

こんにちは。TATです。
今日のテーマは「シエンタとフリードの中古車データを分析してみた」です。
過去の記事で中古車データを分析しました。
-

【Pythonでデータ分析】中古車価格データを分析して一番コスパの良さそうな中古車を探す
今回はこの続編です。
僕が将来的に買いそうな車種を考えたら、色々な欲望や想定が出てくるわけです笑

- 子供が小さいうちはスライドドアが便利かな?
- ベビーカーを軽々積めるくらいの荷室がほしい
- 都市部で走るならデカすぎる車は嫌だ
- 僕の両親も同乗する可能性もあるかも?
こういったことを考慮するとコンパクトミニバンが第一候補になってきて、その筆頭車種がトヨタのシエンタとホンダのフリードです。
ただこれらのどちらがいいかは僕にはわかりません。
人によって様々な意見が出てくるので、「じゃあデータ集めて調べようぜ」ということで今回のテーマになりました。
前回の記事では、中古車データの各車種の内訳データは取っていなかったのでそこまで突っ込んだ分析はできませんでした。
今回はここを深掘りしてみようと思います。
ただし、全車種にやるのではなくて、ワンチャン僕が将来買いそうなシエンタとフリードに限定します。
相変わらず自分勝手ですみませんw
目次
【Pythonでデータ分析】シエンタとフリードの中古車データを分析してみた

今回のデータ分析の目的
まずは今回行うデータ分析の目的をご紹介しておきます。
目的設定の意義
目的がきちんと定まっていないと、どんなデータを集めればいいのか、どのように分析を進めていけばいいのかが曖昧になります。
結果として、無駄な情報を収集することに時間を割いてしまったり、データを集めてもどこからどう分析していけばいいのかがわからなくなります。
こういった状況を避けるために、データ分析を行う前には必ず明確な目的やゴールを設定しておく必要があります。
そしてこれらの目的やゴールに対してある程度の仮説を持っておくとさらによいです。
仮説は間違っていても問題ないです。
間違っていたら、間違っていたことがわかって別の切り口を模索できます。
やみくもに分析するよりも、仮説をもとに分析を進めると自分が今どこにいてこれから何をしようとしているかの目印にもなります。
一番効率の悪いやり方は、とりあえずわからないから集められるだけのデータを収集して、そこから何かしらの知見が得られないかを手探りで調べることです。
これをやりだすと無駄な作業が多すぎて、最終的に後悔します。
そもそもこの場合は目的は定まっていないので、どこまでやれば終わりなのかもはっきりしません。
「なんかおもろいことないかな〜」という曖昧な考えは、データ分析においては危険です。
今回の目的・ゴール
存分にウンチクを語ったところで本題に戻ります。
今回の目的・ゴールについては以下のような項目を設定しました。
具体的な方が良いですが、僕の趣味でやってることなのでわりと適当ですw
以下の答えを探すために分析を行なっていきます。
- データをもとにどちらを買うべきか結論づける
- どのようなオプションや装備が価格に影響するのか
- 価格を下げてしまう要因は何か
- どちらの方が価格が下落しにくいか
こういった目的を設定した上で、色々と仮説を考えてみます。
ざっくりとこんな感じです。
- 年式が古い方が安いだろう
- 走行距離が長い方が安いだろう
- 販売台数の多いシエンタの方が価格下落は大きいのかな?あるいは需要もあるから下がりづらい?
- 地域によって価格差はありそう→台数が少ないと市場原理が働いて高くなるかも?
みたいな感じで仮説を立てておきます。
データを分析する際には、これらの答えを見つけるために進めていきます。
