

こんにちは。TATです。
今日のテーマは「【Python】SeleniumでSBI証券から日本株の注文をキャンセルする方法」です。
PythonとSeleniumを使って、SBI証券のサイトから日本株の注文をキャンセルする操作を自動化してみます。
過去の記事では、Seleniumで日本株の新規の売買注文を入れる方法について解説しました。
今回はこの注文をキャンセルする方法を解説します。
目次
SBI証券へのログイン
事前準備として、PythonとSeleniumでSBI証券にログインしておく必要があります。
Seleniumの準備やSBI証券へログインする方法についてはこちらの記事で解説しています。
ログインが完了したら、本記事で紹介するコードを実行することができます。
-

【Python】SeleniumでSBI証券に自動ログインする方法【自動売買への道】
続きを見る
日本株の注文をキャンセルするまでの流れ
次にPythonとSeleniumでSBI証券のサイトから日本株の注文をキャンセルするまでの流れについて確認しておきます。
ざっくりとこんな感じです。
日本株を売買するまでの流れ
- (SeleniumでSBI証券にログイン)
- 「取引」から「注文照会 取消・訂正」ページへ遷移する
- 注文データ一覧を取得する
- キャンセルしたい注文の「取消」ボタンをクリックする
- 取引パスワードを入力して「注文取消」ボタンをクリックする
- 遷移後のページから注文が成功したかをチェックする
1についてはこちらの記事で解説している内容になるので、()書きにしました。
本記事では1はスキップして、2〜6を実装する方法を解説していきます。
PythonとSeleniumでSBI証券サイトから日本株の注文のキャンセルを実装する
それでは2~6の流れを順番に解説していきます。
「取引」から「注文照会 取消・訂正」ページへ遷移する
まずは「取引」から「注文照会 取消・訂正」ページへ遷移します。
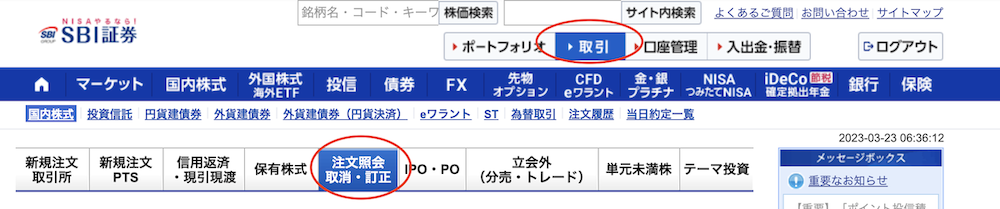
Chromeの「検証」からそれぞれの要素をチェックします。
「取引」については、title="取引"となっているので、これを利用すれば要素を取得できます。

「注文照会 取消・訂正」については、特にこれを特定できる要素はありませんでした。
ここでは「注文照会 取消・訂正」という文字をキーにして要素を取得したいと思います。
「注文照会」と「取消・訂正」の間に<br>が入っているので要注意です。
文字の一部から要素を特定してみます。

Seleniumで実装すると次のようなコードになります。
from selenium import webdriver
# 注文ページへ遷移
driver.find_element_by_css_selector("img[title=取引]").click()
