

こんにちは。TATです。
今日のテーマは「【Python】SeleniumでSBI証券から日本株の約定履歴を収集する方法」です。
PythonとSeleniumを使って、SBI証券のサイトから日本株の約定履歴を収集する操作を自動化してみます。
月別の売買金額を集計したり、株価チャートに売買タイミングを表示して確認したり、いろいろなことに活用することができます。
目次
SBI証券へのログイン
事前準備として、PythonとSeleniumでSBI証券にログインしておく必要があります。
Seleniumの準備やSBI証券へログインする方法についてはこちらの記事で解説しています。
ログインが完了したら、本記事で紹介するコードを実行することができます。
-

【Python】SeleniumでSBI証券に自動ログインする方法【自動売買への道】
続きを見る
日本株の約定履歴を収集するまでの流れ
次にPythonとSeleniumでSBI証券のサイトから日本株の約定履歴を収集するまでの流れについて確認します。
ざっくりこんな感じかと思います。
日本株を売買するまでの流れ
- (SeleniumでSBI証券にログイン)
- 「口座管理」から「取引履歴」ページへ遷移する
- 条件を選択する
- 「照会」ボタンをクリックする
- 結果を収集する
1についてはこちらの記事で解説している内容になるので、()書きにしました。
本記事では1はスキップして、2〜5を実装する方法を解説していきます。
PythonとSeleniumでSBI証券サイトから日本株の約定履歴収集を実装する
それでは2~5の流れを順番に解説していきます。
「口座管理」から「取引履歴」ページへ遷移する
まずは約定履歴のページに遷移します。
SBI証券にログインしてから、「口座管理」→「取引履歴」とクリックすればOKです。

Chromeの「検証」から該当要素を確認してみます。
「口座管理」についてはtitle="口座管理"となっています。
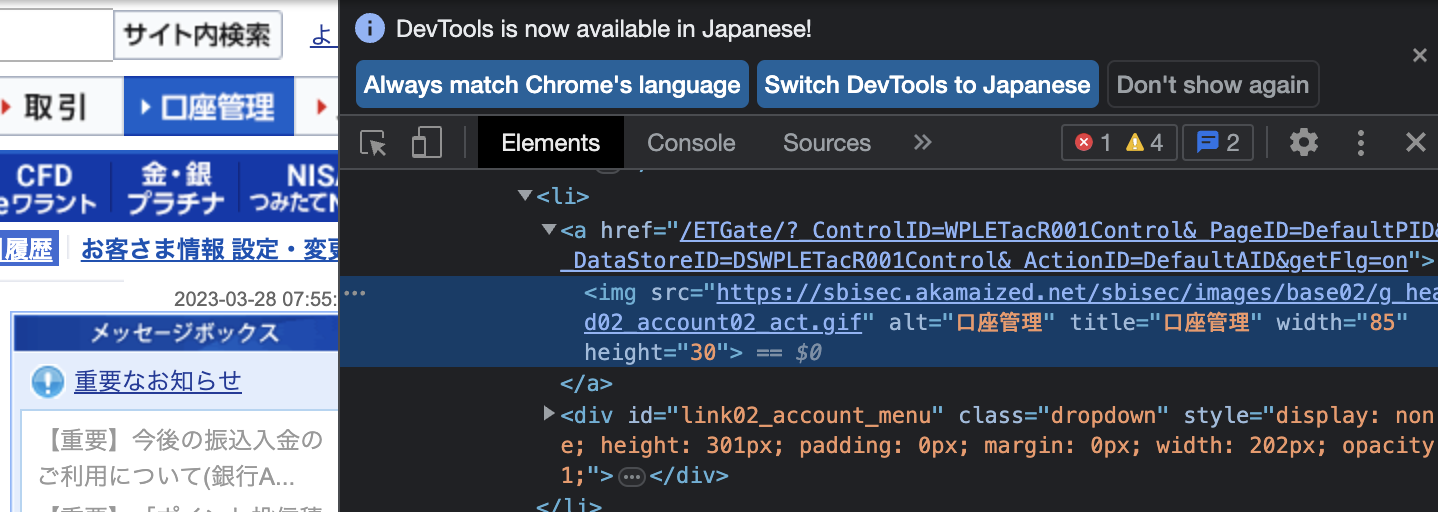
「取引履歴」については、titleやaltなどの要素はありませんが、aタグで文字列が"取引履歴"となっています。

これらを利用してSeleniumでページ遷移させてみます。
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
driver.implicitly_wait(60)
# 取引履歴ページへ遷移
driver.find_element_by_link_text("取引履歴").click()
driver.implicitly_wait(60)
データの読み込み時間を考慮して、driver.implicitly_wait(60)を加えました。
これは次の処理を行うにあたり、対象となる要素が見つかるまで待機するという命令になります。
これがないとページが読み込まれる前に値を入力しようしたり次の処理を行おうとしてエラーが発生する場合があるので、処理に時間がかかる箇所に追加しておくとプログラムの安定感が増します。
これで「約定履歴」のページへ遷移することができます。
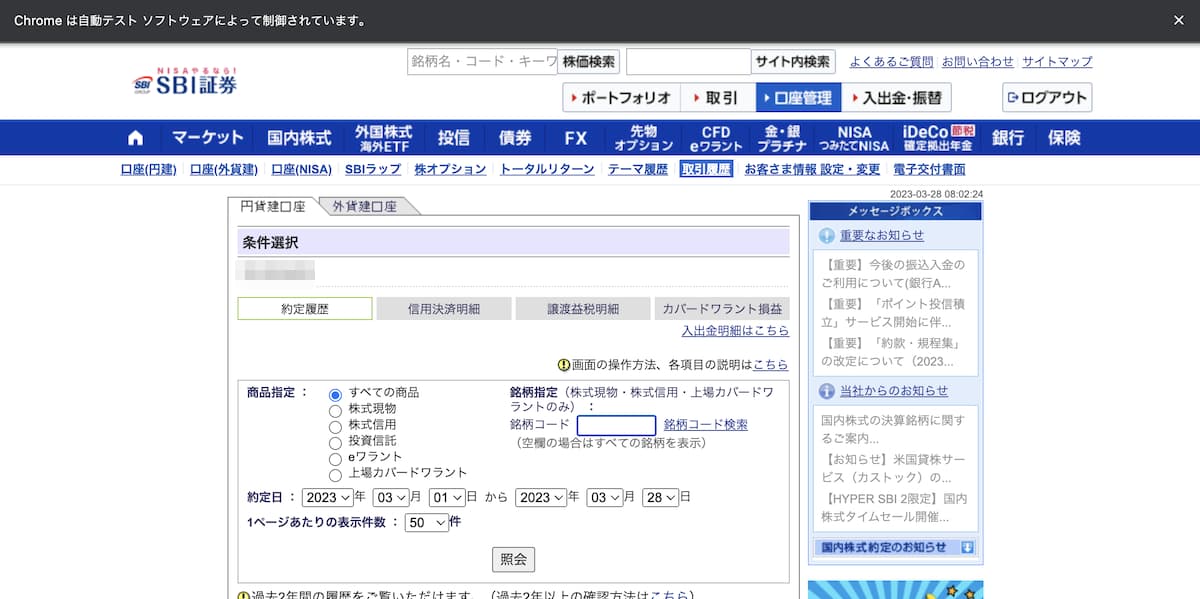
