
こんにちは。TATです。
今日のテーマはPythonを使って世界銀行のデータを取得して可視化することです。
世界銀行のデータは、誰でも無料でアクセスすることができ、Pythonでデータが取得できるライブラリも存在します。
人口やGDPなど、様々なデータがまとめられており、国ごとや地域ごとで比較することも容易に可能です。
グラフなどで可視化をすれば、数値の羅列を眺めるよりも様々な発見があります。
ここでは、世界銀行のデータについて紹介するとともに、このデータにアクセスできるPythonライブラリであるwbdataの基本的な使い方について解説していきます。
また、可視化についてはPythonのPlotlyというライブラリを使います。
目次
【Pythonでデータ分析】Pythonで世界銀行のデータを取得して可視化する!
【無料!】世界銀行のデータについて

まずは世界銀行のデータについてみていきましょう。
世界銀行のサイトでは様々なデータにアクセスすることができます。
人口データやGDPやインフレなど、様々なデータにアクセスすることが可能です。
たくさんのデータがあるのでサイト内を探検してみてください。
しかもこれ、無料です。
こんなにたくさんの世界中のデータがきれいに管理されてまとめられており、なおかつ無料で取得可能というのは、まさにインターネットの恩恵です。
そして次章で解説しますが、これらのデータにアクセスするためのライブラリーまで存在します。
世界銀行のデータにアクセスできるPythonライブラリ「wbdata」
Pythonを使って世界銀行のデータを扱うにはいくつかの方法があります。
- 世界銀行のサイトからCSV、XML、EXCEL形式でダウンロードする
- 専用のライブラリーを利用する
ライブラリーを使わずとも、世界銀行のサイトからは、データをダウンロードすることが可能です。
ゆえにPythonを使わずともエクセルなどで可視化することは容易です。
Pythonでダウンロードしたファイルを読み込んでも可視化できます。
ただ、Pythonを使ってデータを取得するなら、ライブラリーを使う方が便利です。
常に最新のデータが取得できる上に、一度プログラムを作ってしまえば自動でデータを取得することができます。
ダウンロードなどの手作業は発生しません。
本記事では、ライブラリーを使って世界銀行のデータを取得し、可視化します。
