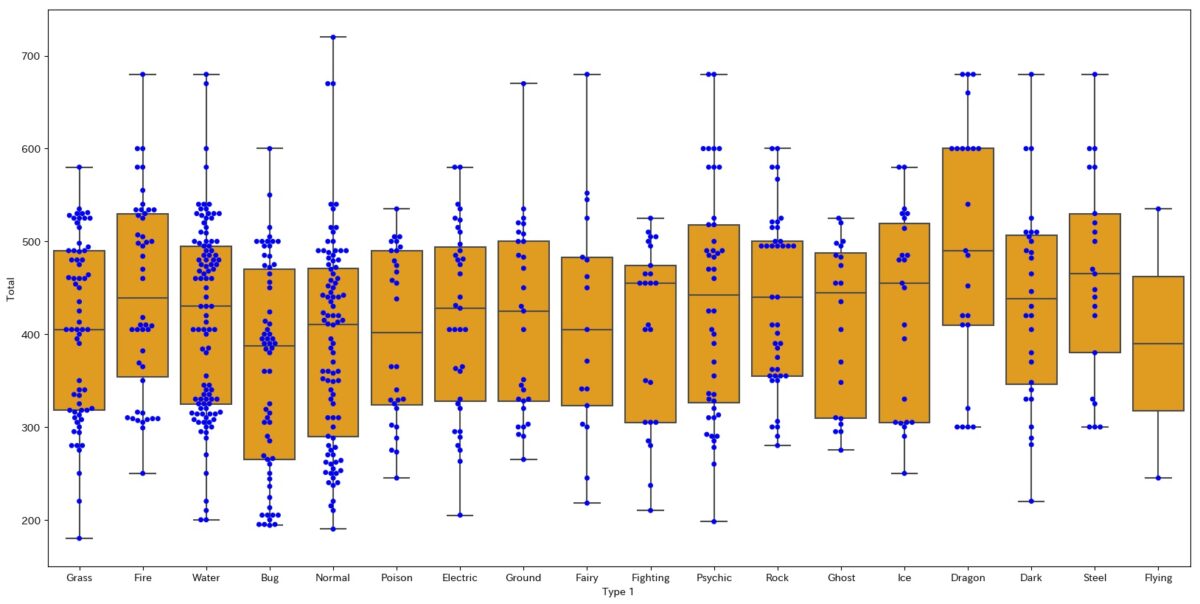
違いはデータが密集しているところが横に膨らんでいる点です。
stripplotだと直線上に表現されていましたが、swarmplotだと横に広がります。
どちらを使ってもboxplotの弱点を補うことができるので、これはもはや好みの問題です。
僕はすっきりと見えるstripplotを好んで使っています。
データの分布が可視化できるviolinplot
お次にboxplotとよく比較されるviolinplotについてご紹介します。
これはデータの分布をカーネル密度グラフで表現します。
seaborn.violinplotを使えば簡単に描くことができます。
Type 1ごとのTotalをviolinplotで描く
例として、boxplotでも登場したType 1ごとのTotalを可視化してみます。
import seaborn as sns plt.figure(figsize=(20,10)) sns.violinplot(data=d2, y="Total", x="Type 1", color="orange")
グラフがこちらです。

このようにアメーバみたいなグラフが描けます。
横に広がるほどデータ数が多いことを意味します。
四分位数を表示する
violinplotだと、boxplotで見えた四分位数がわからなくなってしまいますが、これを表示することも可能です。
inner="quartile"という引数をつけることで四分位数を表示できます。
import seaborn as sns plt.figure(figsize=(20,10)) sns.violinplot(data=d2, y="Total", x="Type 1", inner="quartile", color="orange")
