

こんにちは。TATです。
今日のテーマは「【Python】SeleniumでSBI証券から日本株のポートフォリオを取得する方法」です。
PythonとSeleniumを使って、SBI証券から日本株のポートフォリオを取得する方法について解説していきます。
これで、保有株の状況(損益や評価額など)を確認することができるようになります。
定期的に取得すれば、資産推移をチャートにまとめたり、日々の変動率を自動モニタリングするなどといった使い方も可能です。
目次
SBI証券へのログイン
事前準備として、PythonとSeleniumでSBI証券にログインしておく必要があります。
Seleniumの準備やSBI証券へログインする方法についてはこちらの記事で解説しています。
ログインが完了したら、本記事で紹介するコードを実行することができます。
-

【Python】SeleniumでSBI証券に自動ログインする方法【自動売買への道】
続きを見る
日本株のポートフォリオを取得するまでの流れ
次にPythonとSeleniumでSBI証券のサイトから日本株をポートフォリオを取得するまでの流れについて確認しておきます。
ざっくりとこんな感じです。
今回は最終的にポートフォリオを円グラフで可視化したいと思います。
日本株を売買するまでの流れ
- (SeleniumでSBI証券にログイン)
- 口座管理ページに遷移する
- ポートフォリオ情報を取得する
- データ整形を行う
- 円グラフで可視化する
1についてはこちらの記事で解説している内容になるので、()書きにしました。
本記事では1はスキップして、2〜5を実装する方法を解説していきます。
具体的にはこちらの赤枠の部分のデータを収集します。
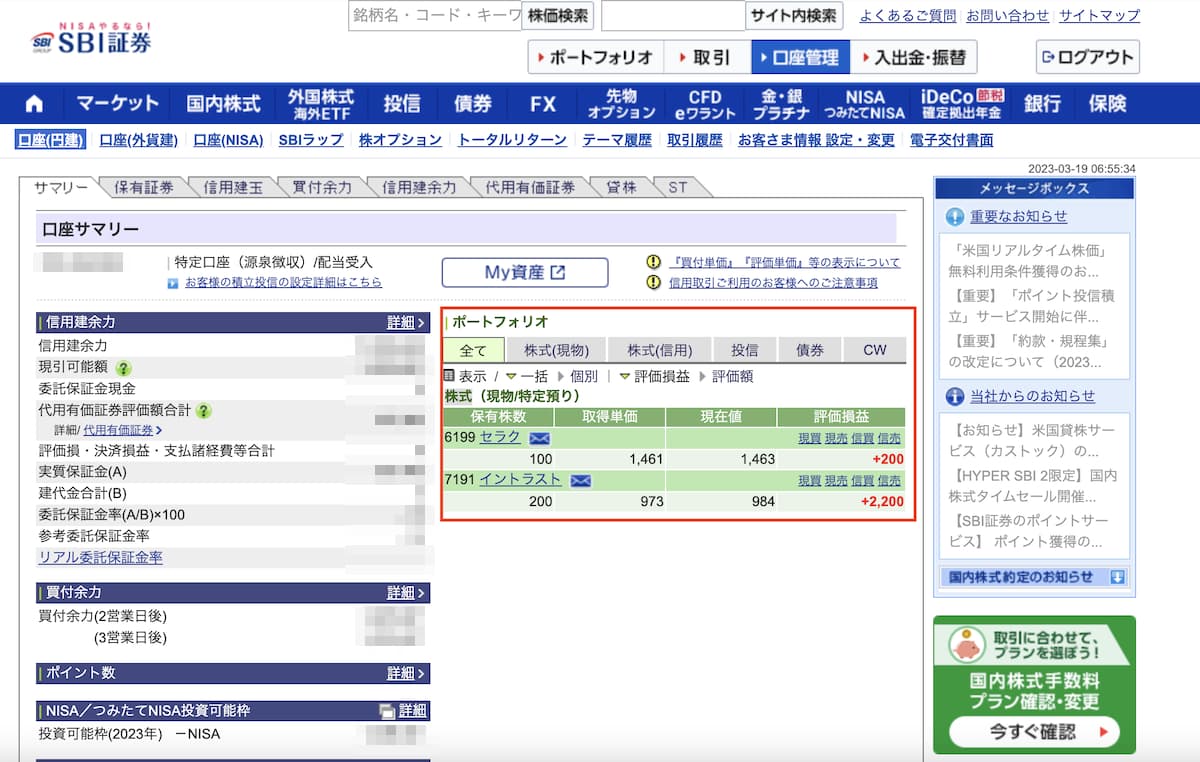
PythonとSeleniumでSBI証券から日本株のポートフォリオ取得を実装する
それでは2~5の流れを順番に解説していきます。
口座管理ページに遷移する
まずは口座管理ページへ遷移します。

Chromeの検証からHTMLソースを確認すると、title="口座管理"となっていることが確認できます。
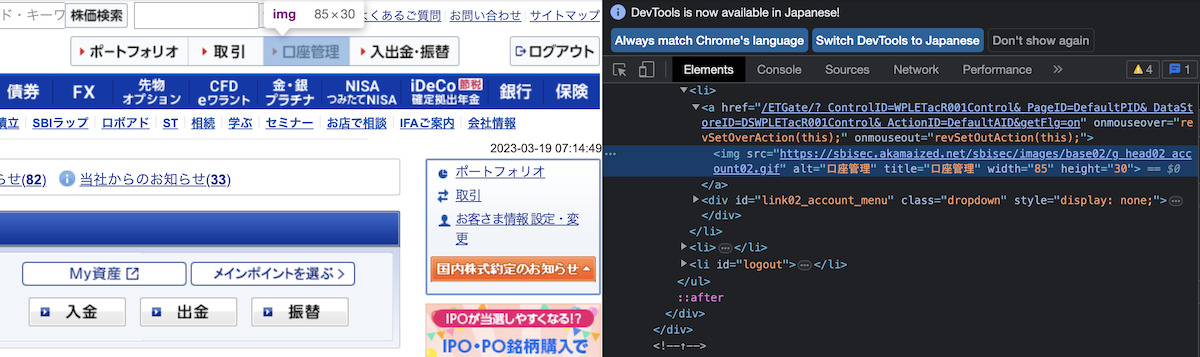
この情報を利用して、Seleniumで「口座管理」をクリックします。
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
これで口座管理ページへ遷移することができます。
ポートフォリオ情報を取得する
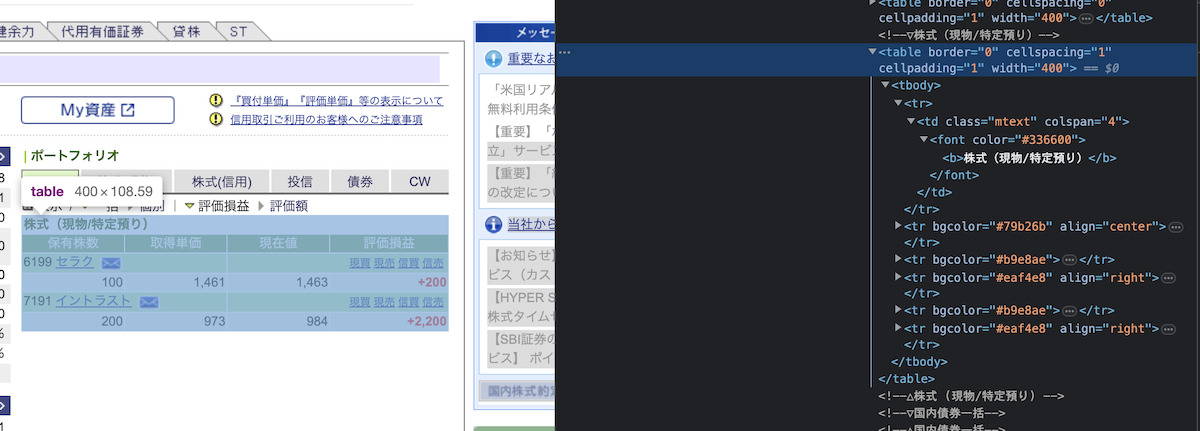
次にポートフォリオ情報を取得します。
こちらの赤枠の部分です。今回で一番厄介な部分になります。
HTMLを見ると、特に特定できる要素がないことがわかります。
tableを特定するnameやidなどの情報が存在していません。
データ取得の流れ
この場合、少し工夫が必要になります。
今回は次のような流れでデータを収集しました。他にもいろいろなやり方があると思います。
できる限り具体的に書きました。
ポートフォリオ取得の流れ
- Beautifulsoupで口座管理ページのHTMLを取得
- 全てのtable要素を取得