wbdata
利用するライブラリーはwbdataです。
wbはWord Bankの略です。
名前の通り、世界銀行のデータにアクセスするためのライブラリーになります。
世界銀行で公開されているデータにアクセスが可能で、国を指定したり期間を指定するのもパラメータをセットするだけで簡単に実装することができます。
wbdataの基本的な使い方(get_data関数)
wbdataの基本的な使い方についてみていきましょう。
ライブラリーのインストールはpipで可能です。
import wbdata import datetime # 期間を指定 data_date = datetime.datetime(2000, 1, 1), datetime.datetime(2021, 1, 1) # データを取得 SP.POP.TOTLは人口を指す j = wbdata.get_data(indicator="SP.POP.TOTL", country="JPN", data_date=data_date, )
シンプルなのでなんとなく流れはわかると思います。
date_dateはdate型で、指定期間の始まりと終わりをタプルで指定します。
indicatorは取得したいデータのIDを指定し、ここで使っているSP.POP.TOTLは人口を指します。
countryのJPNは日本です。
このコードで取得できるデータはこちらです。

このままだとわかりにくいので、DataFrameに変換します。
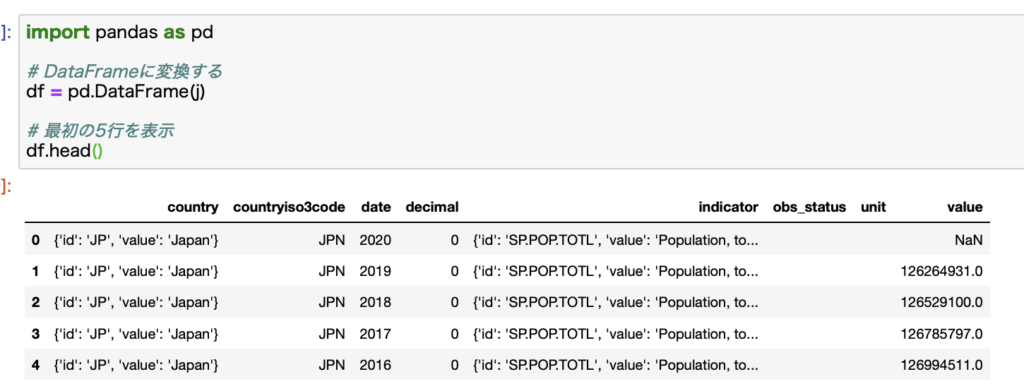
dateカラムに年が入り、valueカラムに値が入っていることがわかります。
その他にもcountryカラムやindicatorカラムには指定したデータの詳細情報があります。
countryはISOコードで指定する
countryはISOコードで指定します。
日本はJPNです。
各国のISOコードはWikipediaとかで確認できます。
取得可能なcountry一覧はget_country関数でも確認可能です。
国だけでなく、East Asia & Pacificみたいな地域単位も選択も可能です。

ちなみにcountry="all"とすると全てのデータを取得できます。
WLDとすると世界全体の合計データが取得できます。