これで最初のステップはOKです。
条件を選択する
次に条件を選択します。
「約定履歴」を参照する際には、いろいろな条件を設定することができます。
設定できるのは次の4つです。
ポイント
- 商品指定
- 銘柄指定
- 約定日
- 1ページあたりの表示件数
これらをSeleniumを使って設定していきます。
商品指定
まずは商品指定です。
これはラジオボタンになっています。
ラジオボタンは要素をクリックすれば選択することができるので、各要素を判定できればOKです。
HTMLを見ると、それぞれにidが付与されていることが確認できます。
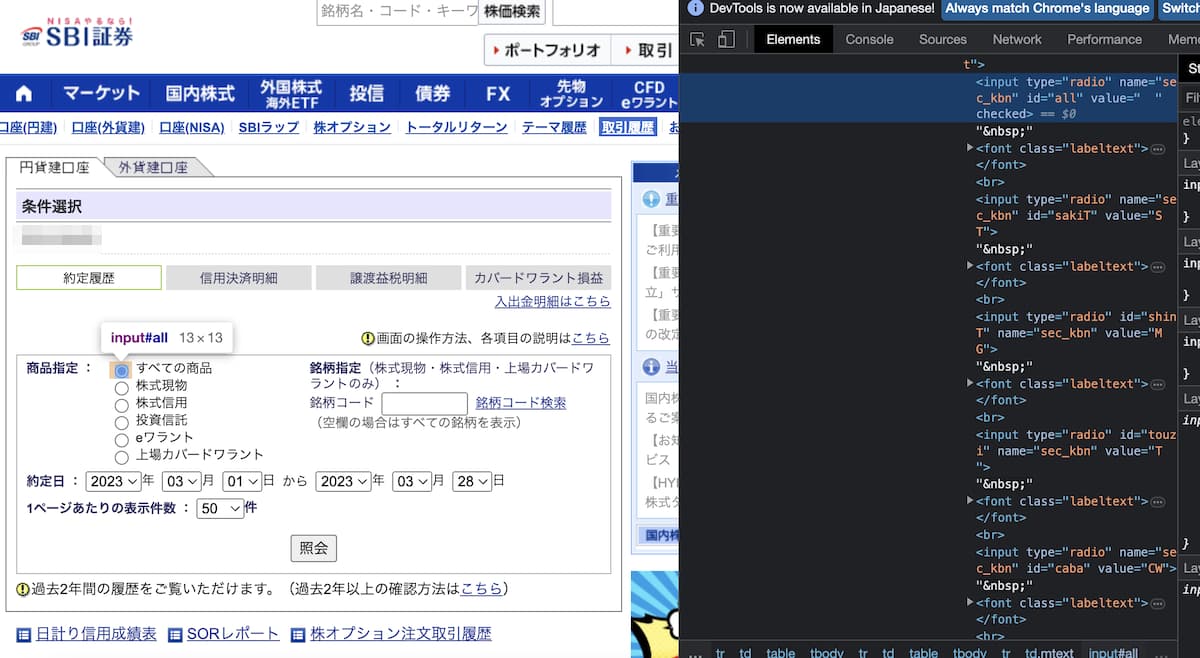
すべての商品ならid="all"、株式現物ならid="sakiT"、といったようにidが設定されているので、これを利用すれば任意の商品を設定することができます。
今回は商品とidを紐づけられる辞書を作成して対応しました。
# 商品指定
product_dict = {
"すべての商品": "all",
"株式現物": "sakiT",
"株式信用": "shinT",
"投資信託": "touzi",
"eワラント": "caba",
"上場カバードワラント": "stCW"
}
product = "すべての商品"
driver.find_element_by_id(product_dict[product]).click()
これで任意の商品を選択することができます。
銘柄指定
次に銘柄指定です。
こちらは入力タイプですね。
HTMLを見ると、name="web_sec_code"となっているのでこれを利用します。

文字列を入力するにはsend_keys()を使います。
# 銘柄指定
ticker = 7203
driver.find_element_by_name("web_sec_code").send_keys(ticker)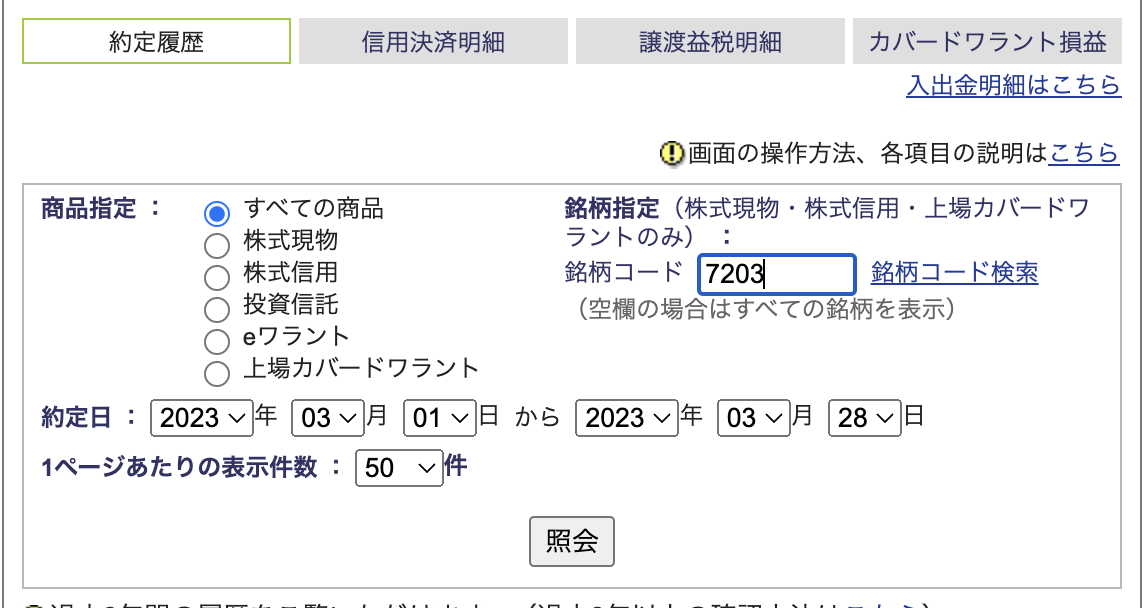
約定日
次に約定日です。
こちらはドロップダウンメニューですね。
1ページあたりの表示件数についても同じドロップダウンメニューです。
ここでは約定日だけ解説します。
それぞれの要素をチェックすると、それぞれnameが付与されていることがわかります。
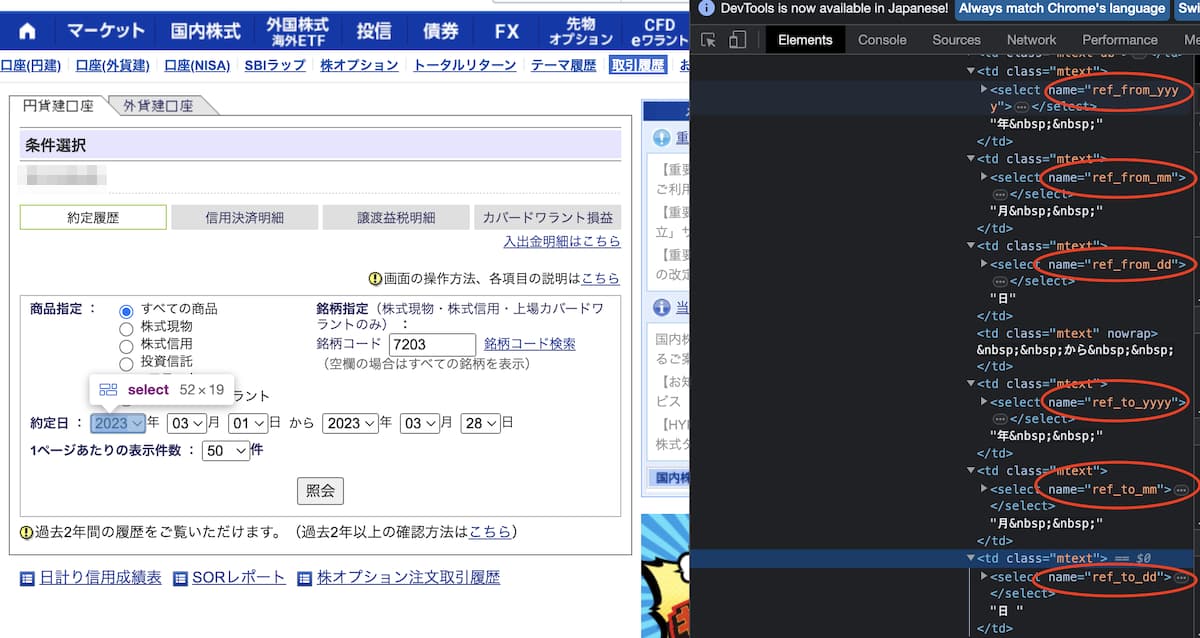
これらの要素にアクセスして値を選択すればOKです。
Seleniumでドロップダウンメニューを選択するためには、selenium.webdriver.support.select.Selectを使います。
全て同じやり方なので、ここでは約定日の開始年の設定だけ解説します。
# from 年
from_year_div = driver.find_element_by_name("ref_from_yyyy")
from_year_options = Select(from_year_div)
# 値の取得 ついでに文字列をintに変換
from_year_value_list = [int(y.get_attribute("value")) for y in from_year_options.options]
