
【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた! では、機械学習モデルを使ったデータ分析に一例をご紹介します。
機械学習手法の1つであるランダムフォレストを利用して、SUUMOからお得物件(およびぼったくり物件)を探してみました。
過去の記事で、「SUUMOからスクレイピングで収集したデータをもとに理想の賃貸物件を探す」というふざけた企画をしました。
-

【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
今回は、このおふざけがさらにレベルアップしまして、機械学習モデルをぶっ込んで家賃予測をしてみました。
予測値と実際のデータを比較して、お得物件(予測値よりも安い物件)(およびぼったくり物件(予測値よりも高い物件))を探しました。
かなりふざけた企画ですが、それなりにいい感じの物件が見つかりましたw
ついでにSUUMOのエラーデータも見つかりましたw
目次
【Pythonで不動産データ分析!】機械学習(ランダムフォレスト)を用いてSUUMOからお得物件を探してみた!

1. Pythonのスクレイピング技術でSUUMOからデータ収集
まずは機械学習モデルを作成するために必要な情報を集めます。
これにはスクレイピングという技術を使います。
これは前回の記事でもご紹介しているので詳細については、こちらの記事をご参照ください。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
ここでは東京23区内にある物件全てのスクレイピングで収集しました。
データは2020年6月14日の朝に取得しまして、データ数は全527,492個でした。
なかなかすごい量です。
-

【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
2. 機械学習モデル作成のためのデータ整形〜重複データ多すぎたw〜
データの加工
次に集めたデータをきれいに整形していきます。
ここが一番重要な作業になります。
データがきちんとしていないとモデルの精度が落ちてしまうので、ここはしっかりとやっていきます。
やったこととしては、基本的には前回と同じですが、少し追加しました。
前回のデータ加工と同様に行なった作業はこちらの通りです。
- 「家賃」「管理費」「敷金」「礼金」「面積」「築年数」を数値データへ変換(さらに「管理費」は単位を万円へ変換)
- 「アドレス」から「区」を抽出
- 「アクセス」から「沿線」「駅」「徒歩」を抽出(さらに「徒歩」は数値データに変換)
- 「アクセス」が駅でないデータ(バスとか)は除外
- 徒歩圏内でないでデータ(車で3分とか)は除外
- "URL", "アクセス"をキーにして重複データを除外
数値データの型変換や必要情報の抽出、不要な情報は削除するようなイメージです。
ここまでの作業を終えた段階で、有効データ数は176,946個でした。
ざっくり3分の1まで減ってしまいましたw
ほぼURLの重複データ削除の作業で消えています。
さらに重複データの除去
ここではURLをキーにして重複データを削除しましたが、前回の記事ではそれでも重複データが発見されました。
同じ物件でも別URLで別物件として登録されてしまっているケースが結構あるんですね。
SUUMOさんはこの辺り含めてもっときちんとデータ管理するべきです(笑)
そこで今回は、URL以外のカラムでも全て一致しているものは重複データとして除外しました。
キーとしたのはこれらです。
["アドレス", "カテゴリー", "名称", "家賃", "敷金", "構造", "礼金", "管理費", "築年数", "間取り", "階数", "面積", "沿線", "駅", "徒歩"]
これらのデータが全て一致した場合には重複データと判断して削除します。
すると有効データは166,335個になりました。
1万個ほど減りましたね。まじで重複データ多すぎですw
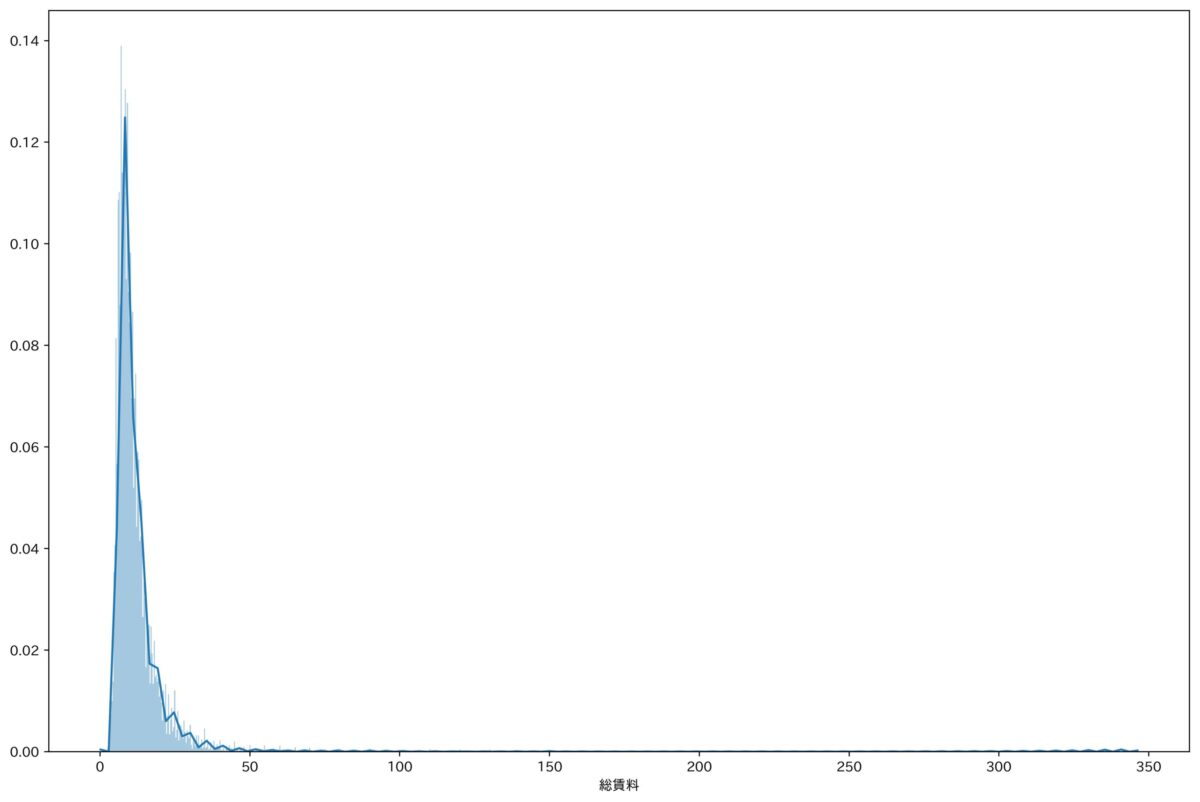
ここまでくるとデータとしてはかなりきれいになって、家賃の分布を見たらこんな感じできれいな正規分布になっていました。
ここでは管理費も含めた総賃料で見ています。
外れ値の除去
ただこちらのチャートを見ると、頭おかしいくらい家賃の高い物件もちらほら存在していることがわかります。
もっとも高い家賃は345万円でしたw
これです。
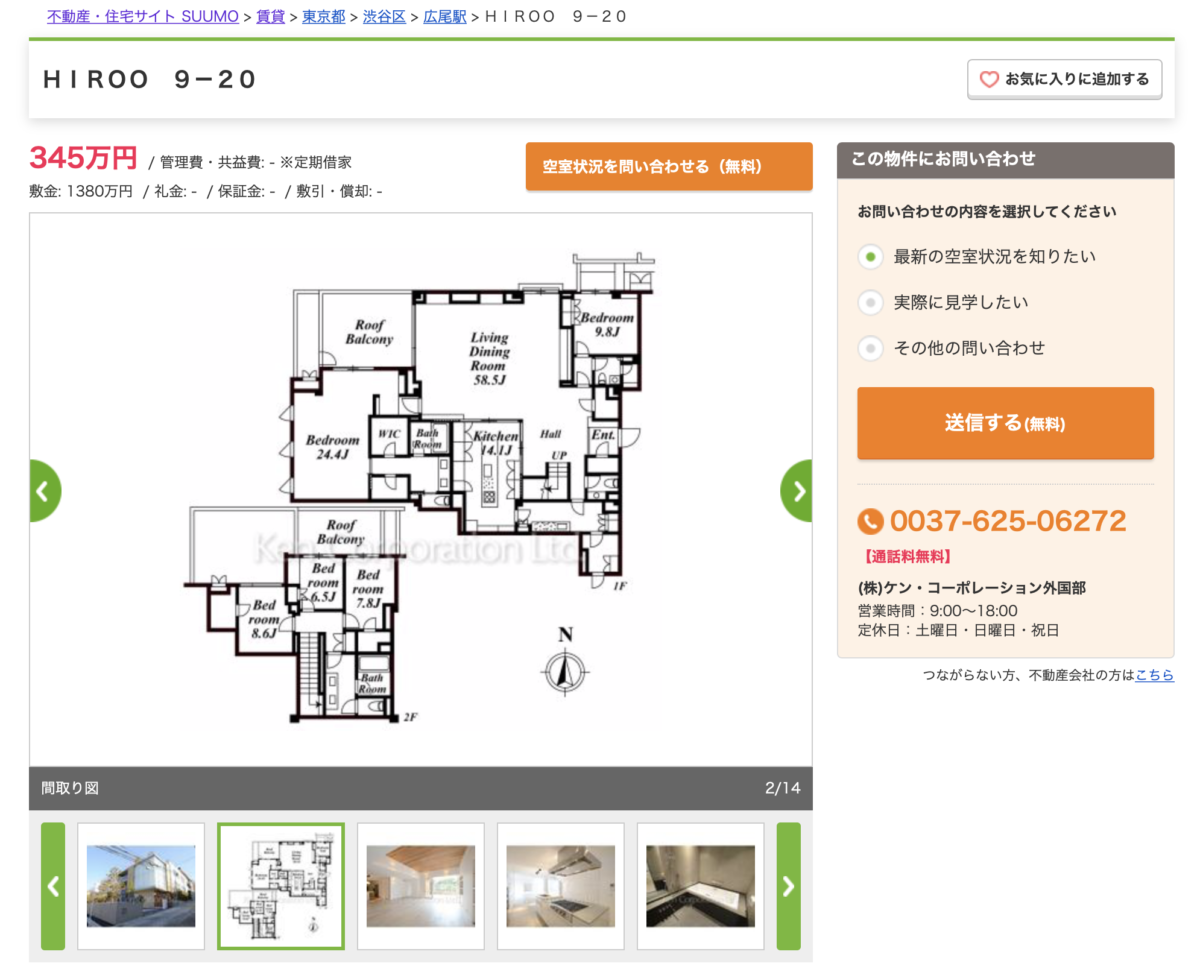
5LDKで広さは327.94平方メートルです。
敷金1380万円とか頭おかしすぎますw
こういったぶっ飛んだ値は外れ値と呼ばれ、これらを含めたままモデルを作ると精度が落ちてしまいます。
ゆえにこういったぶっ飛んだ値を削除する作業を行います。
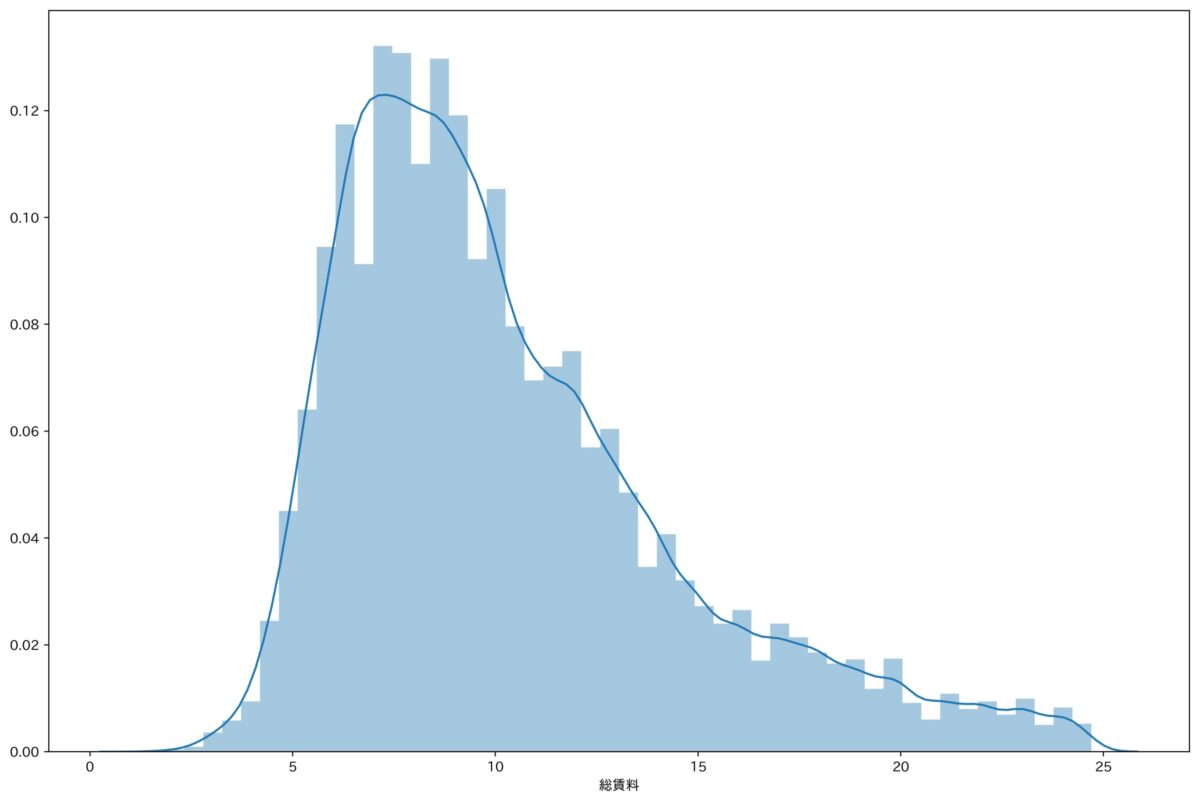
ここでは総賃料の標準偏差σを求めて、-3σ〜3σに収まるデータのみを採用します。
この考え方は正規分布の確率密度関数に基づいています(詳しくはWikipediaをどうぞ)
これで外れ値を外すといい感じの正規分布になりました。
外れ値の除外方法には他にも色々とありますが、ここではめんどかったのでシンプルにこれでいきますw
ということで、今回はこのデータを使って機械学習モデルを作ります。
最終的な有効データは164,230個となりました。
2000個ほどが外れ値として除外されました。
最終的なデータはこんな感じです。
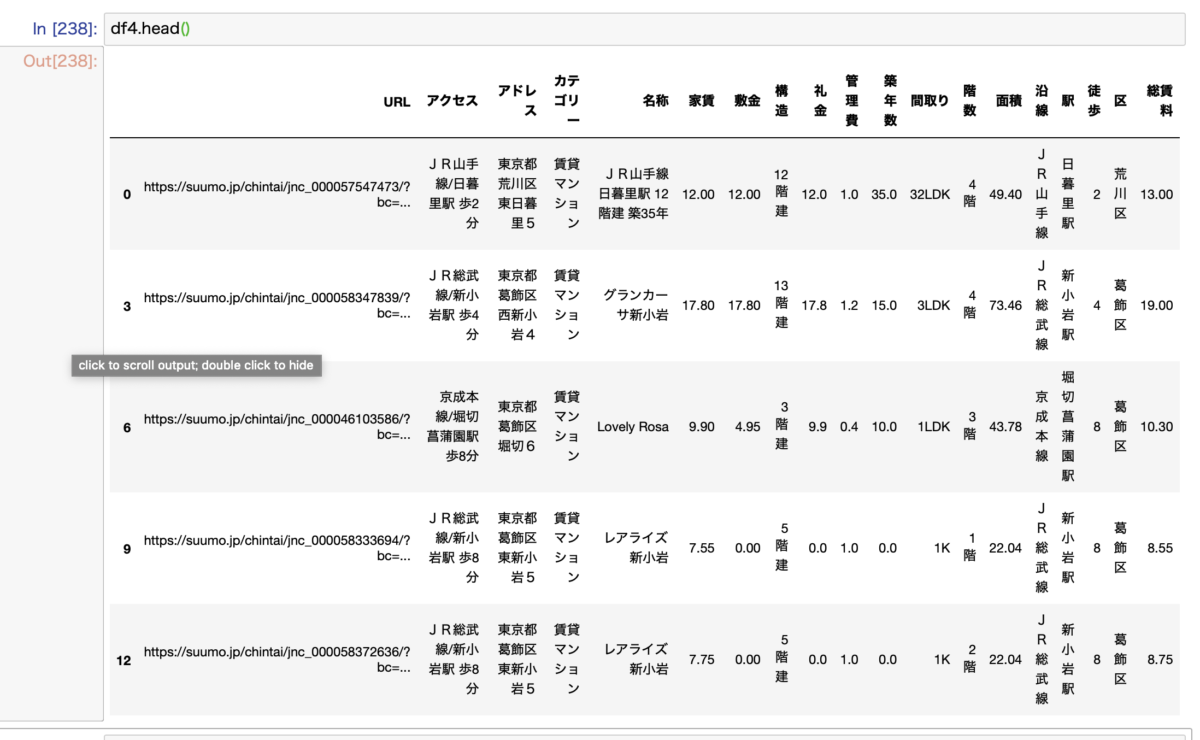
最初の527,492個からかなり減りましたねw
-