indicatorは世界銀行のサイトから確認可能
indicatorで指定するIDについては、世界銀行のサイトから確認できます。
データの一覧は世界銀行のサイトから確認可能です。
例としてGDPを探してみます。
サーチボックスで検索するといろいろヒットします。

(世界銀行より)
ここでは左下にあるGDP (current US$)を選択してみます。
クリックすると詳細ページに行きます。
デフォルトでは世界全体のGDPが表示されます。
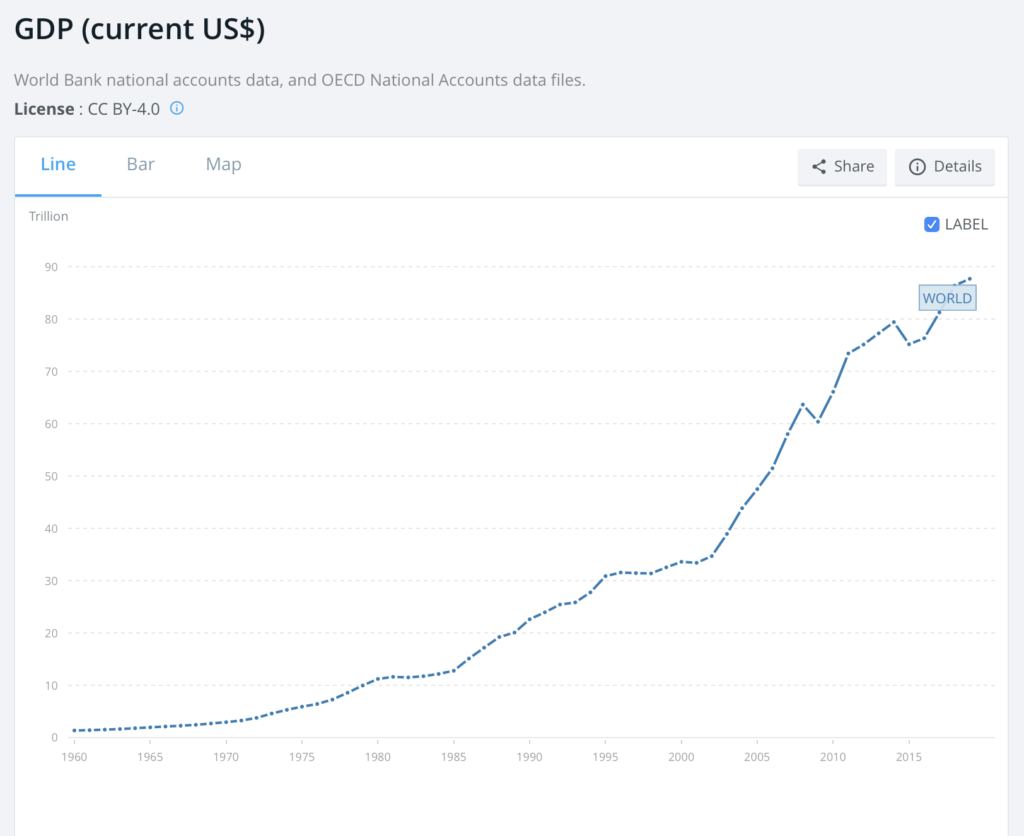
(世界銀行より)
ここでグラフの右上にあるDetailsをクリックします。
これで表示されるIDをwbdataでそのまま使うことができます。

(世界銀行より)
こんな感じで取得したいデータのIDがわかるとwbdataを使ってデータの取得が可能です。
wbdataでは国の指定も期間の指定もパラメータをセットすればカスタマイズできるのでとても便利です。
get_dataframe関数はDataFrameに自動変換
get_dataframe関数を使うと、返り値がDataFrameになります。
indicatorは辞書型で指定するとカラム名を指定できます。複数指定も可能です。
また、get_dataframe関数でもget_data関数でも、countryはリスト形式で複数指定できます。
例として2019年の日本とアメリカのGDPと人口データを取得してみます。
import wbdata
import datetime
# 期間を指定
data_date = datetime.datetime(2019, 1, 1), datetime.datetime(2019, 12, 31)
# indicatorを指定
indicator = {"SP.POP.TOTL": "Population", "NY.GDP.MKTP.CD": "GDP"}
# DataFrame型でデータを取得
df = wbdata.get_dataframe(indicator, country=["JPN", "USA"], data_date=data_date, )
取得できるデータがこちらです。
indicatorは辞書型で指定し、keyにIDをいれValueがカラム名になります。