driver.implicitly_wait(60)
# 注文照会、取り消し・訂正ページへ遷移
driver.find_element_by_partial_link_text("注文照会").click()
driver.implicitly_wait(60)
これで「注文照会 取消・訂正」ページへ遷移することができます。
データの読み込み時間を考慮して、driver.implicitly_wait(60)を加えました。
これは次の処理を行うにあたり、対象となる要素が見つかるまで待機するという命令になります。
これがないとページが読み込まれる前に値を入力しようしたり次の処理を行おうとしてエラーが発生する場合があるので、処理に時間がかかる箇所に追加しておくとプログラムの安定感が増します。
以上で最初のステップは完了です。
注文データ一覧を取得する
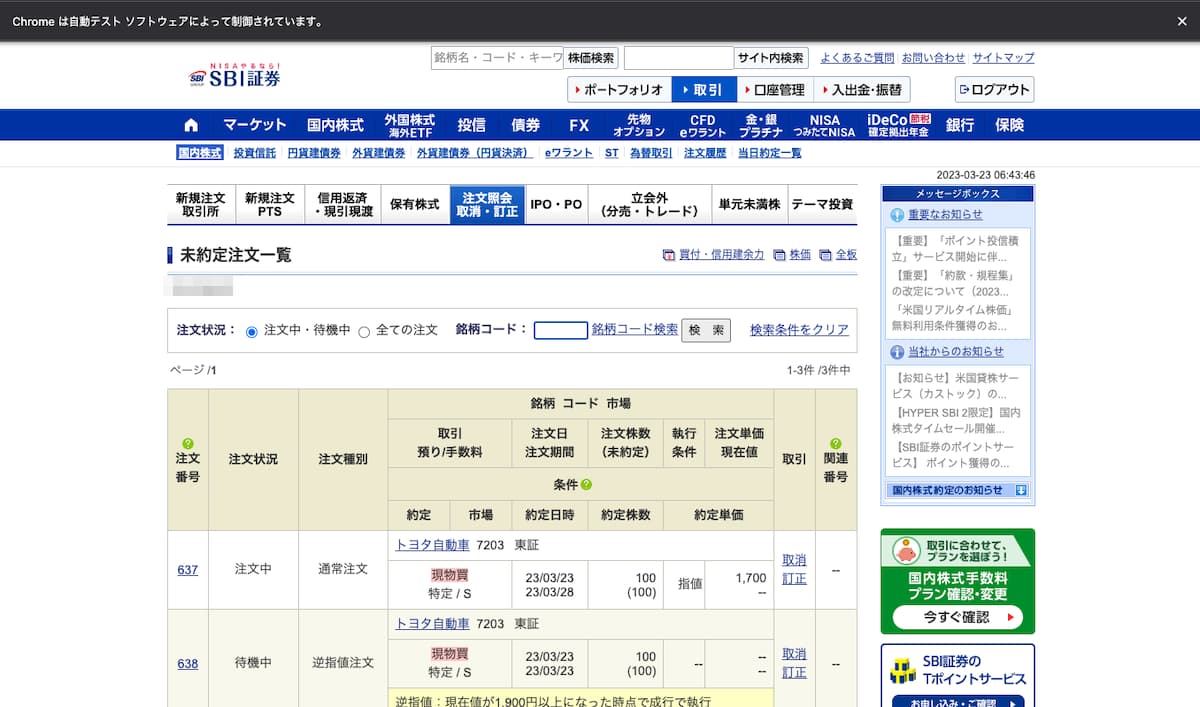
次に注文データの一覧を取得します。
「注文照会 取消・訂正」を見ると、現在注文中のデータ一覧を確認できます。
ここではデモ用に適当なオーダーを入れておきましたw
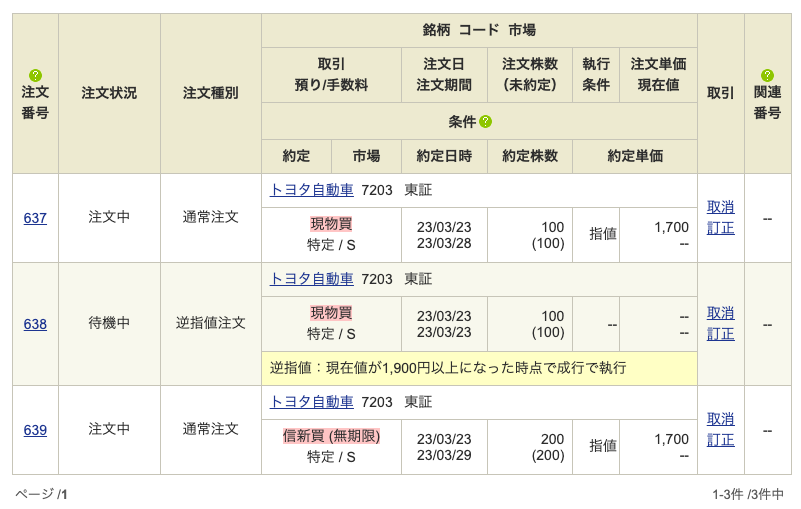
注文番号がわかれば特定できる
重要になるのが注文番号です。
取消をしたい注文の注文番号がわかっていれば簡単に対象の注文を特定することができます。
注文番号については、注文が完了した際に確認できます。
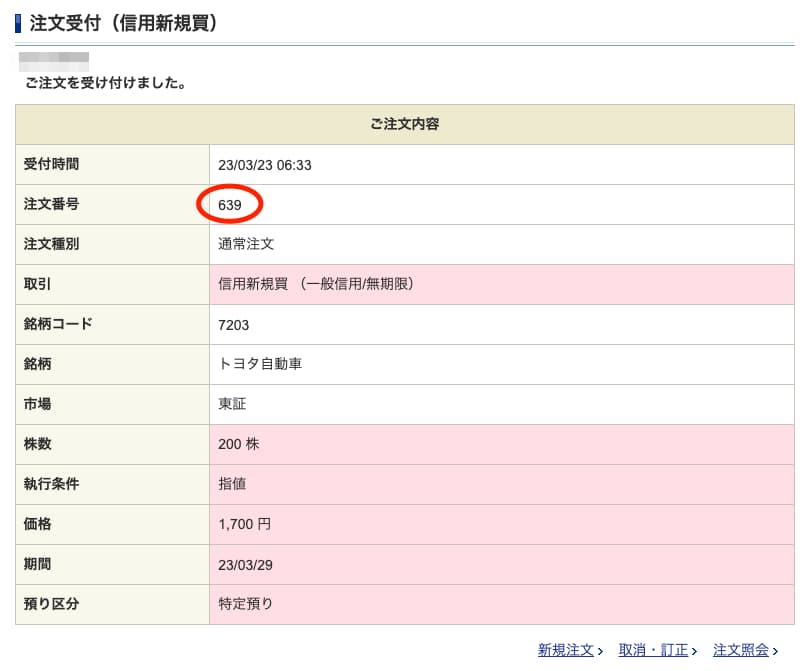
自動売買のシステムを構築する際には、この注文番号を注文完了時に何処かに保管しておくと、キャンセルするときに便利です。
とりあえず注文データ一覧を取得する
ここでは注文番号を把握してない時のことを考慮して、一旦ここにあるデータを取得してみます。
Beautifulsoupを使ってこのテーブルにあるデータを取得しました。
マルチインデックスになってるので結構厄介なのですが、注文番号が存在している行を判定して、そこから必要な情報に順番にアクセスしていきました。
細かい解説は割愛しますが、コード内になるべく多くのコメントをつけたので参考にしてみてください。
import unicodedata
from bs4 import BeautifulSoup
import re
import pandas as pd
# tableを抽出, 「注文状況」というカラムを検索して、そのtableを取得
html = BeautifulSoup(driver.page_source, "html.parser")
table = html.find("th", text=re.compile("注文状況")).findParent("table")
