
こんにちは。TATです。
今日のテーマはXBRLです。
僕が運営する「投資でニート生活」では、TDNETやEDINETから各種XBRLデータを収集しています。
このXBRLを収集するに至るまでの地獄の作業についてここでご紹介したいと思いますw
「自分もXBRLを収集したい」と考えている方の参考になれば嬉しいです。
一言で言えば地獄でした。
データの収集自体はそこまで難しくありませんが、そこからの仕分け作業が地獄ですw
PythonでTDNETとEDINETからXBRLデータを集めたら地獄だった話。

データについて
まずは収集するデータについておさえておきます。
XBRLデータとは?
ここまでさりげなく、XBRLデータと紹介してきましたが、そもそもXBRLデータとは何なのか、ここで改めて解説します。
XBRLデータは、eXtensible Business Reporting Languageを略したものです。
普段我々が目にするPDFなどとは異なり、XBRLデータはXMLベースで構造化されたデータになっているので、プログラムで簡単にデータを識別できるようになっています。
XBRL(eXtensible Business Reporting Language)は、各種事業報告用の情報(財務・経営・投資などの様々な情報)を作成・流通・利用できるように標準化されたXMLベースのコンピュータ言語です。特に、組織における財務情報・開示情報(財務諸表や内部報告など)の記述に適しています。
たとえば財務情報は、年度ごと、あるいは組織や業種ごとに、文書構造や項目、計算式などが異なるといった特徴があります。
Yahoo!ファイナンスや株探などの証券情報を扱うサイトでは、決算などの情報が発表された数十秒後に速報ニュースなどが流れてきます。
こういったニュースは、XBRLデータを活用することで実現できます。
データを自動で取り込んで、データの内容を解析、内容によって文章を自動作成して、ニュース記事として公開しています。
この仕組みさえ知っていれば、誰でもXBRLデータを使ってデータ収集をプログラムで行うことができるようになります。
僕が運営する「投資でニート生活」では、まさにこのXBRLデータを収集しています。
一部は自動ニュースとして記事を自動作成しています。
データの取得先はTDNETとEDINET
次にXBRLデータはどこから取得できるかについて見ていきます。
結論から言えば、TDNETやEDINETです。
似たような名前ですが、運営者が異なります。
TDNETは東京証券取引所、EDINETは金融庁によって運営されています。
また開示される書類の種類も異なります。
TDNETでは、決算短信や業績予想修正、EDINETでは有価証券報告書や四半期報告書、大量保有報告書などがあります。
提出書類については各サイト(TDNETとEDINET)をご覧ください。
どちらのサイトにおいても、XBRL形式のデータがある場合にはリンクが出てきます。
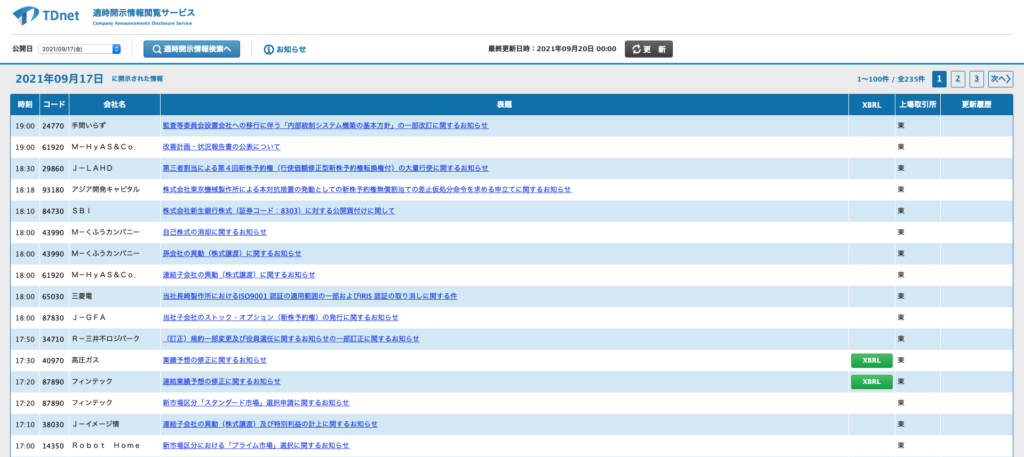
「TDNET」より
XBRLデータの構造
次にXBRLデータの構造についてみておきましょう。。
TDNETとEDINETで、データの構造は少し異なりますが、大体の構造は同じです。
それぞれ見てみましょう。
TDNET
まずはTDNETです。