グラフがこちらです。
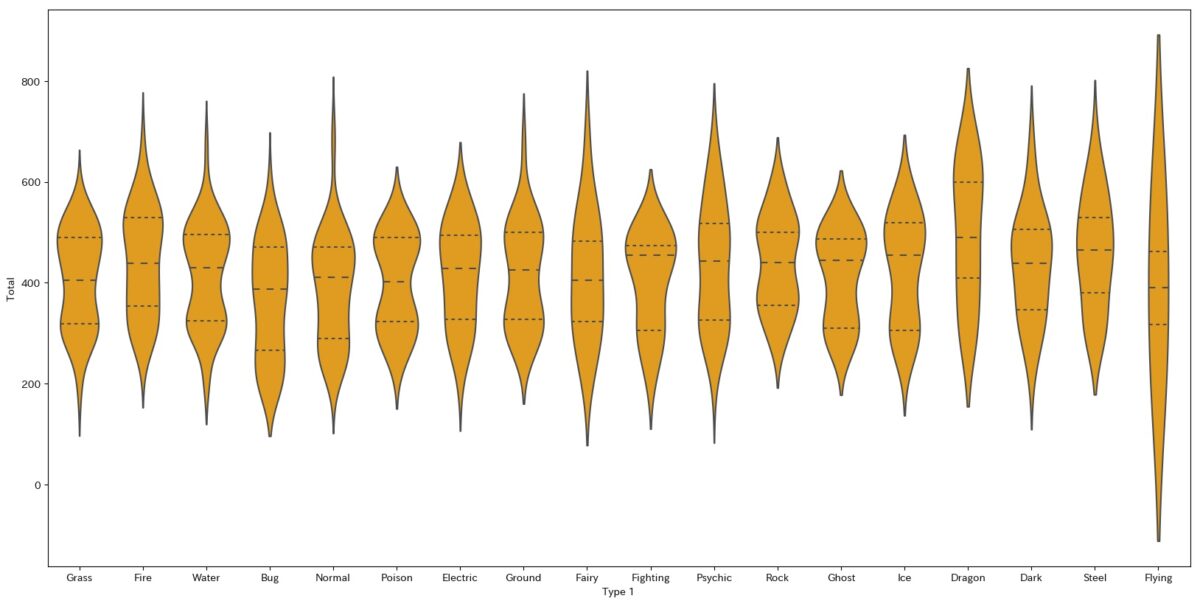
四分位数が表現できていることが確認できます。
これならboxplotと同様の使い方ができますね。
swarmplotで分布を加える
boxplotと同様に、stripplotやswarmplotと組み合わせることで、分布も可視化することができます。
violinplotは幅はデータ数として表現されているのでswarmplotと組み合わせると見た目がいい感じになります(個人の意見ですw)
import seaborn as sns plt.figure(figsize=(20,10)) sns.violinplot(data=d2, y="Total", x="Type 1", color="orange") sns.swarmplot(data=d2, y="Total", x="Type 1",color="blue")
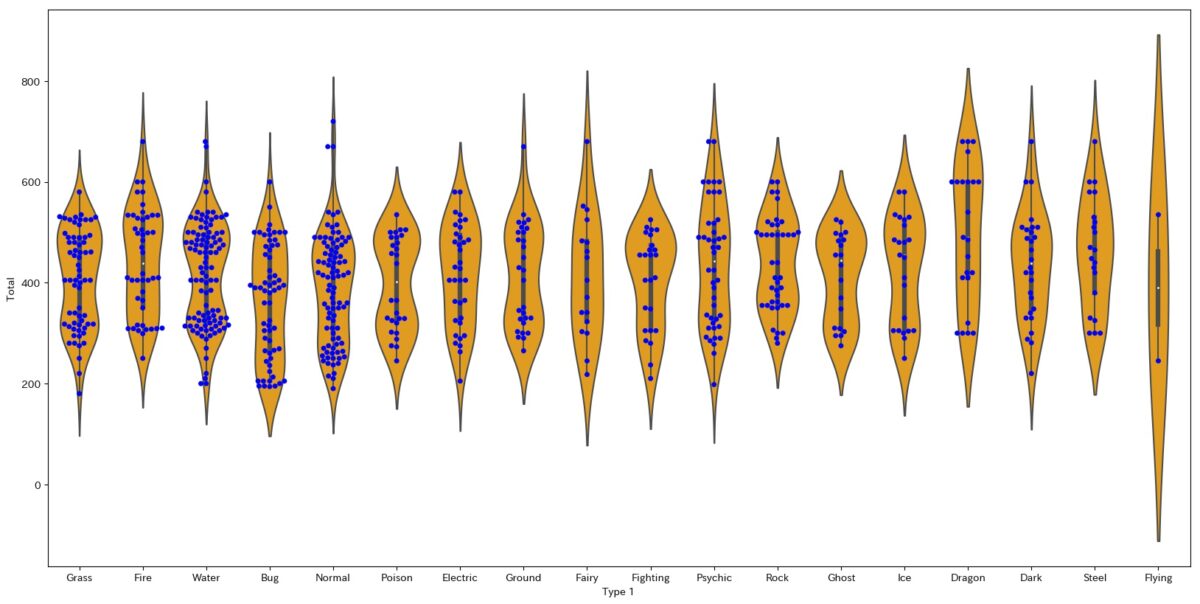
ちょっと色の組み合わせが気持ち悪いですが、適宜調整してくださいw
とにかく、こんな感じでswarmplotと組み合わせるといい感じに分布も表現できます。
hueでグルーピングする
最後にhueについて紹介しておきます。
violinplotでもhueを利用できます。
これまで同様にLengedaryでグルーピングしてみます。
import seaborn as sns plt.figure(figsize=(20,10)) sns.violinplot(data=d2, y="Total", x="Type 1", hue="Legendary", color="orange")
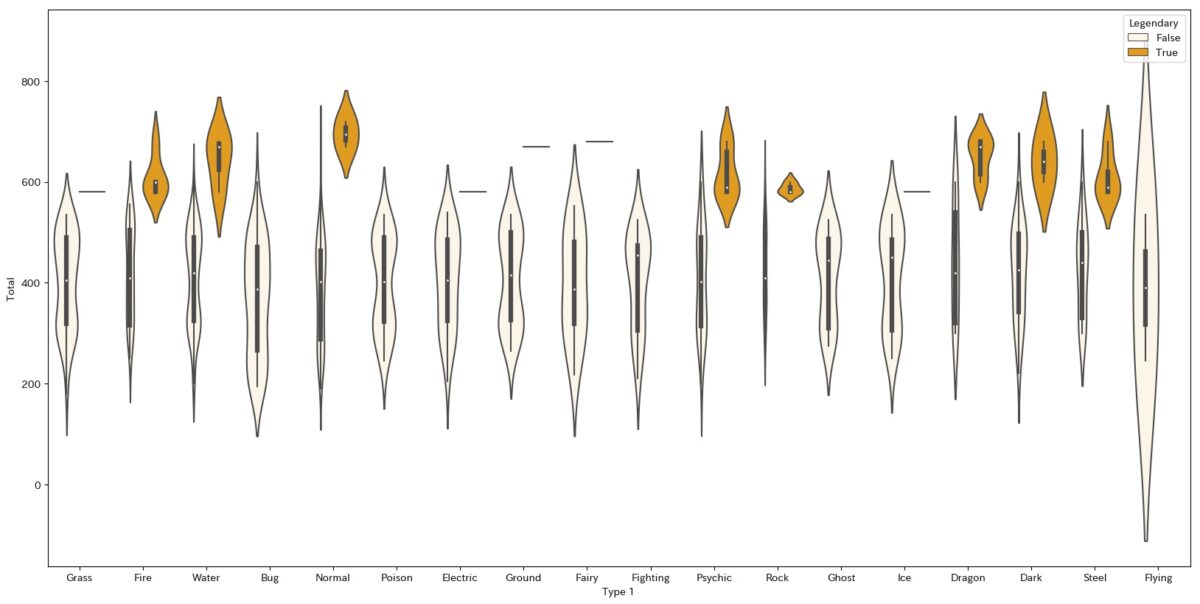