# データを格納する変数を定義
data = []
# tableの各行を処理する
for tr in table.find("tbody").findAll("tr"): #tbodyの全行(tr)を取得
#最初のtdにa要素があれば注文番号があると判断する
if tr.find("td").find("a"):
# 行のデータを格納する変数を定義
row = []
# 注文番号
row.append(tr.findAll("td")[0].getText().strip())
# 注文状況
row.append(tr.findAll("td")[1].getText().strip())
# 注文種別
row.append(tr.findAll("td")[2].getText().strip())
# 銘柄、コード 同じtdにまとまっているので分割してそれぞれのデータを取得する
text = unicodedata.normalize("NFKC", tr.findAll("td")[3].getText().strip())
row.append(text.splitlines()[0].strip().split(" ")[0])
row.append(text.splitlines()[0].strip().split(" ")[-1])
"""
ここからは次に行のデータを取得
"""
#取引、預り、手数料 同じtd内にまとまっているので分割してそれぞれのデータを取得する
tmp_data = []
for t in tr.findNext("tr").findAll("td")[0].getText().strip().replace(" ", "").splitlines():
if t!="" and t!="/":
tmp_data.append(t)
# 信用取引の場合は取得される要素数が増えるので、要素数によって処理を分ける
if len(tmp_data)==4:
row.extend([tmp_data[0]+tmp_data[1], tmp_data[2], tmp_data[3]])
else:
row.extend(tmp_data)
# 注文日、注文期間 同じtd内にまとまっているので分割してそれぞれのデータを取得する
row.extend(tr.findNext("tr").findAll("td")[1].getText().replace(" ", "").strip().splitlines())
# 注文株数、(未約定) 同じtd内にまとまっているので分割してそれぞれのデータを取得する
row.append(tr.findNext("tr").findAll("td")[2].getText().replace(" ", "").strip().splitlines()[0])