適当なXBRLデータをダウンロードして中身を確認します。
ここでは決算短信のXBRLデータを見ていきます。
データをダウンロードすると、ZIP形式でダウンロードされます。
解凍して中身を確認すると、SummaryとAttachmentというフォルダーがあり(書類によって中身は異なります)、Summaryに入ると.htmファイルがあります。
これがXBRLファイルです。
TDNETでは、XBRLデータの中でも少し進化したiXBRL(inline XBRL)という形式が使われています。
これは、XBRLをHTML構造のような形式にしたもので、通常のXBRLファイルより人間が見やすい形式になっています。
Chromeで開くとPDFで見るときと同じようなフォーマットでデータを確認できます。
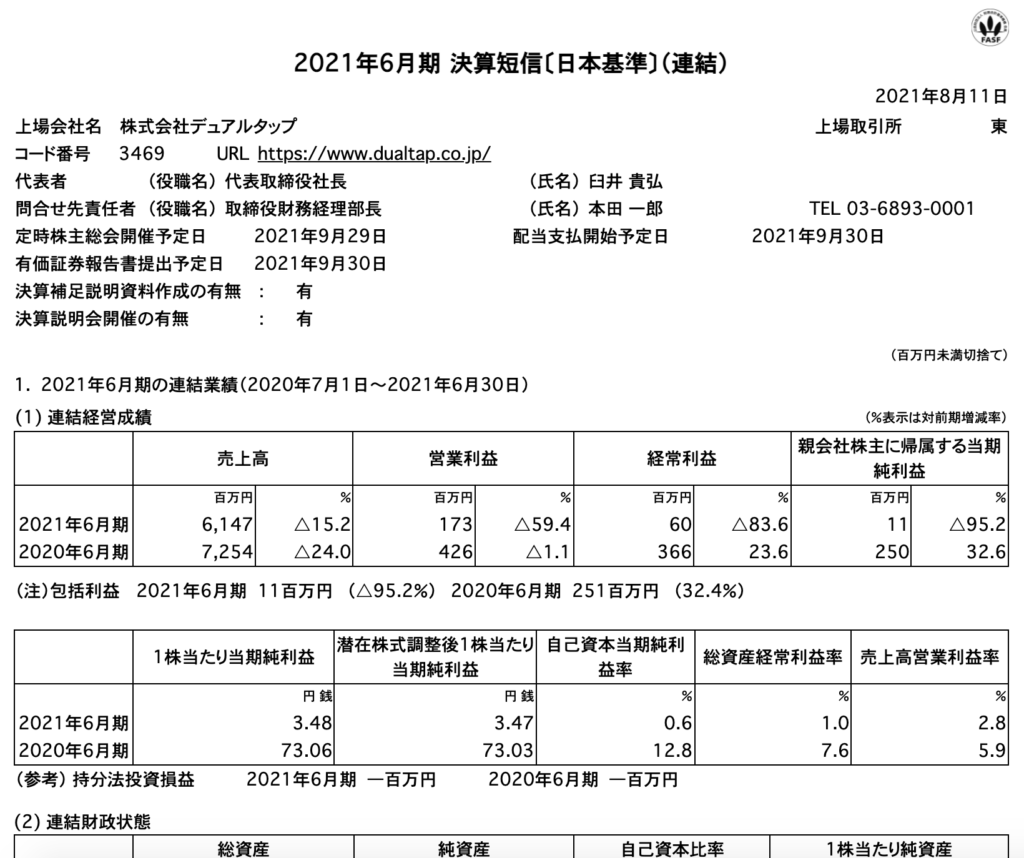
各要素の構造を確認してみます。
例えば、2021年6月期の売上高(6,147百万円)を見てみましょう。
Chromeであれば右クリックで検証をクリックです。

こんな感じで、contextref, decimals, format, name, scale, unitrefから成り立っていることが確認できます。
nameのNetSalesを確認すれば、このデータが売上高であることが確認できますね。
decimalsやscaleから、単位が百万円になっていることも確認できます。
contextrefを見ると、今期の値で、連結決算のデータであることがわかります。
このように、各値に付随するデータを確認すれば、それが何のデータなのかを確認することができるようになっているのがXBRLデータです。
つまりこのデータを収集すればOKなわけです。
こういったデータの意味を特定できる要素をタクソノミと言います。
東証サイトにはこのタクソノミをまとめてくれている資料があります。
この資料を確認すれば、どのタクソノミが何を示しているのかを確認することができます。
つまり、このタクソノミを活用すれば、それぞれの値の意味を理解できるようになるわけです。
EDINET
次にEDINETを見てみます。
ここでは有価証券報告書を見てみます。
適当なXBRLデータをダウンロードして中身を確認すると、たくさんのデータが入っていることが確認できます。
TDNETでも登場した.htm形式のデータもあります。
加えて.xbrlファイルがあります。
.htmファイルは、書類の内容ごとにファイルが分かれているので人間にもわかりやすい構造になっています。
一方で.xbrlファイルは1ファイルしかありません。
全データがここに集約されています。
どちらを使っても問題ありませんが、僕は.xbrlファイルから収集しています。
例えば、.htmファイルには、決算情報の概要をまとめているページがあります。
こんな感じです。
有価証券報告書の冒頭部分で必ず登場するページです。
こちらは株式会社セキチューの第70期の有価証券報告書です。
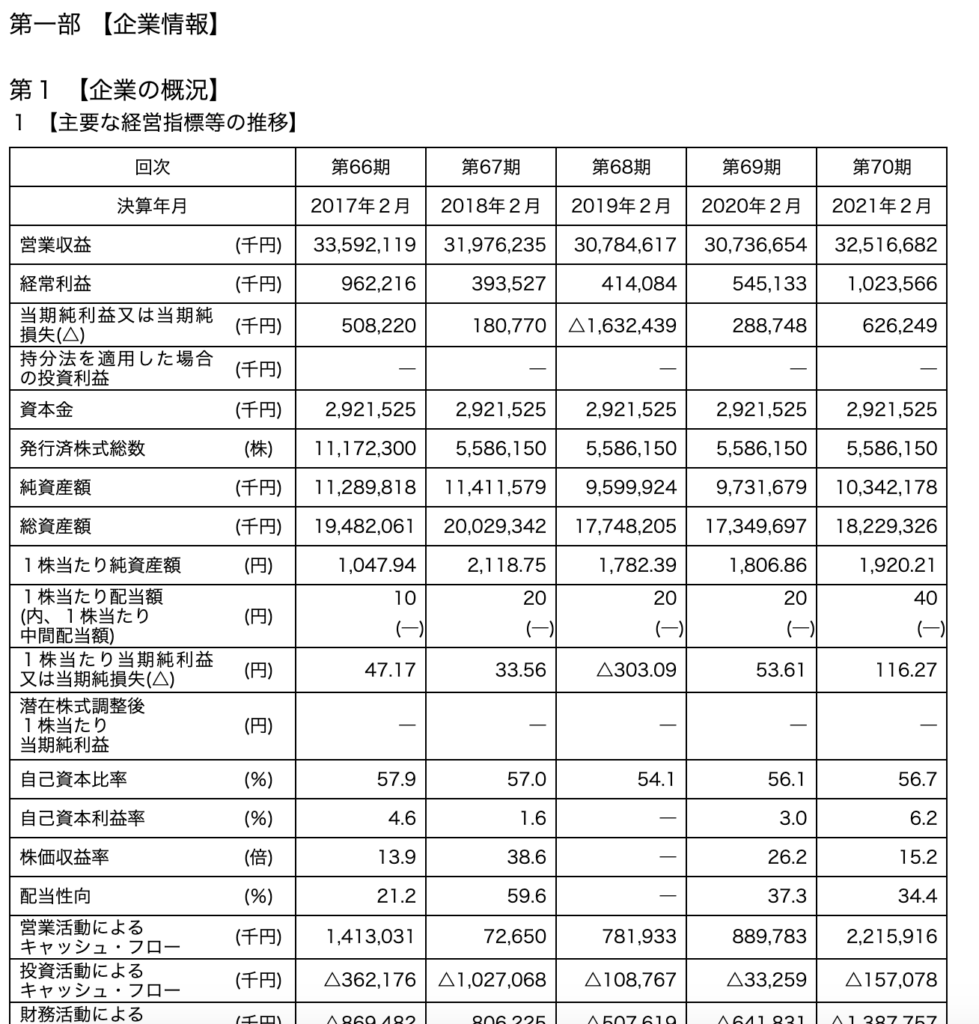
ここを確認すれば、主要な経営指標などを確認することができます。
ここにないデータについては詳細データから取得する必要があります。
一方、.xbrlファイルを開いてみると文字の羅列です。
人間には読みにくいフォーマットです。