こんな感じでSelectを使います。対象の要素を取得してSelectに引き渡せばOKです。
ここから選択できる値を取得することもできます。
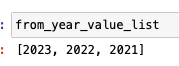
値を選択する際には、値を直接指定することもできますし、indexで指定することもできます。
値を直接指定する場合は該当する値がない場合はエラーになってしまうのでindexで選択する方が無難です。
先ほど作成したfrom_year_value_listから任意の値を検索してそのindexを利用することもできます。
この場合intで指定できるので使い勝手が良くなります。
次のコードでは全て2022年を選択しています。
# indexで指定
from_year_options.select_by_index(1)
# from_year_value_listを利用してindexを指定
from_year_options.select_by_index(from_year_value_list.index(2022))
# 値を直接指定
from_year_options.select_by_value("2022")
どれを使っても結果は変わらないのでお好きなものを選んでいただければOKです。

同じ要領で、その他のドロップダウンメニューもSeleniumで操作することができます。
全要素を網羅したコードは最後にまとめてご紹介します。
ここでは一旦次に進みます。
「照会」ボタンをクリックする
条件の設定が完了したら「照会」ボタンをクリックします。
要素を確認すると、name="ACT_search"となっているのでこれを利用します。

# 「照会」をクリック
driver.find_element_by_name("ACT_search").click()
これで約定履歴が表示されます。
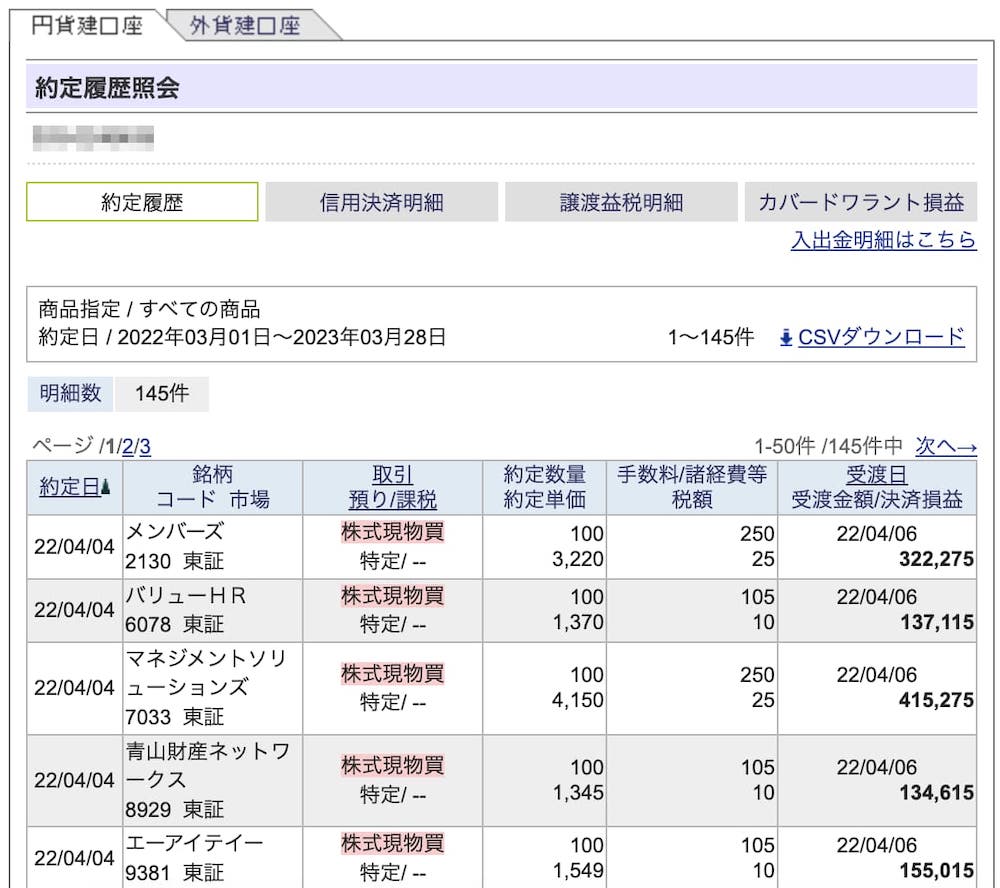
僕の取引履歴が丸見えですが、こんな感じで表示されたらOKです。
結果を収集する
最後に表示された取引履歴の結果を収集します。
データの収集
これにはBeautifulsoupを使っていきます。
テーブルの各行にアクセスして順番に収集していけばOKです。
さらにデータが多い場合はページが分割されているので、これも考慮する必要があります。
「次へ→」ボタンがある際には次のページが存在すると判断できるのでこれを利用します。
「次へ→」ボタンが存在し続ける限りはずっと次のページに遷移してデータを収集するような仕組みにします。
1つずつ解説していると長くなってしまうのでここではコードをまとめてご紹介します。
なるべる多くのコメントをつけるようにしました。
from bs4 import BeautifulSoup
import bs4
import unicodedata
import pandas as pd
import re
# 各行のデータを格納する変数を定義
data = []
# 次ページが存在するかをチェックするための変数を定義
is_next_page_available = True
# is_next_page_availableがTrueである限り処理を繰り返す
while is_next_page_available:
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# tableを取得
table = html.find("tr", {"id": "tr_a_color"}).findParent("table")
# 全てのtr要素をチェック 一行目はカラム名なのでスキップする
for tr in table.findAll("tr")[1:]:
# 行データを格納するリストを定義
row = []
# 全てのtd要素からテキストを抽出
for td in tr.findAll("td"):
# 各contentをチェック
for c in td.contents:
# 要素の種類によってテキストの抽出方法を切り替える
if isinstance(c, bs4.element.NavigableString):
text = c.strip()
elif isinstance(c, bs4.element.Tag):
text = c.getText().strip()
# 正規化
text = unicodedata.normalize("NFKC", text)
if text != "":
# 改行をチェック
for t in text.splitlines():
# スペース区切りをチェック
for t2 in t.split(" "):
if t2 != "":
# rowに追加
row.append(t2)
# dataに追加
data.append(row)
# 次ページがあるかチェック あればクリック、なければ終了
if html.find("u", text=re.compile("次へ→")):
driver.find_element_by_link_text("次へ→").click()
driver.implicitly_wait(60)
else:
is_next_page_available = False
# カラム名を定義
columns = ["約定日", "銘柄", "コード", "市場", "取引", "預り", "課税", "約定数量",
"約定単価", "手数料/諸経費等", "税額", "受渡日", "受渡金額/決済損益"]
# DataFrameに変換
df = pd.DataFrame(data, columns=columns)
これでデータがきれいに収集できます。
1つのセル内に複数の要素がごちゃ混ぜになっているので、データをきれいに収集するのは少し厄介でコードが複雑になってしまったのですがなんとかなりましたw
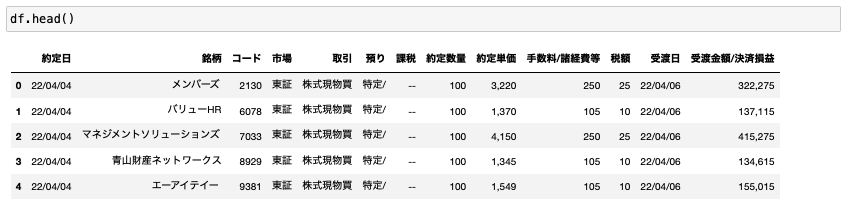
データの整形
次に修正したデータを少し整形していきます。
これは何をやるかによってどこまで綺麗に整形するべきかは変わってくると思うのですが、ここでは次のような作業をしました。
データ整形
- 「預り」から"/"を排除
- 「コード」「約定数量」をintに変換
- 「手数料/諸経費等」、「税額」、「受渡金額/決済損益」、「約定単価」をfloatに変換
- 「約定日」、「受渡日」をdatetimeに変換
これらを実装したコードがこちらです。