【コード解説】データ分析のためにSUUMOの賃貸物件情報を整形する!【re, pandas, apply, lambda等】
3. 機械学習手法の1つであるランダムフォレストを使って家賃を予測
機械学習モデルを作るにあたって、一番大変なのはデータの用意で、特にデータの整形作業が一番めんどくさいです。
これさえ終わってしまえば、機械学習モデルを作るのは非常に簡単です。
ランダムフォレスト
今回は、機械学習手法の1つであるランダムフォレストを利用します。
ランダムフォレストについて知らない方も多いと思うので簡単に解説します。
Wikipedia先生の文章を抜粋します。
ランダムフォレストは、2001年に Leo Breiman によって提案された機械学習のアルゴリズムであり、分類、回帰、クラスタリングに用いられる。決定木を弱学習器とするアンサンブル学習アルゴリズムであり、この名称は、ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用することによる。(Wikipediaより)
なんのこっちゃかわからないですよねw
すこぶる簡略して説明しますと、過去の記事で線形回帰について解説しました
-

【数式なしで徹底解説!】機械学習の基本!回帰分析(単回帰分析・重回帰分析)について解説します!
ランダムフォレストはこれに条件分岐をつけたようなイメージです。
線形回帰だと、全てのデータを一様に扱いますが、ランダムフォレストの場合は決定木を利用した条件分岐が設けられています。
「中央区の物件の場合」、「山手線沿線の物件の場合」などといったように条件分岐を設けたうえで回帰分析をすることができます。
これによって普通の回帰分析よりも精度は良くなる傾向にあります。
モデルの作成
そして機械学習モデルを作るためには、説明変数と目的変数が必要です。
先ほどの記事でも解説していますが、説明変数はいわゆる入力情報で、目的変数は出力情報です。
ここでは、目的変数に["築年数", "面積", "徒歩", "区", "沿線", "駅"]を用いて、目的変数を総賃料としました。
目的変数の値を入れると総賃料の予測値が出てきます。
モデルの作成はPythonのscikit-learnというライブラリーを使うと簡単にできます。
一部だけですが、こんな感じです。