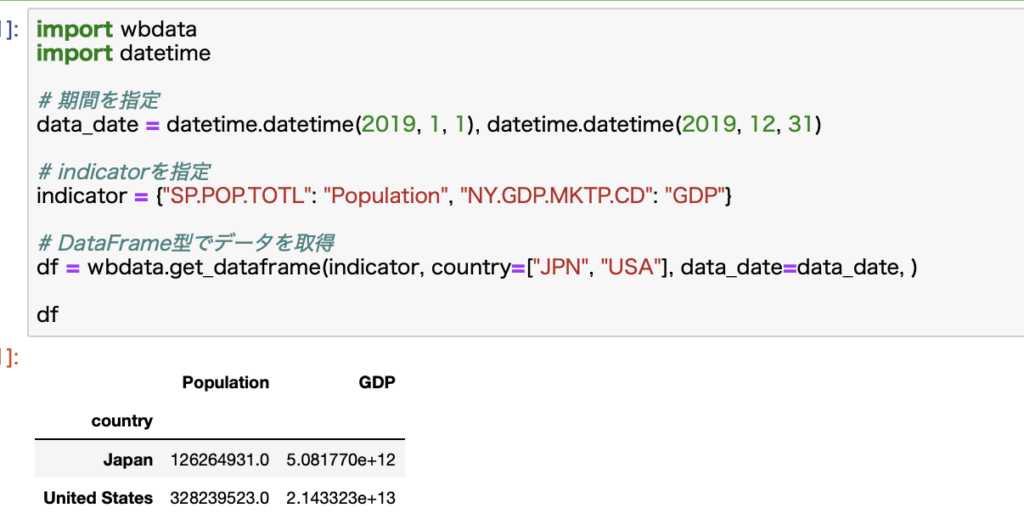
get_data関数とは異なり、Indicatorは指定した名前のカラム名に変換され、詳細な情報は出てきません。
国名も自動で変換されます。
特にこだわりがない場合はget_dataframe関数を使えば、indicatorを複数指定することができてなおかつカラム名も指定できるので便利かと思います。
ここからは、基本的にget_dataframe関数を使っていきます。
取得したデータをPlotlyで可視化する
データの取得方法がわかったところで、次は取得したデータを可視化してみます。
今回はPlotlyというライブラリを使います。
Plotlyを使うと、インタラクティブなグラフが簡単に描けます。
さらに見た目もとてもきれいなグラフが描けるので便利です。
こちらについては習うより慣れろということでいろいろなデータを可視化していきましょう。
コードも全て公開するのでご参考ください。
データ①:日本の総人口の推移を可視化する
1つ目の例として、日本の総人口データを可視化してみましょう。
人口を示すIDはSP.POP.TOTLでした。
期間はできるだけ古いものから欲しいので1950〜2021とします。
国は日本だけを指定します。
import wbdata
import datetime
# 期間を指定
data_date = datetime.datetime(1950, 1, 1), datetime.datetime(2021, 12, 31)
# indicatorを指定
indicator = {"SP.POP.TOTL": "Population"}
# DataFrame型でデータを取得
df = wbdata.get_dataframe(indicator, country=["JPN"], data_date=data_date)
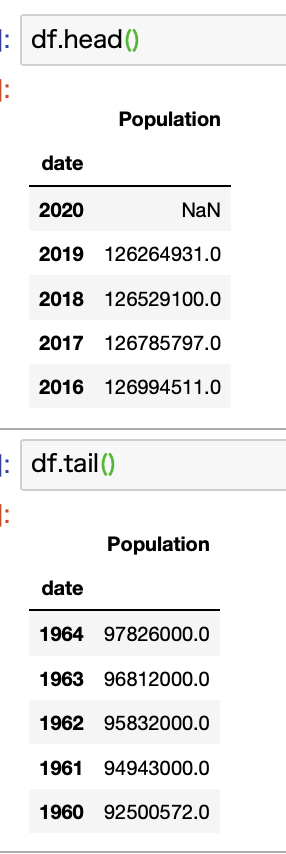
このコードで得られるデータがこちらです。
取得した時点(2021年6月時点)では2020のデータはまだありませんでした。
一方で、一番古いデータが1960年のものであることが確認できました。
このデータを可視化してみます。
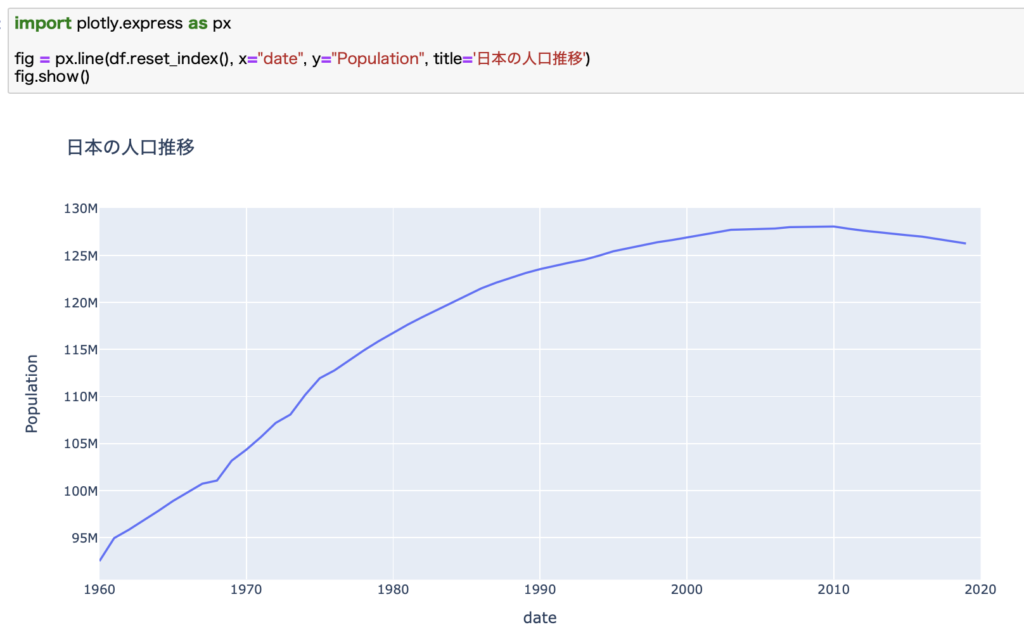