row.append(tr.findNext("tr").findAll("td")[2].getText().replace(" ", "").strip().splitlines()[-1])
# 執行条件
row.append(tr.findNext("tr").findAll("td")[3].getText().strip())
# 注文単価、現在値
row.extend(tr.findNext("tr").findAll("td")[4].getText().strip().replace(" ", "").splitlines())
"""
ここからは2行後のデータから条件を取得 該当データがない場合は--とする
"""
# 条件
if not tr.findNext("tr").findNext("tr").find("td").find("a"):
row.append(tr.findNext("tr").findNext("tr").find("td").getText().strip())
else:
row.append("--")
# dataに行データを追加
data.append(row)
# カラム名を定義
columns = ["注文番号", "注文状況", "注文種別", "銘柄", "コード", "取引", "預り", "手数料", "注文日",
"注文期間", "注文株数", "(未約定)", "執行条件", "注文単価", "現在値", "条件"]
# DataFrameに変換
df = pd.DataFrame(data, columns=columns)
# 注文番号をintに変換
df["注文番号"] = df["注文番号"].astype(int)
これで綺麗にデータを取得することができます。
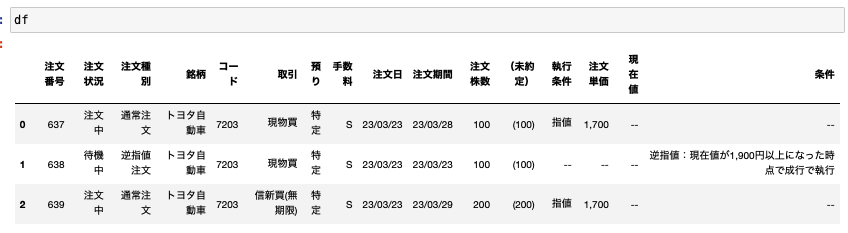
ここから条件指定などをして取消をしたい注文を特定することができれば便利ですね。
キャンセルしたい注文の「取消」ボタンをクリックする
次にキャンセルの処理をしていきます。
キャンセルしたい注文が特定できれば、その注文の「取消」ボタンをクリックします。
「取消」ボタンを確認すると、特に要素を特定できる要素はないので文字をキーにして要素を取得します。
# 取消ボタンを取得
driver.find_elements_by_link_text("取消")
先ほど収集したテーブルデータ(df)の行数と一致していますね。
そしてこの取得できた要素はリスト形式になっているので、indexで特定の要素にアクセスできます。
これはdfのindexと一致しているので活用できます。
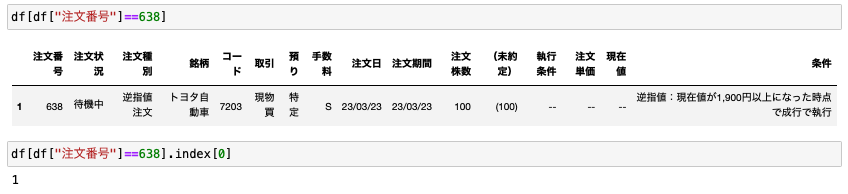
ここでは例として注文番号「639」をキャンセルしてみましょう。