こんな感じで目的やゴールを設定したところで、早速データを集めていきます。
データはPythonで価格.comをスクレイピングして収集
まずは肝心のデータに関してですが、こちらについては価格.comから収集しました。
過去記事でも価格.comからのデータを使っていたので、ここは統一しようと思います。
-
【Pythonでデータ分析】中古車価格データを分析して一番コスパの良さそうな中古車を探す
データを収集するためのPythonコードについてはこちらの記事で解説しています。
-

【Pythonコード解説】価格.comをスクレイピングして中古車データを収集する
サイトを確認
次にサイトを確認します。
例えばシエンタやフリードですと、こんな感じで中古車一覧を確認できるページがあります。
→ https://kakaku.com/kuruma/used/spec/Maker=1/Model=30098/Generation=41908/Page=1/ (シエンタ)
→ https://kakaku.com/kuruma/used/spec/Maker=2/Model=30264/Generation=42017/Page=1/(フリード)
このPageの数字を切り替えるとことで遷移できます。

(参照元:価格.com)
ちなみに今回はシエンタは2015年モデル、フリードは2016年モデルのデータを収集しました。
古いモデルは無視してます。買うこともないので。
各ページを順番にスクレイピングしていき、次ページがなくなるまでいきます。
ただ今回はサイトの仕様上、60ページまでしか表示されないので、マックスでも1,200個までしか表示されません。
ゆえに、地域ごとに分けて収集しました。
この辺りの詳細については、コードの解説記事でどうぞ。
-
【Pythonコード解説】価格.comをスクレイピングして中古車データを収集する
そしてそれぞれのページに行くと詳細データを確認できます。
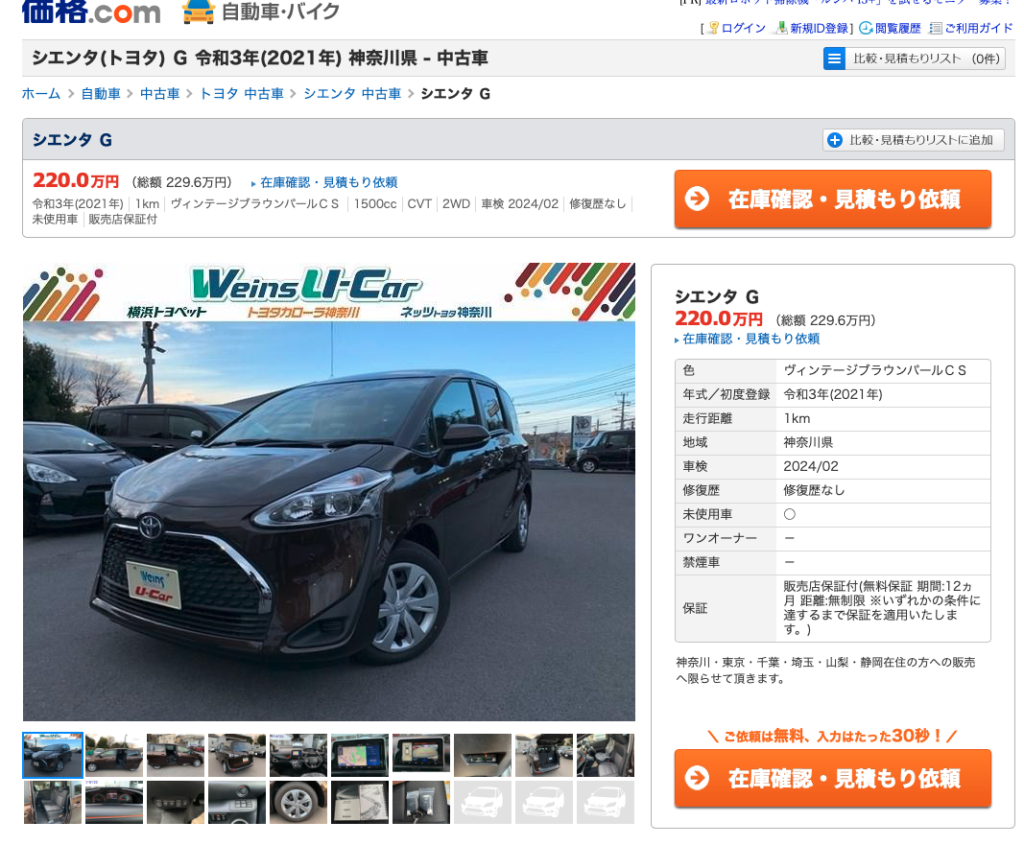
(参照元:価格.com)
右側に走行距離とかの情報がありますね。
さらに下にスクロールすると詳細な情報が確認できます。
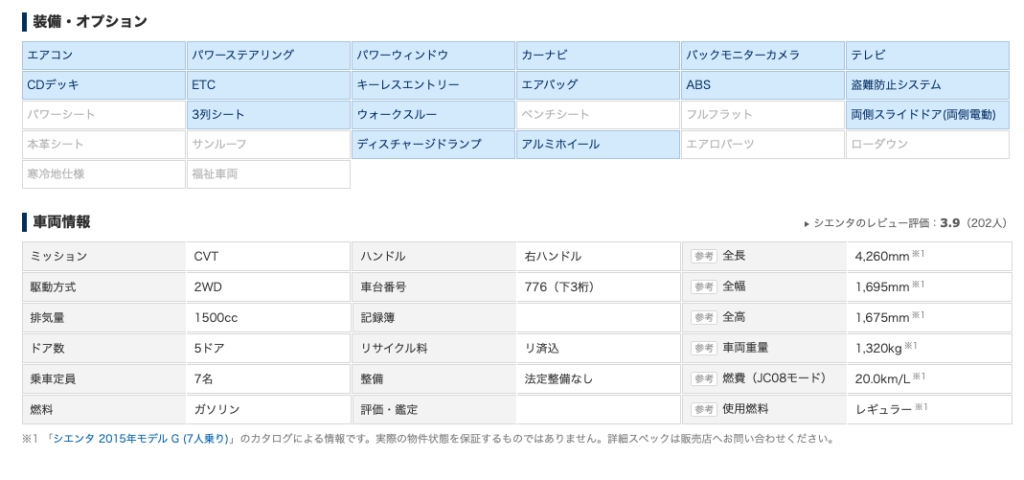
(参照元:価格.com)
装備・オプションや車両情報があります。
今回はここにあるデータを根こそぎとりました!
収集したデータを確認
それでは取得したデータを確認します。
データを収集・整形するためのプログラムコードはこちらの記事でご確認ください。
-
【Pythonコード解説】価格.comをスクレイピングして中古車データを収集する
サイトからスクレイピングで収集して整形した結果がこちらです。
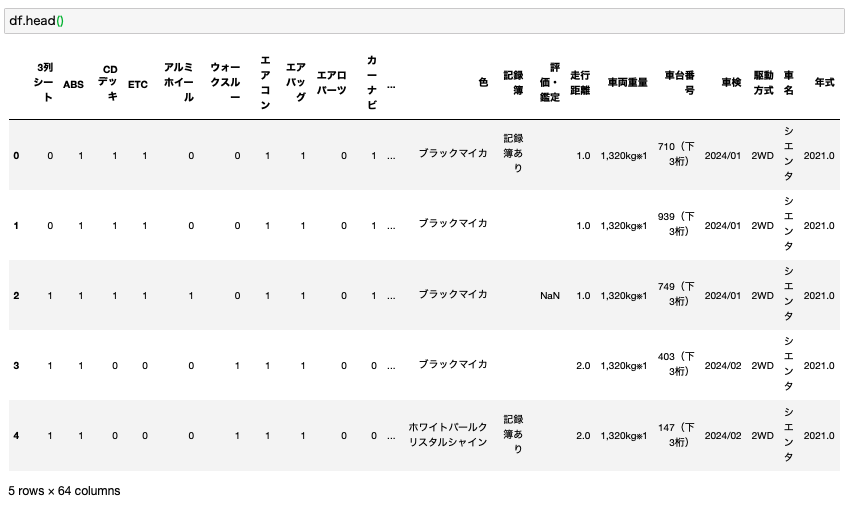
カラム数が64個と、なかなかのサイズになりました。
シエンタとフリードのそれぞれのデータ数はこちらです。
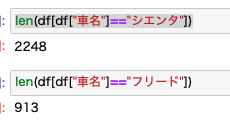
シエンタの方が圧倒的に多いですね。
販売数も多いので、当然中古車数も多くなります。
こちらのデータを使って分析をしていきます。
収集したデータを分析・可視化する
それでは収集したデータを分析していきます。
様々な角度から可視化して当初の目的やゴールに向かって仮説を紐解いていきます。
グラフはコードも一緒にお見せしたいので、コードとグラフを含めたスクショをメインに使います。
画質的に見にくくなるかもですが・・・
コードはご自由にパクっていただいてOKです!