- table内に別のtableが存在しない、かつ「保有株数」という文字のfontタグが存在していれば対象tableとして判断
- 区分情報(特定預りなど)を取得
- tableの各行を取得する
- bgcolor="#b9e8ae"の場合、銘柄情報が含まれる行と判断して証券コードと銘柄名を取得
- 次の行から保有株数、取得単価、現在値、評価損益を取得
コード紹介
上記の方法をPythonで実装したコードがこちらです。
なるべくコメントを多くつけるようにしました。
from bs4 import BeautifulSoup
import re
import unicodedata
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# 全てのtableを抽出
tables = html.findAll("table")
# データを格納する変数を定義
data = []
# 各tableをチェック
for i, table in enumerate(tables):
# 対象tableに該当するかチェック
if table.find("font", text=re.compile("保有株数")) and not table.find("table"):
# 区分取得
category = table.find("b").getText().strip()
# 各行のデータを取得
for tr in table.findAll("tr"):
# bgcolorで判断
if tr.get("bgcolor") == "#b9e8ae":
row = []
# 証券コードと銘柄名を取得
text = unicodedata.normalize("NFKC", tr.find("td").getText()).strip()
row.extend(text.split(" "))
# 保有株数, 取得単価, 現在値, 評価損益を取得
for t in tr.findNext("tr").findAll("td"): #findNext('tr')で次の行を取得
row.append(t.getText().replace(",", "").replace("+", "")) # 不要な文字を排除
# 区分を追加
row.append(category)
# dataに追加
data.append(row)
これできちんとデータが取得できていることが確認できます。

unicodedataで文字列を統一
基本的にはコメントに書いてある通りの内容になっています。
ここでは突然登場しているunicodedataについてだけ簡単に解説しておきます。
unicodedataを使うと、文字列を統一することができます。
今回の使用例だとこんな感じになります。

unicodedataを使用しないと、文字列のスペースが\xa0となっています。
unicodedataを使うことできちんとスペースとして表示されるようになりました。
このように文字コードによって値が変になっている場合はunicodedataを使ってきれいにすることができます。
全角数字とかもunicodedataを使えば半角に変換できます。
データ整形を行う
次にデータ整形を行います。
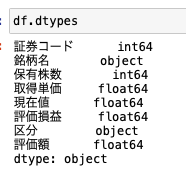