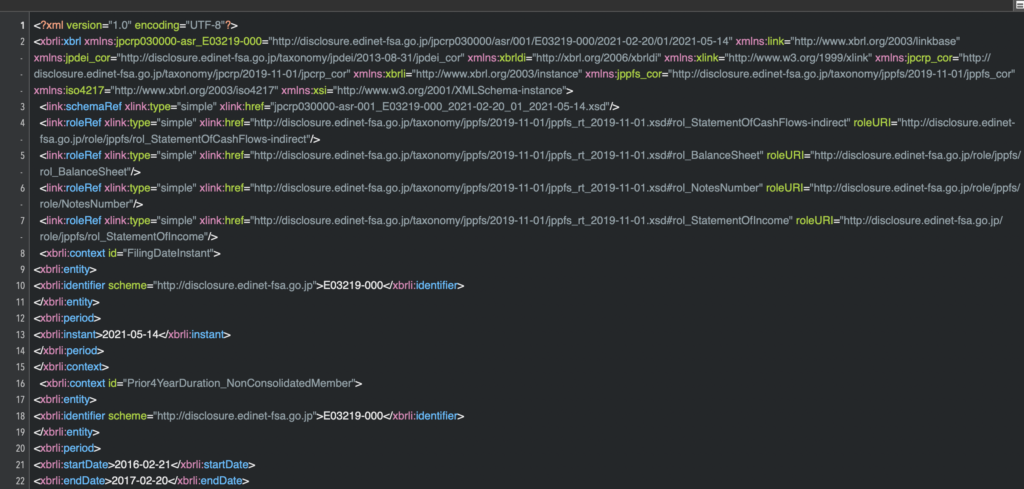
ここから必要なデータを抽出していくことになります。
1つだけ例としてデータを検索してみましょう。
.htmファイルにある最新の売上高32,516,682を探してみます。

htmlファイルでは千円単位になっていますが、.xbrlファイルでは生データがそのまま入っています。
TDNETの時と同様に、contextRefやdecimalsなどのデータもあります。
冒頭のjpcrp_crp:以降の値から、OperatingRevenueつまりは売上高であることも確認できますね。
よって、EDINETの場合も、TDNETと同様に各値に付随するデータを取得すれば、その値が何を意味しているのかがわかるようになっています。
EDINETのタクソノミーについてもEDINETページに資料があります。
この資料と突合すれば、何がどのデータを示しているかを確認できます。
XBRLデータを収集する
XBRLデータについてわかったところで、データを収集します。
このデータ収集自体はそこまで難しくありません。
TDNETの.htmファイル、EDINETの.xbrlファイルを対象に、各値に付随するデータを根こそぎ収集すればOKです。
EDINETのデータを集めるとこんな感じになります。
こちらはトヨタ自動車のデータです。
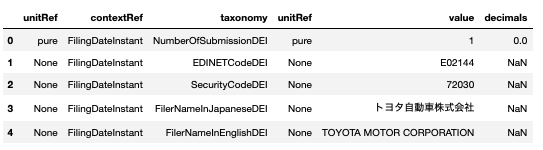
それぞれの値に付随するtaxonomyやunitrefなどを収集します。
これをデータベースに更新していつでも呼び出せるようにしておけばOKです。
「データを加工して必要なものだけをデータベースに突っ込んだ方が効率いいんじゃないか?」と思った方は鋭いです。
実際、その通りです。
ただ、僕の場合は後からデータをいじくったりする場合もあると思ったため、生データを全て突っ込むデータベースを用意して、とりあえずはそこに全てを更新することにしました。
そして整形したデータを管理するデータベースを別途用意して、整形したデータはこちらで管理するようにしました。
データの整形はこの後紹介しますが、かなり大変です。
後から間違えに気づいてもすぐに更新できるように、生データは容量が大きくなってもいいから全て保管しておこうと考えました。
実際、僕が使用しているエックスサーバーであれば、データベースの作成数や容量に応じて料金が変わることもないので、迷うことなくデータベースによる管理を選びました。
AWSとかになるとデータベースはコストがかかるので、生データはデータベースに突っ込まずにAWSで.xbrlファイルのまま保存しておく方がコストを抑えることができると思います。
とりあえず個人で使うサーバーとしてはスペック的にみてもコスパでみてもエックスサーバーは最強に思います。
![]()
![]()
収集したXBRLデータを整形する ← これが地獄
データの収集が終われば次にやるべきはデータ整形です。
このままだとデータ量が多すぎてデータを取得する際にも時間がかかってしまいますし、横並びで銘柄を比較したりするにもとても不便です。
よって、扱いやすいように整形して新たなデータベースに突っ込んでおく必要があります。
この新たなデータベースから基本的にはデータを取得して分析などに利用することになります。
業種などによってタクソノミーは異なる
そしてこの整形作業が地獄の始まりです。
