

こんにちは。TATです。
今日のテーマは「【Python】SeleniumでSBI証券から日本株の買付余力を取得する方法」です。
PythonとSeleniumを使って、SBI証券のサイトから日本株の買付余力を取得する操作を自動化してみます。
ついでに信用建余力もまとめて取得してみます。
新規でエントリーする際には、現状の保有株から計算される買付余力の確認が必要になります。
本記事で紹介するコードを活用すれば、買付余力が取得できるようになるので、売買判断等に活用することができます。
目次
SBI証券へのログイン
事前準備として、PythonとSeleniumでSBI証券にログインしておく必要があります。
Seleniumの準備やSBI証券へログインする方法についてはこちらの記事で解説しています。
ログインが完了したら、本記事で紹介するコードを実行することができます。
-

【Python】SeleniumでSBI証券に自動ログインする方法【自動売買への道】
続きを見る
日本株の買付余力を取得するまでの流れ
次にPythonとSeleniumでSBI証券のサイトから日本株の買付余力を取得するまでの流れについて確認します。
ざっくりこんな感じかと思います。とてもシンプルです。
日本株を売買するまでの流れ
- (SeleniumでSBI証券にログイン)
- 「口座管理」ページへ遷移する
- 買付余力と信用建余力を取得する
1についてはこちらの記事で解説している内容になるので、()書きにしました。
本記事では1はスキップして、2〜3を実装する方法を解説していきます。
PythonとSeleniumでSBI証券サイトから日本株の買付余力の取得を実装する
それでは2~3の流れを順番に解説していきます。
「口座管理」ページへ遷移する
まずは「口座管理」ページへ遷移します。
SBI証券にログインしてから、「口座管理」をクリックすればOKです。