dfを確認するとindexは2ですので、これを利用して「取消」ボタンをクリックします。
# 取消をクリック
driver.find_elements_by_link_text("取消")[2].click()
これで注文取消画面に遷移します。
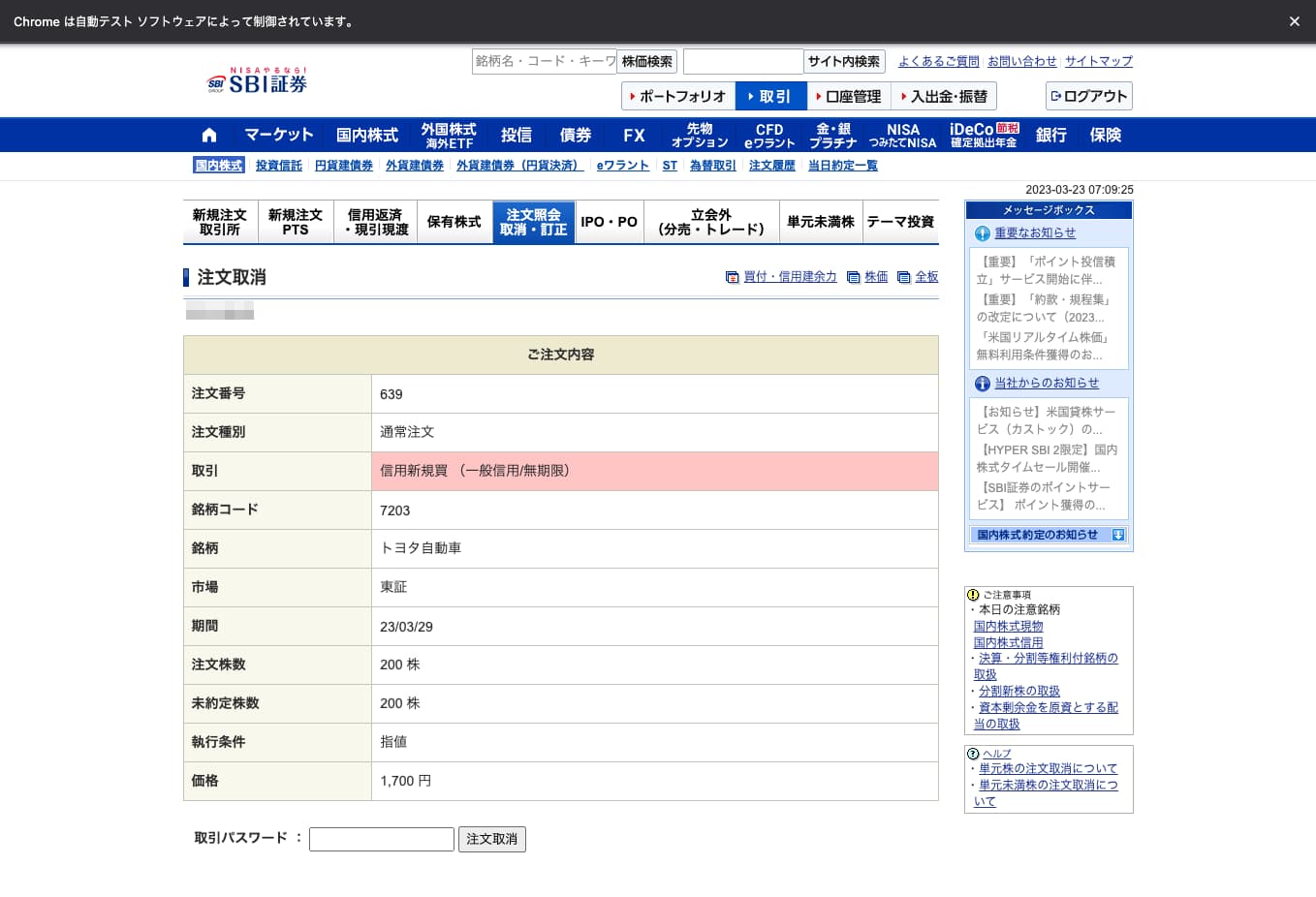
取引パスワードを入力して「注文取消」ボタンをクリックする
注文のキャンセルを確定させるためには、取引パスワードを入力して「注文取消」ボタンをクリックします。
要素を確認してみます。
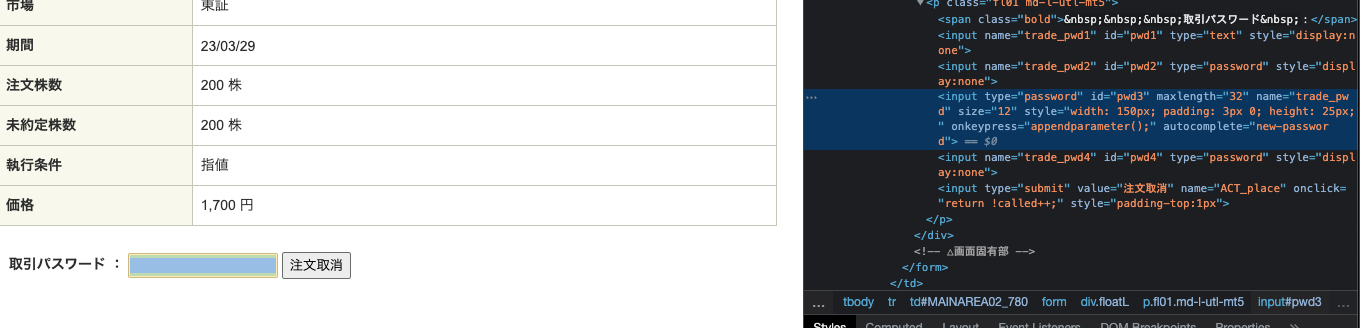
取引パスワードはid="pwd3"となっています。「注文取消」ボタンについては、value="注文取消"となっているので、これらの要素を利用して処理を実装します。
# 取引パスワード
trade_password = "password"
driver.find_element_by_id("pwd3").send_keys(trade_password)
# 注文取消を確定
driver.find_element_by_css_selector("input[value=注文取消]").click()
これで注文取消が確定します。
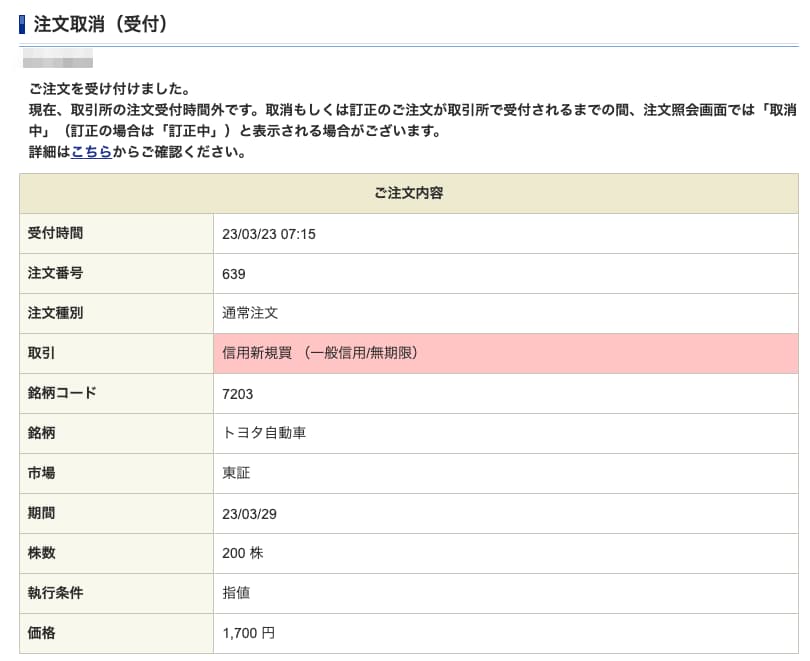
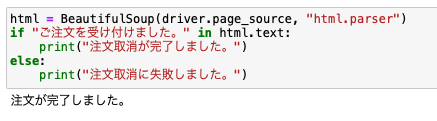
遷移後のページから注文取消が成功したかをチェックする
最後に遷移後のページから注文取消が成功したのかどうかを確認します。
注文取消が成功すると、「ご注文を受け付けました。」という文言が表示されます。
これがあるかどうかをチェックすればOKです。
html = BeautifulSoup(driver.page_source, "html.parser")
if "ご注文を受け付けました。" in html.text:
print("注文取消が完了しました。")
else:
print("注文取消に失敗しました。")
かなりシンプルですが、これで十分に機能します。
注意点
ここで1つだけ注意点です。
注文取消が完了してもう一度「注文照会 取消・訂正」のページを確認すると、注文状況が取消中となります。
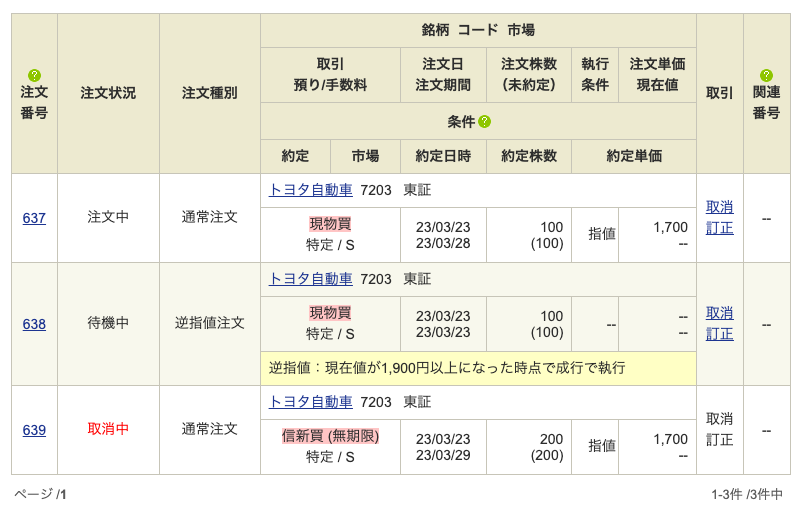
しばらくすると取消が完了して、この行そのものが消えるのですが、しばらく残っているので連続で注文を取り消す際には注意が必要です。
取消中の注文は取消のリンクが無効になっているので、行数とリンクの数が合わなくなってしまいます。
これを調整するためには、取得したdfから注文状況が取消中になっている行を削除して、indexをリセットしてあげればOKです。
df = df[df["注文状況"]!="取消中"].reset_index(drop=True)