理由は明白です。
業種などによってタクソノミーは異なるからです。
ポイント
XBRLのタクソノミーは業種などによって異なる。
どういうことかと言いますと、同じ売上高でも、1つの銘柄ではNetSalesと記載されているのに対して、別の銘柄では違う書き方がされているということです。
結果、異なる銘柄どうしの売上高を比較しようにもタクソノミーが異なればデータが取得できないので、そのままでは比較ができないことになります。
よって横並びで比較するためにも、データの容量を必要なものだけに絞ってコンパクトにするためにも、このデータ整形作業が非常に大事になってきます。
売上高を示すタクソノミーが多すぎる・・・
例として売上高のタクソノミーをみてみましょう。
地獄という理由がお分かりいただけるかと思いますw
「売上高」を示すタクソノミー
"NetSalesSummaryOfBusinessResults",
"NetSales",
"OperatingRevenue1SummaryOfBusinessResults",
"OperatingRevenue1",
"ShippingBusinessRevenueWAT",
"ShippingBusinessRevenueAndOtherOperatingRevenueWATSummaryOfBusinessResults",
"ShippingBusinessRevenueAndOtherOperatingRevenueWAT",
"ShippingBusinessRevenueAndOtherServiceRevenueWATSummaryOfBusinessResults",
"ShippingBusinessRevenueAndOtherServiceRevenueWAT",
"OperatingRevenueELESummaryOfBusinessResults",
"OperatingRevenueELE",
"OperatingRevenueRWYSummaryOfBusinessResults",
"OperatingRevenueRWY",
"OperatingRevenueSECSummaryOfBusinessResults",
"OperatingRevenueSEC",
"ContractsCompletedRevOASummaryOfBusinessResults",
"ContractsCompletedRevOA",
"NetSalesNSSummaryOfBusinessResults",
"NetSalesNS",
"PLJHFDAKJHGFSummaryOfBusinessResults",
"PLJHFDAKJHGF",
"SalesAllSegmentsSummaryOfBusinessResults",
"SalesAllSegments",
"SalesDetailsSummaryOfBusinessResults",
"SalesDetails",
"TotalSalesSummaryOfBusinessResults",
"TotalSales",
"SalesAndOtherOperatingRevenueSummaryOfBusinessResults",
"SalesAndOtherOperatingRevenue",