Xに説明変数、Yに目的変数が入っており、トレーニング用とテスト用にデータを分けて検証します。
スコアは0.98となりました。
これは1に近いほど良くて、重回帰分析でやると0.84ほどでした。
これでモデルの完成です。
実際にはランダムフォレストに用いる様々なパラーメータをチューニングすればさらに精度を上げることができます。
ただ、ここではデフォルトでいい感じだったのでこれ以上追求するのはやめましたw
4. 予測家賃と実際の家賃を比較して、お得物件を物色してみた!
作成したモデルで家賃を予測
モデルが完成したら、早速家賃を予測していきます。
元々のデータ全てに対して予測家賃を算出して、実際の家賃を比較していきます。
こんな感じになりました。
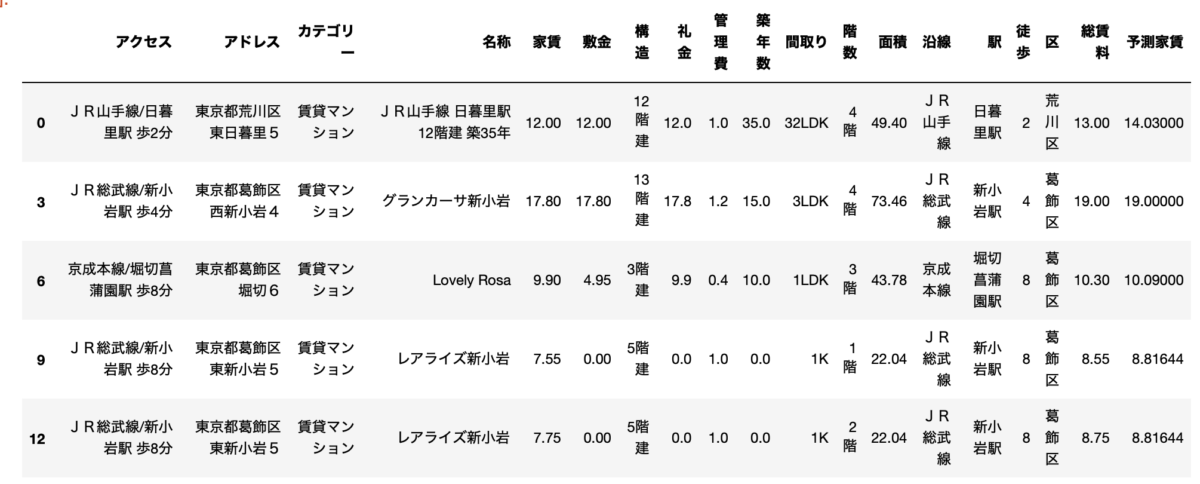
右にある総賃料が家賃+管理費の実際の値で、予測家賃がモデルが算出した家賃です。
結構いい感じですよね。
予測値と実際の値を比較してお得物件を探す
これらのデータを比較して、お得物件を探していきます。
ついでにお遊びがてらぼったくり物件も探しますw
まずはお得物件です。
これは実際の総賃料が予測値よりも安いものを意味します。
わかりやすく見えるように総賃料と予測賃料の比を計算して並び替えます。
まずはお得物件トップ10を見てみます。
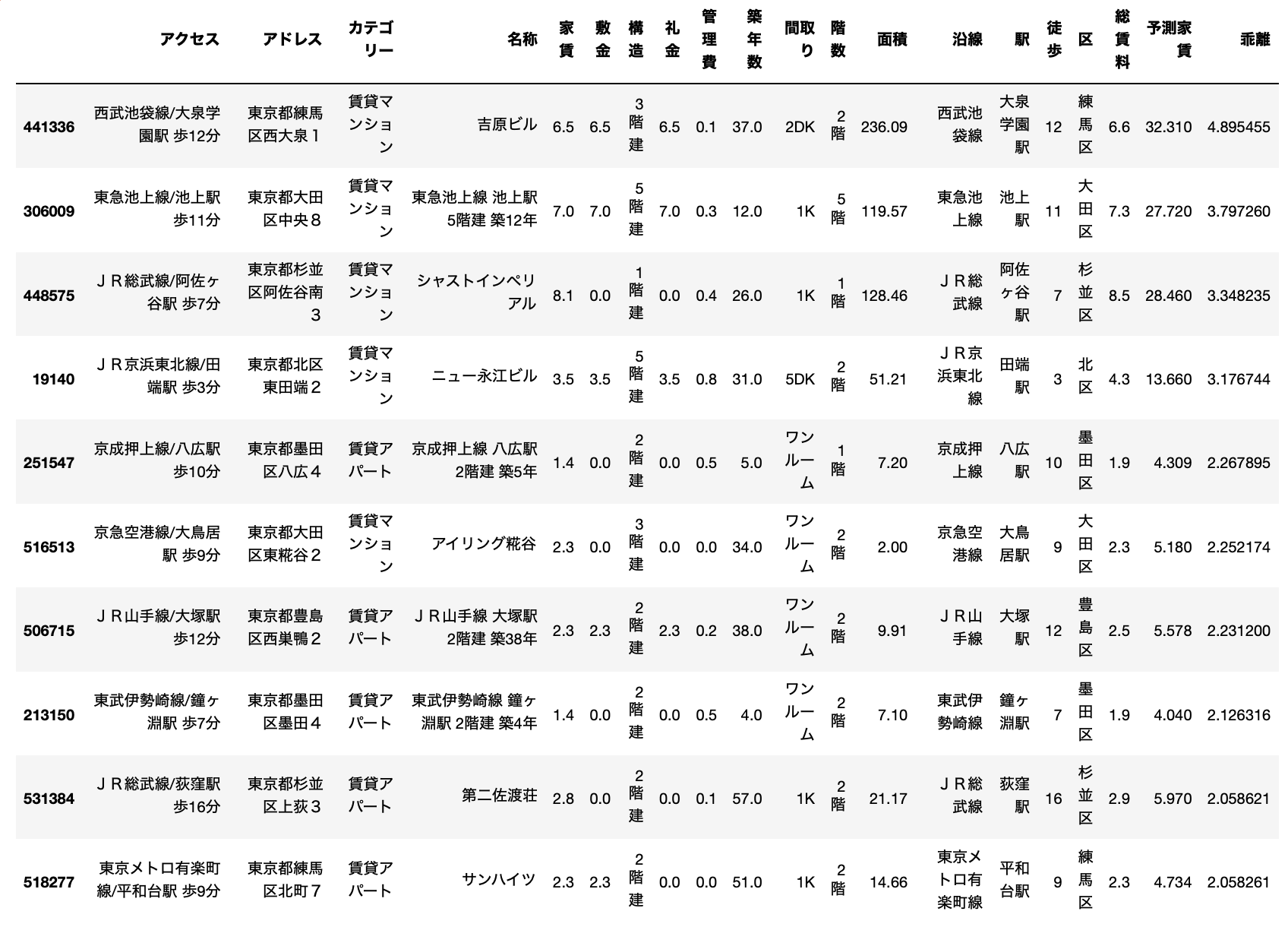
みなさんこちらのデータを見て、何か気がつくでしょうか?
はい、実際の賃料と予測値の乖離が明らかに大きすぎますねw
実際にSUUMOのページを見てみます。
例えば1位の物件がこちら。
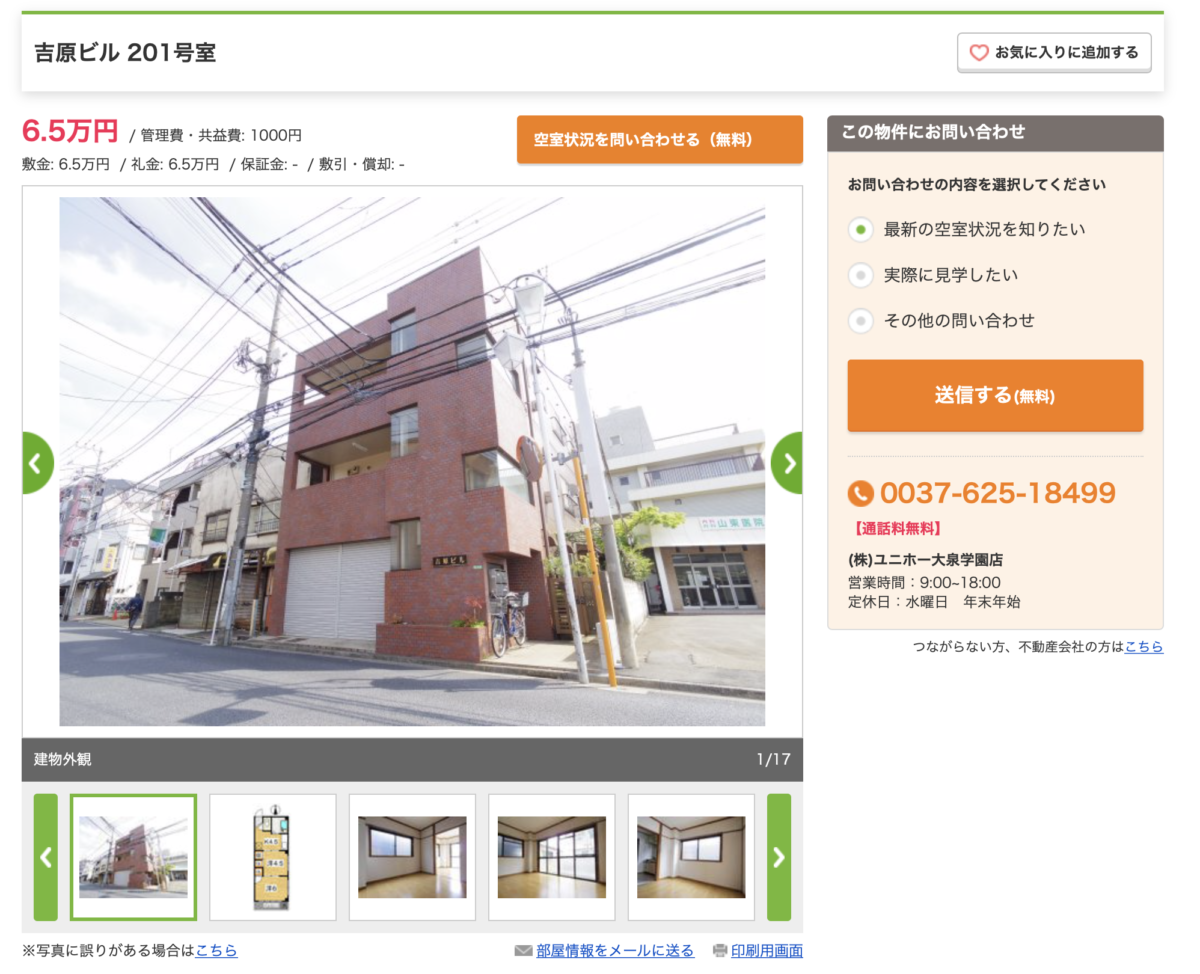
パッとみた感じ良さそうな物件に見えます。
ただ騙されてはいけません。
こちらの物件、モデルは予測家賃を32.31万円と予測しています。
明らかに変です。
でもきちんと情報を見るとその理由がわかります。
これです。
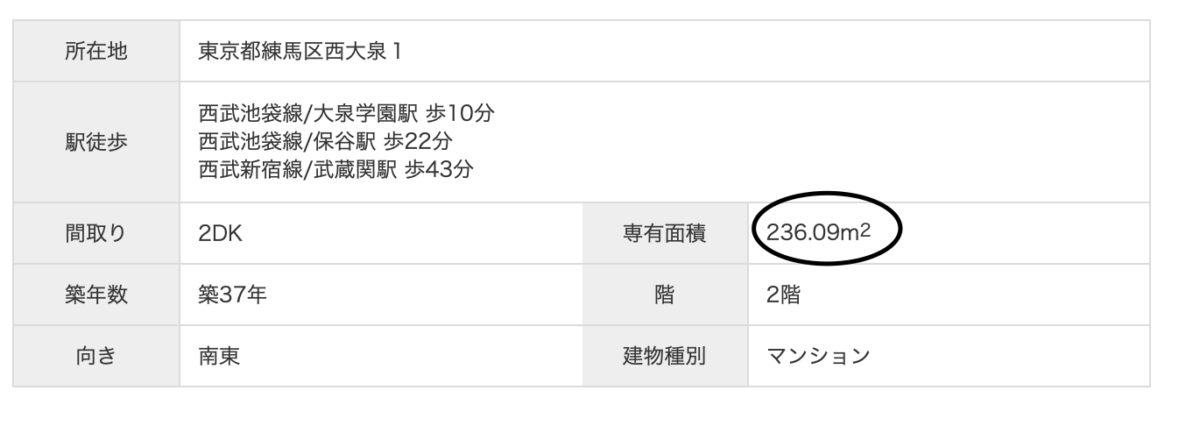
間取りに対して明らかに占有面積がでかすぎます。
入力エラーですwww