価格データをヒストグラムで可視化する
まずは価格データをヒストグラムで見てみます。
ヒストグラムを使えばデータの分布がわかるので便利です。
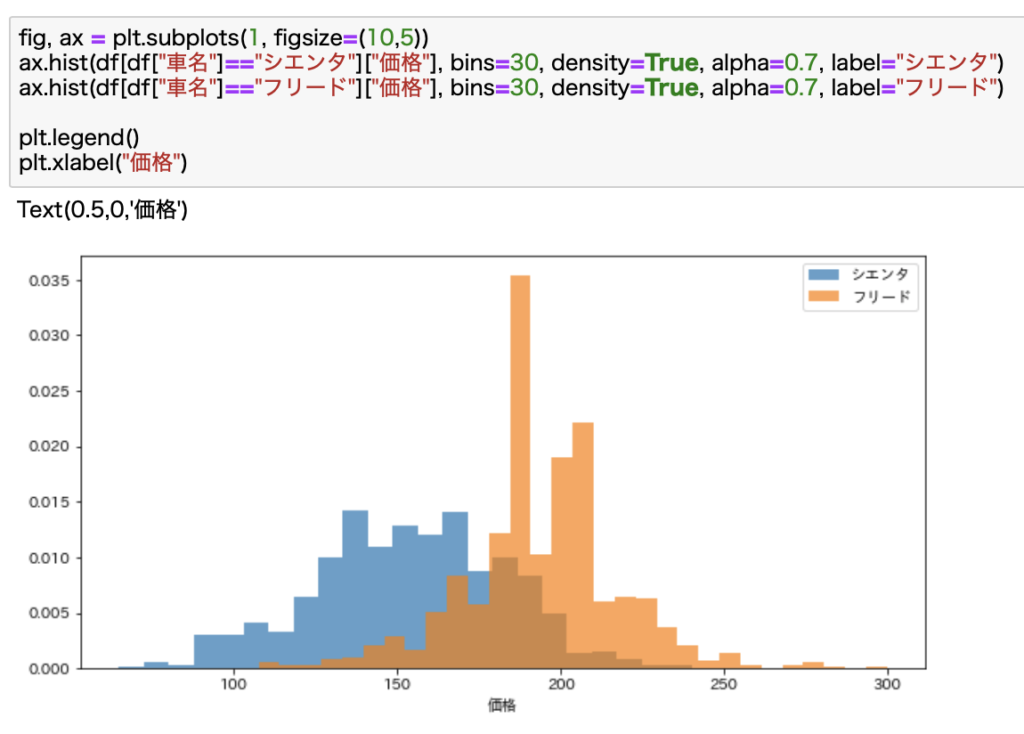
シエンタとフリードではデータ数が異なります。
よってこれらを横並びで比較するために正規化して可視化しています。
それぞれのヒストグラムの総和が1になります。
結果を見ると全体的にフリードの方が高いことがわかりますね。
走行距離と価格の関係をみる
次に走行距離と価格の関係をみていきます。
仮説では、走行距離が長いほど価格が低くなるとみています。
これは想像つきますよね。
ここをデータを見て本当にそうなっているのかを確認します。
散布図を使ってみてみます。
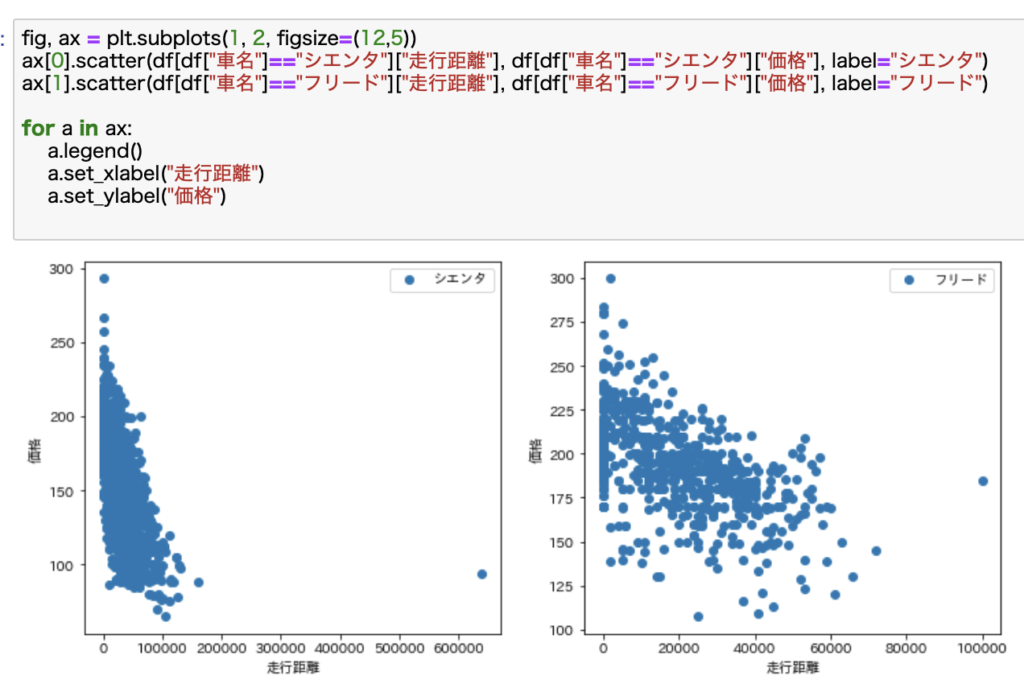
どうでしょうか。
ざっくり見た感じ、右下がりになっているように見えます。
つまり、走行距離が長いほど価格は下落する傾向にあります。
シエンタは一つだけ走行距離がめっちゃ長いものがあるのでグラフとしてはちょっと見づらいですね。
走行距離の最大値を20万kmとして表示してみます。
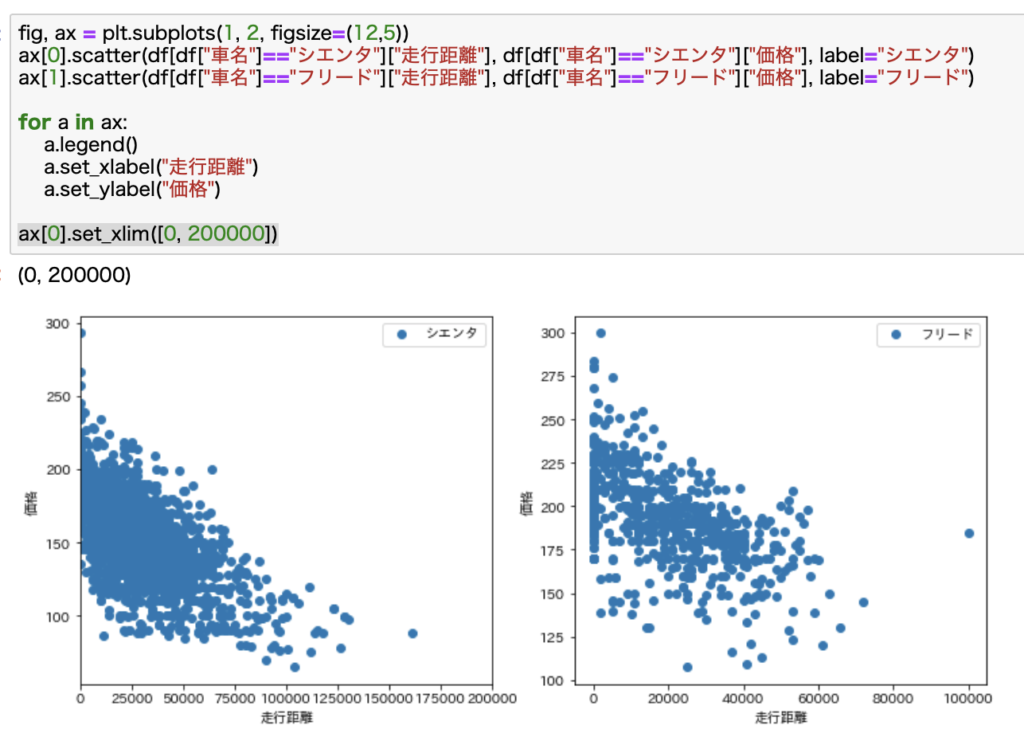
だいぶ見やすくなりました。右下がりになっていることがよくわかりますね。
仮説は概ね正しいと見て良さそうです。
年式と価格の関係をみる
次に年式と価格の関係をみていきます。
仮説では、年式が古いと価格も下がるとのことでした。
これも想像つきますよね。
先ほど同様に散布図で見てみます。
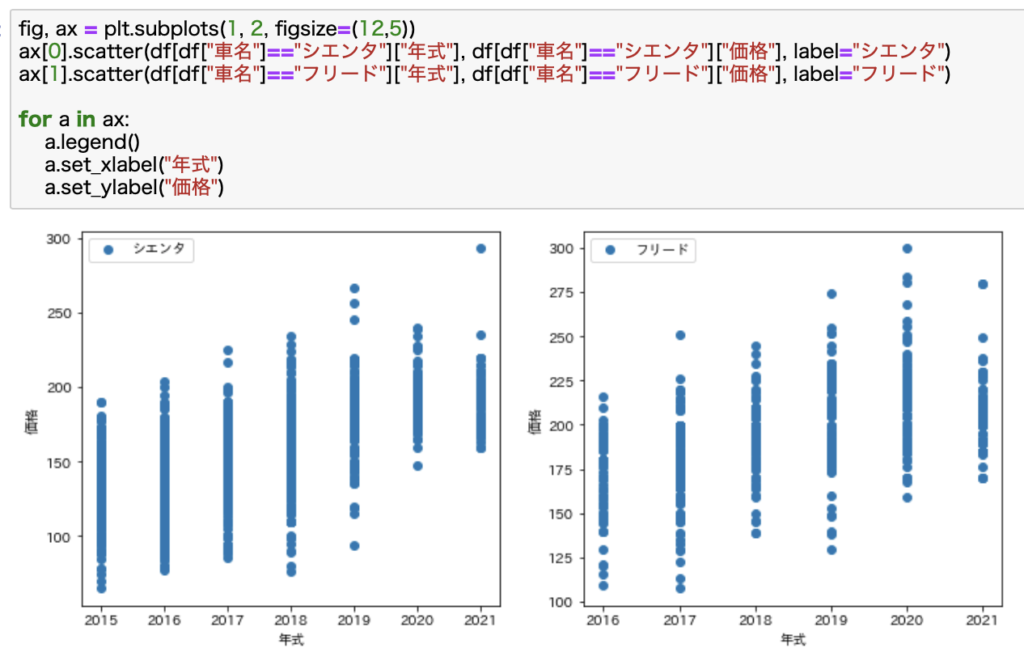
各年代の価格レンジが右上がりなことがわかります。
ただ、散布図だとデータの分布が少しみづらいのでViolinplotで見てみます。
横幅が大きいと該当するデータが大きいことを意味するので、データの分布を見るには便利な可視化方法です。
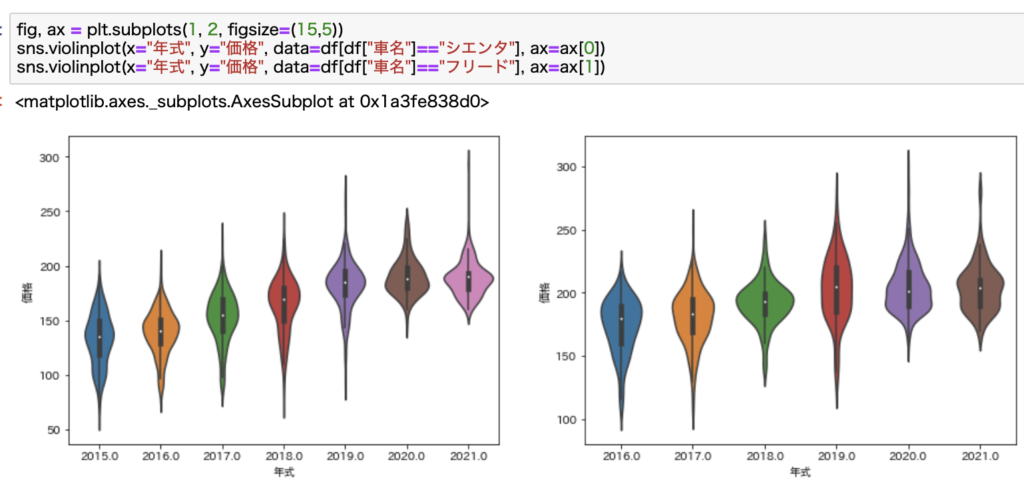
こちらの方が見やすいですよね。
年式が新しいものほど価格レンジが上がっていることがわかります。
ここも仮説通りですね。
見た感じ、シエンタの方がきれいな右上がりのようにも見えますね。