# 不要な文字を削除
df["預り"] = df["預り"].apply(lambda x: x.replace("/", ""))
# 不要な文字列を削除してintに変換
df["コード"] = df["コード"].astype(int)
df["約定数量"] = df["約定数量"].apply(lambda x: int(x.replace(",", "")))
# 不要な文字列を削除してfloatに変換
df["手数料/諸経費等"] = df["手数料/諸経費等"].apply(lambda x: float(x.replace(",", "")))
df["税額"] = df["税額"].apply(lambda x: float(x.replace(",", "")))
df["受渡金額/決済損益"] = df["受渡金額/決済損益"].apply(lambda x: float(x.replace(",", "")))
df["約定単価"] = df["約定単価"].apply(lambda x: float(x.replace(",", "")))
# 日付の型変換
df["約定日"] = df["約定日"].apply(lambda x: datetime.datetime.strptime(x, "%y/%m/%d"))
df["受渡日"] = df["受渡日"].apply(lambda x: datetime.datetime.strptime(x, "%y/%m/%d"))
これでデータが結構きれいになります。
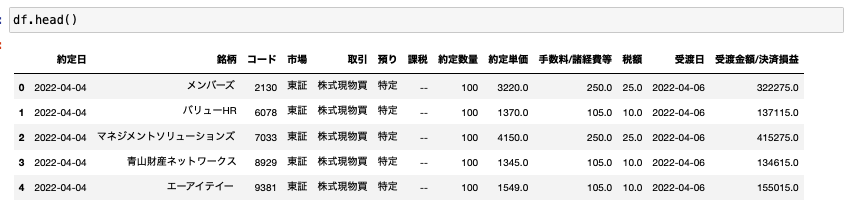
これで全てのプロセスが完了です。
あとは必要に応じてカラムを追加したり集計したりすればいろいろな分析や用途に活用できるかと思います。
最後にコードをまとめてどうぞ!
最後に、これまでのコードをまとめたものを共有します。
解説で割愛した部分も全て網羅しています。
なるべくコメントも多くつけたつもりです。
ちょっと長いですが、コピペ用にどうぞ。
from selenium import webdriver
from selenium.webdriver.support.select import Select
from bs4 import BeautifulSoup
import bs4
import unicodedata
import re
import pandas as pd
import datetime
"""
ページ遷移
"""
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
driver.implicitly_wait(60)
# 取引履歴ページへ遷移
driver.find_element_by_link_text("取引履歴").click()
driver.implicitly_wait(60)
"""
条件選択
"""
# 商品指定
product_dict = {
"すべての商品": "all",
"株式現物": "sakiT",
"株式信用": "shinT",
"投資信託": "touzi",
"eワラント": "caba",
"上場カバードワラント": "stCW"
}
product = "すべての商品"