なんと予測モデルを作った結果、エラーデータを発見することができましたw
2位以降の物件も同じような状況です。
2位と3位の物件は占有面積が明らかにおかしいですよね。
1Kで100平米超えですw。
4位の物件は家賃が安すぎるように見えますw
これも入力ミスですかね。
一応一つずつみた感じですと、9位のやつとか正しいデータっぽいです。
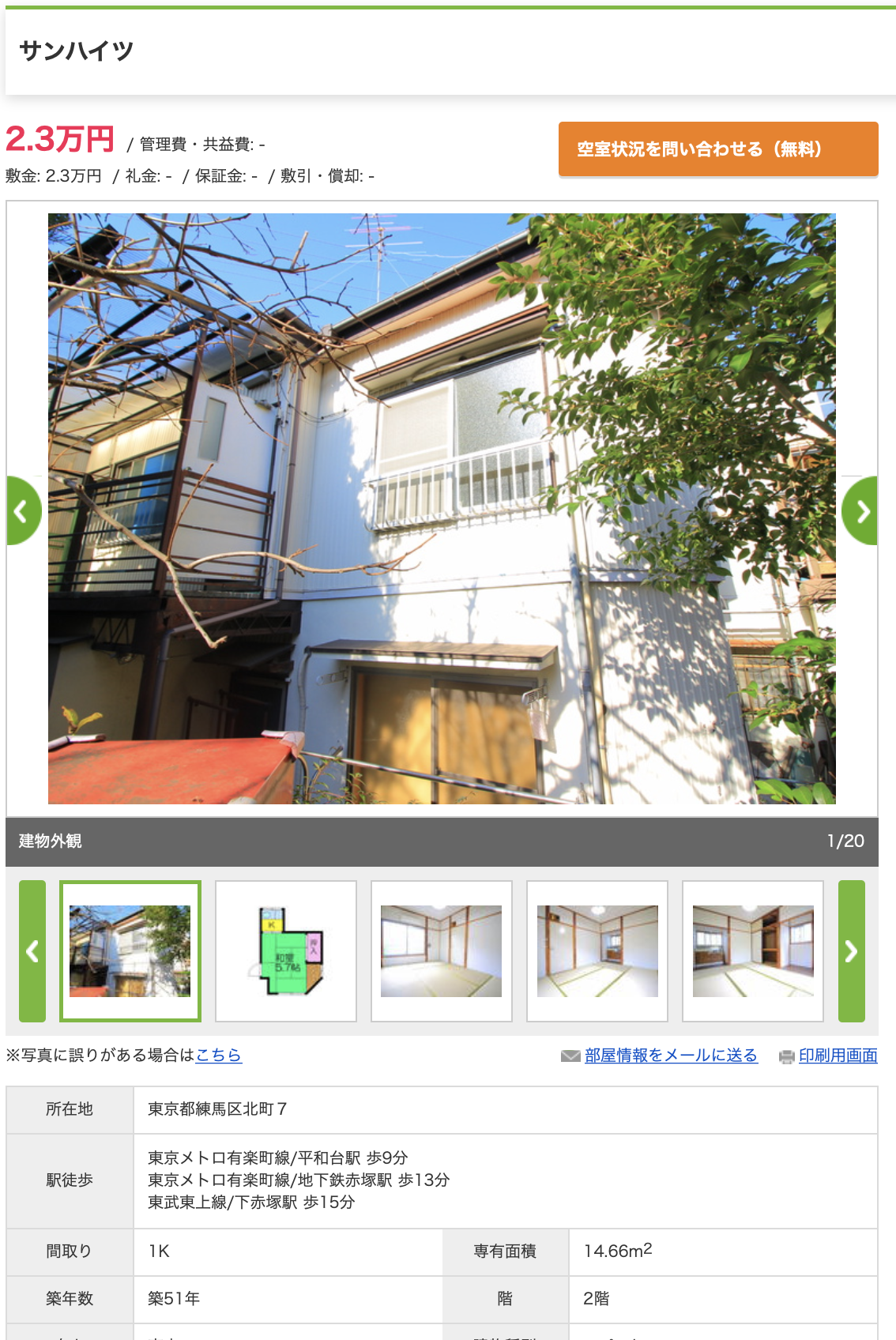
築51年で15平米ほどの部屋です。これでお家賃2.3万円はかなりすごいですね。
23区内でこの家賃はなかなかないと思います。
ただ、これだけ見るとボロボロの物件とエラーデータしか見えないので、少し条件を絞って総賃料が10万円以上の物件だけでみてみます。
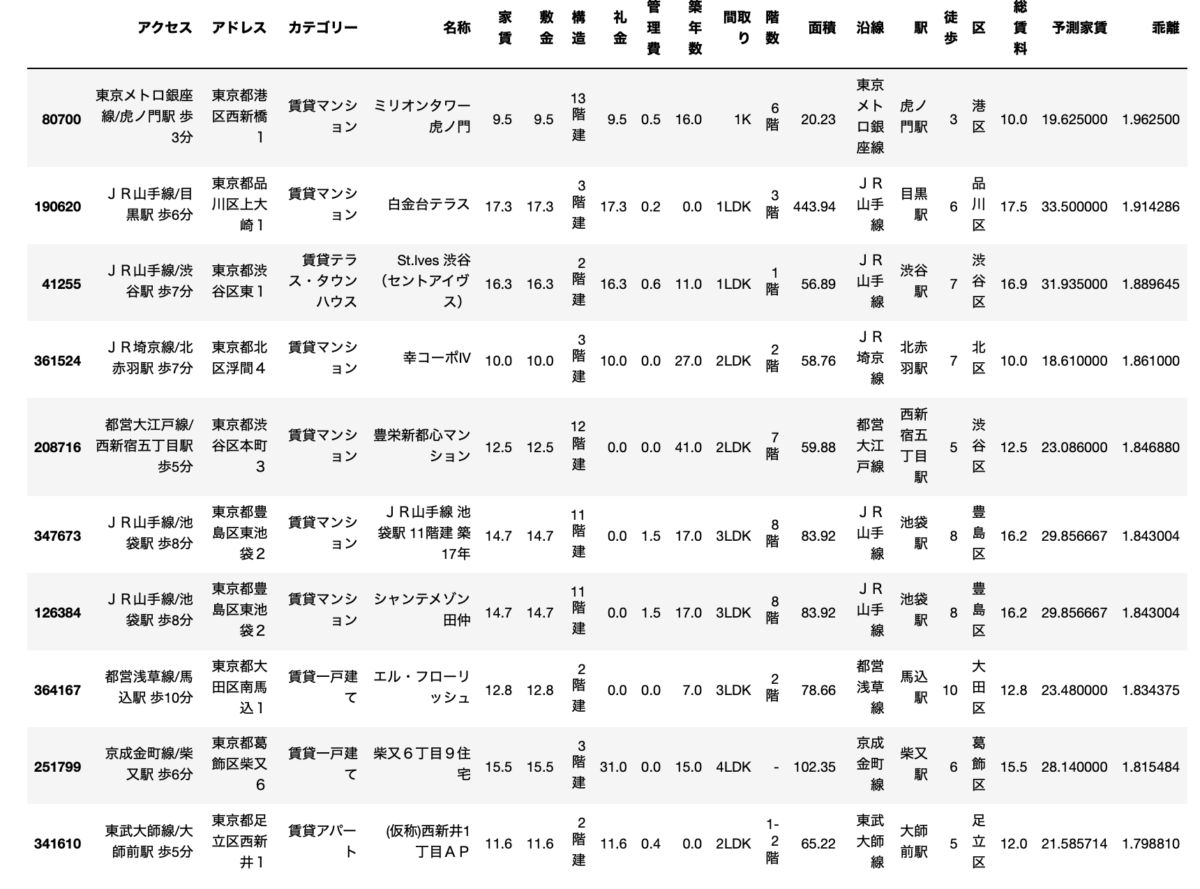
2位の物件は明らかに面積がバグっていますが、結構いい感じじゃないですかね。
1位の虎ノ門の物件なんてかなりお得ですよね。
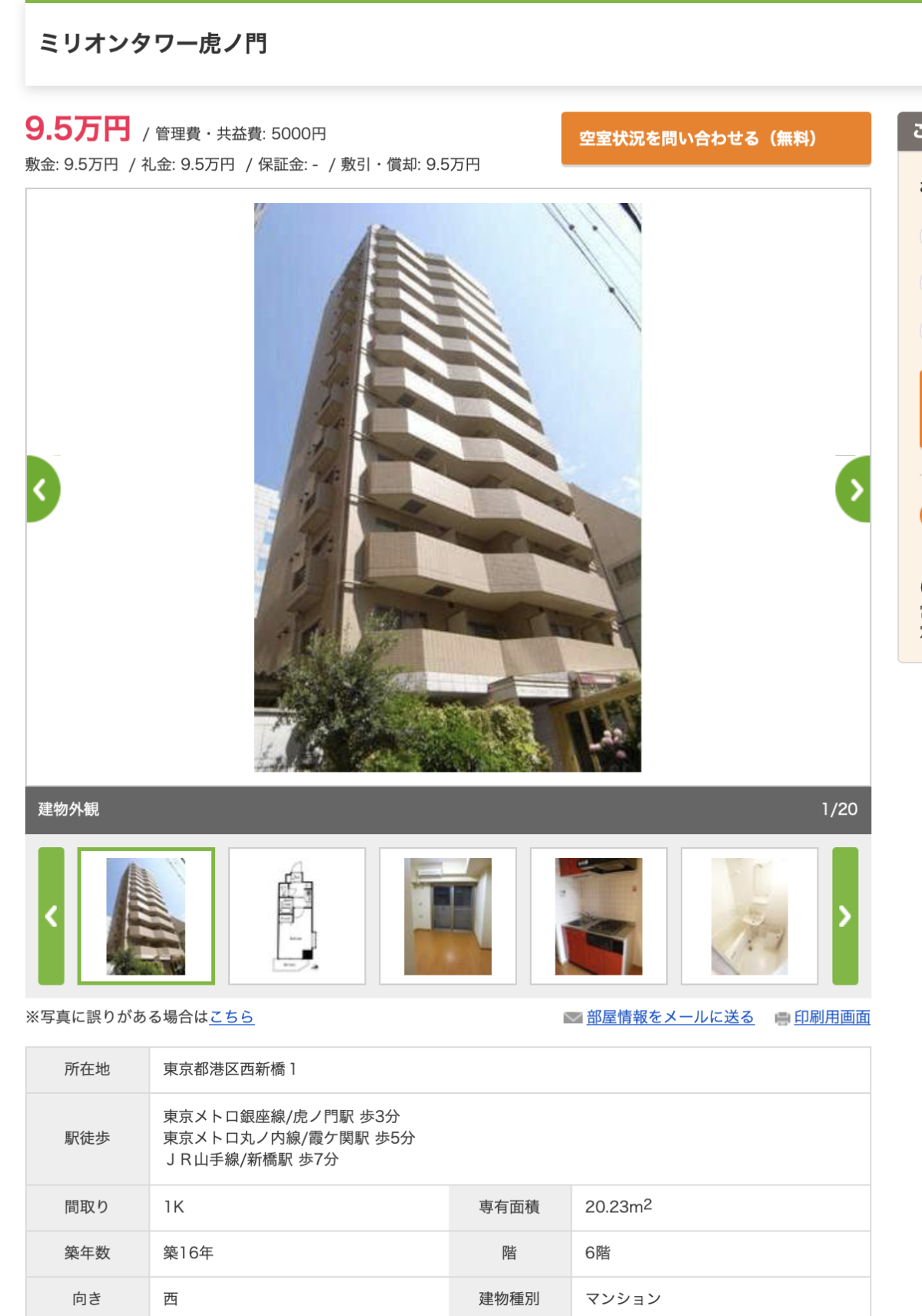
虎ノ門というスーパー高級エリアで築年数もそこまで古くない16年、これで10万円はすごいですよね。
予測では19万です。
3位の渋谷徒歩7分の物件も相当お得だと思います。
こうやって機械学習を利用してデータを見てみると、相場と乖離している物件を簡単に見つけることができます。
(おまけ)ぼったくり物件も探してみました
次に遊び半分で、逆パターンも探してみました。
つまり予測家賃に比べて実際の家賃が高すぎるぼったくり物件です。
このような物件には手を出してはいけませんw
条件なしでやったらさっきのようにエラーデータばかりになるので、ここでも総賃料10万円以上の物件に絞ってみてみます。
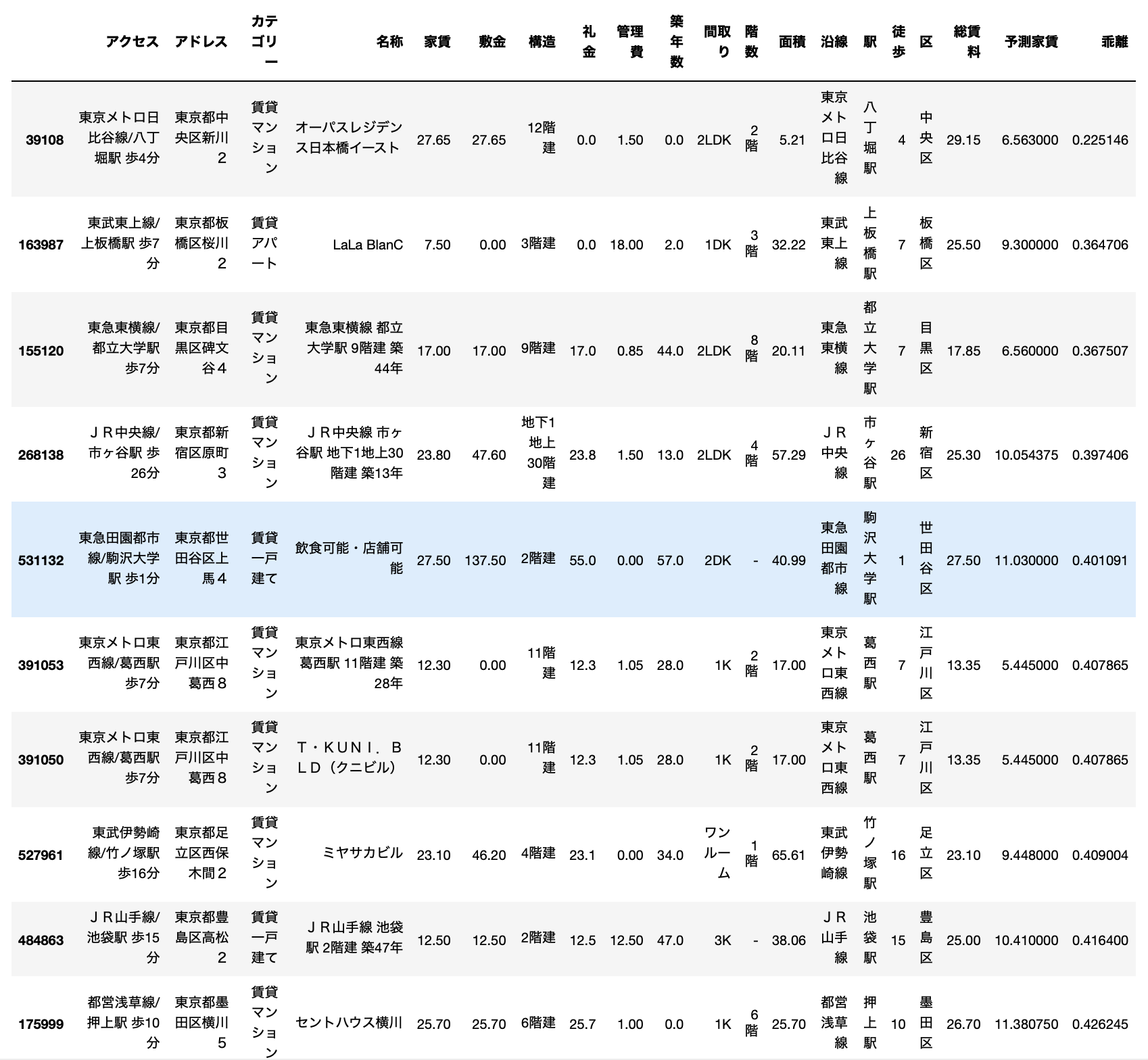
ここでもやはりエラーデータのオンパレードですw
1位の物件は面積狭すぎです。多分52.1が正しい値ですよね。
2位の物件は管理費がバグってますねw 3位は間取りの割に面積が変ですw
こういったエラーデータを除外してみてみると、いくつかまともそうな物件もあります。
例えば、9位の物件です。