ちなみにViolinplotについてはこちらの記事でも解説しているので、もしご興味があればあわせてご覧ください。
-

【Pythonコード解説】Pythonでポケモンのデータセットを可視化する
年式と価格の関係をシエンタとフリードで比較する
次に先ほどの延長戦として、年式と価格の関係をシエンタとフリードで比較してみます。
年式ごとの平均価格とか中央値を見るとこんな感じになります。
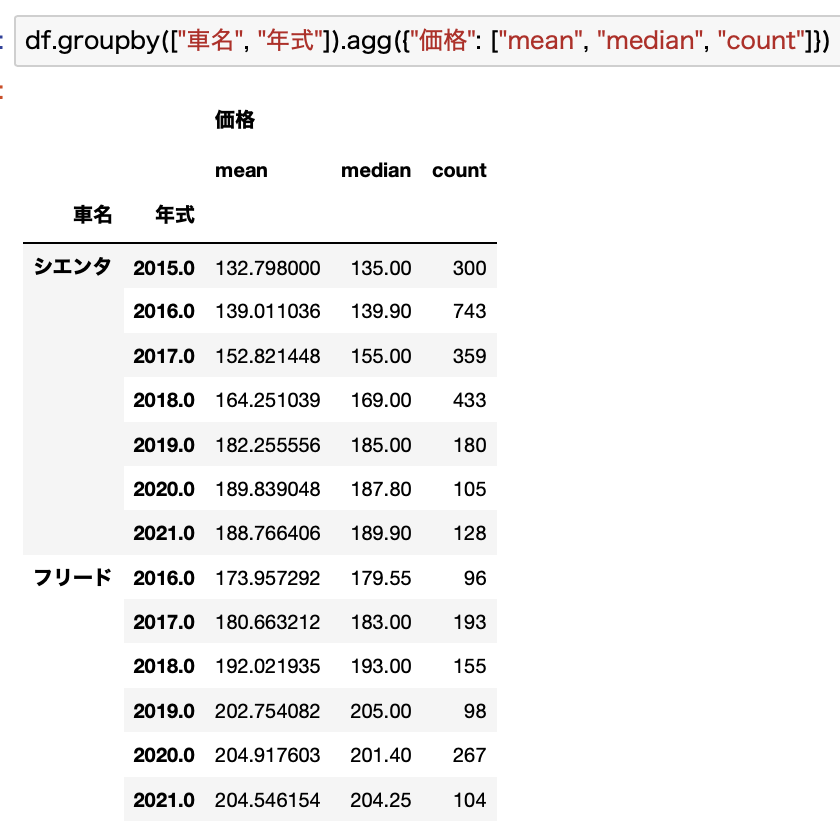
平気価格で比較してみます。
単純に比較するとこんな感じになります。
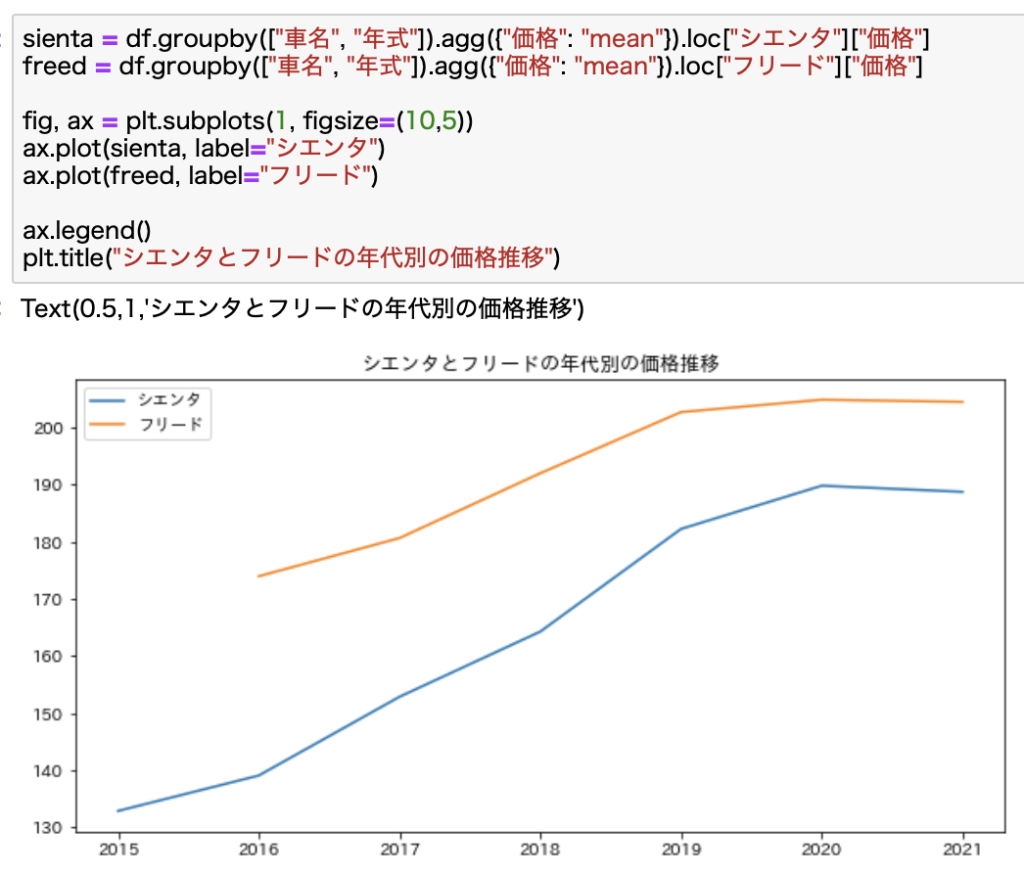
パッとみたらどちらも右上がりのグラフであることがわかります。
ただこれだけだと比較しづらいですよね。
この場合はある基準値に対する相対値で比較するとわかりやすくなります。
この方法は株価の比較などによく使われます。
複数銘柄を比較する際にはそもそも株価が全然違うのでそのまま横並びで比較することができません。
この場合は、例えば年初の株価を1とした相対値などを使って比較します。
こうすることで株価が違う銘柄も横並びで比較することができます。
同じ手法を使って、ここでは2021年の平均価格を基準にして比較してみます。
こんな感じです。
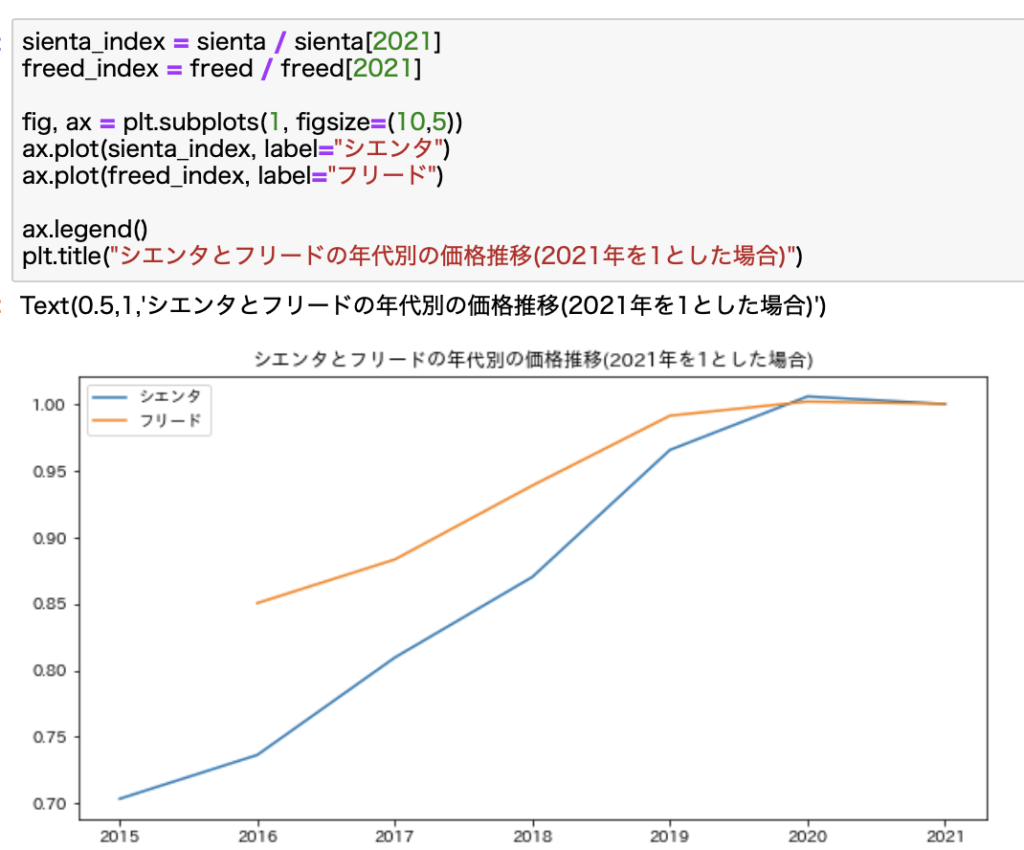
2021年の平均価格を1として、これに対する比が各年にプロットされます。
これなら価格が違う2つの車種を横並びで比較することができます。
このデータからわかることは、2020年の価格に差はほとんど見られません。
しかしそれ以前のデータを見ると、シエンタの方が下落率が大きいことがわかります。
これから中古車を購入する場合には、単純に価格で比較したらシエンタの方が安いです。
しかし、年式と価格の関係を見ると、フリードの方が下落率が小さいので、中古で購入した価格と数年後に売った時の価格差が小さいことがわかります。
売却まで考慮したら価格は高いけどフリードの方が良さそうです。
データを見ると、単純に価格の比較だけでは見えてこないようなことも見えてくるわけです。
このような発見こそが、データ分析の醍醐味であり、やっていてとても楽しいところでもあります。
地域ごとの価格を見る
次に地域ごとの価格をみていきます。