"NetSalesAndOtherOperatingRevenueSummaryOfBusinessResults",
"NetSalesAndOtherOperatingRevenue",
"NetSalesAndServiceRevenueSummaryOfBusinessResults",
"NetSalesAndServiceRevenue",
"NetSalesAndOperatingRevenueSummaryOfBusinessResults",
"NetSalesAndOperatingRevenue",
"NetSalesAndOperatingRevenue2SummaryOfBusinessResults",
"NetSalesAndOperatingRevenue2",
"NetSalesAndOperatingRevenueSummaryOfBusinessResults",
"NetSalesAndOperatingRevenue",
"NetSalesOfFinishedGoodsRevOASummaryOfBusinessResults",
"NetSalesOfFinishedGoodsRevOA",
"NetSalesOfMerchandiseAndFinishedGoodsRevOASummaryOfBusinessResults",
"NetSalesOfMerchandiseAndFinishedGoodsRevOA",
"RevenuesUSGAAPSummaryOfBusinessResultsSummaryOfBusinessResults",
"RevenuesUSGAAPSummaryOfBusinessResults",
"NetSalesIFRSSummaryOfBusinessResults",
"NetSalesIFRS",
"OperatingRevenuesIFRSKeyFinancialDataSummaryOfBusinessResults",
"OperatingRevenuesIFRSKeyFinancialData",
"TotalTradingTransactionIFRSSummaryOfBusinessResults",
"TotalTradingTransactionIFRS",
"TotalTradingTransactionsIFRSSummaryOfBusinessResults",
"TotalTradingTransactionsIFRS",
"RevenueSummaryOfBusinessResults",
"Revenue",
"RevenueIFRSSummaryOfBusinessResults",
"RevenueIFRS",
"OperatingRevenue2SummaryOfBusinessResults",
"OperatingRevenue2",
"GrossOperatingRevenueSummaryOfBusinessResults",
"GrossOperatingRevenue",
"NetSalesRevOASummaryOfBusinessResults",
"NetSalesRevOA",
"InsurancePremiumsAndOtherOIINSSummaryOfBusinessResults",
"InsurancePremiumsAndOtherOIINS",