池袋の物件で、築47年で3Kの物件です。
確かにこの古さで家賃12.5万円は高すぎる印象ですね。
このように、機械学習を用いて相場よりも高すぎる物件を見つけることができました。
(リベンジ)外れ値を除去して再検索しました
さっきまではかなり吹っ飛んでエラーデータが多かったので、もう少しここでまじめにデータをきれいにしてみます。
最初のデータ整形の時と同じように、外れ値を削除します。
現時点では、予測値と実際の値の比の分布はこんな感じです。
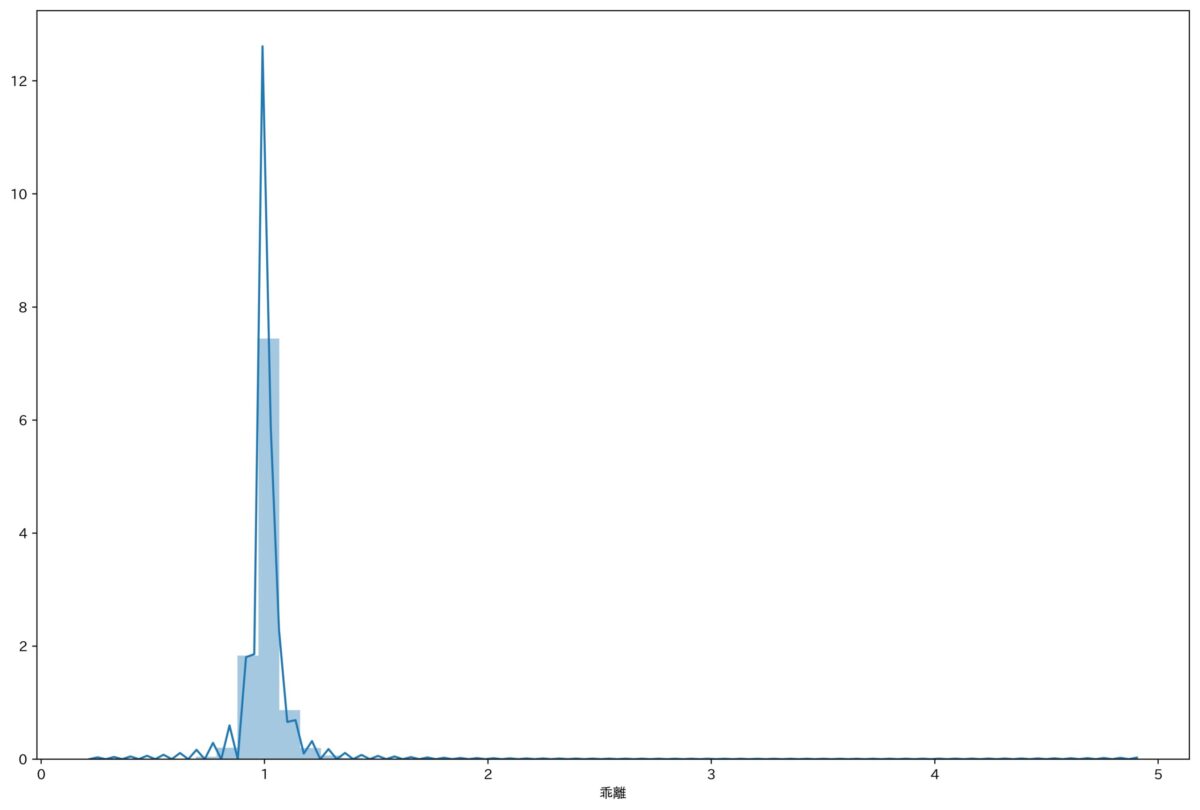
1に集中してますが、やはりここでも吹っ飛んでる外れ値があることがわかります。
ここでもデータ整形の時と同様に、-3σ〜3σで絞ります。
すると美しい正規分布になりました。
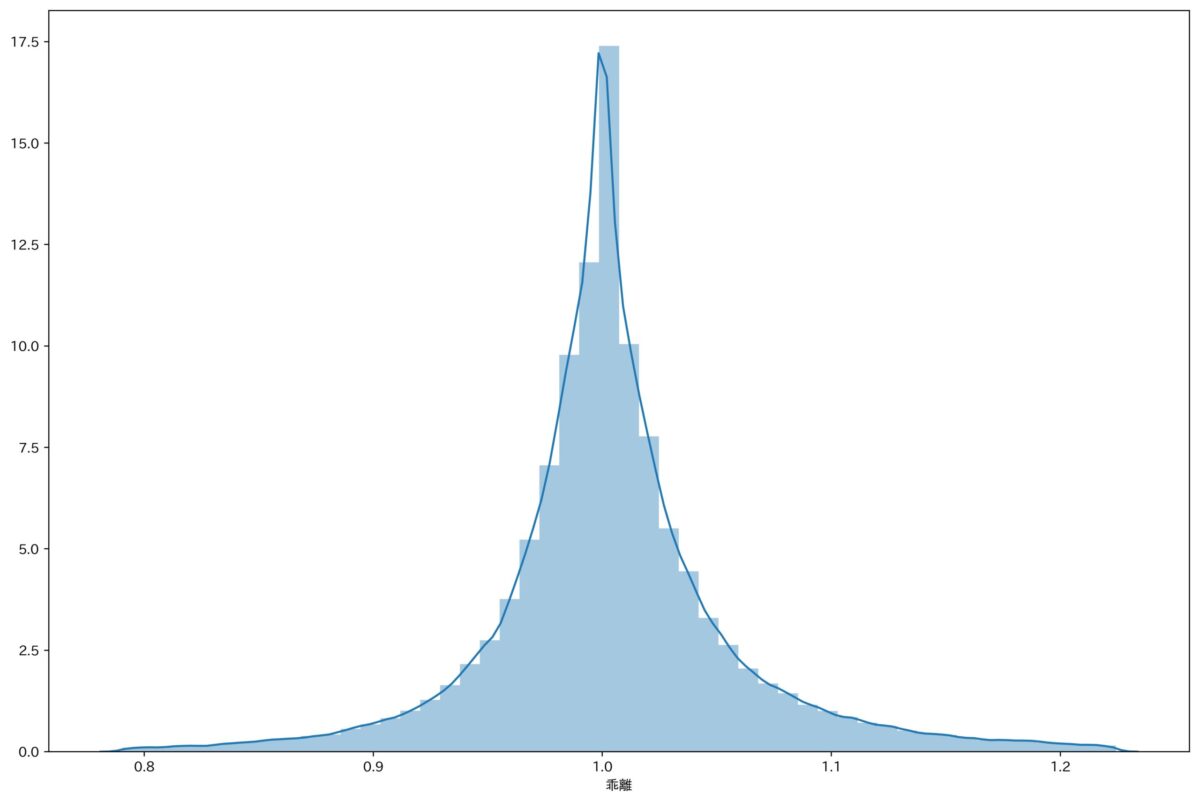
これで外れ値は削除されたので、この状態でもう一度検索してみます。
お得物件
まずはお得物件です。
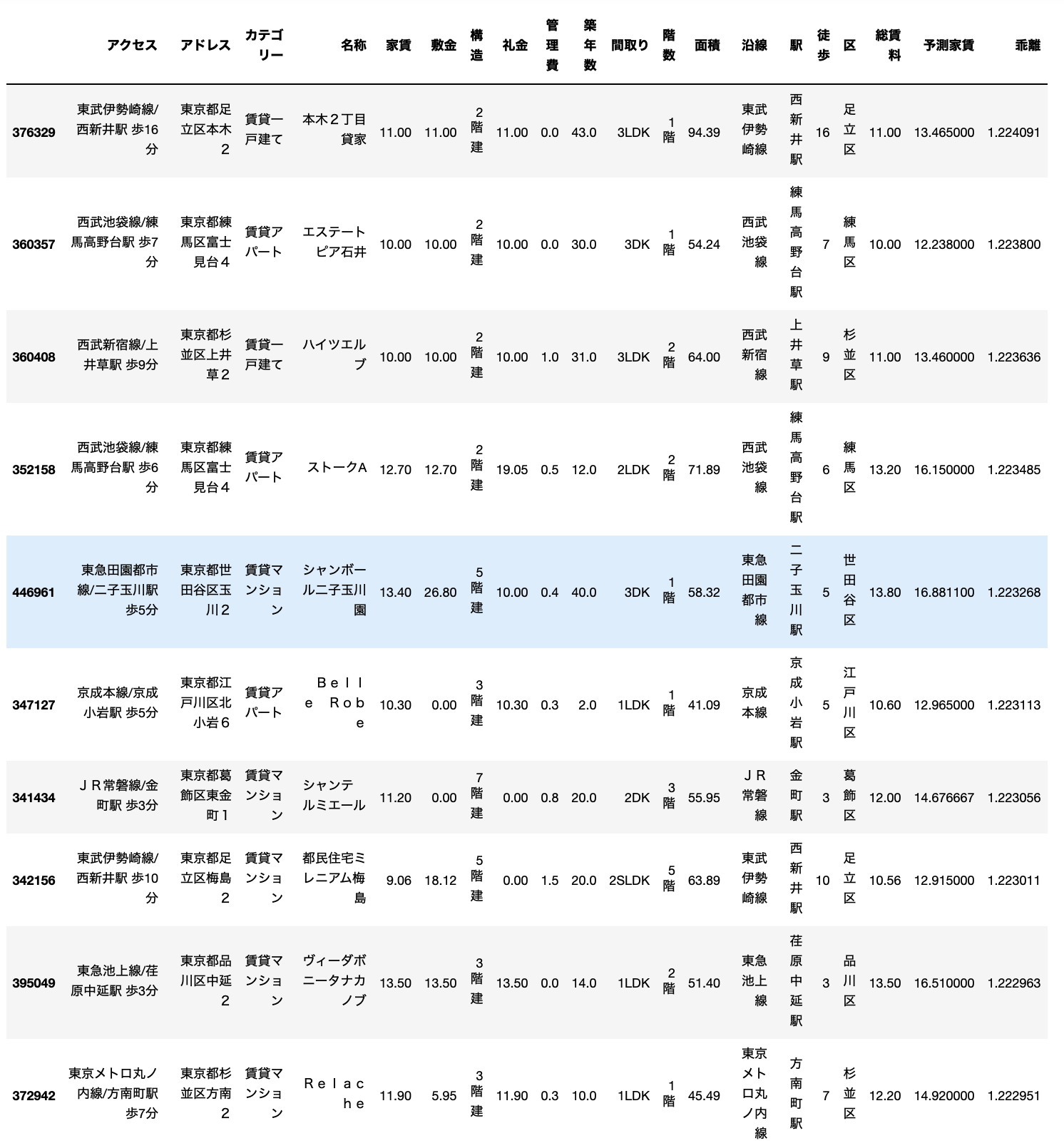
かなりまともなデータになりましたね。
1位の物件は、築年数は43年とかなり古いですが、広さは90平米超えで家賃11万円です。
23区内で90平米を超える物件は貴重ですからこれはかなりお得な感じがします。
サイトを見ると、残念ながら外観写真はありませんでした。
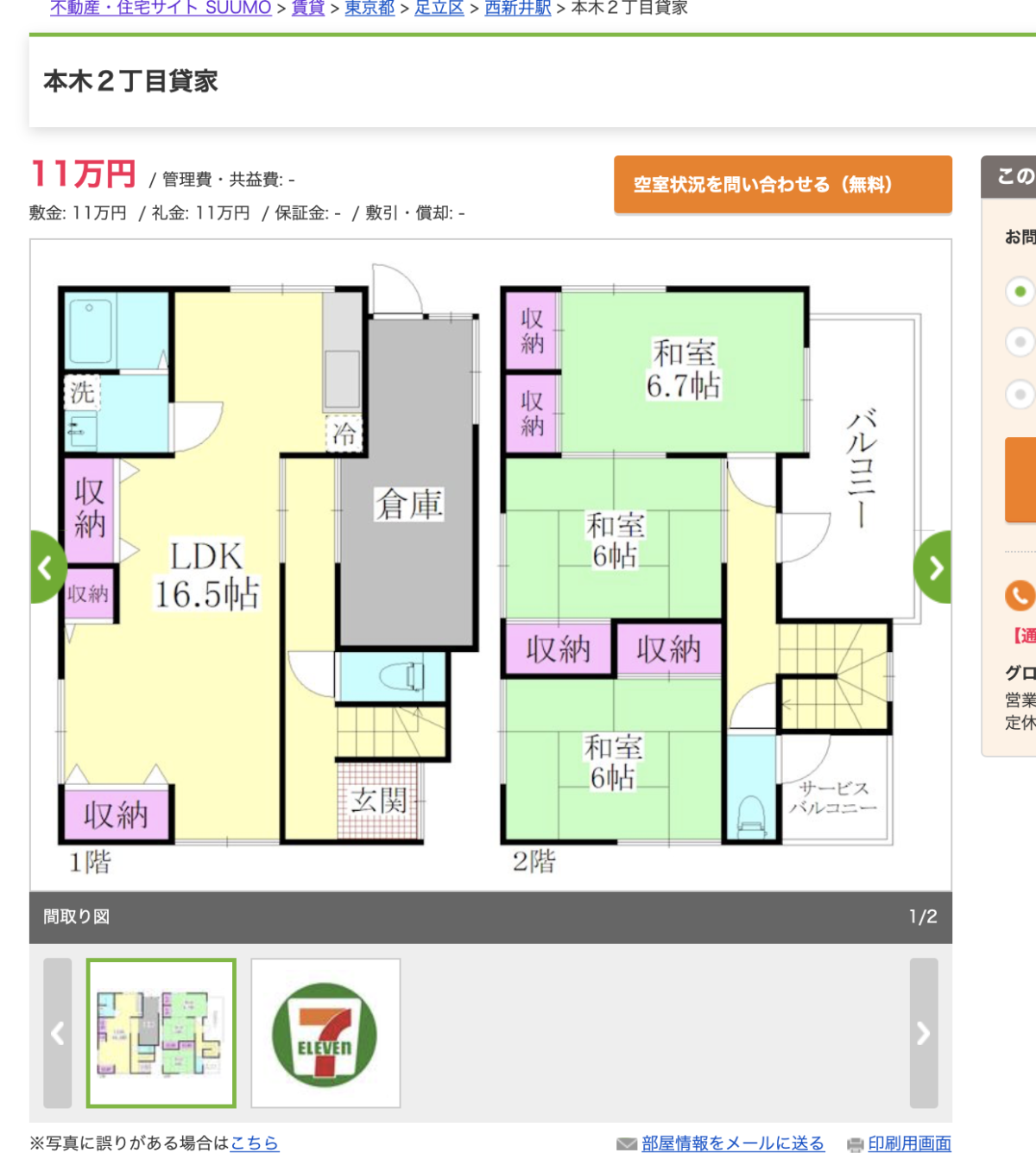
もう少し築浅物件で見てみると、4位の物件が良さそうです。
練馬区の高野台駅徒歩6分で築12年の2LDKです。
広さも70平米を超えています。
予測値16.15万円に対して、実際の家賃は13.2万円です。
相場の20%オフみたいな感じです。
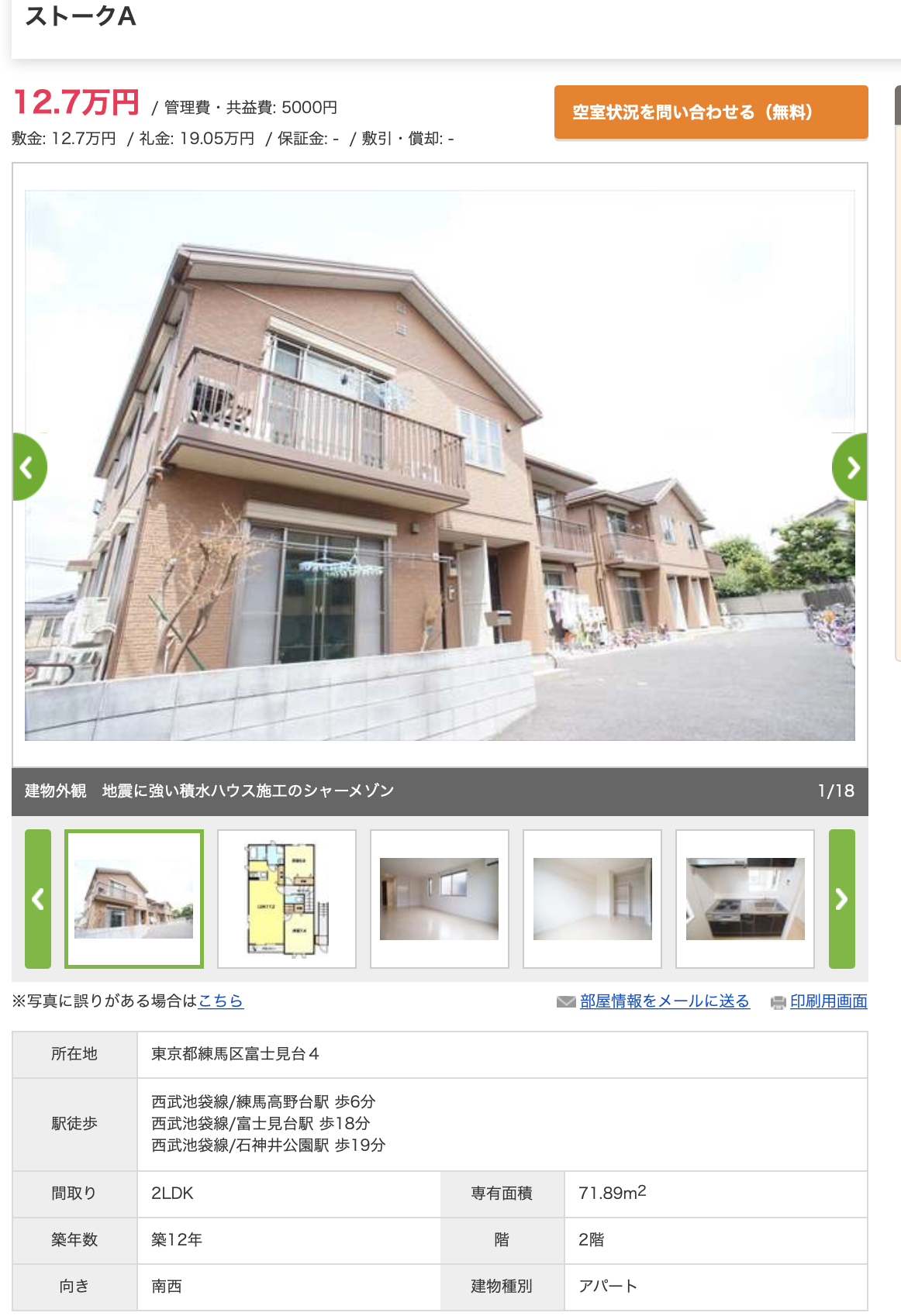
サイトを見ても結構いい感じですよね。
ぼったくり物件
次にぼったくり物件をみてみます。