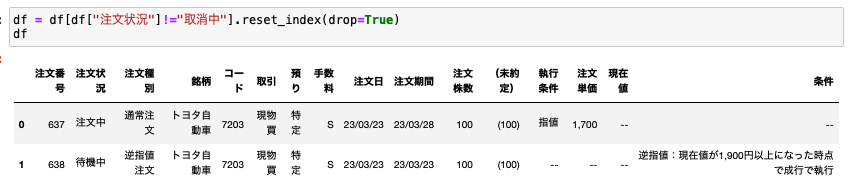
これでリンクの数とdfの行数が一致します。
連続で注文取消を行うこともあると思うので、この処理を加えておくと安心です。
最後にコードをまとめてどうぞ!
ここまでの内容で、PythonとSeleniumを使って注文をキャンセルすることができました。
最後に、これまでのコードをまとめたものを共有します。
注文一覧のテーブルデータの取得については関数にしました。
なるべくコメントも多くつけましたつもりです。
コピペ用にどうぞ。
from selenium import webdriver
import unicodedata
from bs4 import BeautifulSoup
import re
import pandas as pd
def extract_order_list(html):
# tableを抽出, 「注文状況」というカラムを検索して、そのtableを取得
table = html.find("th", text=re.compile("注文状況")).findParent("table")
# データを格納する変数を定義
data = []
# tableの各行を処理する
for tr in table.find("tbody").findAll("tr"): #tbodyの全行(tr)を取得
#最初のtdにa要素があれば注文番号があると判断する
if tr.find("td").find("a"):
# 行のデータを格納する変数を定義
row = []
# 注文番号
row.append(tr.findAll("td")[0].getText().strip())
# 注文状況
row.append(tr.findAll("td")[1].getText().strip())
# 注文種別
row.append(tr.findAll("td")[2].getText().strip())
# 銘柄、コード 同じtdにまとまっているので分割してそれぞれのデータを取得する
text = unicodedata.normalize("NFKC", tr.findAll("td")[3].getText().strip())
row.append(text.splitlines()[0].strip().split(" ")[0])
row.append(text.splitlines()[0].strip().split(" ")[-1])
"""
ここからは次に行のデータを取得
"""
#取引、預り、手数料 同じtd内にまとまっているので分割してそれぞれのデータを取得する
tmp_data = []