"PremiumAndOtherIncomeSummaryOfBusinessResults",
"PremiumAndOtherIncome",
"InsurancePremiumsAndOtherIncomeSummaryOfBusinessResults",
"InsurancePremiumsAndOtherIncome",
"InsurancePremiumsAndOthersSummaryOfBusinessResults",
"InsurancePremiumsAndOthers",
"InsurancePremiumsAndOtherSummaryOfBusinessResults",
"InsurancePremiumsAndOther",
"NetSalesOfCompletedConstructionContractsCNSSummaryOfBusinessResults",
"NetSalesOfCompletedConstructionContractsCNS",
"NetSalesOfCompletedConstructionContractsSummaryOfBusinessResults",
"NetSalesOfCompletedConstructionContracts",
"ContractsCompletedSummaryOfBusinessResults",
"ContractsCompleted",
"RentIncomeOfRealEstateRevOASummaryOfBusinessResults",
"RentIncomeOfRealEstateRevOA",
"OperatingRevenueSPFSummaryOfBusinessResults",
"OperatingRevenueSPF",
"OperatingRevenueIVTSummaryOfBusinessResults",
"OperatingRevenueIVT",
"OperatingRevenueCMDSummaryOfBusinessResults",
"OperatingRevenueCMD",
"OperatingRevenueOILTelecommunicationsSummaryOfBusinessResults",
"OperatingRevenueOILTelecommunications",
"OperatingRevenue1SummaryOfBusinessResults",
"OperatingRevenue1",
"OrdinaryIncomeBNKSummaryOfBusinessResults",
"OrdinaryIncomeBNK",
"OperatingIncomeINSSummaryOfBusinessResults",
"OperatingIncomeINS",
"BusinessRevenuesSummaryOfBusinessResults",
"BusinessRevenues",
"BusinessRevenueSummaryOfBusinessResults",
"BusinessRevenue"
"BusinessRevenueRevOASummaryOfBusinessResults",
"BusinessRevenueRevOA",