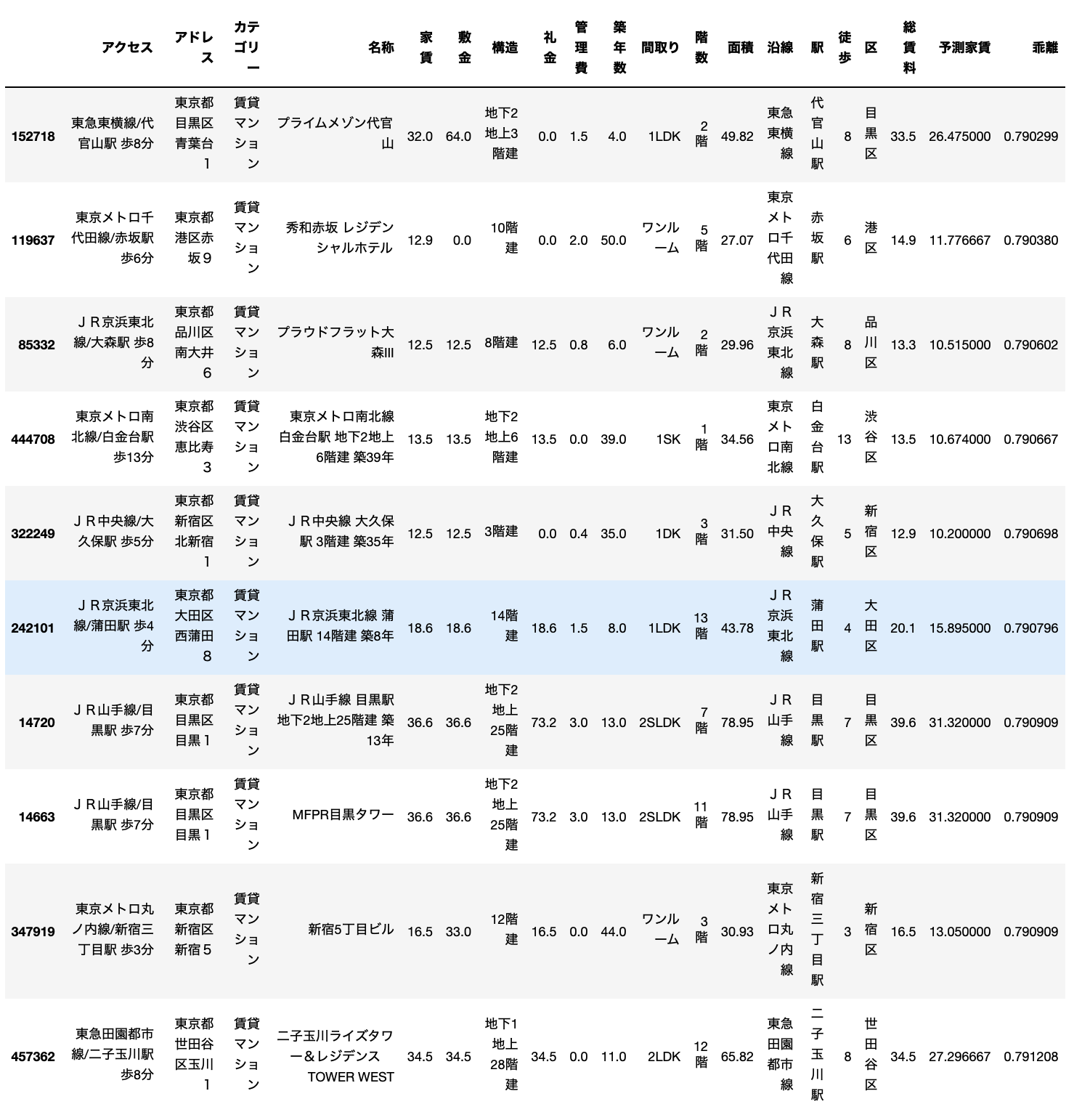
こちらもぶっ飛んだデータがなくなりましたね。
1位の物件は代官山の物件で、予測家賃26.475万円に対して実際に家賃が33.5万円です。
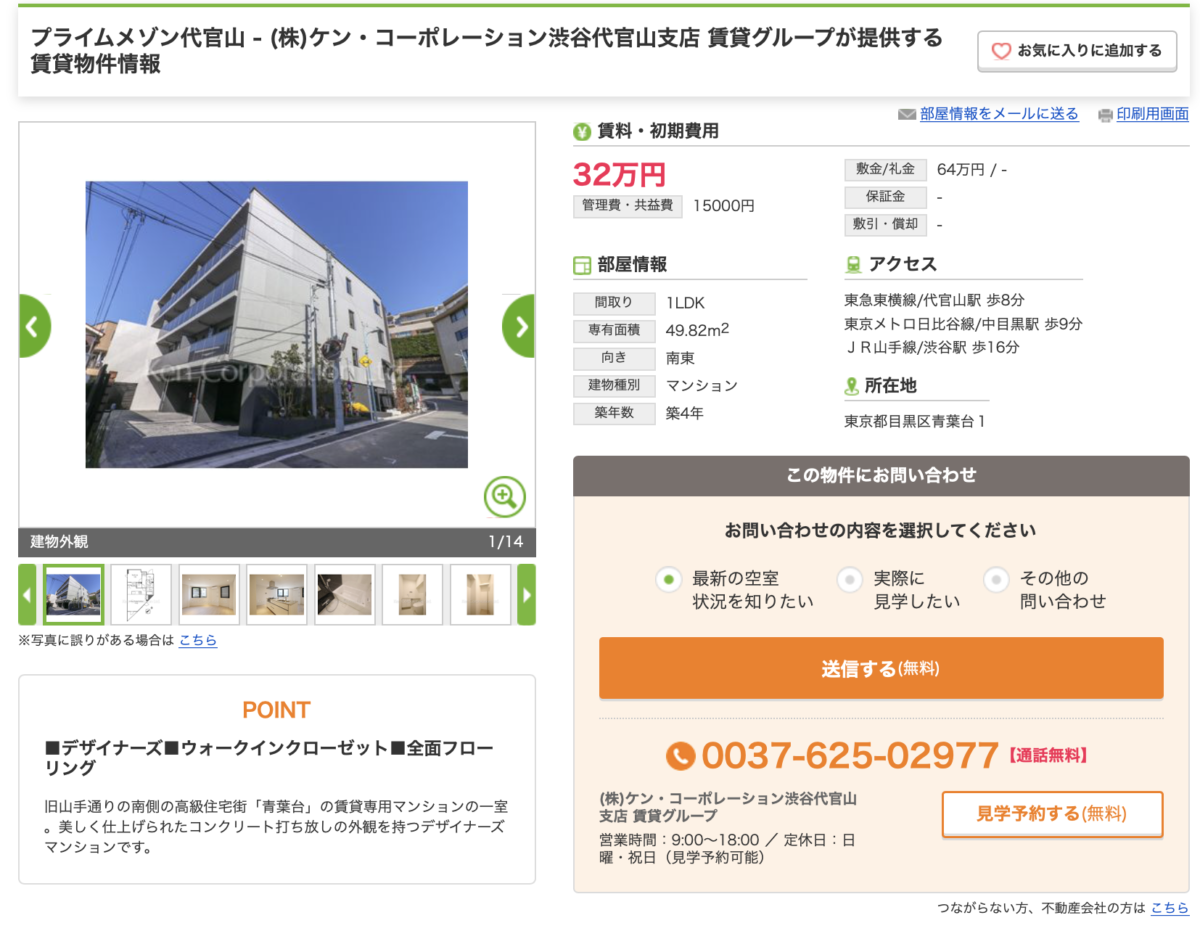
高いですね。まだ代官山で築4年なので強気に設定しているのかもしれません。
あるいは物件オーナーが家賃設定に対して正しい不動産知識を持っていない可能性もあります。
反対に2位の物件は築50年のボロ物件ですが、家賃は14.9万円です。
さすがは赤坂といったところです。
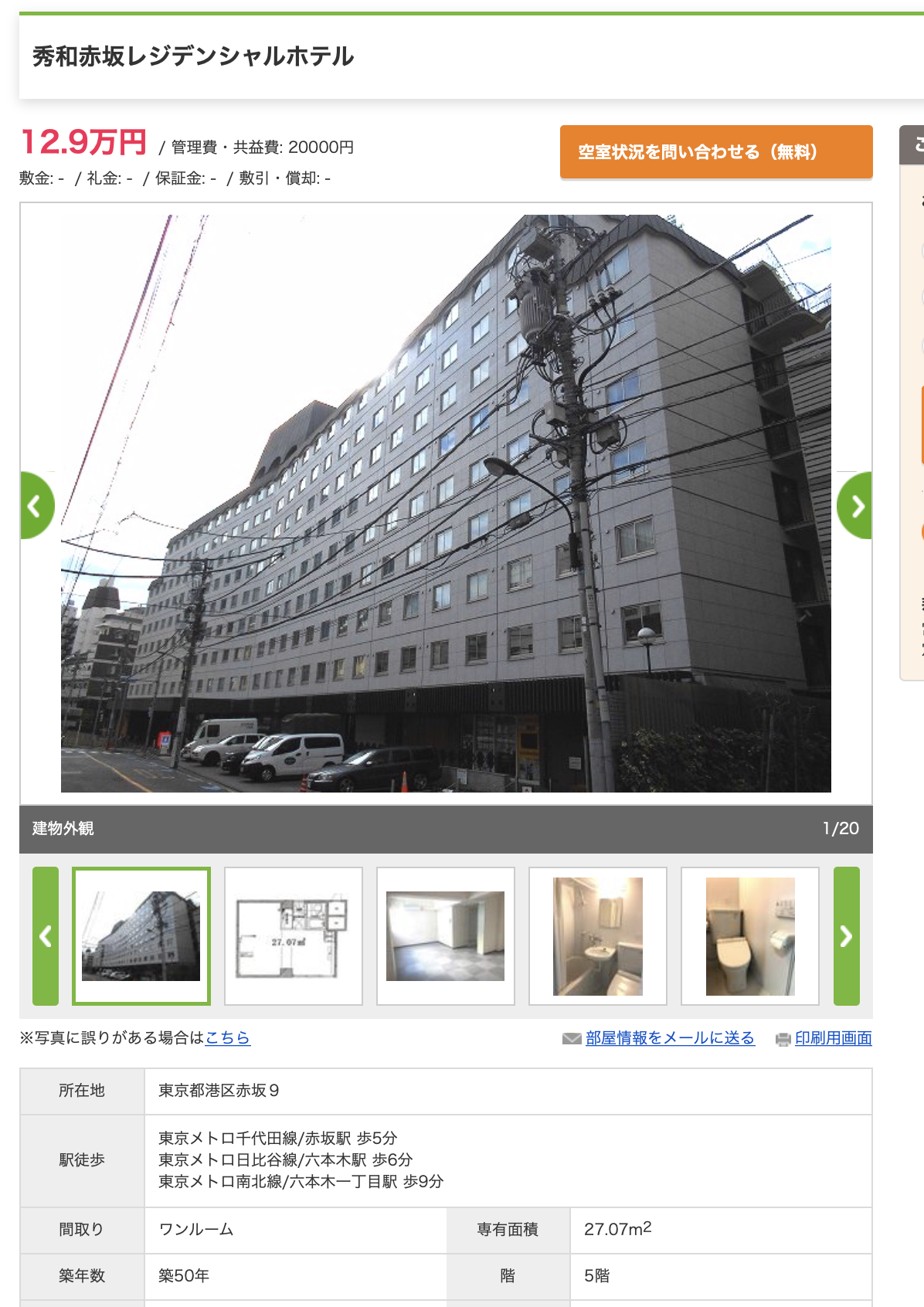
サイトを見てみると築50年の割にかなりきれいであることがわかります。
本当に築50年なのか(もしかしてデータのミス?)怪しい感じもしますが、見た感じ随所に古い感じがみられます。
きちんと管理されてきた物件なのでしょうか。
何れにしても機械学習モデルに言わせればこれは割高です。
このように、結果に対しても外れ値を除外してあげると、きれいなデータを確認することができました。
ついでに自分用の物件も探してみたw
そして最後にノリで自分用の物件も探してみましたw
こちらの記事で使った条件と同じものを使います。
-
【Pythonで不動産データ分析!】SUUMOをスクレイピングして情報収集!理想の賃貸物件を探してみた!
- 間取り:2LDK
- 築年数:15年以内
- 駅徒歩:7分以内
- 面積:50㎡以上
- カテゴリー:賃貸マンション
- エリア:中央区、新宿区、渋谷区、品川区、墨田区、江東区、目黒区のいずれか
この条件で探したお得物件トップ5がこちらです。
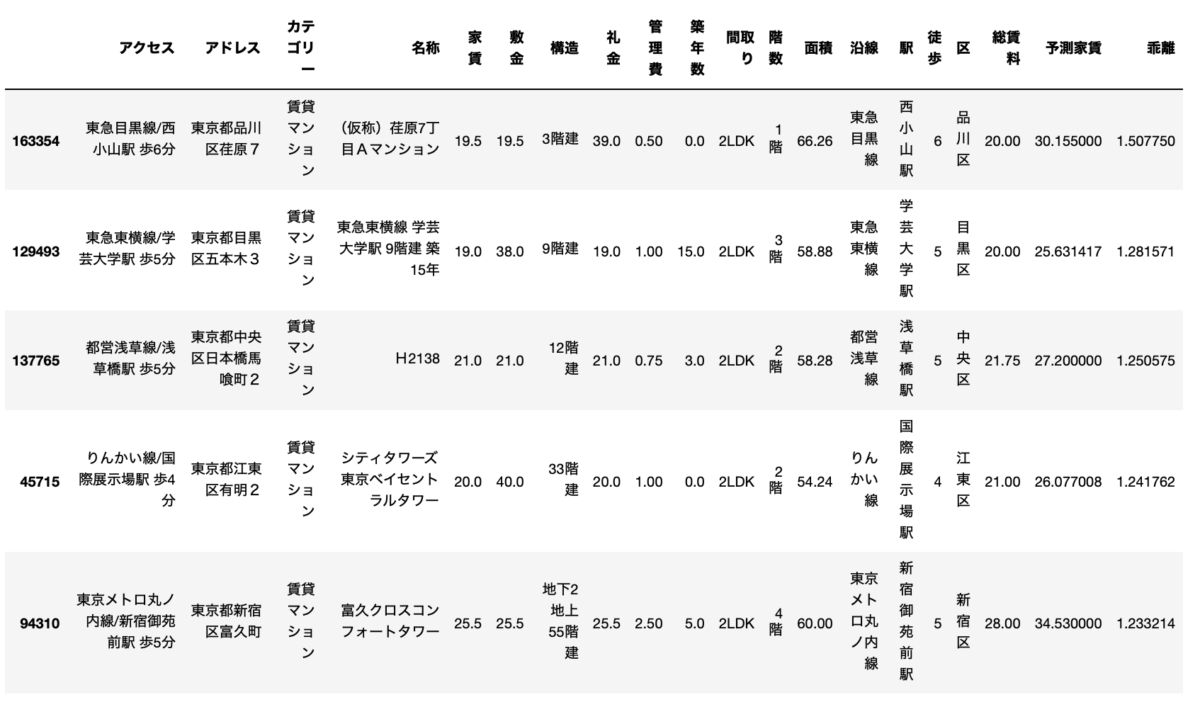
なかなか良さそうな物件ですね。
とりあえず1位はまだ建築中なので2位の物件だけご紹介します。(ちなみに1位の物件は3σのふるいにかけると除外される物件ですw)
学芸大学駅の物件ですね。