for t in tr.findNext("tr").findAll("td")[0].getText().strip().replace(" ", "").splitlines():
if t!="" and t!="/":
tmp_data.append(t)
# 信用取引の場合は取得される要素数が増えるので、要素数によって処理を分ける
if len(tmp_data)==4:
row.extend([tmp_data[0]+tmp_data[1], tmp_data[2], tmp_data[3]])
else:
row.extend(tmp_data)
# 注文日、注文期間 同じtd内にまとまっているので分割してそれぞれのデータを取得する
row.extend(tr.findNext("tr").findAll("td")[1].getText().replace(" ", "").strip().splitlines())
# 注文株数、(未約定) 同じtd内にまとまっているので分割してそれぞれのデータを取得する
row.append(tr.findNext("tr").findAll("td")[2].getText().replace(" ", "").strip().splitlines()[0])
row.append(tr.findNext("tr").findAll("td")[2].getText().replace(" ", "").strip().splitlines()[-1])
# 執行条件
row.append(tr.findNext("tr").findAll("td")[3].getText().strip())
# 注文単価、現在値
row.extend(tr.findNext("tr").findAll("td")[4].getText().strip().replace(" ", "").splitlines())
"""
ここからは2行後のデータから条件を取得 該当データがない場合は--とする
"""
# 条件
if not tr.findNext("tr").findNext("tr").find("td").find("a"):
row.append(tr.findNext("tr").findNext("tr").find("td").getText().strip())
else:
row.append("--")
# dataに行データを追加
data.append(row)
# カラム名を定義
columns = ["注文番号", "注文状況", "注文種別", "銘柄", "コード", "取引", "預り", "手数料", "注文日",
"注文期間", "注文株数", "(未約定)", "執行条件", "注文単価", "現在値", "条件"]
# DataFrameに変換
df = pd.DataFrame(data, columns=columns)