仮説では、地域ごとに価格差がいくらかあって、例えば車数が少ないと価格が上がるのではないかといった内容でした。
実際に見てみましょう。コード付きでどうぞ。

画質悪くてすみませんw
ただ、このデータからわかることは明確ですね。
- 地域による価格差はほぼない
- 車数に限らず平均価格で見ると差はない
やっぱりトヨタのシエンタは愛知県の車数が圧倒的に多いですね。
フリードは千葉県がトップです(この理由わからんw)
つまるところ、僕の仮説はことごとく間違っていたことになりますw
これは間違っていても問題なしです。
この仮説に基づいて何かしらの施策を行おうとしていたなら、このデータを見て改め直すこともできます。
何れにしても、ただの仮説なので全て正解してるはずもありません(開き直りw)
【応用編】機械学習モデルを作ってシエンタの価格に影響を与えるファクターをあぶり出す
最後に少し応用編です。
どのような装備やオプションが価格に影響を与えているのかを知りたかったので、機械学習モデルを作って調べてみます。
これにはいろいろなやり方がありますが、今回は価格を予測するモデルを作成して、どのようなパラメーターが価格に影響を与えているのかを見てみることにします。
フリードはデータが少ないので、データ数の多いシエンタで分析してみます。
モデルは重回帰分析
今回使うモデルについてですが、シンプルに重回帰モデルにします。
本来なら色々なモデルを比較しつつ、パラメータを最適化しつつベストなモデルを見つけだすのですが、今回はそこまでの精度は求めていません。
そこそこのパフォーマンスが出れば十分です。
よって、もうシンプルな重回帰分析でトライします。
これで精度がよっぽど悪ければ他のモデルも検討しますが、そこそこの精度が出たのでこれで打ち切りましたw
重回帰分析については過去記事でも解説しているので気になる方はご参考にしていただけたらと思います。
-

【数式なしで徹底解説!】機械学習の基本!回帰分析(単回帰分析・重回帰分析)について解説します!
使用する変数
次に使用する変数を見てみます。
これまでの分析から、相関の強そうな年式と走行距離を筆頭に、その他にどの変数を含めるかを考えます。
本来ならこの変数選定もじっくりとやるべきところですが、今回はサクッと決め打ちでいきます。