Plotlyで描くとこんな感じになります。
plotlyにはグラフを描くためのクラスが二つあります。
expressとgraph_objectsです。
どちらも同等のグラフが描けますが、コードの書き方がちょっと変わります。
どちらを使ってもいいのですが、ここではexpressを使っていきます。
graph_objectsの使い方についてもぜひ調べてみてください。ググるとたくさんの情報が出てきます。
ここではexpressのlineを使ってラインチャートを描いています。
指定するのは、使用するDataFrameとx軸とy軸のカラム名です。titleもつけられます。
dfはdateがindexになっているので、reset_indexを使ってカラムに変更しています。
使い勝手としてはseabornに似ているような感じもします。
グラフを見ると、2010年あたりでピークをうって、そこから人口は減少に転じていることがよくわかります。
これからくる(もうすでにきてますが)超少子高齢化社会は不可避ですね。。。
データ②:G7のGDP推移を可視化する
2つ目の例としてGDPを見てみます。
今回は日本だけではなく、G7に属する各国で比較していこうと思います。
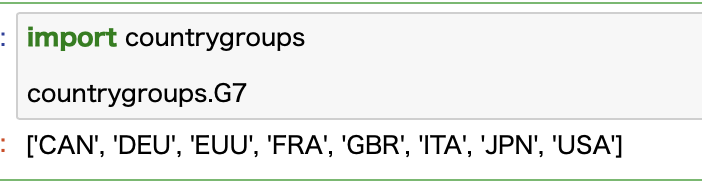
G7に属する国を覚えていれば問題ないですが、覚えてない場合にはcountrygroupsというライブラリーを使うと便利です。
pipでインストールできます。
ライブラリー名の通り、様々なグループに属する国のリストを取得することができます。
こちらはG7に属する国です。
デフォルトではISOコードで表示されます。
国名で表示することもできます。

EUは不要なので削除する必要がありますね。
G7の他にもOECDやEUなどいろいろなグループが選択できます。
取得できるグループ一覧についてはライブラリーの公式サイトから確認できます。
GDPのIDはNY.GDP.MKTP.CDなので、G7のGDPを取得するには次のようなコードになります。
import wbdata
import datetime
import countrygroups
# 期間を指定
data_date = datetime.datetime(1950, 1, 1), datetime.datetime(2021, 12, 31)