収集したデータをDataFrameに変換して、さらに型変換はカラムの追加などといった作業を行います。
基本的に、スクレイピングで収集したデータは全て文字列になっているので、適切に数値に変換する作業が必要になります。
今回行った作業は次の通りです。
データ整形
- dataをDataFrameに変換
- 証券コード、保有株数をintに型変換、取得単価、現在値、評価損益をfloatに型変換
- 保有株数と現在地から評価額を計算
とてもシンプルです。
Pythonで実装すると次のようになります。
import pandas as pd
# DataFrameに変換
df = pd.DataFrame(data, columns=["証券コード", "銘柄名", "保有株数", "取得単価", "現在値", "評価損益", "区分"])
# 型変換
for col in ["証券コード", "保有株数"]:
df[col] = df[col].astype(int)
for col in ["取得単価", "現在値", "評価損益"]:
df[col] = df[col].astype(float)
# 評価額
df["評価額"] = df["保有株数"] * df["現在値"]
dfを確認するときちんとデータが整形されていることが確認できます。
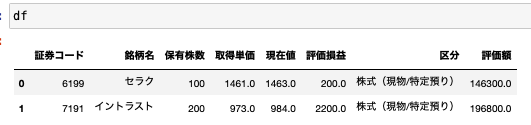
型変換もバッチリです。
これでデータの準備は完了です。
円グラフで可視化する
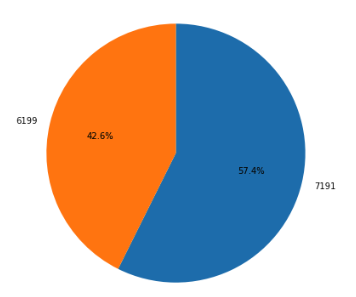
最後に取得したポートフォリオを円グラフで可視化してみます。
今回はmatplotlibとplotlyを使った例をご紹介します。
matplotlib
まずはmatplotlibです。
%表示にすると見やすくなります。
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(7,7))
plt.pie(
x=df["評価額"],
labels=df["証券コード"],
counterclock=False,
startangle=90,
autopct='%1.1f%%' #%表示に変更
)
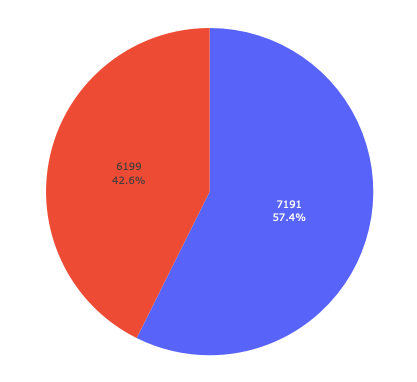
plotly
次にPlotlyです。
import plotly.express as px fig = px.pie(data_frame=df, names="証券コード", values="評価額") fig.update_traces(textinfo="percent+label") #ラベルと%表示 fig.update_layout(showlegend=False) #凡例を非表示 fig.show()
最後にコードをまとめてどうぞ!
最後にここまでご紹介したコードをまとめます。
コピペ用にどうぞ。
円グラフの部分は割愛します。
from bs4 import BeautifulSoup
import re
import unicodedata
import pandas as pd
# 口座管理ページへ遷移
driver.find_element_by_css_selector("img[title=口座管理]").click()