ちなみにsplit=Trueという引数を加えるとこうなります。
import seaborn as sns plt.figure(figsize=(20,10)) sns.violinplot(data=d2, y="Total", x="Type 1", hue="Legendary", split=True, color="orange")
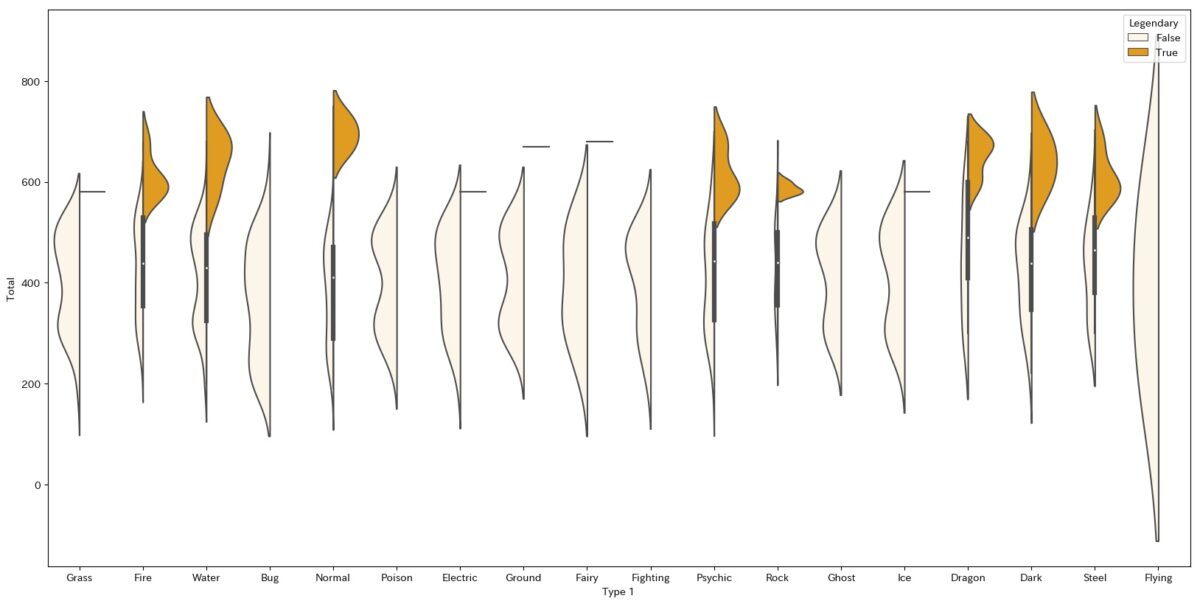
ご覧の通り、左右で分割して表現されます。
グルーピング数が3つ以上の場合は機能しないのでご注意ください。
以上で解説はおしまいです。
Pythonだと複雑なデータの可視化も簡単にできます
ここまでで紹介してきた様々なデータの可視化については全てPythonで書かれています。
紹介してきているコードから、数行でいい感じのグラフが描けることがわかります。
それほどPythonはわかりやすくて、初心者でも学びやすいプログラミング言語です。
エクセルでは作れないようなグラフをPythonでかっこよく描くことができれば、周りから注目されたりするかもですw
データの可視化以外にも、データ分析やスクレイピングなど多くの用途に利用することができます。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
習得しておけば、仕事や転職時にも役立ちます。
僕は社会人になってからPythonを独学して転職にも成功しました。
今では仕事でもバリバリPythonを使っています。
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】
-

【副業は神です】2度の転職において副業が内定の決め手になったお話。
加えて英語を身につけることができると、さらにレベルアップすることができます。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
まとめ
いかがでしたでしょうか。
今回は「Pythonによるデータの可視化」ということで、ポケモンのデータセットをいろいろな方法で可視化する方法を解説しました。
少ないコードで美しいグラフが描けてしまうことがPythonの素晴らしい点です。
特にseabornを使うとイケてるグラフが簡単に描けます。
エクセルなどではなかなか描けないような複雑なグラフでも、Pythonならサクッと描けてしまいます。
これを知っていると仕事とかでも役に立つ場面があると思います。
今後もPythonのコード解説の記事は積極的に増やしていこうと思うので、何かご要望とかありましたら、Twitterとか本サイトのお問い合わせページからご連絡いただければと思います。
今回は気合いを入れて書いたらかなり長くなってしまいましたw
ここまで読んでくださって、ありがとうございました。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-
【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
-
【Pythonコード解説】Pythonでポケモンのデータセットを集計する
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-
【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
-
プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】




{kind=link}