# indicatorを指定
indicator = {"NY.GDP.MKTP.CD": "GDP"}
# country EUは除外
countryList = countrygroups.G7
countryList.remove("EUU")
# DataFrame型でデータを取得
df = wbdata.get_dataframe(indicator, country=countryList, data_date=data_date)
こちらで取得できたデータを可視化してみます。
人口データを可視化した時と比べて、パラメーターにcolorが増えます。
colorは、seabornで言うところのhueと同じ働きをします。
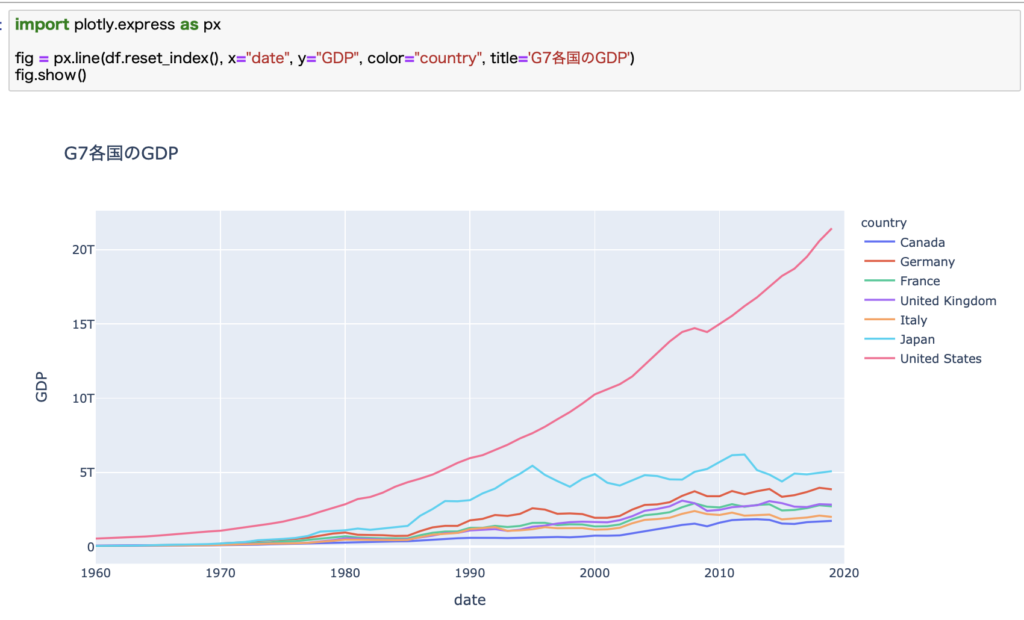
国ごとを比較すると一目瞭然で、アメリカの独走です。
日本も頑張っていましたが、バブル崩壊後は横ばいです。
いわゆる失われた30年ですね。本当に悲しくなるくらいのアメリカの一人勝ちです。
このデータを見ると、長期投資をするならアメリカ株にすべきということがよくわかりますね。
-

【米国株×高配当株】僕の投資戦略を解説します〜米国株編〜
続きを見る
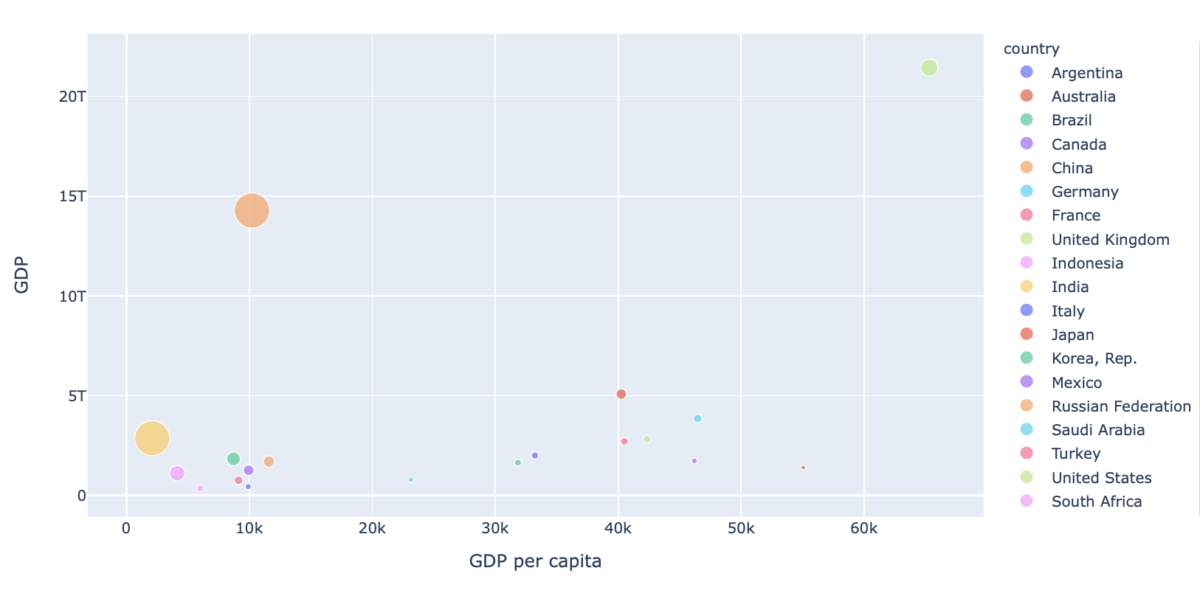
データ③:G20各国のGDP、1人あたりのGDP、人口を可視化する
最後の例として、G20各国のGDPと一人あたりのGDPと人口の関係を見てみます。
1人あたりのGDPを示すNY.GDP.PCAP.CDを追加します。
import wbdata
import datetime
import countrygroups
# 期間を指定
data_date = datetime.datetime(1950, 1, 1), datetime.datetime(2021, 12, 31)
# indicatorを指定
indicator = {"NY.GDP.MKTP.CD": "GDP", "NY.GDP.PCAP.CD": "GDP per capita", "SP.POP.TOTL": "Population"}
# country EUは除外
countryList = countrygroups.G20