driver.implicitly_wait(60)
# htmlを取得
html = BeautifulSoup(driver.page_source, "html.parser")
# 全てのtableを抽出
tables = html.findAll("table")
# データを格納する変数を定義
data = []
# 各tableをチェック
for i, table in enumerate(tables):
# 対象tableに該当するかチェック
if table.find("font", text=re.compile("保有株数")) and not table.find("table"):
sample = table
# 区分取得
category = table.find("b").getText().strip()
# 各行のデータを取得
for tr in table.findAll("tr"):
# bgcolorで判断
if tr.get("bgcolor") == "#b9e8ae":
sample = tr
row = []
# 証券コードと銘柄名を取得
text = unicodedata.normalize("NFKC", tr.find("td").getText()).strip()
row.extend(text.split(" "))
# 保有株数, 取得単価, 現在値, 評価損益を取得
for t in tr.findNext("tr").findAll("td"): #findNext('tr')で次の行を取得
row.append(t.getText().replace(",", "").replace("+", "")) # 不要な文字を排除
# 区分を追加
row.append(category)
# dataに追加
data.append(row)
# DataFrameに変換
df = pd.DataFrame(data, columns=["証券コード", "銘柄名", "保有株数", "取得単価", "現在値", "評価損益", "区分"])
# 型変換
for col in ["証券コード", "保有株数"]:
df[col] = df[col].astype(int)
for col in ["取得単価", "現在値", "評価損益"]:
df[col] = df[col].astype(float)
# 評価額
df["評価額"] = df["保有株数"] * df["現在値"]
これで、SBI証券から日本株のポートフォリオを自動取得することができます。
まとめ
こんにちは。TATです。
今日のテーマは「【Python】SeleniumでSBI証券から日本株のポートフォリオを取得する方法」です。
PythonとSeleniumを利用すれば、SBI証券に自動ログイン(参考記事)して、そこから日本株をポートフォリオを取得することができます。
定期的に取得すれば、資産推移をチャートにまとめたり、日々の変動率を自動でモニタリングして通知を送るみたいな使い方も可能です。
アイデア次第ではもっといろいろな活用ができそうです。
最後まで読んでくださり、ありがとうございました。









{kind=link}