# 注文番号をintに変換
df["注文番号"] = df["注文番号"].astype(int)
# 注文状況が取消中の行を削除してindexをリセット
df = df[df["注文状況"]!="取消中"].reset_index(drop=True)
return df
# 注文ページへ遷移
driver.find_element_by_css_selector("img[title=取引]").click()
driver.implicitly_wait(60)
# 注文照会、取り消し・訂正ページへ遷移
driver.find_element_by_partial_link_text("注文照会").click()
driver.implicitly_wait(60)
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# 注文一覧を取得
df = extract_order_list(html)
# 任意取消をクリック ここではindexで2を指定
driver.find_elements_by_link_text("取消")[2].click()
# 取引パスワード
trade_password = "password"
driver.find_element_by_id("pwd3").send_keys(trade_password)
# 注文取消を確定
driver.find_element_by_css_selector("input[value=注文取消]").click()
# 注文取消が成功したかをチェック
html = BeautifulSoup(driver.page_source, "html.parser")
if "ご注文を受け付けました。" in html.text:
print("注文取消が完了しました。")
else:
print("注文取消に失敗しました。")
テーブルデータの取得がなければ結構短いコードで実装できてしまいますね。
dfを利用すれば、注文条件でキャンセルしたいオーダーを特定することができます。
注文番号がわかっていればその値がある行のindexを取得すればOKです。
これで、PythonとSeleniumで任意の注文をキャンセルできるようになりました。
まとめ
本記事では「【Python】SeleniumでSBI証券から日本株の注文をキャンセルする方法」について解説しました。
PythonとSeleniumを利用すれば、SBI証券に自動ログイン(参考記事)して、そこから日本株の新規注文を入れたり、本記事で紹介したように注文をキャンセルすることもできます。
新規注文を入れる方法については過去の記事をご参照ください。
最後まで読んでくださり、ありがとうございました。









{kind=link}