countryList.remove("EUU")
# DataFrame型でデータを取得
df = wbdata.get_dataframe(indicator, country=countryList, data_date=data_date)
取得できたデータを可視化します。
今回はバブルチャートを使ってみます。
x軸を1人あたりのGDP、y軸をGDP、丸の大きさを人口として国ごとのデータを表示します。
まずは取得時の最新データである2019年のデータを見てみましょう。
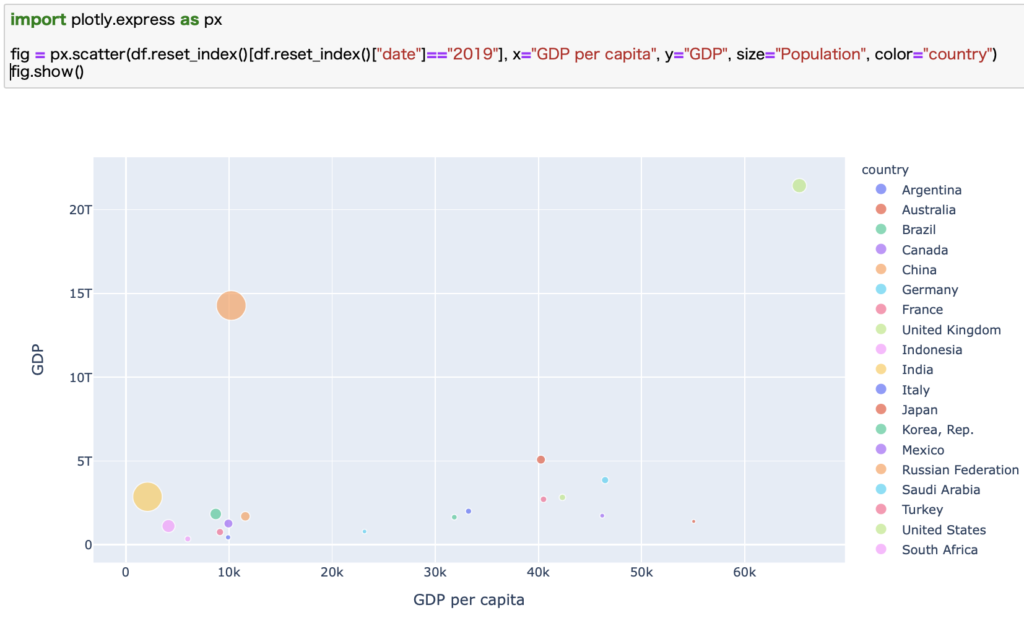
僕自身もデータを見て驚きましたが、アメリカが圧倒的に強いですね。
GDPが世界トップであることがわかっていましたが、1人あたりのGDPでもここまで圧倒しているとは思いませんでした。
このグラフで右上に位置するアメリカは紛れもなく世界最強です。
一方で人口の多い中国やインドは、先進国と比べると1人あたりのGDPで見ると低くなってしまうことがわかります。
中国は、GDPで見ると世界2位ですが、1人あたりのGDPで見ると結構低くて、同じラインにはメキシコとかアルゼンチンなどがあります。
我らが日本は、横軸40k、縦軸5Tの位置にある赤丸です。
GDPではアメリカと中国に次ぐ第3位です。
1人あたりのGDPで見ると中国には勝っていますが、アメリカには大きく突き放されています。
そして気になるのが、グラフの右下にいる国です。
これらは、GDPは低いですが1人あたりのGDPはとても高い国です。
人口も少なく、かなり効率的に稼げている国になります。
日本より1人あたりのGDPが高い国は、アメリカ以外だとオーストラリア、ドイツ、カナダ、イギリス、フランスです。
オーストラリアはとても効率よく稼いでいる国ですね。
次に、少し時を戻して1990年のデータでも比較してみます。
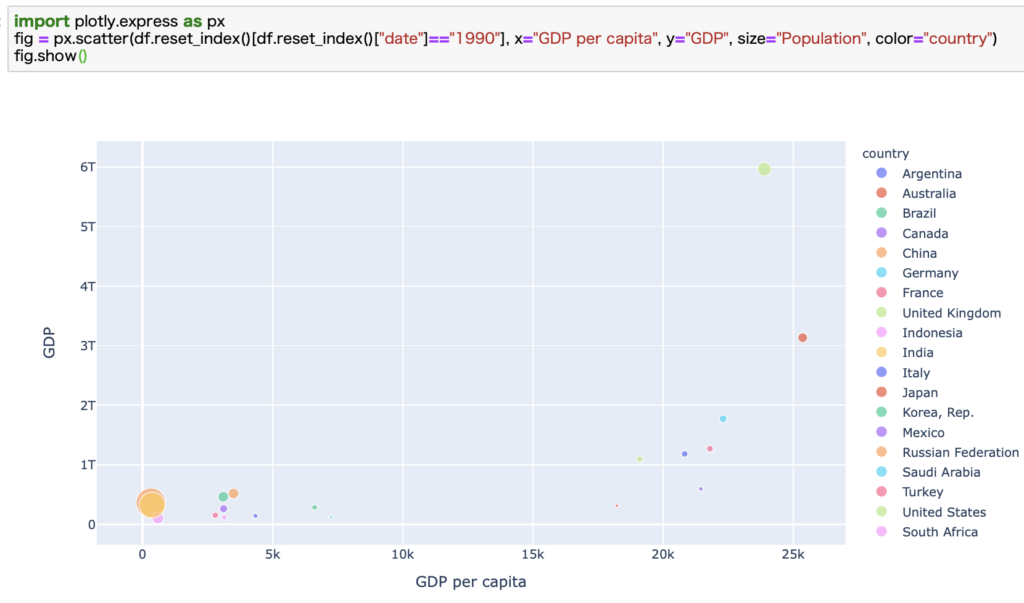
お気づきでしょうか。1990年で1人あたりのGDPが最も高い国は日本です。
GDPもアメリカに次ぐ世界第2位です。
バブル崩壊までは日本経済がイケイケだったことがよくわかるデータです。
グラフ右側はG7が占めています。
当時から人口が多かったインドや中国は、1990年時点ではGDPでも1人あたりのGDPでも最下位レベルでした。