"OperatingRevenueSummaryOfBusinessResults",
"OperatingRevenue",
"SummaryOfSalesBusinessResults",
"SummaryOfSales",
"OperatingRevenuesSummaryOfBusinessResults"
"OperatingRevenues",
"OrdinaryIncomeSummaryOfBusinessResults"
基本的には、最後にSummaryOfBusinessResultsがつくものとつかないものがあるので、実際の個数はこの半分ほどです。
半分だとしても結構な数ですよね。
ここからどのような作業が必要かというと、
各データの売上高と思われるデータを取得 → Yahoo!ファイナンスや株探などのデータと照らし合わせる → 一致していればそのタクソノミーをプログラムに組み入れる
この作業をひたすら繰り返します。
これがなかなかのマニュアル地獄作業です。
もちろん売上高以外にもEPSやROEなど、それぞれのデータについてこういった検証作業が必要になります。
データ収集を自動化するためにプログラムを頑張って開発していたのに、こんな作業が後から必要になってくるとは思いませんでした。
控えめにいっても地獄ですw
タクソノミの検証作業はこれからも続く・・・
僕自身、ある程度のタクソノミーの検証作業は行ってきました。
8〜9割くらいの精度でデータ整形できていると思います。
ただ、決して完璧ではないことも事実です。
3,000銘柄以上ある日本の個別銘柄を1個ずつ全てチェックしていくのは非現実的ですし、さらに言えば現状だと特に必要としている一部のデータしか整形作業は完了していません。
欲しいデータが増えるたびにこの検証作業は続きます。
そしてもちろん、XBRLの仕様が変更されたりしたら、これらの作業は振り出しに戻ります。
ということで、これからも地道に作業を進めていくつもりです。。。
ただ、完全なマニュアル作業とは異なり、プログラムの場合は一度作業を行ってしまえば、それ以降はプログラムが自動でデータを識別してデータベースを管理してくれます。
これがプログラミングの醍醐味の1つでもあります。
よって、この作業を頑張れば頑張るほど未来の作業が低減されます。
完全マニュアルで作業をしているとこうはいきません。
そういうことで、引き続き頑張ります。
収集したデータを配布しています。
最後にお知らせです。
ここまでご紹介した通り、僕が運営している「投資でニート生活」では、TDNETやEDINETから各種XBRLデータを収集しています。
地獄の検証作業の甲斐あって、そこそこ使えるデータセットになってきました。
また、XBRL以外のデータも収集してます。
基本的には、僕がバイブルとして愛用している「オニールの成長株発掘法」と「ミネルヴィニの成長株投資法」で紹介されている投資手法で必要となるデータを収集しています。


特によく活用しているデータが、「オニールの成長株発掘法」で紹介されているレラティブストレングスと「ミネルヴィニの成長株投資法」で紹介されているトレンドテンプレートです。
-

【毎週無料公開】日本株でレラティブストレングスっぽいものを計算する【オニールの成長株発掘法】
続きを見る
-

【毎週無料公開】日本株にミネルヴィニのトレンドテンプレートを適用してスクリーニングする!