そもそも価格に影響する装備やオプションについてみたいというのが本来の目的なので、これを全部ぶちこみます。
詳細ページでいうところのこれです。ここの装備・オプションの部分になります。
(参照元:価格.com)
装備・オプションがついていれば1、ないなら0と数値を振ってデータセットを作成します。
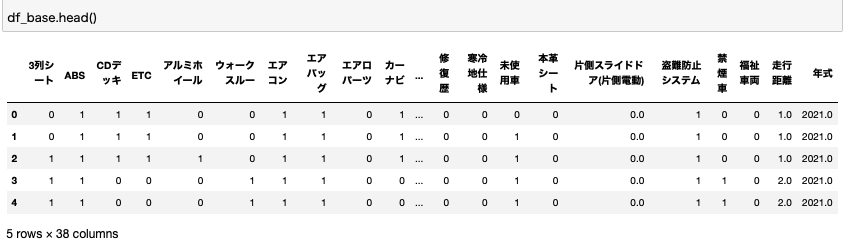
変数に利用するデータを抽出したものがこちらです。
抽出したデータはdf改め、df_baseという変数に変更しました。
価格モデルを作成する
データセットの用意ができたのでモデルを作成します。
モデルの出力値は価格です。
それ以外の全データが入力値になります。
そしてデータセットを分割して、一部は訓練用、残りをテスト用のデータとして使用します。
訓練用のデータを使ってモデルを作成し、テスト用のモデルを使って精度を測ります。
さらに、データスケールが異なるので統一します。
ほとんどのデータは1と0の数値データですが、年式や走行距離は異なります。
これらのデータをそのまま使うとスケールが全く違うのでモデルの精度が落ちてしまいます。
これは、スケールを統一してあげれば解決します。
今回はあまり凝ったことをしていないのでコードもとてもシンプルです。
さらに精度を上げようと思ったら、変数を最適化したりモデルの選定し直したりいろいろな作業が必要になってきます。
ここではそこまでの性能は求めていないので、わりと適用にやってますw
コードはこちらです。
これだけでできてしまうPythonの優秀さに驚きます。

精度としては0.693でした。
ちなみに最高値は1です。
人によって意見が変わってくるところですが、0.7くらいの精度が出るとまあいいかなと判断されることが多いです(あくまで僕の経験ですがw)
今回は0.693でほぼ0.7なので、これでよしとします。
ここの精度があまりにも低ければ、変数やモデルを見直す必要があります。
ちなみに、このモデルを検討する際に、なるべくたくさんの変数をぶっこんだ方がいいという方もいますが、これは過学習の原因にもなって精度が爆下がりすることもあるので注意が必要です。
今回の場合は装備・オプションを全部つっこみみましたが、シンプルに入力値は年式と走行距離の2つだけの方が精度は高くなるということも十分あり得ます。
価格に影響するファクターをあぶり出す