30年ほどで凄まじい勢いで成長したことがよくわかりますね。
そしてG7は揃ってアメリカに突き放される結果となりました。
データを可視化することで、数字だけではなかなか見えてこないデータの特徴が見えてきます。
今回は以上でおしまいにしますが、世界銀行にはたくさんのデータがあるので、もしご興味があればいろいろ探してみてください。
まとめ
いかがでしたでしょうか。
今回は「Pythonを使って世界銀行のデータを取得して可視化すること」というテーマで、世界銀行のデータを紹介しつつ、Pythonのwbdataライブラリーを使ってデータを取得し、Plotlyを使って可視化する方法についてご紹介しました。
世界銀行のデータは、誰でも無料でアクセスすることができ、様々なデータがまとまっています。
グラフなどで可視化をすると、数値だけではわからない様々な発見があります。
世界銀行にはたくさんのデータがまとめられているので、是非ともいろいろなデータを探しつつ可視化してみてください。
本などでは書かれていない新たな発見ができるかもしれません。
Pythonを使うとデータの取得、加工、可視化が簡単にでき、データ分析やAIなど様々な用途に利用することができます。
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
続きを見る
転職にも有利になるので、知っておくと武器になります。
-

【実体験】ゼロからのPython独学を決意してから転職を掴み取るまでのお話。
続きを見る
また、Pythonは独学でも習得できるくらい学びやすい言語です。
僕自身も独学で習得しました。もしプログラミングやデータ分析などに興味があるなら、Pythonはおすすめです。
-

【決定版】Python独学ロードマップ【完全初心者OK】
続きを見る
-

Pythonをゼロから独学で習得するのに必要な時間は?【僕の経験をご紹介します】
続きを見る
今回は世界銀行のデータについて基本的な解説とほんの一部のデータしか紹介できなかったので、今後テーマを決めてそれに沿ったデータを紹介できていければと思います。
データの可視化についても、特に今回紹介したPlotlyについても今後どんどん使っていこうと思います。
ここまで読んでくださってありがとうございました。


{kind=link}