続きを見る
こういった様々なデータを収集して、銘柄のスクリーニングを行ったりして銘柄選定のプロセスを効率化しています。
そして、データ収集が進みつつ、おかげさまで本ブログや「投資でニート生活」のアクセスが増えるに連れて、「収集したデータを売ってください」という旨のリクエストが増えてきました。
最初は正直スルーしていたのですが、さすがにリクエストがだいぶ増えてきたのでデータを販売することとしました。
noteで「【オニール×ミネルヴィニ】TATの日本成長株投資研究所」という名前のマガジンを作り、ここでデータを販売してます。

→ 「【オニール×ミネルヴィニ】TATの日本成長株投資研究所」を見る
ここには「オニールの成長株発掘法」と「ミネルヴィニの成長株投資法」の投資手法で重要視されている様々なデータをまとめて、誰でもスクリーニングができるようにCSV形式で配布しています。
直近数四半期や過去3年間の業績推移(特に売上高とEPS)と前年同期比の成長率、レラティブストレングス、大量保有報告書、52週高値更新など、様々なデータをまとめています。
1銘柄ずつこれらの項目をチェックするとなると結構な時間を要します。
しかし、こちらで販売しているデータを利用すれば作業時間をかなり短縮できます。
浮いた時間でさらに細かい銘柄分析などに活用いただければと思います。
もしご興味があれば是非ともご覧ください。
実際、僕はこういったデータを活用して銘柄選定の作業を効率化しています。
オニールやミネルヴィニの投資手法は多くの方に参考にされている、成長株投資のバイブル的存在ですが、銘柄選定のプロセスが結構大変で、全て実行しようと思うと結構な時間を要します。
たくさん時間を用意できる方(専業投資家とか?)なら可能でしょうが、僕のような兼業投資家にはなかなかきついのが現状です。
この状況を打破するために、僕は趣味のプログラミングの力を駆使して、銘柄選定を効率化することに尽力しています。
データの分析・可視化にはPythonが最適!
本記事で紹介したコードは、全てPythonを使って書いています。
Pythonはデータの分析や可視化を得意とするプログラミング言語で、さらにAI関連のライブラリーも豊富で昨今のAIブームで需要が急拡大しています。
→ 【いますぐ始められます】データ分析をするならPythonが最適です。
また、Pythonは比較的学びやすい言語でもあります。
実際、僕は社会人になってからPythonを独学で習得して転職にも成功し、Python独学をきっかけに人生が大きく変わりました。
→ 【実体験】ゼロからのPython独学を決意してから転職を掴み取るまでのお話。
Pythonの学習方法についてはいろいろな方法があります。
僕はUdemyを選びましたが、書籍やプログラミングスクールも選択肢になります。
→ 【決定版】Python独学ロードマップ【完全初心者からでもOKです】
→ 【まとめ】Pythonが学べるおすすめプログラミングスクール
→ プログラミングの独学にUdemyをおすすめする理由!【僕はUdemyでPythonを独学しました!】
まとめ
いかがでしたでしょうか。
ここでは、TDNETやEDINETからXBRLデータを収集したら地獄だったという僕の体験談をご紹介しました。
とても大変な作業ですが、リターンもかなり大きくて、銘柄選定の作業が大幅に短縮されて、本業で時間がない状況でも効率よく銘柄選定ができるようになっています。
結果として、リクエストも増加してデータを販売するようにもなりました。
作業しているときは地獄のような作業でしたが、目に見える形でたくさんのメリットをもたらしてくれているので、本当にやってよかったと思います。
そして途中で挫折せずによくここまできたなとも思いますw
この記事を読んで「よーし、僕もXBRL集めるぞ」というきっかけになれば嬉しいですが、「大変そうだな」と感じる方は是非とも僕のnoteで販売しているデータを見てみてください。
そのまま僕のデータを利用していただいても良いですし、活用できると判断すれば自分でデータ収集をするためのモチベーションも上がるのではないでしょうか。
ここまで読んでくださり、ありがとうございました。








{kind=link}