作成したモデルで、それぞれの変数に与えられた係数を確認します。
この絶対値が大きければ価格への影響も大きいことを意味しています。
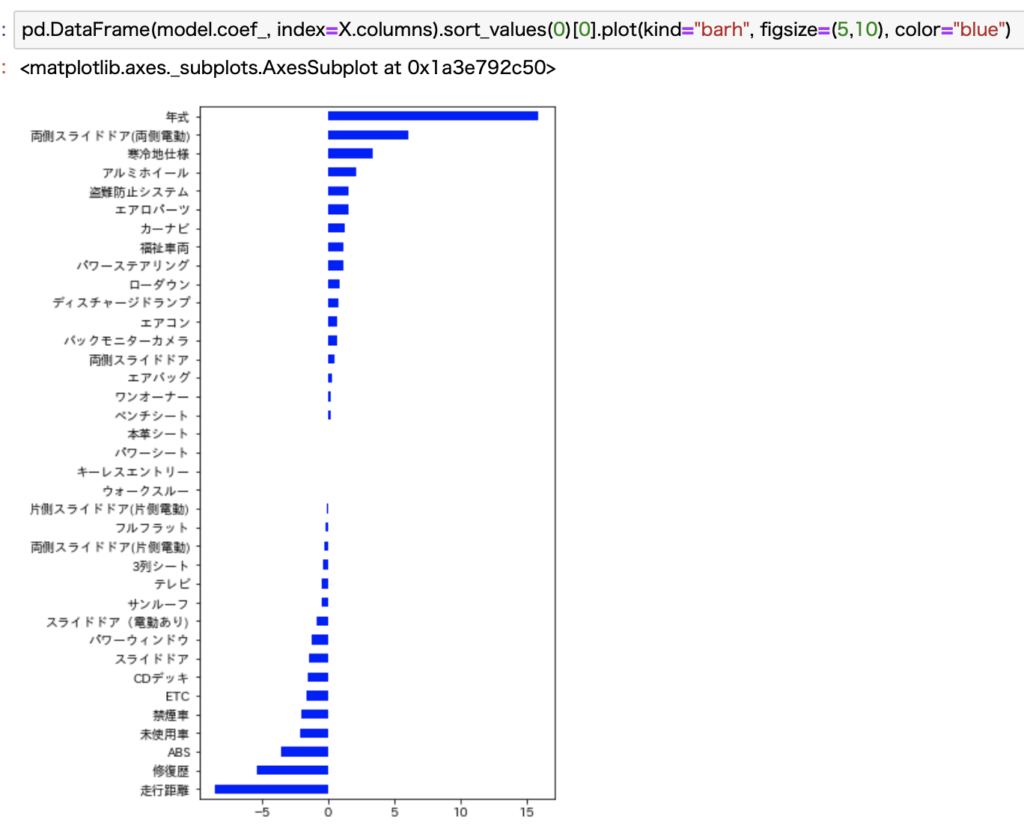
ご覧の通り、走行距離と年式が大きく影響していることがわかります。
イメージ通りですね。
マイナス値は負の相関、プラス値は正の相関を意味します。
年式は正の相関なので、年式が新しいほど価格も上昇していることを意味します。
反対に走行距離は負の相関なので、これが大きくなると価格が下がることを意味しています。
その他の装備・オプションだと、例えば両側の電動スライドドアや寒冷地仕様などはプラスに影響しますね。
反対に、修復歴があるとマイナスに影響します。
わりとイメージ通りですね。
ただ、未使用車や禁煙者が負の相関であるのは意外です。
これはデータ数とかに偏りがあるかもなので、一概には言えないですが、データを見るとこういった不思議な発見もあるのが面白いところです。
ということで、応用編はこれにて終了です。
ここではシンプルに重回帰モデルを使いましたが、この他にもいろいろなモデルがあります。
精度をさらに上げようと思えばいろいろな選択肢があります。
機械学習については、改めてコード付きで解説する記事を今後作ってもいいかもですね。
データ分析にはPythonが最適です。
最後に今回の分析に使用したPythonについて触れておきます。
ここでお見せしているコードは全てPythonというプログラミング言語で行なっています。
Pythonは初心者にも学びやすい
ここまで紹介してきたように、Pythonを使うと複雑な計算処理もシンプルなコードで一瞬で計算することができます。
Pythonはデータ分析やAI関連に強くて、世界中で人気を集めている言語です。
すっきりとしたコード体系で、誰でもきれいなコードが書けるような設計になっています。
過去の記事では、データ分析としてPythonをご紹介している記事や、Pythonでできることをまとめたものがありますので、もしPythonにご興味があれば合わせてご覧ください。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
データ分析に関する記事を発信しています
Pythonを使った様々なデータ分析について発信しています。