しかし、いざリンク先を開いたら掲載が終了していました。
データを取得したのが朝9時で、こちらのチェックをしたのは12時くらいです。
3時間の間に取られてしまいました。
やはり見る人が見るとお得であることはすぐにわかってしまうんですかね。
ちなみに3位の物件もすでに消えていて、4位の物件はまだありました。
かなり良さそうですね。高いですが・・・
予測家賃は26万ほどなので、6万円くらいお得ですね。
いい感じの物件ですが、やはり都心は高いですねw
5. 機械学習を使うとエラーデータを検出できる!
以上のように、機械学習モデルを利用してお得物件やぼったくり物件を見つけることができました。
しかし、ここで驚いたことが、SUUMOにはエラーデータがたくさんあることです。
分析して初めてわかりましたが、ここまでエラーが多いとは驚きましたw
おそらく手入力でデータを登録しているのでしょうかね。
データを入力した際の確認がしっかりできていないと、人間が作業するとこのようなミスに繋がることは避けられません。
誰しもが間違いを犯すのでこれを責めることはできません。
ただ、機械学習などを利用すればこのような入力エラーの可能性がある物件をあぶりだすことができます。
今回のように、今あるデータの中から予測値との乖離が大きすぎるデータをエラーの可能性があるとしてあぶりだすことができます。
先ほどは3σを基準に外れ値を取り除く作業をしましたが、ここで除去された物件がエラーデータ候補になります。
その後は人間が確認していけばOKです。
(さらなる改良は必要ですが)さらにこのモデルを使えば、新規物件を登録する際に、モデルで予測した家賃との乖離の大きさによってエラーを事前にはじき出すことも可能です。
そうすると、エラーデータを減らすことができ、今後も事前チェックでエラーを検知することができるようになります。
実際、機械学習はこのようなエラー検知にもよく利用されています。
是非とも、SUUMOさんにもこのようなシステムを導入して、データの精度を上げていただけると、ユーザーとしても利便性が高まると思います!
ちなみに僕はSUUMOユーザーです。
今回の分析を通して、他の情報サイト(HOMESとか)についても検証したくなりましたねw
スクレピングの観点で見ると、SUUMOが一番検索結果ページに情報がまとまっていたので採用しました。
6. データ分析・機械学習にはPythonが最適です!
ここでは、機械学習による家賃予測に挑戦してみました。
予測値と実際の値を比較して、お得な物件やぼったくり物件を見つけることができました。
さらに副産物として、多くのエラーデータが存在することもわかりましたw
やはりデータ分析は楽しいです。
そしてここでご紹介したものは全てPythonというプログラミング言語を利用して行いました。
Pythonは特にAI関連やデータ分析に強くて、最近話題のデータサイエンティストに人気の言語です。
シンプルな構造でとてもすっきりとしたコードが書けます。
Pythonでできることや学習法については過去の記事でもご紹介しているので、ご興味を持たれた方は是非ともご参考にしていただけると嬉しいです。
-