Chromeの検証からHTMLソースを確認すると、title="口座管理"となっていることが確認できます。
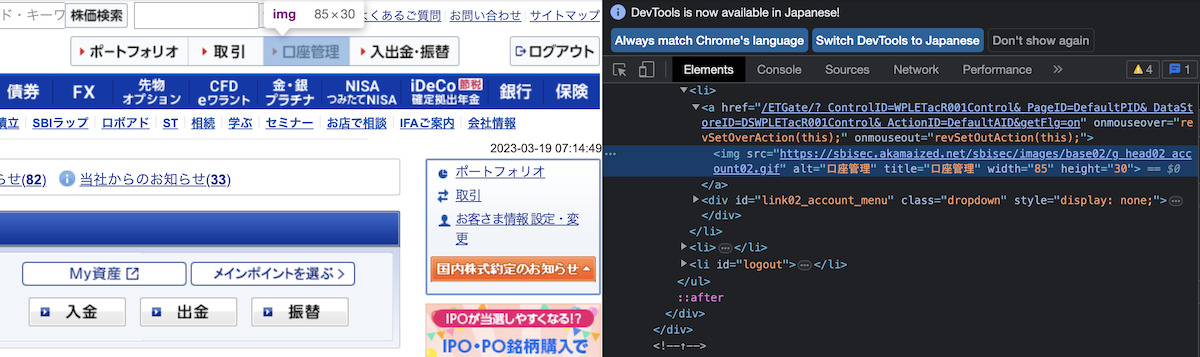
この情報を利用して、Seleniumで「口座管理」をクリックします。
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
これで口座管理ページへ遷移することができます。
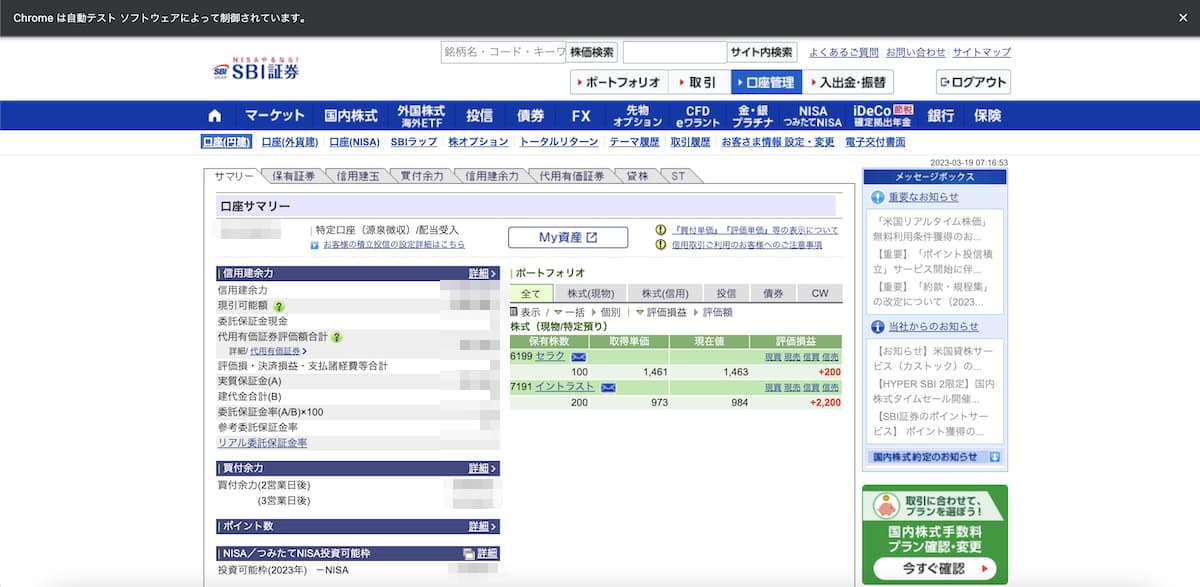
これで最初のステップ完了です。
買付余力と信用建余力を取得する
次に買付余力と信用建余力を取得します。
先ほどのページにすでに情報がありますね。
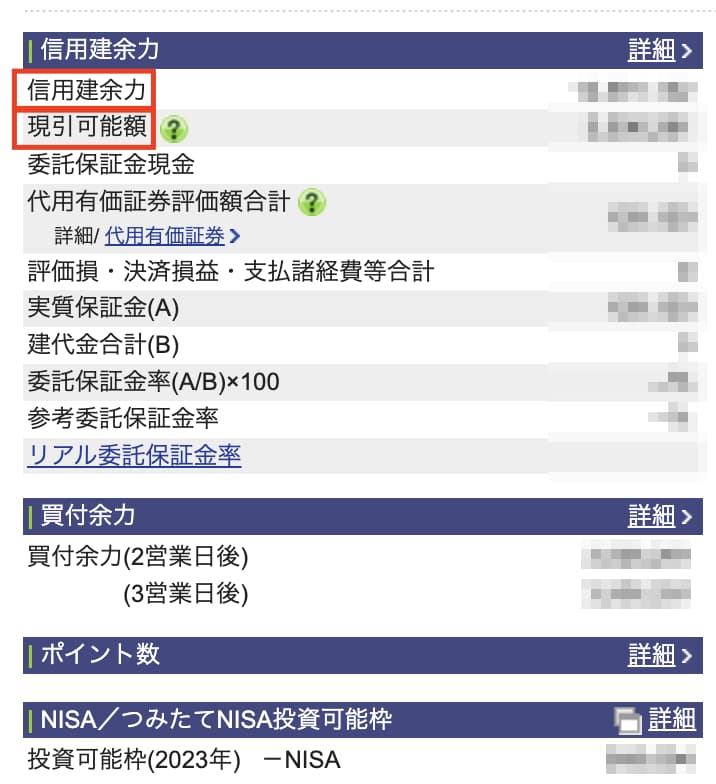
信用建余力はそのまま同じ名前で記載されています。
買付余力は取引可能額となっています。少し下にいくと2営業日ごと3営業日後の買付余力も確認できます。
これらの情報をPythonで取得していきます。
信用建余力や取引可能額が記載されている部分はテーブルになっており、td要素のなかにdivが入っています。
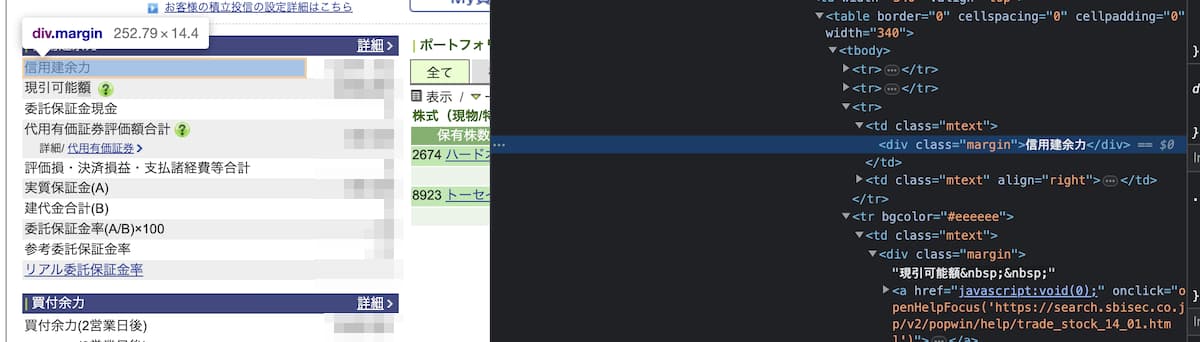
これを利用すればPythonを使って情報を抽出することができます。
次のコードでは、信用建余力と買付余力、さらに2営業日後と3営業日後の買付余力を取得しています。
from bs4 import BeautifulSoup
import re
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# 信用建余力
div = html.find("div", text=re.compile("信用建余力"))
margin_buying_power = div.findNext("div").getText().strip()
# 買付余力
buying_power = div.findNext("tr").findAll("div")[-1].getText().strip()
# 買付余力(2営業日後)
div = html.find("div", text=re.compile("買付余力\\(2営業日後\\)"))
buying_power_d2 = div.findNext("div").getText().strip()
# 買付余力(3営業日後)
buying_power_d3 = div.findNext("tr").findAll("div")[-1].getText().strip()
これで買付余力と信用建余力を取得することができます。
僕の口座のデータ取得時の余力バレちゃいますが、こんな感じです。
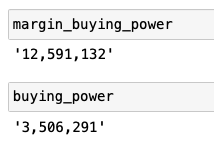
ちなみにこれらは文字列になっているので、数値として扱う際には変換が必要になります。