本記事の他にもデータ分析に関する記事を書いているので、もしご興味があれば合わせて読んでくださると嬉しいです。
-
ポケモンのデータセットを発見したので分析してみた!【Pythonによるデータの可視化も解説】
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
-

最近話題になったジャニーズグループの歌詞を歌詞化してみました!
Pythonのコード解説記事も増やしています
さらに最近はPythonのコード解説記事も増やしているので、Pythonを学んでいる方のお役に立てれば幸いです。
-

【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
-

【Pythonコード解説】ポケモンの名前を英語から日本語に変換する辞書を作る
まとめ
いかがでしたでしょうか。
今回は「シエンタとフリードの中古車データを分析してみた」というテーマで価格.comから集めたデータを分析してみました。
データをいじくりまわして、設定した目的やゴールは達成することができました。
僕的には当初はシエンタかなと思っていたのですが、データをみていると、最終的な判断としてはフリードがいいのかなと感じています。
特に価格の下落率で見ると、新車で買った場合にはわかりませんが、中古で購入した場合には下落率が小さいので、売却までを考慮したらフリードの方が良さそうです。
ただし価格全体が高いので、最初の出費は大きくなります。ここは僕が頑張りしかなさそうです。
今回はかなり個人的な目的を果たすための分析でしたが、今後のデータ分析に関する記事は増やしていければと思っています。
また、ここで紹介した価格.comからデータを収集するPythonコードについてはこちらの記事でも詳しく解説しているのでご参考にしていただければと思います。
Pythonを学習している方のお役に立てれば幸いです。
-
【Pythonコード解説】価格.comをスクレイピングして中古車データを収集する
また、この記事の前編となる中古車データの分析記事もあわせてご覧ください。
-
【Pythonでデータ分析】中古車価格データを分析して一番コスパの良さそうな中古車を探す
ここまで読んでくださってありがとうございました。




{kind=link}