【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
また、Pythonは需要がどんどん高まっているので、身につけておくと転職時などにも有利になります。
僕は実際にPythonを独学して転職にも成功しています。
-

【副業は神です】2度の転職において副業が内定の決め手になったお話。
C言語などに比べてとても学びやすい言語ですので、これからプログラミングを始めたいという方にもPythonはおすすめです!
-

プログラミング学習は独学とプログラミングスクールどちらにすべきか?【結論、全部試すべし!】
まとめ
いかがでしたでしょうか。
ここでは、Pythonを使って、SUUMOの賃貸物件情報から機械学習モデルと作り、実際の家賃と比べることで、お得な物件とぼったくり物件を探してみました。
その結果、SUUMOには多くのエラーデータが存在していることがわかりましたw
まず重複データが非常に多いこと、そして各物件情報でもエラーがあることがわかりましたwww
この辺りの管理についてはもう少し工夫が必要であるように感じます。
機械学習を利用すれば、現在あるエラーデータをあぶりだすこともできますし、今後新規物件を登録する際の事前チェックも可能になります。
こういった発見ができることも機械学習やデータ分析をするからこそです。
世の中でデータサイエンティストの需要が高まる理由の一例をご紹介できたのではないかなと思います。
今回は気合い入れてかなり記事が長くなってしまいましたが、ここまで読んでくださってありがとうございました。
-
【いますぐ始められます】データ分析をするならPythonが最適です。【学習方法もご紹介します!】
-

【挫折しないために!】プログラミングを学習するためには目的意識が重要!途中で挫折する人の特徴とは?
-

【迷っている方へ!】プログラミングに興味を持ったらとりあえずやってみよう!
-
プログラミング学習は独学とプログラミングスクールどちらにすべきか?【結論、全部試すべし!】
-
【人気上昇中】今人気のプログラミング言語「Python」は何ができるのか?できることまとめます【転職でも有利です】
-

プログラミングの独学にUdemyをおすすめする理由!【僕はPythonを独学しました】




を用いてSUUMOからお得物件を探してみた! では、機械学習モデルを使ったデータ分析に一例をご紹介します。 機械学習手法の1つであるラ){kind=link}