driver.find_element_by_id(product_dict[product]).click()
# 銘柄指定
ticker = 7203
driver.find_element_by_name("web_sec_code").send_keys(ticker)
# 約定日
# from 年
from_year_div = driver.find_element_by_name("ref_from_yyyy")
from_year_options = Select(from_year_div)
from_year_value_list = [int(y.get_attribute("value")) for y in from_year_options.options]
# from 月
from_month_div = driver.find_element_by_name("ref_from_mm")
from_month_options = Select(from_month_div)
from_month_value_list = [int(m.get_attribute("value")) for m in from_month_options.options]
# from 日
from_day_div = driver.find_element_by_name("ref_from_dd")
from_day_options = Select(from_day_div)
from_day_value_list = [int(d.get_attribute("value")) for d in from_day_options.options]
# to 年
to_year_div = driver.find_element_by_name("ref_to_yyyy")
to_year_options = Select(to_year_div)
to_year_value_list = [int(y.get_attribute("value")) for y in to_year_options.options]
# to 月
to_month_div = driver.find_element_by_name("ref_to_mm")
to_month_options = Select(to_month_div)
to_month_value_list = [int(m.get_attribute("value")) for m in to_month_options.options]
# to 日
to_day_div = driver.find_element_by_name("ref_to_dd")
to_day_options = Select(to_day_div)
to_day_value_list = [int(d.get_attribute("value")) for d in to_day_options.options]
# 表示件数
max_count_div = driver.find_element_by_name("max_cnt")
max_count_options = Select(max_count_div)