これで必要なデータを取得することができました。
最後にコードをまとめてどうぞ!
最後に、これまでのコードをまとめたものを共有します。
データの読み込み時間を考慮して、driver.implicitly_wait(60)を加えました。
これは次の処理を行うにあたり、対象となる要素が見つかるまで待機するという命令になります。
これがないとページが読み込まれる前に値を入力しようしたり次の処理を行おうとしてエラーが発生する場合があるので、処理に時間がかかる箇所に追加しておくとプログラムの安定感が増します。
それではどうぞ!
from bs4 import BeautifulSoup
import re
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
driver.implicitly_wait(60)
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# 信用建余力
div = html.find("div", text=re.compile("信用建余力"))
margin_buying_power = div.findNext("div").getText().strip()
# 買付余力
buying_power = div.findNext("tr").findAll("div")[-1].getText().strip()
# 買付余力(2営業日後)
div = html.find("div", text=re.compile("買付余力\\(2営業日後\\)"))
buying_power_d2 = div.findNext("div").getText().strip()
# 買付余力(3営業日後)
buying_power_d3 = div.findNext("tr").findAll("div")[-1].getText().strip()
これで、PythonとSeleniumを使って、SBI証券のサイトから日本株の買付余力を取得することができるようになりました。
まとめ
本記事では「【Python】SeleniumでSBI証券から日本株の買付余力を取得する方法」について解説しました。
PythonとSeleniumを使えば、買付余力を自動で取得することができます。
基本的にはブラウザ上で行う操作は全てSeleniumで置き換えることができます。
買付余力を取得できれば、新規でエントリーする際の口座状況の把握に活用することができます。
少し現金を残して余裕を持って投資するような戦略を構築することも可能になりますね。
最後まで読んでくださり、ありがとうございました。









{kind=link}