max_count_value_list = [int(c.get_attribute("value")) for c in max_count_options.options]
# 約定日を設定
from_year_options.select_by_index(from_year_value_list.index(2022))
from_month_options.select_by_index(from_month_value_list.index(1))
from_day_options.select_by_index(from_day_value_list.index(1))
to_year_options.select_by_index(to_year_value_list.index(2023))
to_month_options.select_by_index(to_month_value_list.index(3))
to_day_options.select_by_index(to_day_value_list.index(31))
# 表示件数を設定
max_count_options.select_by_index(max_count_value_list.index(100))
# 「照会」をクリック
driver.find_element_by_name("ACT_search").click()
driver.implicitly_wait(60)
"""
データの収集
"""
# 各行のデータを格納する変数を定義
data = []
# 次ページが存在するかをチェックするための変数を定義
is_next_page_available = True
# is_next_page_availableがTrueである限り処理を繰り返す
while is_next_page_available:
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# tableを取得
table = html.find("tr", {"id": "tr_a_color"}).findParent("table")
# 全てのtr要素をチェック 一行目はカラム名なのでスキップする
for tr in table.findAll("tr")[1:]:
# 行データを格納するリストを定義
row = []
# 全てのtd要素からテキストを抽出
for td in tr.findAll("td"):
for c in td.contents:
# 要素の種類によってテキストの抽出方法を切り替える
if isinstance(c, bs4.element.NavigableString):
text = c.strip()
elif isinstance(c, bs4.element.Tag):
text = c.getText().strip()
# 正規化
text = unicodedata.normalize("NFKC", text)
if text != "":
# 改行をチェック
for t in text.splitlines():
# スペース区切りをチェック
for t2 in t.split(" "):
if t2 != "":
# rowに追加
row.append(t2)
# dataに追加
data.append(row)
# 次ページがあるかチェック あればクリック、なければ終了
if html.find("u", text=re.compile("次へ→")):
driver.find_element_by_link_text("次へ→").click()
driver.implicitly_wait(60)
else:
is_next_page_available = False
# カラム名を定義
columns = ["約定日", "銘柄", "コード", "市場", "取引", "預り", "課税", "約定数量",
"約定単価", "手数料/諸経費等", "税額", "受渡日", "受渡金額/決済損益"]
# DataFrameに変換
df = pd.DataFrame(data, columns=columns)
"""
データの整形
"""
# 不要な文字を削除
df["預り"] = df["預り"].apply(lambda x: x.replace("/", ""))
# 不要な文字列を削除してintに変換
df["コード"] = df["コード"].astype(int)
df["約定数量"] = df["約定数量"].apply(lambda x: int(x.replace(",", "")))
# 不要な文字列を削除してfloatに変換
df["手数料/諸経費等"] = df["手数料/諸経費等"].apply(lambda x: float(x.replace(",", "")))
df["税額"] = df["税額"].apply(lambda x: float(x.replace(",", "")))
df["受渡金額/決済損益"] = df["受渡金額/決済損益"].apply(lambda x: float(x.replace(",", "")))
df["約定単価"] = df["約定単価"].apply(lambda x: float(x.replace(",", "")))
# 日付の型変換
df["約定日"] = df["約定日"].apply(lambda x: datetime.datetime.strptime(x, "%y/%m/%d"))
df["受渡日"] = df["受渡日"].apply(lambda x: datetime.datetime.strptime(x, "%y/%m/%d"))
これで、PythonとSeleniumを使って、SBI証券のサイトから日本株の約定履歴を収集することができるようになりました。
まとめ
本記事では「【Python】SeleniumでSBI証券から日本株の約定履歴を収集する方法」について解説しました。
PythonとSeleniumを使えば、約定履歴の収集を自動化することができました。
参照時の条件選択も全てSeleniumを通じて操作することができます。
これを利用すれば、日次、週次、月次の売買金額を集計したり、株価チャートに売買履歴を表示して分析したり、いろいろな用途に活用できるかと思います。
最後まで読んでくださり、ありがとうございました。









{kind=link}